Webinar Recap: Smart Answers for Employee and Customer Support After COVID-19
Your questions answered on Smart Answers, including use cases and frequently asked questions.

The recent shift to remote work and online purchases and customer service engagements has forced businesses to meet increasing customer and employee demands without more resources. Chatbots and virtual assistants have become popular solutions for helping users self-solve, but workflow-based functionality in most tools is limiting and frustrates users.
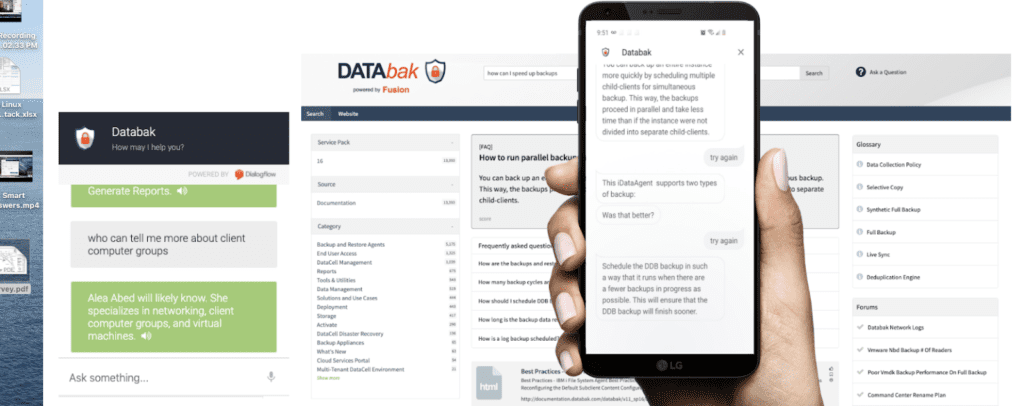
We recently launched Smart Answers, an add-on to Lucidworks Fusion that brings the power of AI-powered search to conversational frameworks. You can check out the recording of our recent webinar on the topic below, where my colleague Steven Mierop presented a detailed demo of Smart Answers integrated with Google’s Dialogflow. The demo explores a user’s experience across a spectrum of self-service interactions, from voice with a mobile app to a website chatbot, to access contextual information and answers.
Watch the webinar below, and read on for answers to questions we didn’t have time to answer during the session.

CIOs and IT Shops Ramping up for Deploying AI-Powered Conversational Frameworks
Deployment of conversational frameworks that combine chatbot or virtual assistant frontends and robust AI-powered contextual search backends are on the rise. This is where the value of Smart Answers comes in. According to Gartner research:
- “31% of CIOs have already deployed or are in short-term planning to deploy conversational platforms, up from 21% from 2018.” This is an increase of 50% year over year.
- “By 2025, customer service organizations that embed AI in their multichannel customer engagement platform will elevate operational efficiency by 25%.” AI helps deliver a cost-efficient, automated yet human experience in conversations.
Overview of Smart Answers
Smart Answers on Lucidworks Fusion brings the benefits of a scalable, AI-powered enterprise search platform to virtual assistants and chatbots. Its robust question-answering capabilities use advanced deep learning to match question/answer pairs and enable self-service for employees and customers. By increasing search and answer relevance, businesses save on the cost of answering incoming queries.These features bring traditional search relevancy development and deep learning together into an easy-to-use configuration framework that leverages Fusion’s indexing and querying pipelines.
Even if you don’t have an existing set of recorded interactions for question/answer pairs, you can still build a robust question-answering system using our cold start solution. Smart Answers improves relevancy by using deep learning (dense-vector semantic search) based on existing FAQs or documents.
Use Cases
The need for self-solve as a consumer, employee or support agent are evermore important in the current environment. The compound effects of the social distancing constraints brought by Covid19 are accelerating digital transformation efforts across the board. Allowing users to retrieve knowledge by asking questions in a natural way (which assumes many different ways) and receive the same reliable answers, is where Smart Answers shines. Below are some of the business applications our customers are implementing using Smart Answers.
CUSTOMER SUPPORT
- Call Centers: Improves Agent Effectiveness With Fast Answers & Recommendations
- Self-Service Portals: Make Chatbot Support Sessions More Interactive for Higher Resolution Rates
- Call Deflection Free Support Team To Focus On The Harder Problem
ECOMMERCE PRODUCT DISCOVERY
- Self-Service Answers at Point of Sale Improve Click-through Rates
- Easier Product Discovery Increases Add-To-Cart Rates
- Shopper Satisfaction Increases Average Order Value and Return Visits
EMPLOYEE HELP DESK SELF-SERVICE
- 1st Time Remote Workers: Help Them Find What They Need From Afar
- Digital Assistants & Chatbots: Deflect Helpdesk Tickets
- Personalized Answers: Offload Transitional Questions On Hr, Travel, and Expense Reporting Policies
Webinar Questions
Steven and I ran out of time towards the end of the webinar so we wanted to follow up on all the questions that came through during the presentation. The answers to these questions are below.
What quality metrics are you using to evaluate answers?
Business users can access model training metrics via detailed training job logs, for example, MAP, MRR, Precision, Recall). Smart Answers also offers an evaluation job for the query pipelines that output the metrics for the chosen final ranking score.
Is there a “confidence” score to tell whether the answer is “good”?
The output of the evaluation of the query pipeline job will show users the top 5 answers per question and their scores (which can be configured as an ensemble between SOLR score and Vector Similarity scores between queries and answers).
Do you have experience using interaction analytics tools as a dataset to train the model?
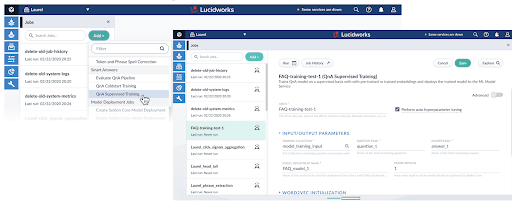
Fusion offers a capability called Data Science Toolkit Integration that allows data scientists to bring their own models to Fusion. This allows for full flexibility in building your models in the IDE of choice (like a Jupyter Notebook) and uses APIs to publish the models into Fusion. We are using the same infrastructure to support Smart Answers, however, the training experience for the Smart Answers model is only available in the low-code Job framework in Fusion Admin UI. Examples are in the screenshot below.
Is there any repetition detection in the dialog? I.e. if the user keeps asking the same thing, will it eventually give up and give a different result?
The behavior of the dialog flow can be configured with basic workflows that can have follow-up questions if a question gets repeated. This is available through traditional dialog management in chatbots frameworks that Fusion integrates with. Per the recording in the webinar, we have been able to configure key words like “Try Again” and “Is this a better answer?” directly into the dialog manager to signal to the Fusion backend that another answer is needed and if the new response meets expectations.
How much data is needed to train a model?
In general, the quality of the model is assessed on a case-by-case basis when reviewing the training results after each job. What we are seeing from experience is that a training dataset of 2,000 question/answer pairs can provide a robust generalization.
What type of model is used?
We have two types of training jobs:
- The Cold Start Training Job: used when we only have documents available for answering questions (no curated question/answer pairs in FAQs). This training job uses a Word2vec model.
- The FAQ Training Job: used when we have a dataset with curated question/answer pairs. The training job uses a neural network model.
What version of Fusion is this available with?
Smart Answers is available on Fusion 5.1 or higher.
What NLP software do you use?
We are using Python for the modeling stages and the Data Science Toolkit Integration capability in Fusion for surviving the models into the index and query pipelines. One of the areas where we have added our IP is in optimizations around model serving at millisecond speed into a query pipeline. While there are several models frameworks that can model embeddings, the focus on the speed of model serving is a differentiator for Smart Answers.
Can we control the output such that you get, just a glossary definition, or an FAQ answer, or a combination of a glossary/FAQ answer along with traditional search results as a fallback?
The strength of Smart Answers is that it is built on top of an already robust search engine. Hence we can layer keyword search, glossary definitions and FAQ based on the content of the incoming query. There is an example of this towards the end of the demonstration in the webinar.
Can we use custom parameters at tuning time?
There is a long list of parameters that can be customized at training time in the Low-Code Job framework. Please see doc for the advanced model training configuration.
Can you show us a query pipeline that’s using Smart Answers?
Please visit the query pipeline configuration details into our documentation.
Can you start with a set of known FAQs and still use the cold start methodology to find other Q/A pairs in other documents?
In the FAQ training job, there is an option to enhance the vocabulary learning by adding documents to derive custom embeddings based on the specific domain.
The cold-start methodology is designed to be a first step. Users make use of documents to train a Word2Vec model that then gets applied to the incoming queries, calculates vector similarity to a document and renders the document back as a ranked answer based on similarity. As search users input queries and click on results, those “signals” get recorded and can become training question/answer pairs for FAQ training. This way we provide an ever improving loop for the Smart Answers models.
How is the model used at index time? Special stage?
Answer: Yes! The model is served into a specific index stage for the encoding. Smart Answers comes with a default Index Pipeline. In the machine learning stage (which can be renamed as QnA Encoder for usability) users can point to the model they want to use and input the name of the field that needs to be processed.
Interested in reading more about the technology that powers self-service? Check out this blog.
Looking to connect with Lucidworks to learn more about how Smart Answers could power a better digital experience for your employees and customers? Contact us today!
LEARN MORE
Contact us today to learn how Lucidworks can help your team create powerful search and discovery applications for your customers and employees.