Evolving the Optimal Relevancy Scoring Model at Dice.com
Dice.com's Simon Hughes' talk, "Evolving the Optimal Relevancy Scoring Model at Dice.com".
As we countdown to the annual Lucene/Solr Revolution conference in Las Vegas next month, we’re highlighting talks and sessions from past conferences. Today, we’re highlighting Dice.com’s Simon Hughes’ talk, “Evolving the Optimal Relevancy Scoring Model at Dice.com”.
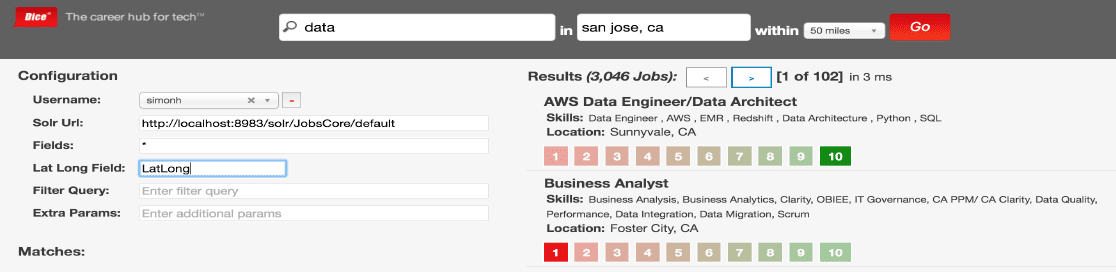
A popular conference topic in recent years is using machine learned ranking (MLR) to re-rank the top results of a Solr query to improve relevancy. However, such approaches fail to first ensure that they have the optimal query configuration for their search engine, without which the re-ranked results may fail to contain the most relevant items for each query (lowering recall). Solr offers many configuration options to control how documents are ranked and scored in terms of relevancy to a user’s query, including what boosts to assign to each field, and how strongly to boost phrasal matches. It is common for companies to manually tune these parameters to optimize relevancy, but this process is highly subjective and not guaranteed to produce the optimal results. We will show a data-driven approach to relevancy tuning that uses optimization algorithms, such as evolutionary algorithms, to evolve a query configuration that optimizes the relevancy of the results returned using data captured from our query logs. We will also discuss how we experimented with evolving a custom similarity algorithm to out-perform BM25 and tf.idf similarity on our dataset. Finally, we’ll discuss the dangers of positive feedback loops when training machine learned ranking models.
![]() Join us at Lucene/Solr Revolution 2017, the biggest open source conference dedicated to Apache Lucene/Solr on September 12-15, 2017 in Las Vegas, Nevada. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
Join us at Lucene/Solr Revolution 2017, the biggest open source conference dedicated to Apache Lucene/Solr on September 12-15, 2017 in Las Vegas, Nevada. Come meet and network with the thought leaders building and deploying Lucene/Solr open source search technology. Full details and registration…
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.