Smart Apps, Scalable Data Science, and Simplified DevOps With Fusion 5
Fusion 5 adds to its AI-powered search platform with native cloud capability, workflows for data scientists, and a visual application development suite.
We launched Fusion 1.0 in September 2014 with the belief that search represents a new paradigm in data processing, and that ranking, relevance, and contextuality are the cornerstones of all modern, AI-powered smart applications.
Since then Fusion has become the industry’s best AI-powered search platform without any limits on the volume, variety, or velocity of the data our customers wanted to process. Our customers love Fusion for its AI, security, and scale.
Now with Fusion 5 we’ve addressed the cloud, pluggable workflows for data scientists, and offer a complete visual application development suite.
You’ve been relying on Fusion to deliver hyper-personal experiences for your employees and customers. Now, Fusion 5 lets you do so with less operational burden, better productivity from data scientists, and faster time to value for building new applications.
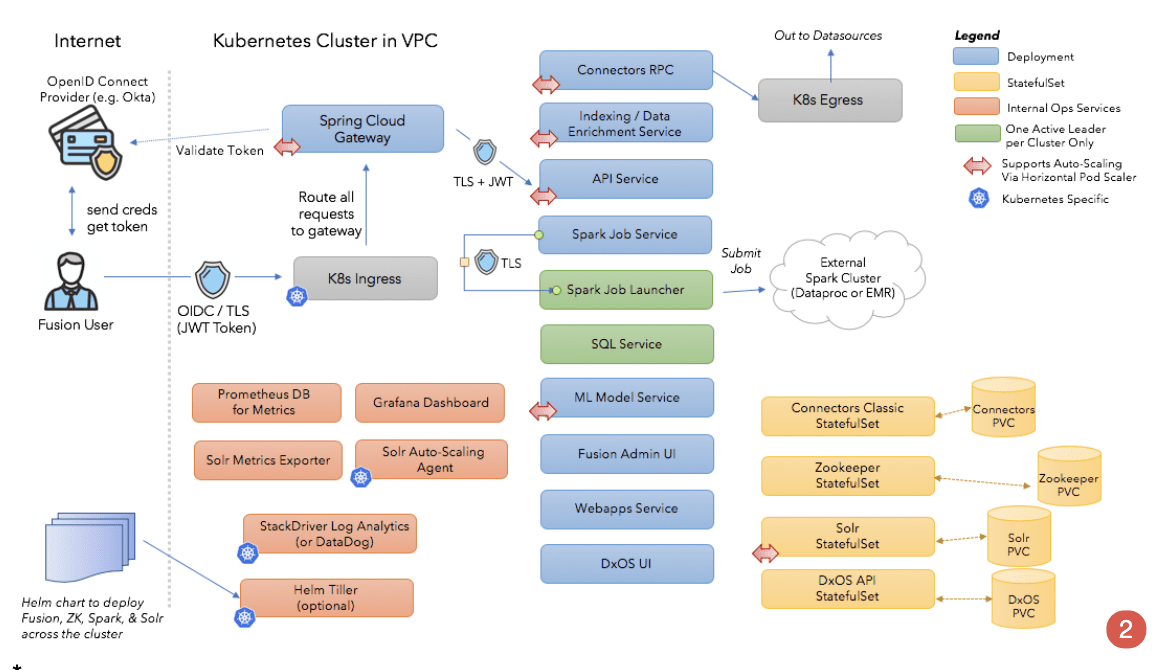
Cloud-native Microservices Architecture
Fusion 5 makes it easy for you to deploy AI-powered search applications across cloud infrastructures. Fusion 5 uses Kubernetes to orchestrate resources. With Horizontal Pod Autoscaling (HPA), customers can apply autoscaling policies to dynamically manage resources. Now customers can dramatically reduce the effort and risk of managing Fusion deployments in both private, public, and hybrid cloud infrastructures.
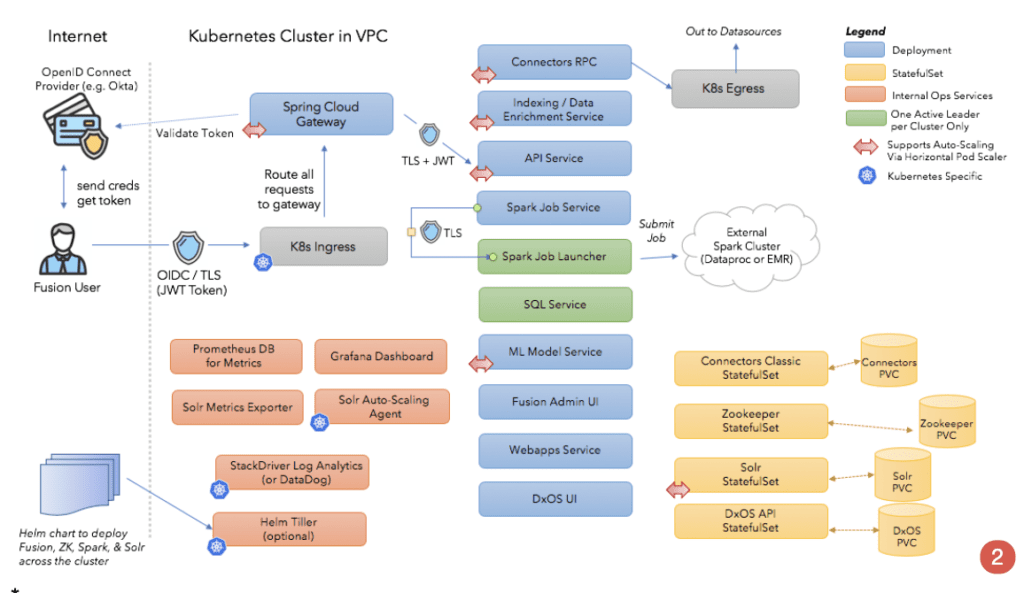
You don’t have to worry about planning and provisioning resources to deal with increased demands on resources. Fusion 5 expands capacity dynamically as new applications are brought into service or as a result of increased demand on resources from growth in usage.
As I/Os or document corpus sizes grow, Fusion automatically adds nodes and rebalances clusters letting users bring new apps online quickly and easily while avoiding unscheduled downtime or performance degradation.
Data Science Toolkit Integration Ramps Up Productivity
With Fusion, your data scientists can already make use of a variety of sophisticated AI techniques from Named Entity Recognition to Learning to Rank to recommendations and A/B testing.
Now with Fusion 5, we natively support Python machine learning models, letting data scientists use this popular programming language to use their existing models with Fusion’s index and query pipelines. With integration for TensorFlow, Scikit-learn, and spaCy, data scientists can use their familiar workflow, streamlining productivity. The result is a more agile and more responsive business with better outcomes.
Quickly Build and Deploy Powerful Apps
App Studio 5 is a complete visual application development suite that customers can use to create custom workflows and interactive dashboards.
App Studio takes care of versioning, upgrades, updates and contains sophisticated built-in workflows for reliable, rapid iterative development. Developers can now focus on the extensive UI component library, and a low-code developer IDE (integrated development environment) for building and customizing UX components without all that other overhead.
Boost, Block, or Bury With Predictive Merchandiser
If you want to curate products (or even information) you can do so now without burdening your team with cumbersome rules or impenetrable code.
Fusion’s Predictive Merchandiser empowers merchandisers to modify product placement, promote or block items from result pages, and create and visualize product rules.
With Predictive Merchandiser, users have full control over product sequencing for search results and they can visually manage synonyms, perform head and tail query analysis, and remediate underperforming queries.
The result is a dramatic increase in merchandiser productivity as it frees them up from having to manage rules and it frees IT from having to do boosts, blocks, and apply rules on behalf of business users.
tl;dr
Fusion 5 is a powerful new way of building, scaling, deploying, and managing AI-powered search apps. Digital Commerce and Digital Workplace customers can realize benefits across the board from porting their existing apps to Fusion 5 and building new applications on it.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.