Fusion, Solr, Wikipedia, and a Little Summer Fun

I love cataloging, indexing, and *finding* stuff. It started within the University of Virginia’s Alderman Library, searching 19th century art and poetry “objects” with Solr then shining the light on broader library holdings and collections with Blacklight.
(It was also during my library world adventures that I serendipitously met the future founder of Lucid Imagination, now Lucidworks, at a Lucene Summit for Libraries event.)
Powerful, useful information access runs deep within us here.
As a way to fuel ideas into effort, I thought it’d be great to see where a couple of young, fresh minds could take the world of Wikipedia data.
Meet Annie and Dean
Annie and Dean joined Lucidworks for a summer internship through the University of Virginia and industry partnership organization, HackCville, after four-week intensive curriculums in data science and software engineering. Eager, yet not really knowing what they were getting into, they bravely tackled a summer of week-by-week challenges.


Annie: software engineer intern – a UVa CS major – “excited to start Launch alongside a team of peers as well as gain mentorship from those working in startups.” “Her dream job combines projects centered around impacting the community, participating in a team setting, and a big city.” “Outside of school, Annie loves to Volunteer at the Charlottesville Health & Rehab Center and draw.”
Dean: data scientist intern – a UVa math major who joined “looking forward to the internship portion of Launch to experience working for a tech related startup” “is excited to gain a strong foundation in mathematical research through his studies. He even takes a data-driven approach to productively budget his own time, using toggl.com to track how he spends his days.”
The `the` challenge
They didn’t know Solr yet, so I gave them an intriguing challenge to kick off their internships.
Through some StackOverflowing, Unix-fu (an art all of us would do well to practice), including Python and Awk, learning XML (kids these days … don’t get schooled on what the real world looks like!), the assert was proven accurate for enwiki (English Wikipedia article dump).
Our ‘Project’
An initial technology stack learning challenge turned into a summer-long Wikipedia data fun fest.
Wikipedia: The Data
Digesting the world’s largest online encyclopedia presents a number of challenges.
- It’s large: The July 1, 2019 dump that we locked into is a 16GB highly compressed archive containing many bzipped XML file partitions.
- It’s difficult: Takes time and resources to transfer, store, and process the raw data.
- New, confusing territory: Wikipedia has a lot of history and nuanced, rich data, metadata, and metadata about the metadata.
- Template parsing trickiness: Within the XML for a Wikipedia page, alongside the page metadata, is the page text itself. The page text is a combination of free-form prose combined with special syntax for hyperlinking, along with nested templates with potentially even further templates.
Our data scientist intern tackled the challenges nobly, producing a workflow as diagrammed:

Parsing and extracting
Many Lucene and Solr wikipedia demos go only text deep ignoring or conflating metadata into a catch-all search text field. Our goal was to go a bit deeper, extracting “types” from Wikipedia infobox nested templates. The following images illustrate what this looks like on a representative Wikipedia page:
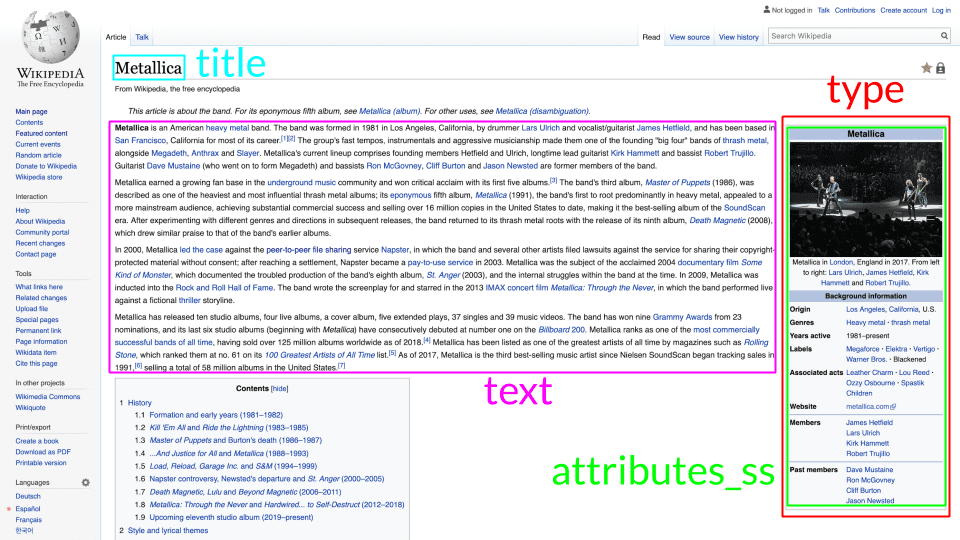
Our parser extracts infoboxes, mapping the infobox names found within a pages text to a Solr `type` field. Types/infoboxes are things like `person`, `musical_artist`, `school`, `airport`, `artist`, `river`, `mountain`, and a ton of others. Each infobox contains key/value pairs providing detail metadata about that particular infobox. For example, Metallica’s page has a `musical_artist` infobox that describes their `years_active` as “1981-present”, and their `website` as “metallica.com“, and so on.
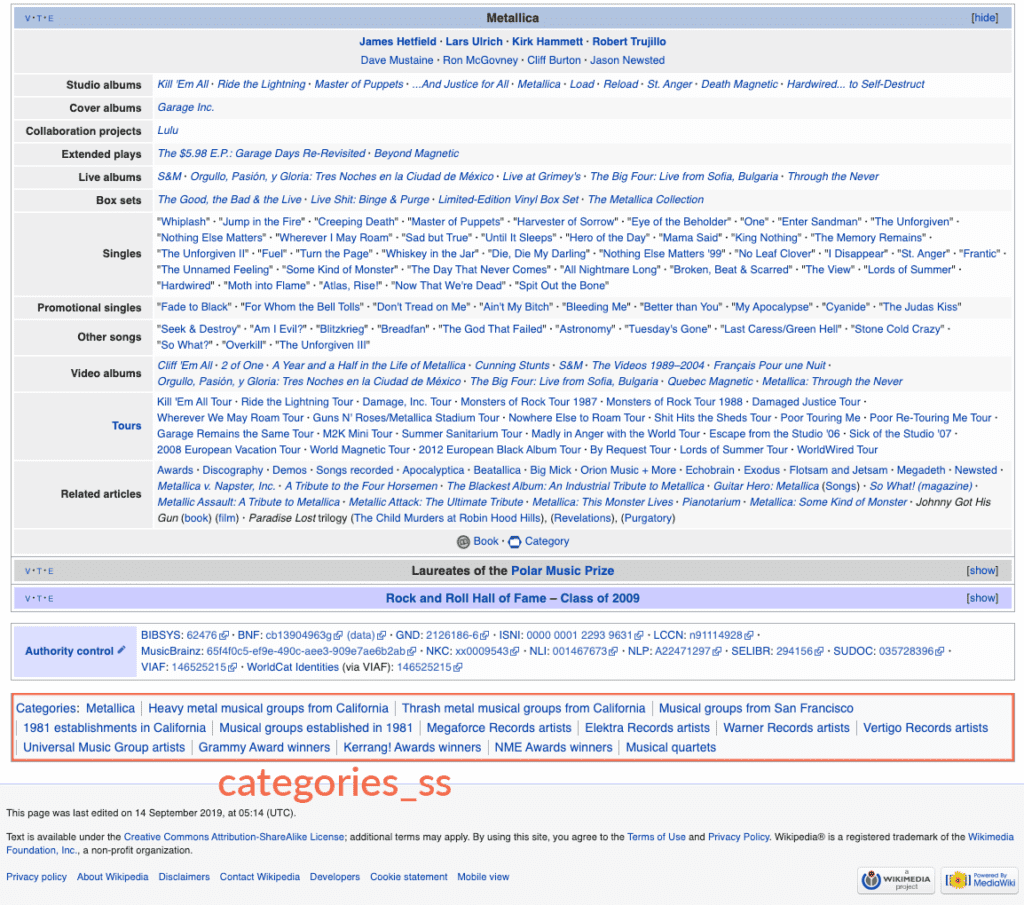
One low hanging fruit for also parsing out of the page data are the categories associated with the page. Wikipedia categories comprise various granularity types of groupings of pages such as “Heavy metal musical groups from California”, allowing easy creation of new categories and associating them with pages by the Wikipedia community.
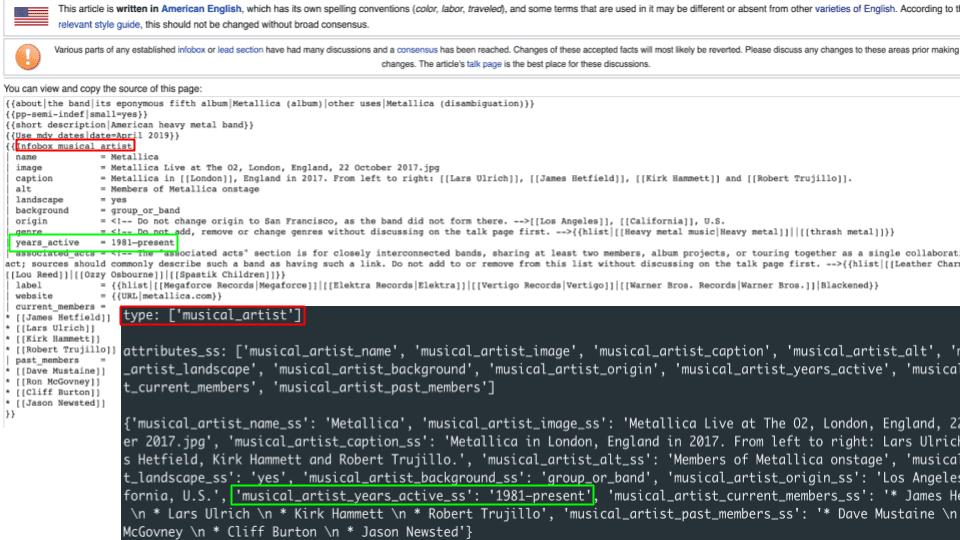
We modeled this as if each page is an “object”, indexed into Solr as a document, typed by each infobox’s name which generally represent “is-a” relationships (Metallica is-a musical_artist), with a hyper-indexed bunch of namespaced fields for each attribute for each infobox. Some pages have multiple infoboxes, for example Mount Davidson is both a `mountain` and a `park`, each having its own attributes like “mountain_elevation_ft=928” and “park_status=Open all year”.
Navigating the collection
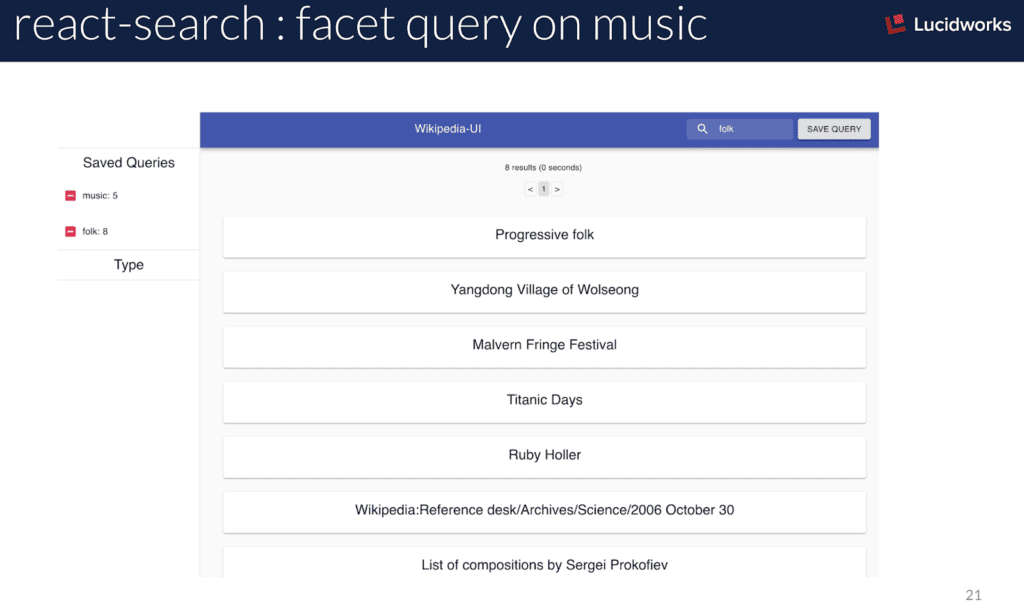
We asked our software engineer intern to create a web UI to display search results against a Fusion query pipeline. She has been learning React, so we stuck with that as the UI framework for the project. Her creative UI behaves a bit differently than traditional search and results display. Her react-search UI, without any direction on how it should behave, produces as-you-type search results and faceting. Faceting by type allows multi-select, a very intriguing way to navigate the intersections of types of Wikipedia things (“What schools are also on the National Registry of Historic Places?”; “What islands are also volcanos?”, “What rivers are also protected areas?”).
Also, queries can be saved within the apps local state and added to each query as Solr `facet.query`’s, exposing overlap cardinality of the current query with each previously saved query. Using a handful of cleverly crafted `facet.query`’s is an underrated and under-exploited feature of Solr, giving insight into various subsets in a universe of documents.
Lou learns Wikipedia
It took us the bulk of the summer to get the above described pieces developed and deployed, leaving little room to get to that wishlist “chat” integration. Using the already usable `Lou` prototype I’ve been tinkering with, it was straightforward to import a slice of our large Wikipedia collection into a `things` collection to demonstrate a couple of quick and dirty question and answer interactions:
“How tall is <mountain>?”
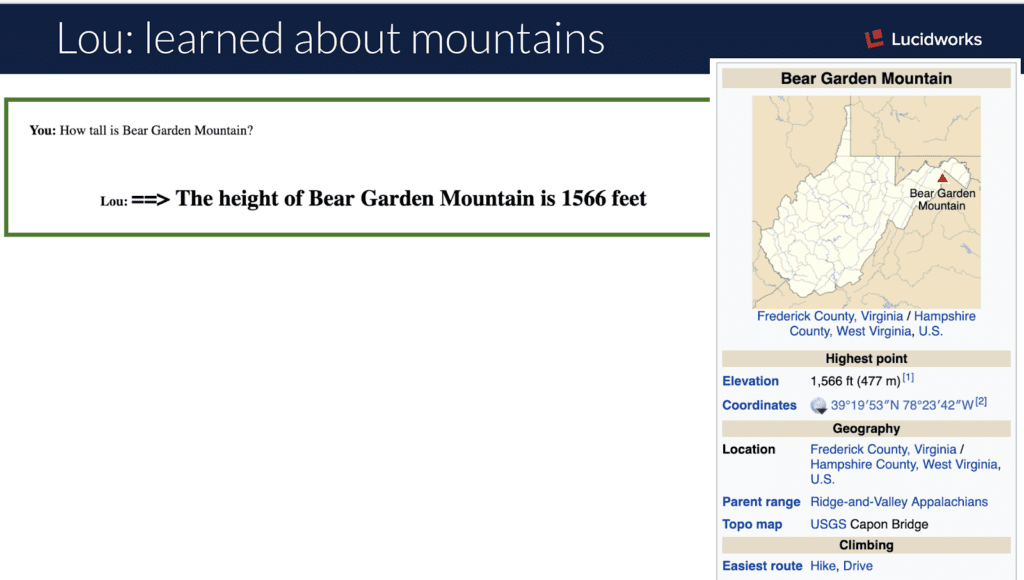
Wikipedia pages that describe mountains have a `mountain` named infobox that provides elevation information, in varying units to keep you on your toes all the way down. The Lou webapp requests to a Fusion pipeline that first tags the query, using the Solr Tagger, identifying any known `things` in the utterance. The query is then parameterized with the types of things tagged, looking up in a second Solr collection that particular generic grammar that has a response template to fill in the blanks from the actual `thing` mentioned.
“What is <scientist> known for?”

Likewise, a `scientist` infobox provides a `known_for` attribute, giving a brief description of the scientists highlights. The Solr Tagger, a little bit of JavaScript, and a slotted grammar lookup makes Lou adaptable to answer all sorts of basic questions from Wikipedia.
What’s next?
This project has broader implications than just a fun summer. Some preliminary results look promising using the extracted types as a way to explore Solr’s semantic knowledge graph relatedness() function. Given some text, like a query or utterance, what are the best types of objects? “Ascent climbing altitude” indicates `mountain` is the best type, whereas “water flow rapids” indicates `river` is the best type.
Besides type navigation and semantic bucketing, we could do the same with the categories extracted.
We haven’t begun to run machine learning jobs on the data, for categorization etc., but we’d like to.
The data itself, while hyper-structured, also has some integrity issues, and there’s more work to be done to fit types of things into a taxonomy. For example, there’s a `scientist` infobox/type, and some but not all also have a `person` infobox/type.
We have only just begun exploring this data and what it can do for us. Stay tuned as we work to get our demo systems ready for world wide availability so we can all experience a Fusion powered Wikipedia.
Best of the Month. Straight to Your Inbox!
Dive into the best content with our monthly Roundup Newsletter!
Each month, we handpick the top stories, insights, and updates to keep you in the know.