Dokument-Clustering in Fusion Tutorial
Einführung
Um die zugrundeliegende Struktur von Daten besser zu verstehen, spielt die explorative Datenanalyse (EDA) oft eine zentrale Rolle in den frühen Phasen der Datenanalyse. Maschinelles Lernen (ML) und statistische Modelle leisten heutzutage einen wichtigen Beitrag zur EDA. Fachexperten verfügen jedoch möglicherweise nicht über die notwendige Ausbildung, um selbst Aufgaben des maschinellen Lernens und der statistischen Modellierung durchzuführen.
In Fusion 3.1 haben wir wichtige Funktionen für das maschinelle Lernen hinzugefügt, damit Benutzer ihre Daten automatisch und mit einem Minimum an Einrichtungs- und Konfigurationsaufwand sinnvoll nutzen können:
- doc_clustering: ein durchgängiges Clustering von Dokumenten, einschließlich der Vorverarbeitung von Dokumenten, dem Herausfiltern von Dokumenten mit extremer Länge und Ausreißern, der automatischen Auswahl der Anzahl von Clustern und der Extraktion von Cluster-Schlüsselwortbezeichnungen. Sie können zwischen hierarchischen Kmeans- und Standard-Kmeans-Clustermethoden wählen.
- outlier_detection: wählt Gruppen von Ausreißern aus dem gesamten Dokumentenkorpus aus.
- cluster_labeling: fügt Schlüsselwort-Etiketten für Dokumente hinzu, die bereits Gruppenzuordnungen haben.
Mit diesen Spark-Modulen kann Fusion die Anzahl der Cluster bestimmen, Ausreißer erkennen, Clusterthemen kennzeichnen und repräsentative Dokumente einstufen – alles automatisch!
Wir haben umfangreiche Untersuchungen durchgeführt und die besten Modelle für praktische Probleme im Bereich der Suche ausgewählt, mit flexiblen Pipelines und guten Standardparametereinstellungen.
In diesem Blogbeitrag zeigen wir Ihnen, wie Sie mit Fusion automatisch interessante Dokumentencluster auf der Grundlage von E-Commerce-Produktbeschreibungen erstellen können. Eine zweite Demonstration verwendet Apache Search Hub Emails (searchhub).
So führen Sie eine Clustering-Analyse in Fusion durch
Wir verwenden einen E-Commerce-Datensatz von Kaggle 1 um zu zeigen, wie man Dokumente auf der Grundlage von Produktbeschreibungen clustert.
Methode 1: Führen Sie den Auftrag über die Benutzeroberfläche Jobs in Fusion aus:
Fügen Sie auf der Seite für die Konfiguration von Aufträgen (siehe wie man Aufträge in Fusion ausführt) einen neuen Auftrag „document_clustering“ hinzu und geben Sie die Parameter wie folgt ein:
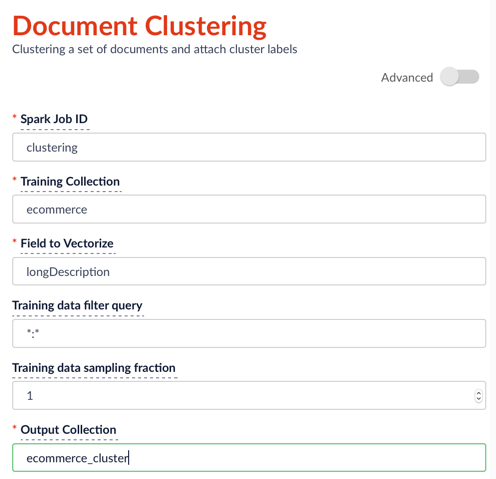
Nachdem Sie die Konfiguration festgelegt haben, klicken Sie auf Ausführen > Starten. Wenn der Lauf beendet ist, sehen Sie links neben der Schaltfläche Start den Status Erfolg.
Methode 2: Job mit Curl-Befehlen ausführen:
Führen Sie den Clustering-Job mit dem folgenden curl-Befehl aus (die json-Konfigurationsdatei ist als clustering_job_ecommerce beigefügt):
1. Laden Sie die Konfigurationen in Fusion hoch.
curl -X POST -H "Content-Type: application/json" -d @clustering_job_ecommerce.json "localhost:8765/api/v1/spark/configurations"2. Starten Sie die Ausführung des Auftrags.
curl -H "Content-Type: application/json" -X POST http://localhost:8764/api/v1/spark/jobs/clustering 3. Zeigen Sie Statusinformationen aus der Protokolldatei an, um die Fehlersuche zu erleichtern.
tail -f var/log/api/spark-driver-default.log | grep ClusteringTask:Hinweis: Das Feld „id“ („id“ = „clustering“) in der Konfigurationsdatei muss mit dem Begriff nach http://localhost:8764/api/v1/spark/jobs/ im zweiten curl-Befehl übereinstimmen (hier: clustering). Das Feld „modelId“ in der Konfigurationsdatei ist eine Kennung für jedes Clustering-Modell, das ausgeführt wird und im Ausgabedatensatz gespeichert wird.
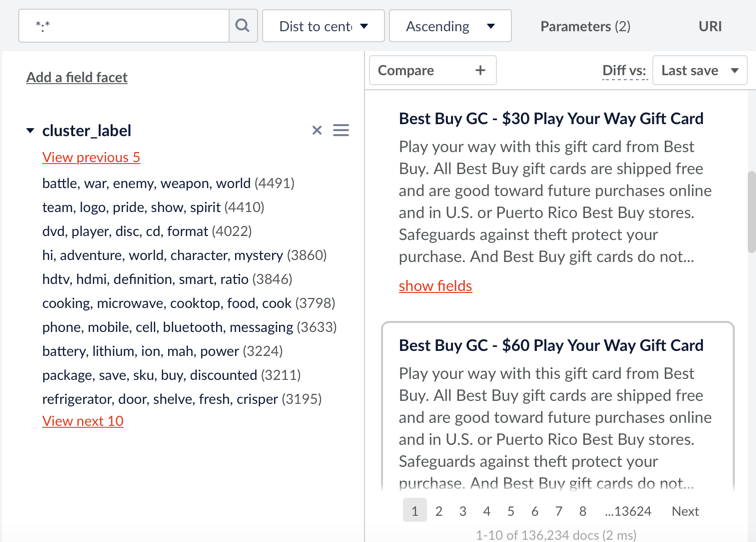
Wenn der Clustering-Auftrag abgeschlossen ist, wird ein neuer Datensatz mit zusätzlichen Feldern(clusterIdField, clusterLabelField, freqTermField, distToCenterField) in der angegebenen Sammlung gespeichert. Wir erläutern diese Felder später in diesem Blogbeitrag im Detail. Der Benutzer kann nach clusterIdField, clusterLabelField, freqTermField facettieren und nach distToCenterField in aufsteigender Reihenfolge sortieren. Dies ist ein Screenshot des Clustering-Ergebnisses (basierend auf der beigefügten Konfigurationsdatei) für den E-Commerce-Datensatz:
Zwei der Spark-Job-Subtypen, die in Fusion 3.1 hinzugefügt wurden, können Ausreißererkennung und Cluster-Beschriftung getrennt von der Haupt-Clustering-Aufgabe durchführen. Bitte sehen Sie sich die beigefügten config json-Dateien(outlier_job, labeling_job) als Referenz an.
Wenn Sie den Clustering Spark-Job mit dem Search Hub-Datensatz ausprobieren möchten, finden Sie hier eine Beispielkonfigurationsdatei(clustering_job_searchhub).
Clustering Job Ziel
Das Ziel einer Dokumenten-Clustering-Aufgabe ist es, Dokumente in Clustern zu gruppieren, so dass die Dokumente im selben Cluster mehr ähnliche Themen haben als Dokumente in verschiedenen Clustern. Clustering ist eine Aufgabe des unüberwachten maschinellen Lernens, da die Clusterzugehörigkeit der einzelnen Dokumente nicht von vornherein bekannt ist.
Überlegungen zum Clustering von Aufträgen
Um qualitativ hochwertige Cluster zu erhalten, müssen Sie beim Clustering einige Dinge beachten:
1. Welche Clustering-Methode und Distanzmetrik soll verwendet werden?
Fusion: Wir haben zwei Spark ML-Clustermethoden in Fusion bereitgestellt: Hierarchisches Bisecting Kmeans 2 („hierarchisch“) und Standard Kmeans 3 („kmeans“). Die Standardauswahl ist „hierarchisch“, eine gemischte Methode zwischen Kmeans und hierarchischem Clustering. Sie kann das Problem der ungleichmäßigen Clustergrößen lösen, das durch Standard-Kmeans entsteht, und ist robuster in Bezug auf die Initialisierung. Außerdem läuft sie viel schneller als die standardmäßige hierarchische Clustering-Methode und hat weniger Probleme mit sich überschneidenden thematischen Dokumenten. Als Abstandsmetrik verwenden wir den Euklidischen Abstand, normalisieren aber den Abstandsvektor, damit er dem Cosinus-Abstand ähnlicher wird 4.
2. Wie viele Cluster gibt es?
Fusion: Drei Parameter(kExact, kMin, kMax) in der Konfigurationsdatei bestimmen die Anzahl der Cluster. Wenn Sie genau wissen, wie viele Cluster es in einem Datensatz gibt, können Sie direkt kExact=k wählen. Andernfalls durchsucht Fusion die möglichen k von kMin bis kMax.
Hinweis: Da es teuer ist, eine große Anzahl möglicher k zu durchsuchen, durchsucht der Algorithmus mögliche k nur bis zu 20 Mal. Wenn zum Beispiel kMin=2 und kMax=100 ist, sucht der Fusion-Algorithmus 2, 7, 12, …, 100 mit einer Schrittweite von 5. Ein großes kMax kann die Laufzeit erhöhen. Der Algorithmus erleidet eine Strafe, wenn k unnötig groß ist. Sie können den Parameter kDiscount verwenden, um diese Strafe zu verringern und ein größeres k zu verwenden. Wenn kMax jedoch klein ist (z.B. kMax<=10), dann wird empfohlen, keinen Rabatt zu verwenden (d.h. kDiscount=1).
Für das Clustering von Dokumenten müssen Sie zusätzlich folgende Dinge beachten:
3. Wie kann ich die Begriffe Dimension und Gewicht reduzieren?
Fusion: Textdaten haben aufgrund des großen Vokabulars in der Regel eine große Anzahl von Dimensionen, die den Clustering-Lauf verlangsamen und zusätzliches Rauschen verursachen können. Wir bieten zwei Methoden zur Textvektorisierung an: TFIDF 5 und Word2Vec 6. Benutzer können verrauschte Begriffe für TFIDF herausfiltern, indem sie die Parameter minDF und maxDF angeben (minimale und maximale Anzahl von Dokumenten, die den Begriff enthalten). Word2Vec kann die Dimensionen reduzieren und kontextbezogene Informationen extrahieren, indem es gemeinsam vorkommende Wörter in denselben Unterraum stellt. Allerdings können durch die Abstraktion auch einige Detailinformationen verloren gehen. Wir haben festgestellt, dass die Verwendung einer hierarchischen Methode zusammen mit TFIDF für Anwendungsfälle wie das Clustern von E-Mails oder Produktbeschreibungen detailliertere Cluster liefern kann. Bei Anwendungsfällen wie dem Clustering von Romanen und Rezensionen können mehrere Wörter ähnliche Bedeutungen ausdrücken; daher kann Word2Vec zusammen mit Standard-Kmeans gute Ergebnisse erzielen. (Standard-Kmeans zusammen mit TFIDF funktioniert bei verrauschten Daten möglicherweise nicht gut). Bei einem großen Datensatz mit einem großen Wörterbuch wird Word2Vec bevorzugt, um dem „Fluch der Dimensionalität“ zu begegnen. Wenn Sie w2vDimension eine ganze Zahl größer als 0 zuweisen, dann wählt Fusion die Word2Vec-Methode gegenüber TFIDF.
4. Wie bereinigt man verrauschte Datenpunkte?
Fusion: Das Clustering-Design in Fusion bietet drei Ebenen zum Schutz vor den Auswirkungen verrauschter Dokumente. In den Schritten der Textvorverarbeitung integriert Fusion den Lucene Textanalysator mit Spark 7. Im Parameter analyzerConfig können Sie die Löschung von Stoppwörtern, Stemming, die Behandlung kurzer Token und reguläre Ausdrücke festlegen. Nach der Textvorverarbeitung können Sie eine optionale Phase hinzufügen, um Dokumente mit extremer Länge (gemessen an der Anzahl der Token) auszusondern. Wir haben festgestellt, dass Dokumente mit extremer Länge den Clustering-Prozess stark beeinträchtigen können. Dokumente mit einer Länge zwischen shortLen und longLen werden für das Clustering beibehalten. Eine weitere Phase, die sich mit verrauschten Daten befasst, ist die Ausreißererkennung. Fusion verwendet die Kmeans-Methode, um Ausreißer zu erkennen. Grundsätzlich gruppiert Fusion die Dokumente in eine Anzahl von AusreißerK Clustern und schneidet dann Cluster mit einer Größe kleiner als outlierThreshold als Ausreißer aus. Ziehen Sie in Erwägung, AusreißerK oder AusreißerSchwellenwert zu erhöhen, wenn keine Ausreißer entdeckt werden.
5. Wie kann ich die Cluster sinnvoll nutzen?
Fusion: Nach dem Hauptschritt des Clustering fügt Fusion der Sammlung vier zusätzliche Felder hinzu, damit Sie die resultierenden Cluster besser verstehen können. Das Feld clusterIdField enthält eine eindeutige Clusterkennung für jedes Dokument. Die ID-Nummer ist bei Ausreißern und Clustern mit extremer Länge negativ, um die Trennung zu erleichtern. Das Feld clusterLabelField enthält thematische Schlüsselwörter, die ausschließlich für den jeweiligen Cluster gelten. Das Feld freqTermField enthält die häufigsten Schlüsselwörter für jeden Cluster. Das Feld distToCenterField enthält den euklidischen Abstand des Dokumentvektors zu seinem entsprechenden Clusterzentrum. Je kleiner der Abstand ist, desto repräsentativer ist das Dokument für den Cluster. Der Konfigurationsparameter numKeywordsPerLabel bestimmt die Anzahl der auszuwählenden Schlüsselwörter.
Ein gestraffter Arbeitsablauf
Auf der Grundlage unserer Überlegungen zum Clustering-Prozess haben wir einen optimierten Arbeitsablauf wie folgt entworfen, wobei die Parameter aufgeführt sind (erforderliche Parameter sind fett gedruckt). Ausführliche Erläuterungen zu den Parametern finden Sie in der Tabelle clustering_config_para.
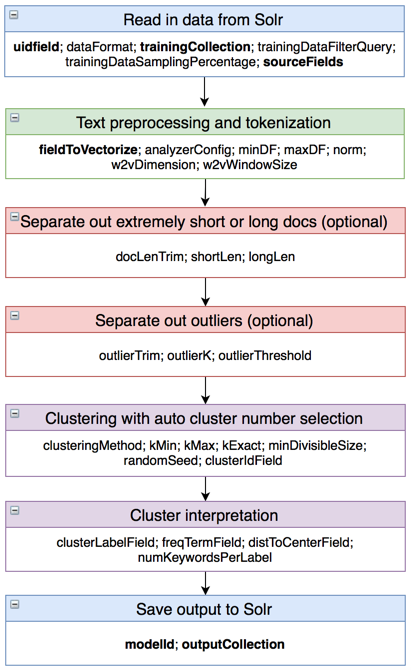
Hinweis: Bei den Parametern minDF, maxDF, shortLen, longLen, outlierThreshold und miniDivisibleSize bezeichnet ein Wert kleiner als 1.0 einen Prozentwert, ein Wert von 1.0 bedeutet 100% und ein Wert größer als 1.0 die genaue Zahl. So bedeutet z.B. minDF=5.0, dass Token in mindestens 5 Dokumenten auftauchen müssen, um beibehalten zu werden, während minDF=0.01 bedeutet, dass, wenn die 1-Perzentil-Zahl in der Dokumentenlängenverteilung 6 ist, minDF 6 zugewiesen wird.
Fazit
Das Clustering von Dokumenten ist eine leistungsstarke Methode, um Dokumente zu verstehen, insbesondere bei der ersten Analyse Ihrer Daten. Durch die Nutzung der Leistungsfähigkeit von Spark in Fusion können sowohl Datenwissenschaftler als auch Fachexperten mit wenigen Klicks ein automatisches Clustering durchführen.
Anhänge:
Parameter-Erklärungen: clustering_config_para
Konfigurationsbeispiel für Clustering-Produktkatalog: clustering_job_ecommerce
Konfigurationsbeispiel für das Clustering von Apache-E-Mails: clustering_job_searchhub
Konfigurationsbeispiel für die Ausreißererkennung: outlier_job
Konfigurationsbeispiel für die Kennzeichnung von Dokumentgruppen: labeling_job
auch: Chancen bei Lucidworks!
NLP-Forschungsingenieur
Wir suchen einen erfahrenen NLP-Experten, der uns bei der Definition und Erweiterung unserer NLP-Produktfunktionen unterstützt. Als NLP-Forschungsingenieur werden Sie End-to-End-Lösungen für NLP-Probleme erforschen, entwerfen, experimentieren und prototypisieren, mit Beratern und Kunden zusammenarbeiten, um die Bedürfnisse der Benutzer zu erfahren, Daten zu sammeln und vorläufige Ergebnisse zu validieren, neue Technologien für maschinelles Lernen und künstliche Intelligenz zu erforschen, anwendbare Ideen aus dem akademischen Bereich zu untersuchen und mit unseren Ingenieurteams bei der Umsetzung von Algorithmen in die Produktion zusammenzuarbeiten.
Must haves:
- Praktische Erfahrung in analytischen NLP-Bereichen wie semantisches Parsing, wissensbasierte Systeme, QA-Systeme, Conditional Random Field und Hidden Markov Model.
- Verständnis der gängigen Algorithmen des maschinellen Lernens und ihrer Anwendungen auf Text.
- Gute Programmierkenntnisse in mindestens zwei der folgenden Sprachen: Python/Scala/Java.
- Erfahrung mit analytischen Paketen wie SciKit Learn/Gensim/NLTK/Spark ML.
- Starke schriftliche und mündliche Kommunikationsfähigkeiten.
Gut zu haben:
- Promotion in NLP, ML oder Statistik mit einem starken analytischen Hintergrund. Sie sollten in der Lage sein, einen Algorithmus auf der Grundlage eines Papiers oder einer Idee von Grund auf zu programmieren und zu bewerten.
- Erfahrung mit Suchprogrammen wie Lucene/Solr oder Elasticsearch.
- Praktische Erfahrung mit Deep Learning Methoden wie RNN, LSTM, GRU, Seq2Seq Modellen.
- Gutes Verständnis für paralleles Rechnen wie Spark.
- Grundlegende Kenntnisse von Software-Entwicklungstools wie Git, Jenkins sind von Vorteil.
Sind Sie an einer Mitarbeit in unserem Team interessiert? Kontaktieren Sie VP of R&D Chao Han unter chao.han@lucidworks.com.