What are Pivot Facets?
Note: While the features and functionality discussed in this blog post are still available and supported in Solr, new users are encouraged to instead use the JSON Facet API to achieve similar results. Although it’s accuracy in distributed collections was somewhat limited when first introduced in Solr 5.0, the JSON Facet API supports a broader set of features (including the ability to sort on nested stats functions). With the additions of (two-phase) refinement support in Solr 7.0, and configurable overrefine added in 7.5, there are virtually no reasons for users to start using facet.pivot or stats.field.
Solr 4.10 will be released any minute now, and with it comes the much requested distributed query support for Pivot Faceting (aka: SOLR-2894). Today we have a special guest post from 4 folks at CareerBuilder who helped make distributed Pivot Faceting a reality: Trey Grainger, Brett Lucey, Andrew Muldowney, and Chris Russell.
What are Pivot Facets?
If you’ve used Lucene / Solr in the past, you are most likely familiar with faceting, which provides the ability to see the aggregate counts of search results broken down by a specific category (often the list of values within a specific field). For example, if you were running a search for restaurants (example docs), you could get a list of top 3 cities with restaurants boasting 4- or 5-star ratings with the following request:
Query:
/select?q=*:*
&fq=rating:[4 TO 5]
&facet=true
&facet.limit=3
&facet.mincount=1
&facet.field=city
Results:
{ ...
"facet_counts":{
...
"facet_fields":{
"city":[
"Atlanta",4,
"Chicago",3,
"New York City",3]}
... }
This is a very fast and flexible way to provide real-time analytics (with ad hoc querying abilities through the use of keywords), but in any reasonably-sophisticated analytics system you will want to analyze your data in multiple dimensions. With the release of Solr 4.0, a new feature was introduced which allowed not just breaking down the values by a single facet category, but also by any additional sub-categories. Using our restaurants example, let’s say we wanted to see how many 4- and 5-star restaurants exist in the top cities, in the top 3 U.S. states. We can accomplish this through the following request (example taken from Solr in Action):
Query:
/select?q=*:*
&fq=rating:[4 TO 5]
&facet=true
&facet.limit=3
&facet.pivot.mincount=1
&facet.pivot=state,city,rating
Results:
{ ...
"facet_counts":{
...
"facet_pivot":{
"state,city,rating":[{
"field":"state",
"value":"GA",
"count":4,
"pivot":[{
"field":"city",
"value":"Atlanta",
"count":4,
"pivot":[{
"field":"rating",
"value":4,
"count":2},
{
"field":"rating",
"value":5,
"count":2}]}]},
{
"field":"state",
"value":"IL",
"count":3,
"pivot":[{
"field":"city",
"value":"Chicago",
"count":3,
"pivot":[{
"field":"rating",
"value":4,
"count":2},
{
"field":"rating",
"value":5,
"count":1}]}]},
{
"field":"state",
"value":"NY",
"count":3,
"pivot":[{
"field":"city",
"value":"New York City",
"count":3,
"pivot":[{
"field":"rating",
"value":5,
"count":2},
{
"field":"rating",
"value":4,
"count":1}]}]}
... ]}}}
This example demonstrates a three-level Pivot Facet, as defined by the “facet.pivot=state,city,rating” parameter. This allows for interesting analytics capabilities in a single request without requiring you to re-execute the query multiple times to generate facet counts for each level. If you were searching an index of social networking profiles instead of restaurant reviews, you might instead break documents down by categories like gender, school, school degree, or even a company or job title. By being able to pivot on each of these different kinds of information, you can uncover a wealth of knowledge through exploring the aggregate relationships between your documents.
For full documentation on how to use Pivot Faceting in Solr (including supported request parameters and additional examples), checkout the Pivot Faceting section in the Solr Reference Guide.
Implementing “Distributed” Pivot Faceting Support
Faceting in a distributed environment is very complex. Even though Pivot Faceting has been supported in Solr for almost 2 years (since Solr 4.0), it has taken a significant amount of additional engineering to get it working in a distributed environment (like SolrCloud). Here’s a bit of the history of the feature, along with details on the technical implementation for those who are interested in a deeper understanding of the internals.
History
Pivot Faceting began life as SOLR-792, Erik Hatcher wrote the original code to present hierarchical facets in non-distributed environments, which was released in Solr 4.0. This work was later expanded into SOLR-2894 to deal specifically with distributed environments like SolrCloud.
Needing this capability for some of CareerBuilder’s data analytics products, Chris Russell took a stab at applying and integrating an early community-generated version patch. After getting the patch working on CareerBuilder’s version of Solr, the team found that distributed environment support was missing a key feature: the available patch understood the need to merge responses from distributed shards, but it had no code to deal with “refinement” requests to ensure accurate aggregate results were returned. Trey Grainger and Chris Russell began architecting a scalable solution for supporting nested faceting refinement requests, and they eventually handed off his work to Andrew Muldowney to continue implementing. Andrew pulled through the refinement work, getting the patch to a point where it worked accurately in a distributed Solr configuration – albeit slowly.
As CareerBuilder’s demands on this patch increased, we pulled in Brett Lucey to take up the task of improving performance. Brett optimized the refinement logic and data structures to ultimately improve performance by 80x. At this point, Chris Hostetter took up the SOLR-2894 mantle and created a robust test suite which uncovered several bugs that were fixed by the team at CareerBuilder.
The Challenge
Before we get into the details of the implementation, here are some useful terms to be familiar with for the discussion:
- Term – A specific value from a field
- Limit – Maximum number of terms to be returned
- Offset – The number of top facet values to skip in the response (just like paging through search results and choosing an offset of 51 to start on page 2 when showing 50 results per page)
- Shard – A searchable partition of documents (represented as a Solr “core”) containing a subset of a collection’s index
- Refinement – The act of asking individual shards for the counts of specific terms that they did not originally return, but which were returned from one or more other shards and subsequently need to be retrieved from all shards for accurate processing. In the context of Distributed Pivot Faceting which contain nested facet levels, the “term” will include a list of parent constraints for any previously processed levels.
When a distributed request is received, the request is distributed across multiple shards, each containing a parition of the collection’s index. Since each shard has a different subset of the index, each shard will respond with the answer that is locally correct based only upon its own data. Work must then be done to collate all these locally correct answers and determine what is globally correct in aggregate, across the entire collection of shards. This process (known as refinement) requires asking each shard for counts of specific terms found in other shards.
In traditional single-level faceting there is only one round of refinement. The collated response is examined to determine which terms need to be refined and the requests are sent. Once those requests are answered the collation now has perfect information for the facet values. This is not true for Pivot Facets, however: while each level of a Pivot Facet is only refined once, the information retrieved from those refinements can – and often does – change the terms being examined for refinement on the subsequent levels, which means we need to store the state of values which come back from each shard and intelligently issue refinement requests as needed to calculate accurate numbers for each level. This requires a lot more work. Pivot faceting is expensive: refinement on a multi-tier facet can take a lot of time. We invested quite heavily in getting the right data structures in place to make this process as fast as possible.
The Implementation
When a Distributed Pivot Faceting request is received, the original query is massaged before being passed along to each shard in the Solr collection. During this massaging, the limit is increased by the offset and then the offset is removed from the query. The limit is then increased, or over-requested, in an attempt to minimize refinement (because if we get all the top values back in the first request, there is no need for an additional refinement request for that level).
We now need to keep a complete record of each shard’s response: each shard’s response is saved in an array, and a combined response from all shards is also saved. The combined response is then inspected, and candidates for possible refinement are selected. Refinement candidates fall into two categories: terms within the limit specified and terms that could possibly be within the limit if refined. To determine if a term might fall within the limit if refined, we inspect each shard’s count for the given term. If any shard does not have a count for that term, we then take the lowest count returned by that shard for the respective field. The reason for this is simple: that count is the highest the shard could return for the particular term. If the combined count for the value is large enough that it would be within the limit, we then refine on it. Because each successive level is highly dependent on the refinement of the preceding level, we do not move to subsequent levels until all of the preceding level’s refinement requests have been answered. After each level has been refined, the combined result is trimmed; correct limits and offsets are applied to each level and the combined result is converted to the proper output format to be returned.
Making use of Distributed Pivot Faceting
How does CareerBuilder make use of Distributed Pivot Faceting?
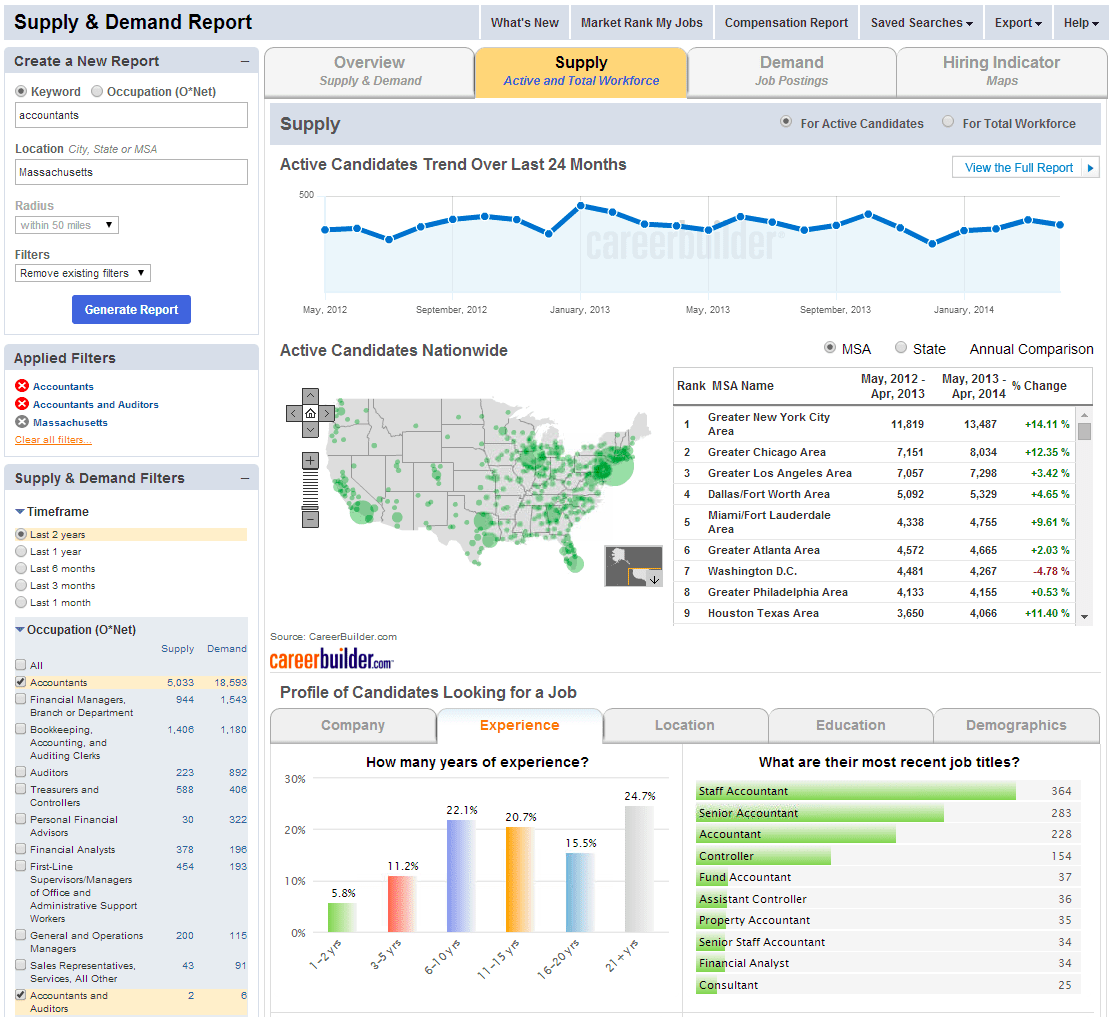
Our primary use case is to power CareerBuilder’s Supply & Demand and Compensation data analytics products, which provide deep insights into labor market data. For example, when someone searches for “accountant” (or any other keyword query), we execute a search across a collection of resumes (supply) and a collection of jobs (demand) and facet on the resulting data. We might facet first by a field representing the collection (“supply” or “demand”), and then pivot on interesting information in that data (e.g.. years experience, locations, educational level, etc.). Below is a screenshot of our Supply & Demand product demonstrating labor market trends for accountants in Massachusetts:
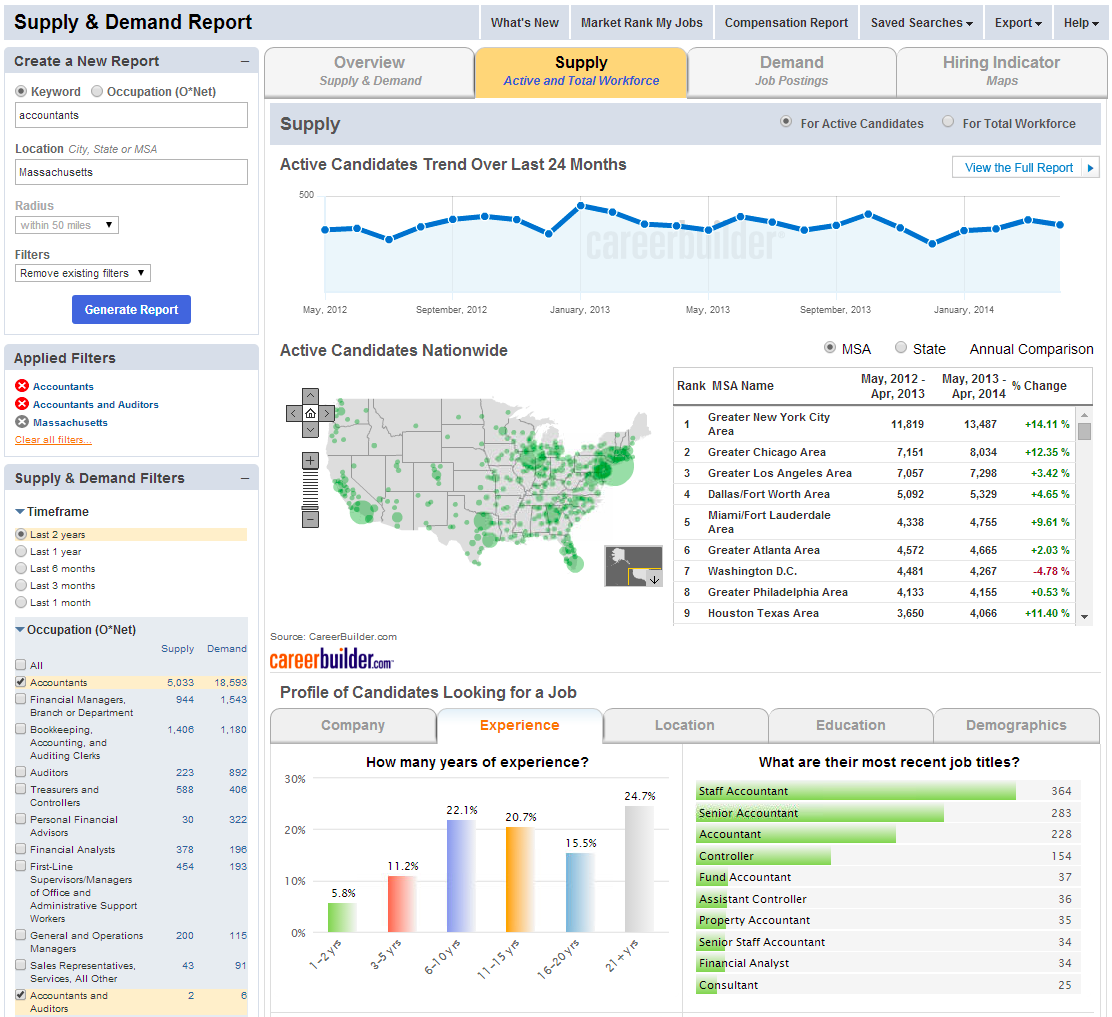
At CareerBuilder, we go a step further and pair Distributed Pivot Faceting with SOLR-3583 in order to get percentiles and other statistics on each level of pivoting. For example, we might facet on “supply” data, pivot on “education level” and then get the percentile statistics (25th, 50th, 75th, etc.) on the salary range for job seekers who fall into that category. Here is an example of how we make use of this data in our Compensation Portal for reporting on labor market compensation trends:
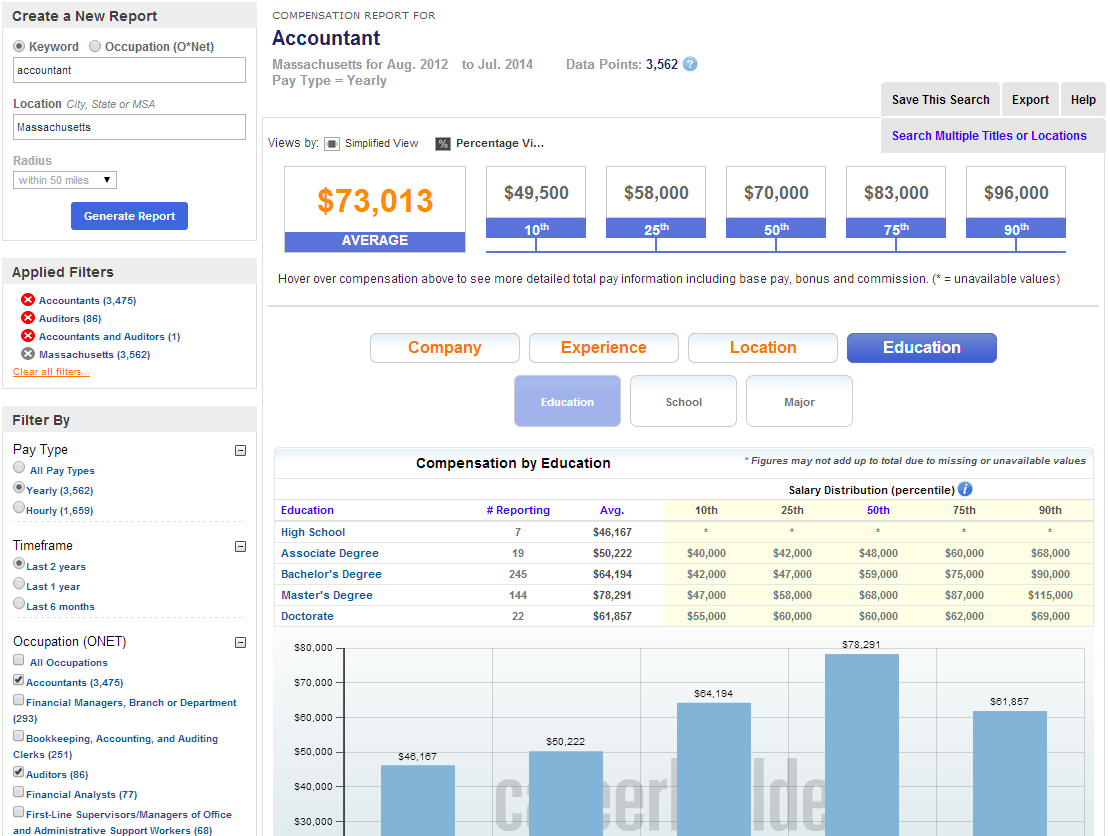
Below is a slide from a talk on our use of Solr for analytics at Lucene Revolution 2013 in which Trey Grainger describes how we make use of these kinds of statistics along with Distributed Pivot Faceting (see minutes 21:30 to 26:00 in the video or slides 41-42):

The SOLR-3583 distributed pivot statistics patch has not been committed to Solr, but readers can investigate it if they have a similar use case. An improved version of SOLR-3583 is currently under development (SOLR-6350 + SOLR-6351) which will likely replace SOLR-3583 in the future. (EDIT 2015-05-20: Pivot Statistics was added in Solr 5.1, and percentile support was added in Solr 5.2 — see the Solr Reference Guide for more details)
What are the current limitations of Distributed Pivot Faceting?
facet.pivot.mincount=0doesn’t work well in Distributed Pivot Faceting. (SOLR-6329)- Pivot Faceting (whether distributed or not) only supports faceting on field values (SOLR-6353)
- Distributed Pivot Faceting may not work well with some custom FieldTypes. (SOLR-6330)
- Using
facet.*parameters as local params inside of facet.field causes problems in distributed search. (SOLR-6193)
How scalable is Distributed Pivot Faceting?
In general, Pivot Faceting can be expensive. Even on a single non-distributed Solr search, if you aren’t careful about setting appropriate facet.limit parameters at each level of your Pivot Facet, the number of dimensions you are requesting back can grow exponentially and quickly run you out of system resources (creating memory and garbage collection issues). This is particularly true if you set your facet.limit=-1 on a field with many unique values. That being said, when you use the feature responsibly, having the distributed support really enables you to build powerful, scalable analytics products on top of Solr. At CareerBuilder, we have utilized the Distributed Pivot Facet feature successfully on a cluster containing hundreds of millions of full-text documents (jobs and resumes) spread across almost 150 shards with sub-second response times, which is very efficient given the amount of data and processing involved.
With Distributed Pivot Faceting support now in place, there are several exciting new features which we believe will finally be able to see the light of day in Solr. In particular, it should soon be possible to combine different facet types at each level (currently Pivot Facets only support faceting on field values, not functions or ranges), and to also provide additional meta information such as statistics (sums, averages, percentiles, etc.) at each facet level. It is a really exciting time for Solr as it moves towards providing a very robust suite of real-time analytics capabilities which are already being used to power cutting-edge products throughout the marketplace.
Thanks again to Trey, Brett, Andrew, Chris, and their co-workers at CareerBuilder — both for the work they did on this patch, as well as for writing & editing this great article on how Pivot Faceting works, and how it can be used.
-Hoss
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.