Pivoting to the Query: Using Pivot Facets to build a Multi-Field Suggester

Suggesters, also known as autocomplete, typeahead or “predictive search” are powerful ways to accelerate the conversation between user and search application. Querying a search application is a little like a guessing game – the user formulates a query that they hope will bring back what they want – but sometimes there is an element of “I don’t know what I don’t know” – so the initial query may be a bit vague or ambiguous. Subsequent interactions with the search application are sometimes needed to “drill-in” to the desired information. Faceted navigation and query suggestions are two ways to ameliorate this situation. Facets generally work after the fact – after an initial attempt has been made, whereas suggesters seek to provide feedback in the act of composing the initial query – to improve it’s precision from the start. Facets also provide a contextual multi-dimensional visualization of the result set that can be very useful in the “discovery” mode of search.
A basic tenet of suggester implementations is to never suggest queries that will not bring back results. To do otherwise is pointless (it also does not inspire confidence in your search application!). Suggestions can come from a number of sources – previous queries that were found to be popular, suggestions that are intended to drive specific business goals and suggestions that are based on the content that has been indexed into the search collection. There are also a number of implementations that are available in Solr/Lucene out-of-the-box.
My focus here is on providing suggestions that go beyond the single term query – that provide more detail on the desired results and combine the benefits of multi-dimensional facets with typeahead. Suggestions derived from query logs can have this context but these are not controlled in terms of their structure. Suggestions from indexed terms or field values can also be used but these only work with one field at a time. Another focus of this and my previous blogs is to inject some semantic intelligence into the search process – the more the better. One way to do that is to formulate suggestions that make grammatical sense – constructed from several metadata fields – that create query phrases that clearly indicate what will be returned.
So what do I mean by “suggestions that make grammatical sense”? Just that we can think of the metadata that we may have in our search index (and if we don’t have, we should try to get it!) as attributes or properties of some items or concepts represented by indexed documents. There are potentially a large number of permutations of these attribute values, most of which make no sense from a grammatical perspective. Some attributes describe the type of thing involved (type attributes), and others describe the properties of the thing. In a linguistic sense, we can think of these as noun and adjective properties respectively.
To provide an example of what I mean, suppose that I have a search index about people and places. We would typically have fields like first_name, last_name, profession, city and state. We would normally think of these fields in this order or maybe last_name, first_name city, state – profession as in:
Jones, Bob Cincinnati, Ohio – Accountant
Or
Bob Jones, Accountant, Cincinnati, Ohio
But we would generally not use:
Cincinnati Accountant Jones Ohio Bob
Even though this is a valid mathematical permutation of field value ordering. So if we think of all of the possible ways to order a set of attributes, only some of these “make sense” to us as “human-readable” renderings of the data.
Turning Pivot Facets “Around” – Using Facets to generate query suggestions
While facet values by themselves are a good source of query suggestions because they encapsulate a record’s “aboutness”, they can only do so one attribute at a time. This level of suggestion is already available out-of-the-box with Solr/Lucene Suggester implementations which use the same field value data that facets do in the form of a so-called uninverted index (aka the Lucene FieldCache or indexed Doc Values). But what if we want to combine facet fields as above? Solr pivot facets (see “Pivot Facets Inside And Out” for background on pivot facets) provide one way of combining an arbitrary set of fields to produce a cascading or nested sets of field values. Think of is as a way of generating a facet value “taxonomy” – on the fly. How does this help us? Well, we can use pivot facets (at index time) to find all of the permutations for a compound phrase “template” composed of a sequence of field names – i.e. to build what I will call “facet phrases”. Huh? Maybe an example will help.
Suppose that I have a music index, which has records for things like songs, albums, musical genres and the musicians, bands or orchestras that performed them as well as the composers, lyricists and songwriters that wrote them. I would like to search for things like “Jazz drummers”, “Classical violinists”, “progressive rock bands”, “Rolling Stones albums” or “Blues songs” and so on. Each of these phrases is composed of values from two different index fields – for example “drummer”, “violinist” and “band” are musician or performer types. “Rolling Stones” are a band which as a group is a performer (we are dealing with entities here which can be single individuals or groups like the Stones). “Jazz”, “Classical”, “Progressive Rock” and “Blues” are genres and “albums” and “songs” are recording types (“song” is also a composition type). All of these things can be treated as facets. So if I create some phrase patterns for these types of queries like “musician_type, recording_type” or “genre, musician_type” or “performer, recording_type” and submit these as pivot facet queries, I can construct many examples of the above phrases from the returned facet values. So for example, the pivot pattern “genre, musician_type” would return things like, “jazz pianist”, “rock guitarist”, “classical violinist”, “country singer” and so on – as long as I have records in the collection for each of these category combinations.
Once I have these phrases, I can use them as query suggestions by indexing them into a collection that I use for this purpose. It would also be nice if the precision that I am building into my query suggestions was honored at search time. This can be done in several ways. When I build my suggester collection using these pivot patterns, I can capture the source fields and send them back with the suggestions. This would enable precise filter or boost queries to be used when they are submitted by the search front end. One potential problem here is if the user types the exact same query that was suggested – i.e. does not select from the typeahead dropdown list. In this case, they wouldn’t get the feedback from the suggester but we want to ensure that the results would be exactly the same.
The query autofiltering technique that I have been developing and blogging about is another solution to matching the precision of the response with the added precision of these multi-field queries. It would work whether or not the user clicked on a suggestion or typed in the phrase themselves and hit “enter”. Some recent enhancements to this code that enable it to respond to verb, prepositional or adjectives and to adjust the “context” of the generated filter or boost query, provide another layer of precision that we can use in our suggestions. That is, suggestions can be built from templates or patterns in which we can add “filler” terms such as the verbs, prepositions and adjectives that the query autofilter now supports.
Once again, an example may help to clear up the confusion. In my music ontology, I have attributes for “performer” and “composer” on documents about songs or recordings of songs. Many artists whom we refer to as “singer-songwriters” for example, occur as both composers and performers. So if I want to search for all of their songs regardless of whether they wrote or performed them, I can search for something like:
Jimi Hendrix songs
If I want to just see the songs that Jimi Hendrix wrote, I would like to search for
“songs Jimi Hendrix wrote” or “songs written by Jimi Hendrix”
which should return titles like “Purple Haze”, “Foxy Lady” and “The Wind Cries Mary”
In contrast the query:
“songs Jimi Hendrix performed”
should include covers like “All Along the Watchtower” (for your listening pleasure, here’s a link), “Hey Joe” and “Sgt Peppers Lonely Hearts Club Band”
and
“songs Jimi Hendrix covered”
would not include his original compositions.
In this case, the verb phrases “wrote” or “written by”, “performed” or “covered” are not field values in the index but they tell us that the user wants to constrain the results either to compositions or to performances. The new features in the query autofilter can handle these things now but what if we want to make suggestions like this?
To do this, we write pivot template pattern like this
${composition_type} ${composer} wrote
${composition_type} written by ${composer}
${composition_type} ${performer} performed
Code to do Pivot Facet Mining
The source code to build multi-field suggestions using pivot facets is available on github. The code works as a Java Main client that builds a suggester collection in Solr.
The design of the suggester builder includes one or more “query collectors” that feed query suggestions to a central “suggester builder” that a) validates the suggestions against the target content collection and b) can obtain context information from the content collection using facet queries (see below). One of the implementations of query collector is the PivotFacetQueryCollector. Other implementations can get suggestions from query logs, files, Fusion signals and so on.
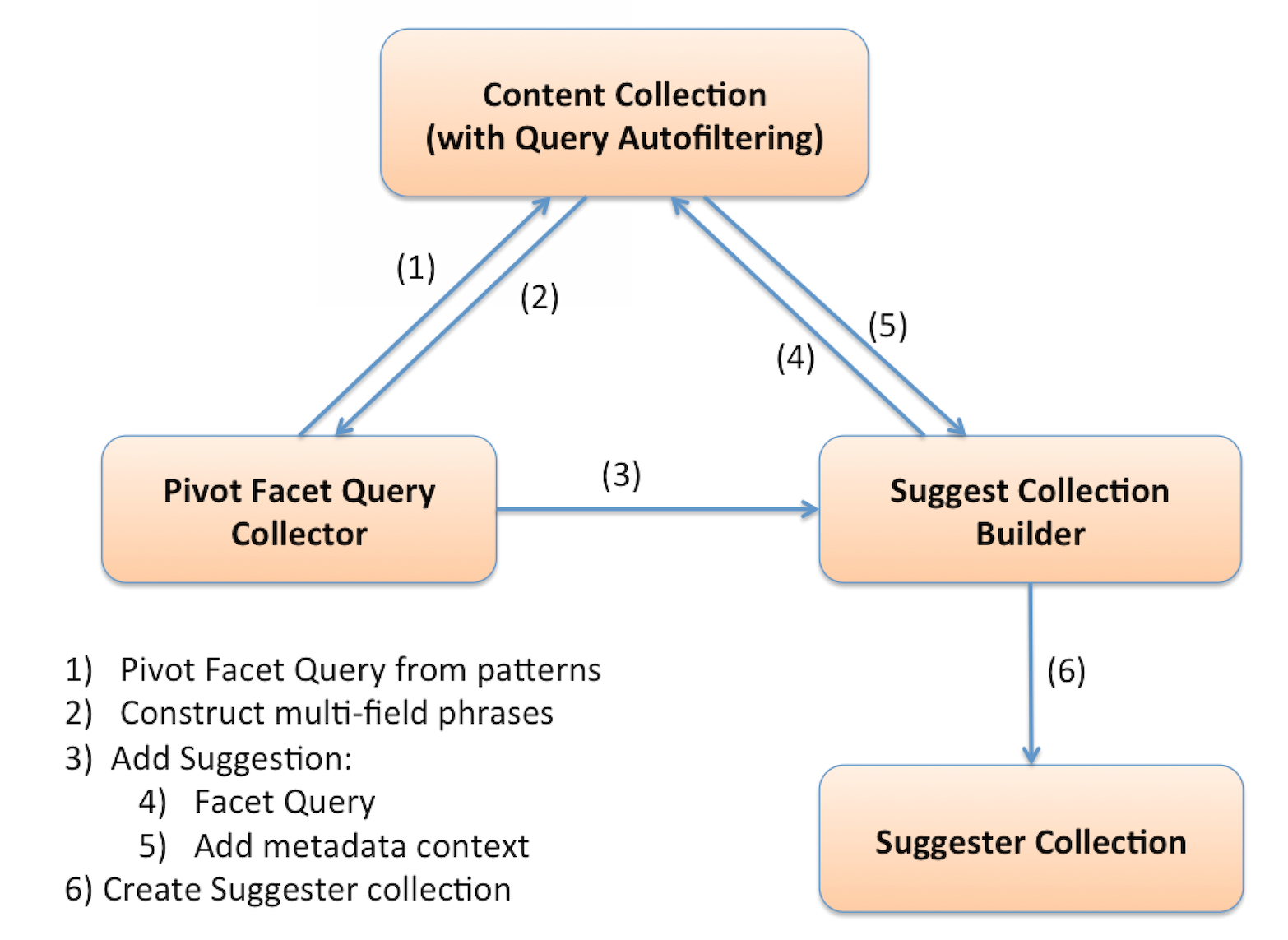
The github distribution includes the music ontology dataset that was used for this blog article and a sample configuration file to build a set of suggestions on the music data. The ontology itself is also on github as a set of XML files that can be used to create a Solr collection but note that some preprocessing of the ontology was done to generate these files. The manipulations that I did on the ontology to ‘denormalize’ or flatten it will be the subject of a future blog post as it relates to techniques that can be used to ‘surface’ interesting relationships and make them searchable without the need for complex graph queries.
Using facets to obtain more context about the suggestions
The notion of “aboutness” introduced above can be very powerful. Once we commit to building a special Solr collection (also known as a ‘sidecar’ collection) just for typeahead, there are other powerful search features that we now have to work with. One of them is contextual metadata. We can get this by applying facets to the query that the suggester builder uses to validate the suggestion against the content collection. One application of this is to generate security trimming ACL values for a suggestion by getting the set of ACLs for all of the documents that a query suggestion would hit on – using facets. Once we have this, we can use the same security trimming filter query on the suggester collection that we use on the content collection. That way we never suggest a query to a user that cannot return any results for them – in this case because they don’t have access to any of the documents that the query would return. Another thing we can do when we build the suggester collection is to use facets to obtain context about various suggestions. As discussed in the next section, we can use this context to boost suggestions that share contextual metadata with recently executed queries.
Dynamic or On-The-Fly Predictive Analytics
One of the very powerful and extremely user-friendly things that you can do with typeahead is to make it sensitive to recently issued queries. Typeahead is one of those use cases where getting good relevance is critical because the user can only see a few results and can’t use facets or paging to see more. Relevance is often dynamic in a search session meaning that what the user is looking for can change – even in the course of a single session. Since typeahead starts to work with only a few characters entered, the queries start at a high level of ambiguity. If we can make relevance sensitive to recently searched things we can save the user a lot of a) work and b) grief. Google seems to do just this. When I was building the sample Music Ontology, I was using Google and Wikipedia (yes, I did contribute!) to lookup songs and artists and to learn or verify things like who was/were the songwriter(s) etc. I found that if I was concentrating on a single artist or genre, after a few searches, Google would start suggesting long song titles with just two or three characters entered!! It felt as if it “knew” what my search agenda was! Honestly, it was kinda spooky but very satisfying.
So how can we get a little of Google’s secret sauce in our own typeahead implementations? Well the key here is context. If we can know some things about what the user is looking for we can do a better job of boosting things with similar properties. And we can get this context using facets when we build the suggestion collection! In a nutshell, we can use facet field values to build boost queries to use in future queries in a user session. The basic data flow is shown below:
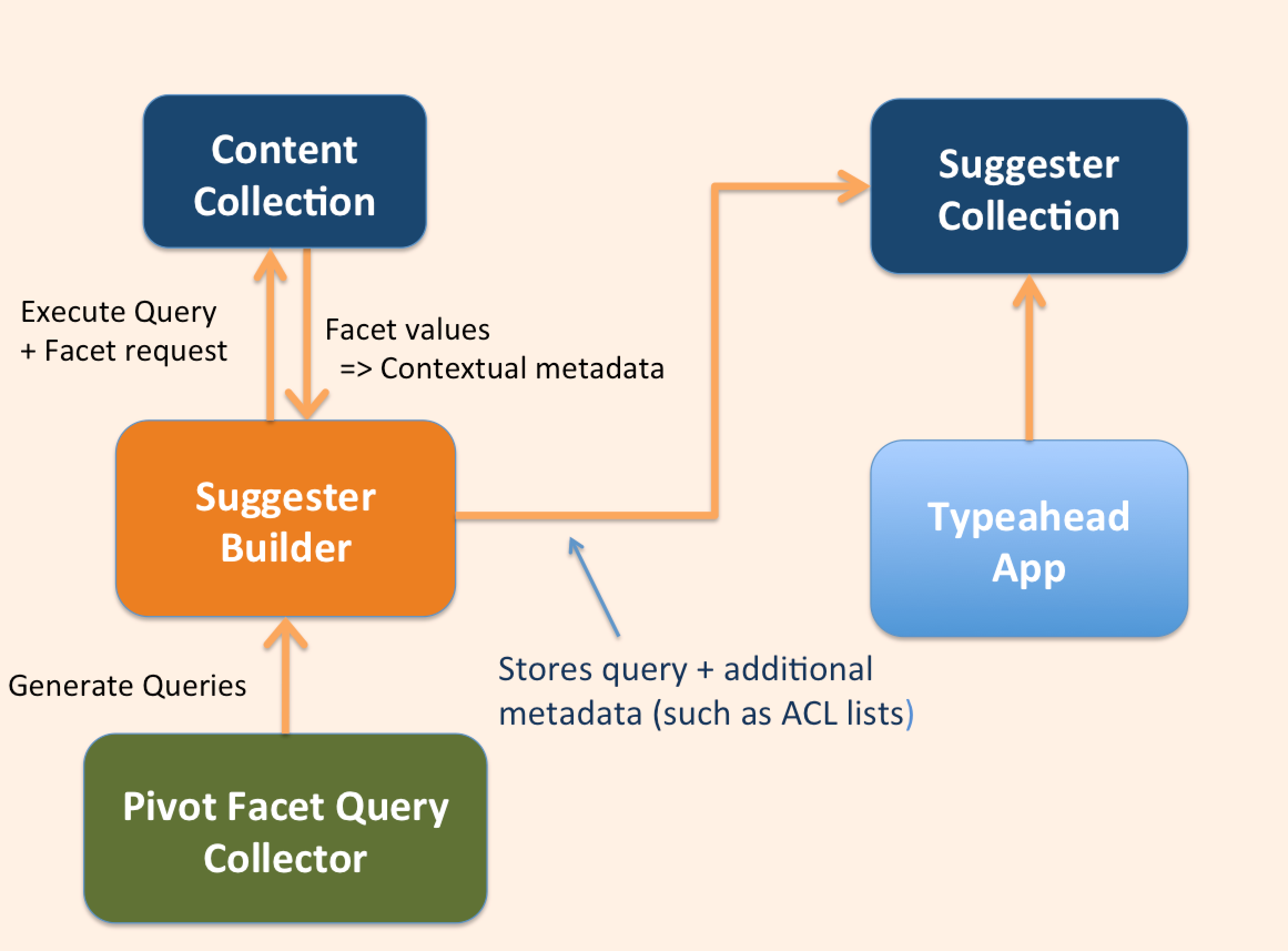
This requires some coordination between the suggester builder and the front-end (typically Javascript based) search application. The suggester builder extracts context metadata for each query suggestion using facets obtained from the source or content collection and stores these values with the query suggestions in the suggester collection. To demonstrate how this contextual metadata can be used in a typeahead app, I have written a simple Angular JS application that uses this facet-based metadata in the suggester collection to boost suggestions that are similar to recently executed queries. When a query is selected from a typeahead list, the metadata associated with that query is cached and used to construct a boost query on subsequent typeahead actions.
So, for example if I type in the letter ‘J’ into the typeahead app, I get
Jai Johnny Johanson Bands
Jai Johnny Johanson Groups
J.J. Johnson
Jai Johnny Johanson
Juke Joint Jezebel
Juke Joint Jimmy
Juke Joint Johnny
But if I have just searched for ‘Paul McCartney’, typing in ‘J’ now brings back:
John Lennon
John Lennon Songs
John Lennon Songs Covered
James P Johnson Songs
John Lennon Originals
Hey Jude
The app has learned something about my search agenda! To make this work, the front end application caches the returned metadata for previously executed suggester results and stores this in a circular queue on the client side. It then uses the most recently cached sets of metadata to construct a boost query for each typeahead submission. So when I executed the search for “Paul McCartney”, the returned metadata was:
genres_ss:Rock,Rock & Roll,Soft Rock,Pop Rock
hasPerformer_ss:Beatles,Paul McCartney,José Feliciano,Jimi Hendrix,Joe Cocker,Aretha Franklin,Bon Jovi,Elvis Presley ( … and many more)
composer_ss:Paul McCartney,John Lennon,Ringo Starr,George Harrison,George Jackson,Michael Jackson,Sonny Bono
memberOfGroup_ss:Beatles,Wings
From this returned metadata – taking the top results, the cached boost query was:
genres_ss:”Rock”^50 genres_ss:”Rock & Roll”^50 genres_ss:”Soft Rock”^50 genres_ss:”Pop Rock”^50
hasPerformer_ss:”Beatles”^50 hasPerformer_ss:”Paul McCartney”^50 hasPerformer_ss:”José Feliciano”^50 hasPerformer_ss:”Jimi Hendrix”^50
composer_ss:”Paul McCartney”^50 composer_ss:”John Lennon”^50 composer_ss:”Ringo Starr”^50 composer_ss:”George Harrison”^50
memberOfGroup_ss:”Beatles”^50 memberOfGroup_ss:”Wings”^50
And since John Lennon is both a composer and a member of the Beatles, records with John Lennon are boosted twice which is why these records now top the typeahead list. (not sure why James P Johnson snuck in there except that there are two ‘J’s in his name).
This demonstrates how powerful the use of context can be. In this case, the context is based on the user’s current search patterns. Another take home here is that use of facets besides the traditional use as a UI navigation aid are a powerful way to build context into a search application. In this case, they were used in several ways – to create the pivot patterns for the suggester, to associate contextual metadata with suggester records and finally to use this context in a typeahead app to boost records that are relevant to the user’s most recent search goals. (The source code for the Angular JS app is also included in the github repository.)
We miss you Jimi – thanks for all the great tunes! (You are correct, I listened to some Hendrix – Beatles too – while writing this blog – is it that obvious?)
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.