Document Clustering in Fusion Tutorial

Introduction
To help to better understand the underlying structure of data, exploratory data analysis (EDA) often plays a central role in the early stages of data analysis. Machine learning (ML) and statistical models make significant contributions to EDA now-a-days; however, domain experts might not have the necessary training to perform machine-learning and statistical-modeling tasks themselves.
In Fusion 3.1, we have added important machine learning features to help users make sense of their data automatically, with a minimum of setup and configuration:
- doc_clustering: an end-to-end document clustering job including doc preprocessing, separating out extreme length documents and outliers, automatic selection of the number of clusters, and extracting cluster keyword labels. You can choose between hierarchical Kmeans and standard Kmeans clustering methods.
- outlier_detection: pick out groups of outliers from whole document corpus.
- cluster_labeling: attach keyword labels for documents that already have group assignments.
These Spark modules let Fusion determine the number of clusters, detect outliers, label cluster topics, and rank representative documents—all automatically!
We have done extensive research and chosen the best set of models for practical problems in the domain of search, with flexible pipelines and good default parameter settings.
In this blog post, we demonstrate how to use Fusion to automatically generate interesting document clusters based on ecommerce product descriptions. A second demonstration uses Apache Search Hub emails (searchhub).
How to run clustering analysis in Fusion
We use an ecommerce dataset from Kaggle 1 to show how to cluster documents based on the product descriptions.
Method 1: Run job through Jobs UI in Fusion:
On the jobs configuration page (please refer to how to run jobs in Fusion), add a new “document_clustering” job and fill in the parameters such as follows:
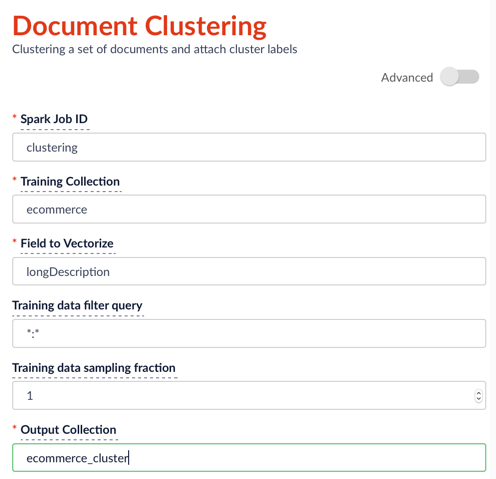
After specifying the configuration, click Run > Start. When the run finish, you will see the status Success to the left of the Start button.
Method 2: Run job using Curl commands:
Run clustering job by using the following curl command (the json configuration file is attached as clustering_job_ecommerce):
1. Upload configurations to Fusion.
curl -X POST -H "Content-Type: application/json" -d @clustering_job_ecommerce.json "localhost:8765/api/v1/spark/configurations"2. Start running the job.
curl -H "Content-Type: application/json" -X POST http://localhost:8764/api/v1/spark/jobs/clustering 3. Display status information from the log file to help debug.
tail -f var/log/api/spark-driver-default.log | grep ClusteringTask:Note: The “id” field (“id” = “clustering”) in the configuration file must match the term after http://localhost:8764/api/v1/spark/jobs/ in the second curl command (here is clustering). The “modelId” field in the configuration file is an identifier for each clustering model that is run and that will be saved in the output dataset.
When the clustering job finishes, a new dataset with additional fields (clusterIdField, clusterLabelField, freqTermField, distToCenterField) is stored in the specified collection. We explain these fields in detail later in this blog post. The user can facet on clusterIdField, clusterLabelField, freqTermField and sort on distToCenterField with ascending order. This is a screenshot of the clustering result (based on the attached configuration file) for the ecommerce dataset:
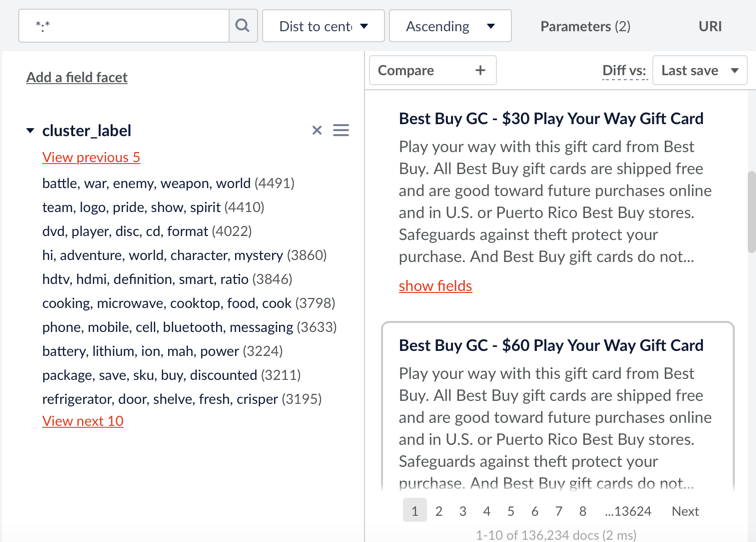
Two of the Spark job subtypes that were added in Fusion 3.1 can perform outlier detection and cluster labeling separately from the main clustering task. Please refer to the attached config json files (outlier_job, labeling_job) for reference.
If you would like to try the clustering spark job on the Search Hub dataset, a sample configuration file is provided (clustering_job_searchhub).
Clustering job goal
The goal of a document-clustering job is to group documents into clusters so that the documents in the same cluster have more similar topics than documents in different clusters. Clustering is an unsupervised machine learning task, because there is no a-priori knowledge of the cluster membership of any individual documents.
Clustering job considerations
To get quality clusters, you must consider several things regarding the clustering job:
1. Which clustering method and distance metric to use?
Fusion: We provided two Spark ML clustering methods in Fusion: Hierarchical Bisecting Kmeans 2 (“hierarchical”) and Standard Kmeans 3 (“kmeans”). The default choice is “hierarchical,” which is a mixed method between Kmeans and hierarchical clustering. It can tackle the problem of uneven cluster sizes produced by standard Kmeans, and is more robust regarding initialization. In addition, it runs much faster than the standard hierarchical-clustering method, and has fewer problems dealing with overlapping topic documents. For a distance metric, we use the Euclidian distance but normalize the distance vector to make it more similar to the Cosine distance 4.
2. How many number of clusters are there?
Fusion: Three parameters (kExact, kMin, kMax) in the configuration file determine the number of clusters. If you know exactly how many clusters there are in a dataset, then you can directly specify kExact=k chosen. Otherwise, Fusion searches through possible k from kMin to kMax.
Note: Because it is expensive to search through a large number of possible k, the algorithm only searches through possible k up to 20 times. For example, if kMin=2 and kMax=100, then the Fusion algorithm searches through 2, 7, 12, …, 100 with a step size of 5. A large kMax can increase the running time. The algorithm incurs a penalty if k is unnecessarily large. You can use the parameter kDiscount to reduce this penalty and use a larger k-chosen. However, if kMax is small (e.g., kMax<=10), then not using a discount (i.e., kDiscount=1) is recommended.
For document clustering, additional things to consider are:
3. How can I reduce the dimension and weight terms?
Fusion: Text data usually has a large number of dimensions because of the large vocabulary, which can slow down the clustering run and bring extra noise. We provide two text-vectorization methods: TFIDF 5 and Word2Vec 6. Users can trim out noisy terms for TFIDF by specifying the minDF and maxDF parameters (minimum and maximum number of documents that contain the term). Word2Vec can reduce dimensions and extract contextual information by putting co-occurring words in the same subspace. However, it can also lose some detailed information by abstraction. We have found that using a hierarchical method together with TFIDF can provide better-detailed clusters for use cases such as clustering email or product descriptions. For use cases such as novel and review clustering, several words can express similar meanings; thus Word2Vec together with standard Kmeans can perform well. (Standard Kmeans together with TFIDF might not work well for noisy data). For a large corpus dataset with a big dictionary, Word2Vec is preferred to help deal with the “curse of dimensionality”. If you assign w2vDimension an integer greater than 0, then Fusion chooses the Word2Vec method over TFIDF.
4. How to clean noisy data points?
Fusion: The clustering design in Fusion provides three layers of protection from the impact of noisy documents. In the text preprocessing steps, Fusion integrates the Lucene text analyzer with Spark 7. You can specify stopword deletion, stemming, short token treatment, and regular expressions in the analyzerConfig parameter. After text preprocessing, you can add an optional phase to separate out documents with extreme length (measured by the number of tokens). We have found that extreme-length documents can severely contaminate the clustering process. Documents with a length between shortLen and longLen are kept for clustering. One more phase that deals with noisy data is outlier detection. Fusion employs the Kmeans method to perform outlier detection. Basically, Fusion groups documents into outlierK number of clusters, then trims out clusters with a size less than outlierThreshold as outliers. Consider increasing outlierK or outlierThreshold if no outliers are detected.
5. How do I make sense of the clusters?
Fusion: After the main clustering step, Fusion adds four extra fields to the collection, to help you understand the resulting clusters. The field clusterIdField contains a unique cluster id for each document. The id number is negative for outliers and extreme-length clusters, for easy separation. The field clusterLabelField contains topic keywords that are exclusive to the particular cluster. The field freqTermField contains the most frequent keywords for each cluster. The field distToCenterField contains the Euclidian distance for the document vector to its corresponding cluster center. The smaller the distance, the more representative the document is for the cluster. The configuration parameter numKeywordsPerLabel determines the number of keywords to pick.
A streamlined workflow
Based on our thoughts about the clustering process, we have designed a streamlined workflow as follows, with parameters listed (required parameters are in bold). For detailed explanations of parameters, please refer to the spreadsheet clustering_config_para.
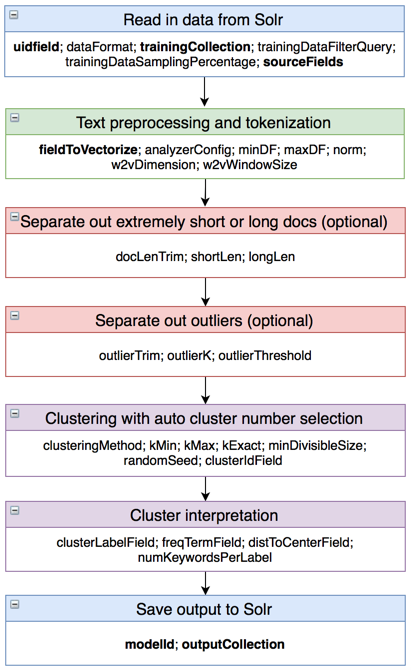
Note: For the parameters minDF, maxDF, shortLen, longLen, outlierThreshold and miniDivisibleSize, a value less than 1.0 denotes a percentage value, a value of 1.0 denotes 100%, and a value greater than 1.0 denotes the exact number. For example, minDF=5.0 means that tokens have to show up in at least 5 documents to be kept, while minDF=0.01 means that, if the 1-percentile number in the document length distribution is 6, then minDF will be assigned 6.
Conclusion
Document clustering is a powerful way to understand documents, especially during your initial analysis of your data. By leveraging the power of Spark within Fusion, both data scientists and domain experts can perform automatic clustering with a few clicks.
Attachments:
parameter explanations: clustering_config_para
configuration example for clustering product catalog: clustering_job_ecommerce
configuration example for clustering Apache emails: clustering_job_searchhub
configuration example for outlier detection: outlier_job
configuration example for labeling document groups: labeling_job
Also: Opportunities at Lucidworks!
NLP Research Engineer
We are looking for a seasoned NLP expert to help define and extend our NLP product features. As an NLP research engineer, you will research, design, experiment and prototype end-to-end solutions for NLP related problems, collaborate with consultants and customers to learn user needs, gather data and validate preliminary results, explore new machine learning/AI technologies, explore applicable ideas from academia, and collaborate with our engineering teams in putting algorithms into production.
Must haves:
- Practical experience in analytical NLP areas such as semantic parsing, knowledge based systems, QA systems, Conditional Random Field and Hidden Markov Model.
- Understanding of common machine learning algorithms and their applications to text.
- Proficient at programming in at least two of the following languages: Python/Scala/Java.
- Experience with analytical packages such as SciKit Learn/Gensim/NLTK/Spark ML.
- Strong written and verbal communication skill.
Nice to haves:
- PhD in NLP, ML or Statistics with a strong analytical background. You should be able to code up and evaluate an algorithm from scratch based on paper or ideas.
- Experience in search such as Lucene/Solr or Elasticsearch.
- Hands on experience with deep learning methods such as RNN, LSTM, GRU, Seq2Seq models.
- Good understanding of parallel computing such as Spark.
- Basic knowledge of software development tools such as git, Jenkins a plus.
Interesting in joining our team? Contact VP of R&D Chao Han at chao.han@lucidworks.com.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.