Activate Conference Provides an Homage to Search—With AI Twist

The search and AI conference, Activate, 2018 was held last week in the birthplace of web search — Montreal. In 1989, a postgraduate student and systems administrator at McGill University named Alan Emtage architected the first web search engine, Archie. The first version exposed a simple UI and indexed FTP archives that would be searched on the search server with grep.
Figure A
Nearly 30 years later, search has come a long way. At Activate 2018, Lucidworks showed the Lucene-Solr world new Artificial Intelligence (AI) and user interfaces for managing information retrieval in an ongoing manner.
Full disclosure: I did not attend the Lucidworks conference as an employee or customer of Lucidworks — but as a software engineer who wanted to learn search from the experts. I saw the list of presenters and they looked eerily similar to many of the Lucene-Solr core contributors. Activate turned out to be chock full of some of the most influential architects and developers in search, machine learning, and natural language processing.
Experts Offer Practical Advice … & Caveats
The conference featured real practitioners — like Josh Wills, who leads search at Slack and previously worked at Google — emphasizing that models are not one-size-fits-all, and sometimes, they go stale. On a panel moderated by Grant Ingersoll, Lucidworks founder and CTO, Wills recalled a time while at Google where ads powered by machine learning started to slowly present themselves less frequently. He joked that their ad system had become “self-aware” and that the ad delivery application discovered “that it didn’t particularly like ads itself.”
He and other panelists agreed that reliance on AI can backfire when you build a system that is overly complicated, or when it leverages a model that has become obsolete.
Infer Query Intent
At Activate, we dove deep into how the latest version of Fusion allows users to enrich their data with built-in automation jobs like Logistical Regression Analysis. During the AI class, I kicked off a logistical regression classification job on a public eCommerce data set and learned that more than 20% of the queries that were classified as “Computers” were also classified as “Accessories.” This is where Fusion Server’s Phrase Extraction stood out to me.
New in Fusion 4.1, you can run a job to extract phrases from your dataset that might otherwise direct users to the wrong place. Take, for example, the query “red iPad case.” A search engine could go in a lot of directions with that query (as with most), as the results might take someone shopping for “Accessories” to “Computers.”
If iPad is boosted, there’s an even greater chance the results do not get a user to where they are trying to go. With the help of the Phrase Extraction job, and the ~ for fuzzy searching, Fusion helps you pluck out the signals that more accurately direct searchers to the information they are looking for when they search. “iPad Case”, “Case iPad,” or any combination of words that includes both “iPad” and “case” should return iPad cases first. Not iPads.
Eliminate User Errors on Phones and Tablets
Now that tablets and phones are ubiquitous, search latency’s influence on user retention has become even more important. Users on touch screens are much more error prone, with mobile device users likely to submit queries with 3 incorrect characters because the buttons are smaller.12
Mistakes though mean more processing time, or worse, slower and less helpful results. Despite this, mobile users want their search results now. Yet traditional search engines, including Solr, really struggle to handle search with an edit distance greater than 2.
In simplified terms, the edit distance equals the number of mistakes or typos in a query and it is based upon the Damerau-Levenshtein distance. Each time an original query requires an insertion, a deletion, a substitution, or a transportation of characters to form a user’s intended query, you add an increment to the edit distance.
Suppose a user looking for an iPad case were to search with “ipd xasse.” The edit distance to the target query would be 3. One for inserting “a” before “d,” one for substituting “x” for “c” in “xasse,” and a third increment of edit distance for deleting the extra “s” in the second word of the original query “casse.” Solr implements the Levenshtein algorithm for edit distance for all queries with an edit distance between 0 and 2, but for edit distances > 2, Solr gets slower.
Fusion however, can handle edit distances greater than that. Chao Han, VP of Data Science at Lucidworks, demonstrated how Fusion’s query parser can quickly handle some queries that may have been initially discovered using Fusion’s head/tail analysis.
Let’s say we found “ipd xasse” in that list of tail queries—the type of queries that do not drive a lot of user engagement. The engine powering Fusion’s head/tail analysis can suggest a rewrite, incorporate contextual information, and boost a tail to the head using the Token and Phrase Spell Correction job.
Fusion should properly rewrite “ipd xasse” for you. If it doesn’t, Fusion also provides a web interface for manually editing the Solr synonyms.txt file (Figure B). You can add the rewrite for “ipd xasse” as a synonym of “ipad case,” and subsequent instances of the query will drive users to relevant “Accessories.” Otherwise, the mobile user might go to another site to purchase an iPad case and more.
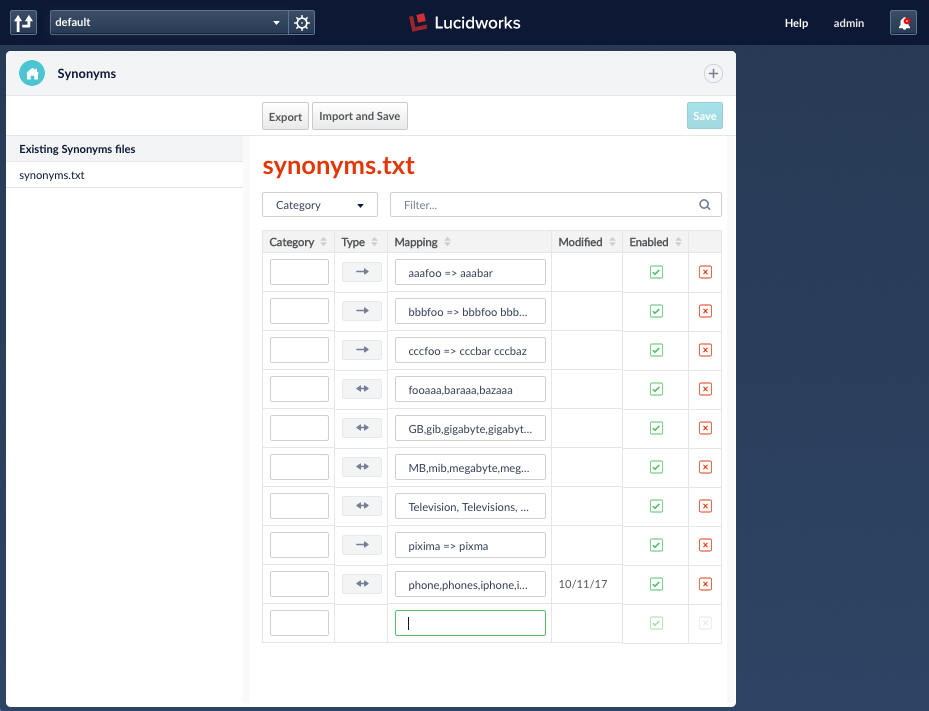
Figure B
No one should accept losing customers to competitors due to a slow mobile search experience!
Spinning Up Clusters—and Solutions
Attendees at this conference spent the week spinning up server clusters, brainstorming solutions to each others’ problems, and focusing on the details. It wasn’t a vendor self-promotion conference, though.
Regardless of your area of your organization, experience with Fusion, or your Solr knowledge, there were sessions for everyone with actionable information. Although I had been recently exploring the capabilities of Fusion through trial downloads and tutorials on the Lucidworks website, I was able to jump in the deep end upon arriving for instructor-led and TA-assisted training on Monday.
If you wanted to move fast, you could take the course materials and move at your own pace with the presentation as helpful background music. If you were new to Solr and Fusion, not especially technical, or needed to slow down, TAs (Lucidworks employees) were on-hand to help you over the hump. Everyone who attended leveled up.
Back in 1989 in Montreal, Alan Emtage’s pioneering move to bring search, a capability well known to people familiar with the command line at that time, to a user interface on the web spawned an era in computing that has radically transformed our world forever.
Today, almost every site or app has some implementation of search. Search engines serve as the homepage of the web for most internet and intranet users. In the same city 29 years later, Activate 2018 brought AI to search. I cannot say what the confluence of AI and search will mean for the next 30 years, but what a time to be alive!
Conference talks and break out session recordings are available here.
_____
1 In a study about password typos and secure correction, the IEEE found that keyboard proximity typos were proportionally higher on mobile. While Mobile OS’s tend to be good at token autocorrect, proximity typos, of course, are not caught every time in input fields. More studies are needed on the subject of mobile typos.
Chatterjee, Rahul, Anish Athayle, Devdatta Akhawe, Ari Juels, and Thomas Ristenpart. “PASSWORD TYPOS and How to Correct Them Securely.” PASSWORD TYPOS and How to Correct Them Securely – IEEE Conference Publication. August 18, 2016. Accessed October 29, 2018. https://ieeexplore.ieee.org/abstract/document/7546536.
“The problem may be exacerbated by various input device form factors, e.g., mobile phone touch keyboards.”
2Gordon, Whitson. “How to Prevent Those Annoyign Texting Typos.” Popular Science. April 05, 2018. Accessed October 29, 2018. https://www.popsci.com/prevent-texting-typos#page-2. “Phones have small screens, and we have big thumbs. This makes us inherently more prone to mistakes when we’re poking at a phone keyboard with our sausage fingers.”
_____
Marcus Eagan is a software engineer based in Palo Alto, California.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.