Multi-Word Managed Synonyms in Solr With Query-Time Support
Tutorial and examples of query-time support for multi-word synonyms in Apache Solr with the eDismax and standard/Lucene query parsers.

Solr has gained multi-word query-time synonym management support in the edismax and standard/”lucene” query parsers.
Cool, right? But why should you care?
Index-time Synonym Expansion Has Problems
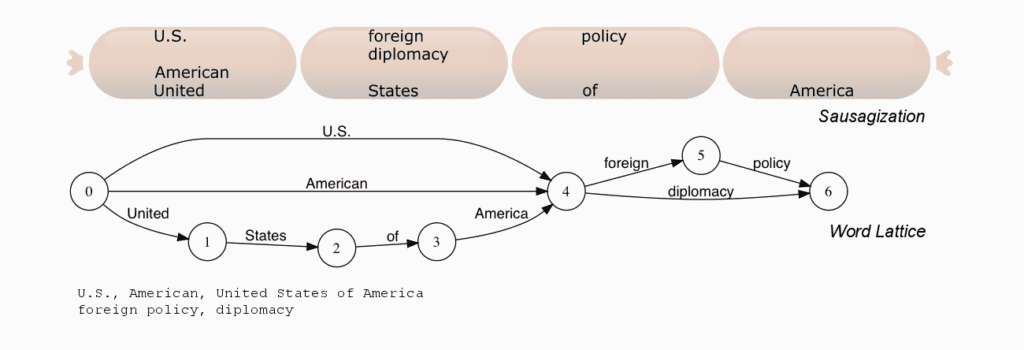
Index-time synonym expansion is an alternative to query-time expansion, but expanding synonyms at index-time has two major problems. This is where Solr managed synonyms comes in.
First, phrase queries that span expanded multi-word synonyms can fail. Because Lucene’s index format stores per-token position information to support phrase queries, but does not store position length information, multi-word synonyms can line up improperly with the surrounding words, causing some synonym-containing phrase queries that should match not to, and some that shouldn’t to improperly match. (This is called “sausagization” because of the way overlapping terms are represented – compare to the “word lattice” in the illustration at the top of this page.)
For example, if index-time synonym expansion “US, United States” is performed on a document containing the sentence “US sales increased“, it will be indexed with “United” and “US” occupying one position, and “States” and “sales” occupying the next (see below). As a result, phrase query “United States sales” will not match this document, and phrase query “United sales” will improperly match.
| Position: | 1 | 2 | 3 |
| Original: | US | sales | increased |
| Synonyms: | United | States |
Second, to modify index-time synonym expansion, you have to completely re-index. This can be a deal-breaker for indexes that take a long time to create, or for those with source access problems.
Solr History: Q: Multi-Word Query-Time Synonyms? A: No.
Solr’s query parsers have had a long-standing problem: matching multi-word synonyms at query-time hasn’t been directly possible[1]. People have gone to considerable lengths[2][3][4][5] to address this problem, but none of those indirect solutions has to-date been incorporated in Solr, so adoptees have been forced to deal with choppy upgrade paths.
The Cause: Query Parsers Split on Whitespace
At the root of the problem is a parsing strategy employed by Solr’s query parsers: before it’s sent to be analyzed, the query text is first split on whitespace. For example, when processing the query “United States“, text analysis components will only see one word at a time: first “United“, and then in a separate analysis session, “States“. When a synonym filter configured to include “USA” as a synonym of “United States” is invoked for each individual word in the query, neither “United” nor “States” will completely match the source synonym “United States“, so queries will never include the target synonym USA.
The Solution (Part 1): sow=false
Solr 6.5 contains a direct out-of-the-box solution: the edismax and standard/”lucene” query parsers now support the “sow” request option (short for Split On Whitespace), which when set to “false” will cause query text to be kept as a single unit when sent to the analyzer. Continuing with the example of the “United States, USA” synonym filter-containing query-time analyzer: in the following query, documents containing only “USA” will match, even though index-time synonym expansion was not performed:
http://localhost:8983/solr/mycollection/select?q=United+States&df=myfield&sow=false
Alternatively:
http://localhost:8983/solr/mycollection/select?q={!lucene sow=false df=myfield}United+States
And using edismax:
http://localhost:8983/solr/mycollection/select?q={!edismax sow=false df=myfield}United+States
Once you’ve got sow=false going, though, SynonymFilter turns out to have its own problems with improper position length handling that mirror the index-time synonym expansion issues described above.
The Solution (part 2): Query-Time SynonymGraphFilter
SynonymFilter has been deprecated in favor of SynonymGraphFilter, which properly handles position length, and generates correct graph representations of token streams containing overlapping synonyms of varying word counts.
In Solr 6.6, the example schemas shipped with Solr will have solr.SynonymGraphFilterFactory everywhere solr.SynonymFilterFactory used to be. In the meantime, you’ll have to change your field types to perform synonym expansion only at query time, e.g.:
<fieldType name="text_general" class="solr.TextField"
positionIncrementGap="100" multiValued="true">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="stopwords.txt"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StopFilterFactory" ignoreCase="true"
words="stopwords.txt"/>
<filter class="solr.SynonymGraphFilterFactory" synonyms="synonyms.txt"
ignoreCase="true" expand="true"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
The Solution (part 3): Graph-aware QueryBuilder
Lucene query building infrastructure, used by Solr’s query parsers, has been upgraded to auto-detect graph token streams, e.g. those produced by SynonymGraphFilter, and to properly interpret them when constructing queries. This fixes another problem that multi-word synonyms have historically had in Lucene and Solr: queries were created with every possible combination of overlapping terms, which could result in unintentional matches. (See Nolan Lawson’s blog [2] for some examples of over-matching insanity if you’re curious.)
Caveats And Remaining Issues
- The dismax and complexphrase query parsers, etc. still split on whitespace and don’t support the sow=false request parameter.
- In Solr 6.5, the autoGeneratePhraseQueries=true field type option is disallowed with the sow=false request parameter, because the code to implement autoGeneratePhraseQueries=true depends on query parsers splitting on whitespace. This can be an issue with e.g. a query “wi-fi” expanded to “wi fi” via WordDelimiterFilter, or a single word converted to a multi-word synonym (and excluding the original word, i.e. using synonym filter option expand="false"). Solr 6.6 removed this prohibition, by enabling the autoGeneratePhraseQueries option for graph queries (e.g. those produced by SynonymGraphFilter), but the “wi-fi => wi fi” WordDelimiterFilter case will still be a problem.
- The sow=false request param can be used to enable all kinds of multi-word analysis processes, not just multi-word synonyms. However, in Solr 6.5, sow=false queries over a field configured to produce shingles of varying sizes via ShingleFilter will trigger graph query processing, but will improperly fail to match documents because of the way graph queries are constructed. Solr 6.5.1 introduced a new “enableGraphQueries=false” field type option that can be used with ShingleFilter to disable graph query construction, thus avoiding the problem.
- Documents with rare synonyms will score higher than those with common synonyms. This can skew hit ranking. (Though this problem is not specific to use of multi-word synonyms, query-time synonym expansion is crippled without multi-word support.) Some of the alternate multi-word query-time synonym expansion solutions[2][3][4][5] have the ability to boost synonyms separately from the original query, thus reducing the impact of rare synonyms on scoring. One workaround using OOTB Solr could be to combine a query over a field with no query-time synonym expansion, boosted higher, with a query over a copy-fielded field with query-time synonym expansion, boosted lower.
- As Doug Turnbull pointed out on the solr-user mailing list[6] (recommended reading, especially for his discussion of the limitations of the new sow=false request parameter), sow=false changes the queries edismax produces over multiple fields when any of the fields’ query-time analysis differs from the other fields’, e.g. if one field’s anlyzer removes stopwords when another field’s doesn’t. In this case, rather than a dismax-query-per-whitespace-separated-term (edismax’s behavior when sow=true), a dismax query per field is produced. This can change results in general, but quite significantly when combined with the mm (min-should-match) request parameter: since min-should-match applies per field instead of per term, missing terms in one field’s analysis won’t disqualify docs from matching. E.g. query “Terminator 100” with request param “mm=100%” against both a title (text) field and a run_length (integer) field will result in the following queries:When sow=true:
+(DisjunctionMaxQuery((title:terminator)) DisjunctionMaxQuery((run_length:[100 TO 100] | title:100)))~2When sow=false:
+DisjunctionMaxQuery((run_length:[100 TO 100] | ((title:terminator title:100)~2)))In the above scenario, when sow=true (and in versions of Solr before 6.5), “terminator” must appear in documents in order to produce a match. But when sow=false, a document can match if its run_length field is 100, even when the title does not contain “terminator”.
Summary And Recommendations
- Use query parameter sow=false with standard/”lucene” and edismax query parsers to enable query-time multi-word synonyms.
- Switch to SynonymGraphFilter in your query-time analyzer. In most cases, you won’t want to include any kind of synonym expansion in your index-time analyzer.
- Specify the expand="true" option (or leave it at the default, which is the same) to SynonymGraphFilter, so that all alternatives are added to the query.
- Be aware that when using sow=false with edismax over fields having different (enough) query-time analysis, the form of query produced will differ from that produced when sow=true; this difference can change both matching and ranking.
[1] The “simple” query parser is capable of not splitting on whitespace, thus enabling multi-word query-time synonyms, if you disable the WHITESPACE operator, e.g. using q.operators= (empty value disables all operators) – see https://cwiki.apache.org/confluence/display/solr/Other+Parsers#OtherParsers-SimpleQueryParser.
[2] Lucene/Solr Synonym-Expanding EDisMax Parser
- JIRA: https://issues.apache.org/jira/browse/SOLR-4381
- Blog: https://nolanlawson.com/2012/10/31/better-synonym-handling-in-solr/
- Code: https://github.com/healthonnet/hon-lucene-synonyms
[3] Auto Phrasing TokenFilter
- JIRA: https://issues.apache.org/jira/browse/SOLR-7136
- Blog #1: https://lucidworks.com/post/automatic-phrase-tokenization-improving-lucene-search-precision-by-more-precise-linguistic-analysis/
- Blog #2: https://lucidworks.com/post/solution-for-multi-term-synonyms-in-lucenesolr-using-the-auto-phrasing-tokenfilter/
- Code: https://github.com/Lucidworks/auto-phrase-tokenfilter
[4] SOLR-5379: Query-time multi-word synonym expansion
[5] The Match Query Parser
- Blog: http://opensourceconnections.com/blog/2017/01/23/our-solution-to-solr-multiterm-synonyms/
- Code: https://github.com/o19s/match-query-parser
[6] Doug Turnbull’s solr-user mailing list post “The downsides of not splitting on whitespace in edismax (the old albino elephant prob)“: http://mail-archives.apache.org/mod_mbox/lucene-solr-user/201703.mbox/%3cCALG6HL8W_cPeXCYnVKs2eSpDsTtcZ8_RbcYqWr+ZPoXwU5APPQ@mail.gmail.com%3e
Credits: Image based in part on a vector drawing from Vecteezy.com.
More on Automatic Synonym Detection
LEVEL UP: Tell the business the benefits of automatic synonym detection
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.