Queue Based Indexing & Collection Management
As we countdown to the annual Lucene/Solr Revolution conference in Boston this October, we’re highlighting talks and sessions from past conferences. Today, we’re highlighting Devansh Dhutia’s session on how Gannet manages schema changes to large Solr collections.
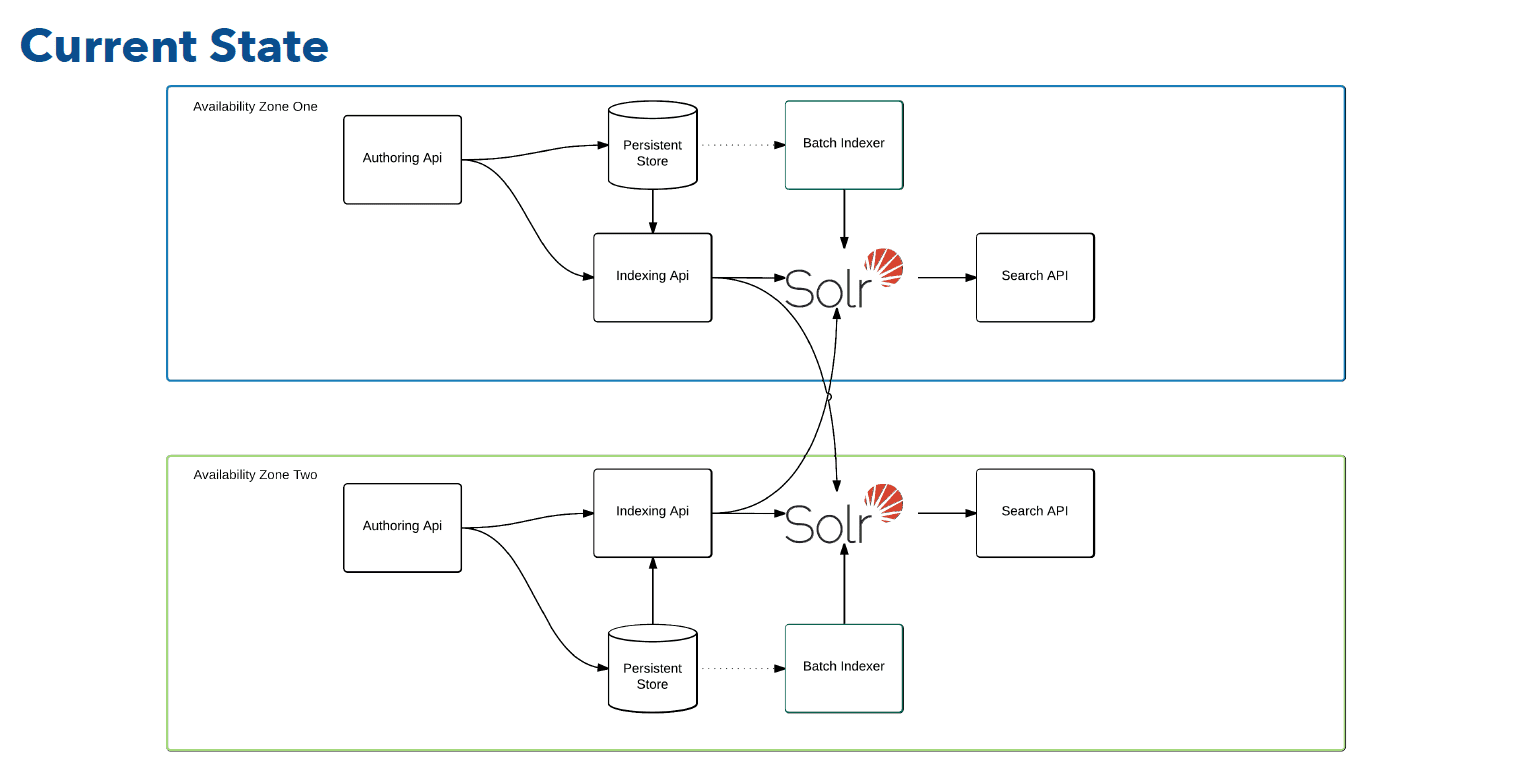
Deploying schema-changes to solr collections with large volumes of data can be problematic when the reindex activity can take almost a whole day. Keeping in mind that Gannett’s 16 million document index grows by approximately 800,000 documents per month, the status quo isn’t satisfactory. A side effect of the current architecture is that during a Solr outage, not only are all reindex activities paused, but upstream authoring engines suffer from latency issues.
This talk demonstrates how Gannett is switching to a queue based solution with creative use of collections & aliases to dramatically improve the deployment, reindex, and authoring experiences. The solution also incorporates keeping a pair of Solr clouds in geographically dispersed data centers in an eventually synchronized state.
Devansh joined the Gannett family in 2006 and has been an active contributor to Gannett’s search strategy starting with Lucene, and for the last 2 years, Solr. Devansh was one of the primary developers involved in switching Gannett from the traditional master-slave solr setup to a geo-replicated Solr Cloud environment. When Devansh isn’t working with Solr, he enjoys spending time with his wife & 3 year old daughter and trying new recipes.
![]() Join us at Lucene/Solr Revolution 2016, the biggest open source conference dedicated to Apache Lucene/Solr on October 11-14, 2016 in Boston, Massachusetts. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
Join us at Lucene/Solr Revolution 2016, the biggest open source conference dedicated to Apache Lucene/Solr on October 11-14, 2016 in Boston, Massachusetts. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.