Approaching Join Index in Apache Lucene
How to apply join index, borrowed from RDBMS world, for addressing drawbacks of the both join approaches currently present in Lucene.
As we countdown to the annual Lucene/Solr Revolution conference in Austin this October, we’re highlighting talks and sessions from past conferences. Today, we’re highlighting Mikhail Khludnev’s session on joins and block-joins in Lucene.
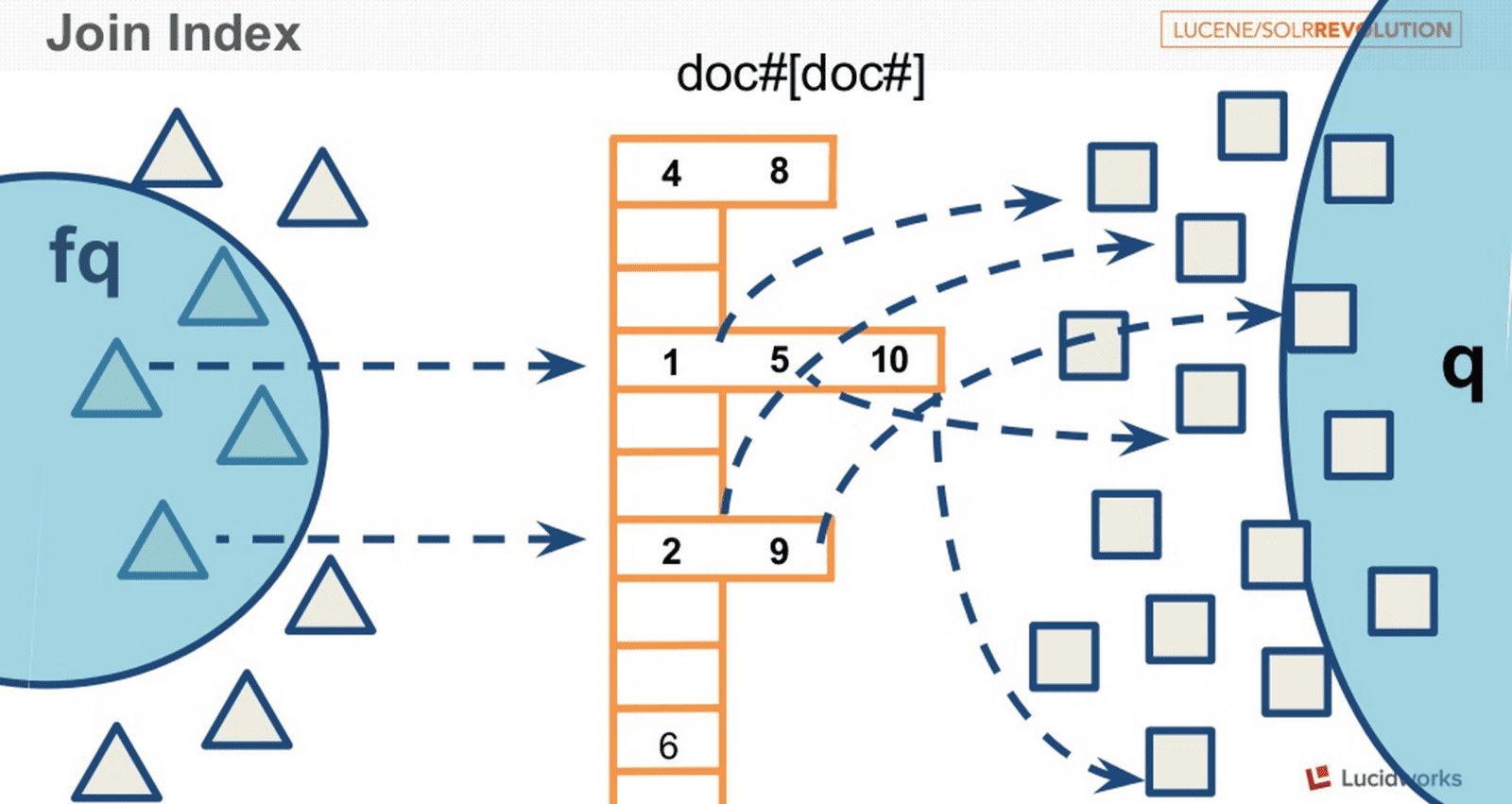
Lucene works great with independent text documents, but real life problems often require to handle relations between documents. Aside from several workarounds, like term encodings, field collapsing or term positions, we have two mainstream approaches to handle document relations: join and block-join. Both have their downsides. Join lacks performance, while block-join makes is really expensive to handle index updates, since it requires to wipe a whole block of related documents.
This session presents an attempt to apply join index, borrowed from RDBMS world, for addressing drawbacks of the both join approaches currently present in Lucene. We will look into the idea per se, possible implementation approaches, and review the benchmarking results.
Mikhail has years of experience building backend systems for retail industry. His interests span from general systems architecture, API design and performance engineering all the way to testing approaches. For last few years he works on eCommerce search platform extending Lucene and Solr, contributes back to community, spokes at Lucene Revolution and other conferences.
![]() Join us at Lucene/Solr Revolution 2015, the biggest open source conference dedicated to Apache Lucene/Solr on October 13-16, 2015 in Austin, Texas. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
Join us at Lucene/Solr Revolution 2015, the biggest open source conference dedicated to Apache Lucene/Solr on October 13-16, 2015 in Austin, Texas. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.