Running Solr With Etcd: SolrCloud Without Zookeeper?
Not a recommendation. Still experimenting. Not rigorously tested. Help needed. Intimidated.
Last week, while I was re-reading our blog post, Apache Solr with Kubernetes, I started thinking about the possibility of repurposing Kubernetes to handle service discovery for Solr instead of using ZooKeeper. After all, Kubernetes (via etcd) and ZooKeeper seem to do a lot of the same things. Could etcd perhaps make Solr run leaner and faster?
The idea of abandoning ZooKeeper is a little disconcerting, though. Anyone who comes from the Solr world will tell you if you are trying to run a Solr cluster without ZooKeeper, “Good luck!” ZooKeeper and Solr are tightly coupled. I heard this sentiment from some of the top Solr engineers on earth and the guys that said it are usually right.
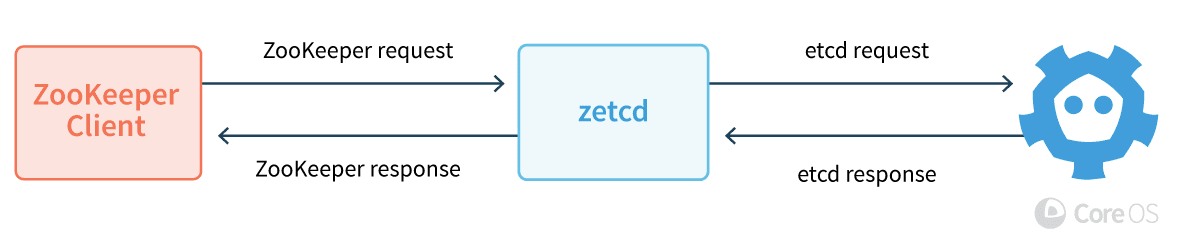
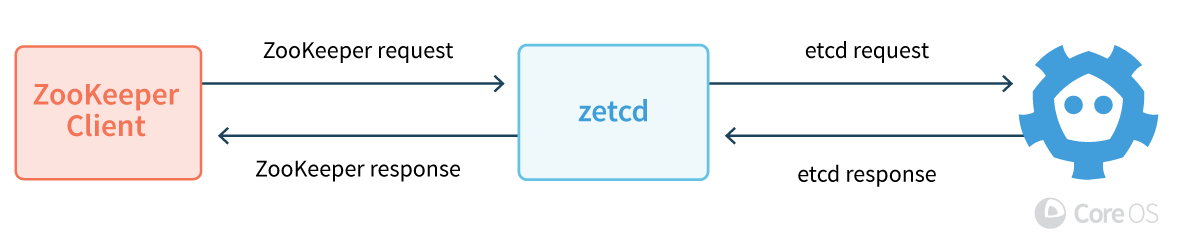
But I started thinking about using etcd – which is the service discovery component of Kubernetes. What if there was a ZooKeeper-like API for Solr to talk to etcd without a whole lot of rework? Lucky for all of us, someone else already thought of that and created it, the kind folks at etc-io (formerly CoreOS). They’ve created a library called zetcd allowing applications to serve the ZooKeeper APIs, but backed with an etcd cluster. Here’s how the etc-io team describes zetcd:
The zetcd proxy sits in front of an etcd cluster and serves an emulated ZooKeeper client port, letting unmodified ZooKeeper applications run on top of etcd. At a high level, zetcd ingests ZooKeeper client requests, fits them to etcd’s data model and API, issues the requests to etcd, then returns translated responses back to the client. The proxy’s performance is competitive with ZooKeeper proper and simplifies ZooKeeper cluster management with etcd features and tooling.
It was shockingly simple to run Solr with zetcd.
How to Run Solr With Zetcd
Here’s all you need to do to start zetcd (the ZooKeeper-like layer on top of etcd in Kubernetes):
Environment Setup
You’ll need to have Go installed and the environment variables setup. If not, there’s an example below in Step 1 or reference the link in the previous sentence. If you already have Go installed, you can jump to Step 2.
Step 1 (Example on Mac OS X)
$ brew install go
$ export GOPATH="$HOME/go"
$ export PATH="$PATH:$GOPATH/bin"
Step 2
$ go get github.com/etcd-io/zetcd/cmd/zetcd
$ zetcd --zkaddr 0.0.0.0:2181 --endpoints localhost:2379
Start Solr in Standalone Mode
Step 3
Then, start Solr in Standalone mode. Here’s the cloud example:
$ bin/solr start -e cloud -z localhost:2181 -noprompt
Solr is now talking to zetcd, which is really etcd, but Solr thinks it’s talking to ZooKeeper. It’s that simple. Try it out and let me know how it goes. I am just starting to dig and have lots to learn.
Some features will not work like some of the commands you are accustomed to in the ZooKeeper CLI. Another more obvious issue is the fact that zetcd does not expose CPU and heap size. I am digging into the likely reasons for that and hope we can address them soon. Obviously, I don’t know what I don’t know yet.
I haven’t fully tested this integration, but I am trying and we expect to provide some feedback in the coming days. Any help on that front would be greatly appreciated. This evolution could be great for Solr because it will afford organizations more flexibility in terms of how they deploy the application or choose whether or not to use Solr in the first place.
Marcus Eagan is a software engineer based in Palo Alto, California and is head of Developer Advocacy for Lucidworks. Follow Marcus on Twitter @marcusforpeace.
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.