Clustering and Classification in Ecommerce
How retailers can use classification and clustering algorithms to increase conversions and improve the customer experience.

With 2023 in the books, ecommerce’s share of retail sales was up 6.3%, according to Mastercard SpendingPulse. This massive sales growth has correlated to a massive burst in customer behavior data. Advancements in generative AI are giving retailers unprecedented, detailed insights into customer behavior, thus allowing them to improve customer experience in various ways: product recommendations, personalized search technology, customer support, and dynamic pricing.
However, with the abundance of customer data available, retailers are faced with the challenge of effectively organizing and using this data to meet their business goals. This is where clustering and classification algorithms come into play. These machine learning techniques can help retailers make sense of their vast amounts of customer data and improve their ecommerce strategies.
When we say AI, we are talking about machine learning, a sub-field of AI that teaches machines to learn and derives insights from input data. This article will introduce two well-known machine learning techniques — classification and clustering — that have influenced the ecommerce site search domain. We’ll also introduce you to some statistical models your data scientists may use to help train the machine.
Being aware of these various models will help you understand the search technology capabilities you’ll need if precision is crucial to satisfying your customer. Being an expert in statistical models is less important than having a search technology that can support you. Think of it this way: If you are a bakery and want to offer gluten-free bread, you need to know every ingredient going into your product.
Supervised vs. Unsupervised Learning
Before we get into statistical modeling, let’s go through a few terms. Customers want the most relevant results (quality), called precision. They also want choice (quantity), which is called recall. So, the dance is between giving them many options and honing in on the most relevant ones. As a merchandiser, you must ensure your data scientists have control over the models to get the most precision.
Some of this precision and recall can be done using a strong ecommerce site search engine. But on top of that, we can see what an individual user — and other individual users in aggregate — have done historically. That lets you assess the probability that customers will buy one thing over another — and that gives you the ability to recommend.
We have two methods to teach the machine on which recommendations work and which don’t: supervised and unsupervised learning. We specify a target variable in supervised learning and then ask the machine to learn from our data.
For example, we have many photos or products containing different fashion items such as shoes, shirts, dresses, jeans, jackets, etc. We can train a supervised learning model on these photos to learn the items on each photo and then use that model to recognize those same items on new photos. Those items are the target variables that we want the model to learn. To have supervised learning, you must have clearly labeled data.
But what if you don’t? Or what if only some of your data is clearly labeled? We eliminate the idea of having a target variable and call this unsupervised learning. We’ll explain the difference between supervised and unsupervised learning further below.
Importance of Classification in Ecommerce
Purse or handbag? Sneakers or athletic shoes? Outerwear or coats? People call things different things, and in retail, the worst thing you can do is have an ecommerce site search engine deliver nothing back to a customer because they typed in an alternative word or synonym. These outputs are called discrete output variables, and we use a method called “classification” to train the computer from a series of inputs.
Teaching the machine to find all items under a specific class requires your training data to be clearly labeled. Once cleaned, you can use machine learning algorithms to train the data. Here are a few:
1 – k-Nearest Neighbors (KNN) algorithm is very simple and effective. Predictions are made for a new data point by searching the entire training set for the most similar K instances (the neighbors) and summarizing the output variable for those K instances. The biggest use case of k-Nearest Neighbors is recommender systems, in which if we know a user likes a particular item, we can recommend similar items for them.
In retail, you use this method to identify key patterns in customer purchasing behavior and subsequently increase sales and customer satisfaction by anticipating customer behavior.
2 – Decision Trees are another important classification technique for predictive modeling machine learning. The representation of the decision tree model is a binary tree. Each node represents a single input variable (x) and a split point on that variable (assuming the variable is numeric). The tree’s leaf nodes contain an output variable (y) used to make a prediction.
Predictions are made by “walking the splits of the tree” until arriving at a leaf node and outputting the class value at that leaf node. Decision trees have many real-world applications, from selecting which merchandise to shop for to choosing what outfits to wear at an office party.
3 – Logistic Regression is the go-to method when our target variable is categorical with two or more levels. Some examples are the gender of a user, the outcome of a sports game, or the person’s political affiliation.
4 – Naive Bayes model comprises two types of probabilities that can be calculated directly from your training data: 1) the probability of each class and 2) the conditional probability for each class given each x value. Once calculated, the probability model can be used to predict new data using Bayes’ Theorem.
Naive Bayes can be applied in various scenarios: marking an email as spam or not spam, forecasting the weather to be sunny or rainy, checking a customer review expressing positive or negative sentiment, and more. It is a simple yet effective method for classification tasks and is often used as a baseline model for comparison with more complex models.

Training a Data Set With Statistical Models
Say your data scientists have decided on a machine-learning algorithm for classification. What we need to do next is to train the algorithm or allow it to learn. To train the algorithm, we feed it quality data known as a training set, the set of training examples used to train our algorithms. We’ll try to predict the target variable with our machine-learning algorithms.
In a training set, the target variable is known. The machine learns by finding relationships between the features and the target variable. In the classification problem, the target variables are also called classes, and there is assumed to be a finite number of classes.
To test machine learning algorithms, we need a separate dataset from the training set, known as the test set. Initially, the program is fed the training examples; this is when the learning happens. Next, the program is fed the test set.
The class for each example from the test set is not given to the program, and the program decides which classification each example should belong to. The class that the training example belongs to is then compared to the predicted value, and we can get a sense of how accurate the algorithm is.
Importance of Clustering in Ecommerce
The clustering task is an instance of unsupervised learning that automatically forms clusters of similar things. The key difference from classification is that we know what we are looking for in classification. That is not the case in clustering. Clustering is sometimes called unsupervised classification because it produces the same result as classification but without having predefined classes.
We can cluster almost anything, and the more similar the items are in the cluster, the better our clusters are. This notion of similarity depends on a similarity measurement. We call this unsupervised learning because we don’t have a target variable as we did in classification. Instead of telling the machine, “Predict Y for our data X,” we ask, “What can you tell me about X?”.
For instance, things that we can ask an unsupervised learning algorithm to tell us about a customer purchase dataset may include, “Based on their ZIP code, what are the 20 best geographic groups we can make out of this group of customers?” or “What 10 product items occur together most frequently in this group of customers?”
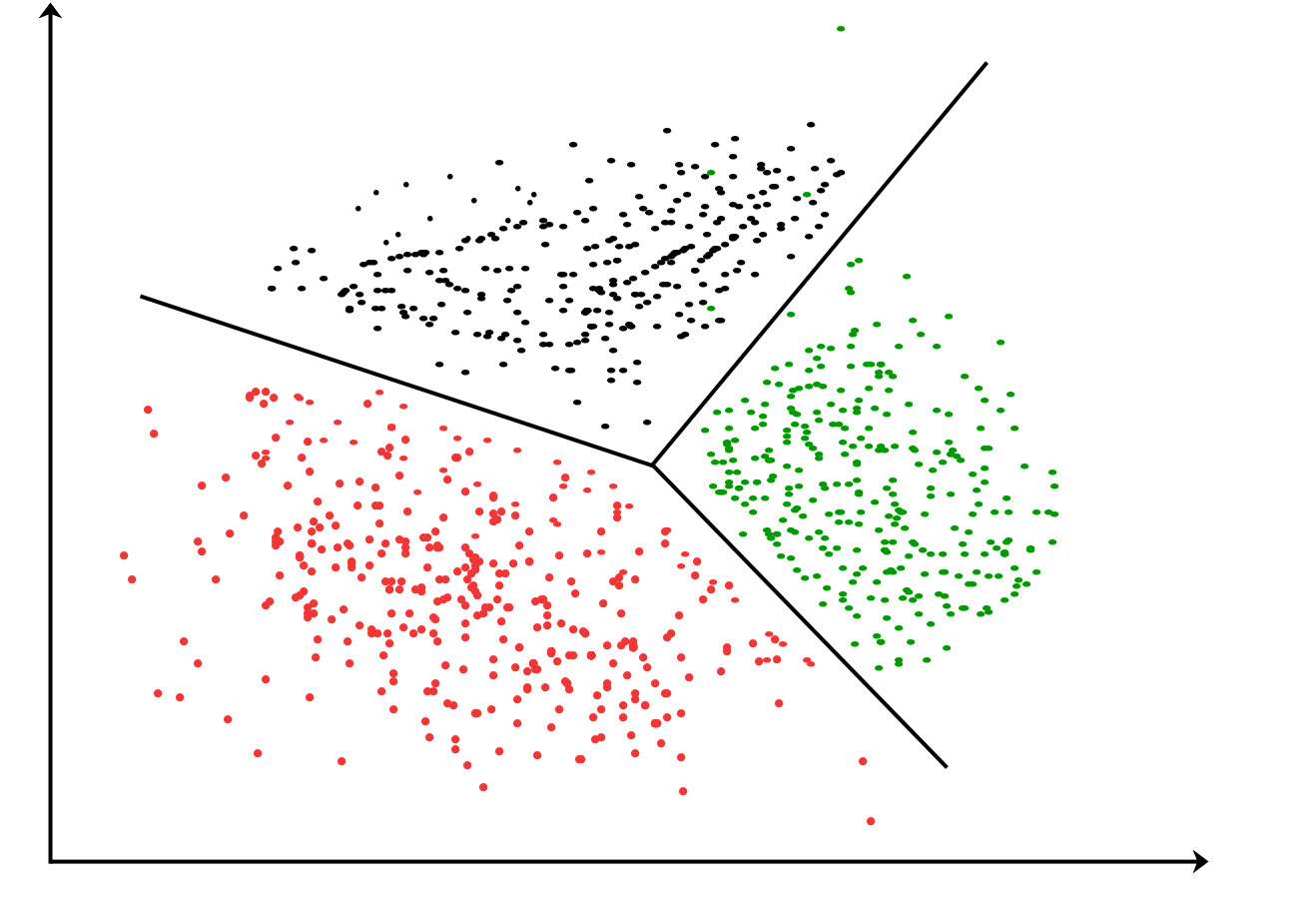
One widely used clustering algorithm is k-means, where k is a user-specified number of clusters to create. The k-means clustering algorithm starts with k-random cluster centers known as centroids.
Next, the algorithm computes the distance from every point to the cluster centers. Each point is assigned to the closest cluster center. The cluster centers are then re-calculated based on the new points in the cluster. This process is repeated until the cluster centers no longer move. This simple algorithm is quite effective but is sensitive to the initial cluster placement.
A second algorithm called bisecting k-means can be used to provide better clustering. Bisecting k-means starts with all the points in one cluster and then splits the clusters using k-means with a k of 2. The cluster with the largest error will be split in the next iteration. This process is repeated until k clusters have been created. In general, bisecting k-means creates better clusters than the original k-means does.
Ecommerce Use Case
In one of our previous posts, we suggested how Amazon could fix its recommendations by incorporating clustering to segment customers to determine if they are likely to buy something similar again. Let’s see how that can happen with a hypothetical scenario:
- Clustering: Let’s say Amazon has a dataset of all the purchase orders for 500,000 customers in the past week. The dataset has many features that can be broadly categorized into customer profiles (gender, age, ZIP code, occupation) and item profiles (types, brands, description, color). By applying the k-means clustering algorithm to this dataset, we end up with 10 different clusters. We do not know what each cluster represents at this point, so we arbitrarily call them Cluster 1, 2, 3, and so on.
- Classification: Okay, it’s time to do supervised learning. We now look at cluster 1 and use a Naive Bayes algorithm to predict the probabilities of ZIP code and item type features for all the data points. It turns out that 95% of the data in cluster 1 consists of customers who live in New York and frequently buy high-heel shoes. Awesome, let’s look at cluster 2 and use logistic regression to do binary classification on the gender and color features for all the data points. As a result, the data in cluster 2 consists of male customers obsessed with black items. If we keep doing this for all the remaining clusters, we will end up with a detailed description for each.
- Recommendation: Finally, we can recommend items to the customer, knowing they are highly relevant according to our prior segmentation analysis. We can simply use the k-Nearest Neighbor algorithm to find the recommended items. For example, customers in cluster 1 are recommended a pair of Marc New York high heels, customers in cluster 2 are recommended a black razor from Dollar Shave Club, and so on.
Supervised and unsupervised learning are two of the main machine learning approaches that power most AI applications currently deployed in ecommerce search technology. The underlying algorithms are classification for supervised learning and clustering for unsupervised learning.
You can see a fair amount of tweaking or tuning that could be done to ensure you have that optimal balance of recall and precision. And despite all the math — tuning is more akin to art. Having access to the algorithms so they can be continuously refined is key.
My next article examines how learning to rank is a key information retrieval tool that uses machine learning and is key to many web services to improve ecommerce site search engine results.
Learn More
- Read additional Retail Recommendations Across the Omnichannel
- Watch Clustering vs. Classification in AI – How Are They Different?
- Contact us for ecommerce search help
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.