Grundlagen der Suche für Dateningenieure
Lucidworks Fusion ist eine Plattform für Data Engineering, die auf Solr/Lucene, der Apache Open Source-Suchmaschine, aufbaut, die schnell, skalierbar, bewährt und zuverlässig ist. Fusion nutzt die Solr/Lucene-Engine, um Suchanfragen auszuwerten und Ergebnisse in Form einer geordneten Liste von Dokument-IDs zurückzugeben. Sie haben die Möglichkeit, Ihre Daten und Suchergebnisse in Scheiben zu schneiden und zu würfeln. Das bedeutet, dass Sie Ihre Daten wie bei Google durchsuchen können und gleichzeitig die Kontrolle über Ihre Daten und die Suchergebnisse behalten.
Der Unterschied zwischen Data Science und Data Engineering ist der Unterschied zwischen Theorie und Praxis. Dateningenieure entwickeln Anwendungen, die ein Ziel und bestimmte Einschränkungen haben. Bei natürlichsprachlichen Suchanwendungen besteht das Ziel darin, relevante Suchergebnisse für eine unstrukturierte Anfrage zu liefern. Zu den Einschränkungen gehören: begrenzte, verrauschte und/oder schlichtweg schlechte Daten und Suchanfragen, begrenzte Rechenressourcen und Strafen für die Rückgabe irrelevanter oder unvollständiger Ergebnisse.
Als Dateningenieur müssen Sie Ihre Daten verstehen und wissen, wie Fusion sie in Suchanwendungen verwendet. Der schwierige Teil ist, Ihre Daten zu verstehen. In diesem Beitrag gehe ich auf die wichtigsten Bausteine der Fusion-Suche ein.
Fusion Schlüsselkonzepte
Fusion erweitert die Funktionalität von Solr/Lucene über eine REST-API und eine auf dieser REST-API aufbauende Benutzeroberfläche. Die Fusion-Benutzeroberfläche ist um die folgenden Schlüsselkonzepte herum organisiert:
- Sammlungen speichern Ihre Daten.
- Dokumente sind die Dinge, die als Suchergebnisse zurückgegeben werden.
- Felder sind die Dinge, die tatsächlich in einer Sammlung gespeichert werden.
- Datenquellen sind das Bindeglied zwischen Ihrem Datenspeicher und Fusion.
- Pipelines kapseln eine Abfolge von Verarbeitungsschritten, so genannte Stages.
- Indizierungspipelines verarbeiten die von einer Datenquelle empfangenen Rohdaten in feldbezogene Dokumente zur Indizierung in einer Fusion-Sammlung.
- Query Pipelines verarbeiten Suchanfragen und geben eine geordnete Liste übereinstimmender Dokumente zurück.
- Die Relevanz ist die Metrik, die verwendet wird, um Suchergebnisse zu ordnen. Sie ist eine nicht-negative reelle Zahl, die die Ähnlichkeit zwischen einer Suchanfrage und einem Dokument angibt.
Lucene und Solr
Lucene war ursprünglich eine Suchmaschine, die für folgende Aufgabe bei der Informationsbeschaffung entwickelt wurde: Finden Sie anhand einer Reihe von Suchbegriffen und einer Reihe von Dokumenten die Teilmenge von Dokumenten, die für diese Anfrage relevant sind. Lucene bietet eine umfangreiche Abfragesprache, mit der Sie komplizierte logische Bedingungen formulieren können. Lucene umfasst nun einen Großteil der Funktionalität eines herkömmlichen DBMS, sowohl in Bezug auf die Art der Daten, die es verarbeiten kann, als auch in Bezug auf die Transaktionssicherheit, die es bietet.
Lucene ordnet diskrete Informationen, z.B. Wörter, Daten, Zahlen, den Dokumenten zu, in denen sie vorkommen. Diese Zuordnung wird als invertierter Index bezeichnet, weil die Schlüssel Dokumentelemente und die Werte Dokument-IDs sind, im Gegensatz zu anderen Arten von Datenspeichern, bei denen Dokument-IDs als Schlüssel verwendet werden und die Werte die Dokumentinhalte sind. Diese Indizierungsstrategie bedeutet, dass die Suche in einem invertierten Index nur einen einzigen Suchvorgang erfordert, im Gegensatz zu einer dokumentenorientierten Suche, die eine große Anzahl von Suchvorgängen, einen pro Dokument, erfordern würde. Lucene behandelt ein Dokument als eine Liste von benannten, typisierten Feldern. Für jedes Dokumentfeld erstellt Lucene einen invertierten Index, der die Feldwerte den Dokumenten zuordnet.
Lucene selbst ist eine Such-API. Solr wickelt Lucene in eine Webplattform ein. Suche und Indizierung werden über HTTP-Anfragen und -Antworten durchgeführt. Solr verallgemeinert das Konzept eines Lucene-Index zu einer Solr-Sammlung, einem eindeutig benannten, verwalteten und konfigurierten Index, der über mehrere Server verteilt („sharded“) und repliziert werden kann, was Skalierbarkeit und hohe Verfügbarkeit ermöglicht.
Fusion UI und Workflow
Die folgenden Abschnitte zeigen, wie die oben genannten Schlüsselkonzepte in der Fusion-Benutzeroberfläche umgesetzt werden.
Sammlungen
Fusion-Sammlungen sind Solr-Sammlungen, die von Fusion verwaltet werden. Fusion kann so viele Sammlungen verwalten, wie Sie brauchen, wollen oder beides. Bei der ersten Anmeldung fordert die Fusion-Benutzeroberfläche Sie auf, eine Sammlung auszuwählen oder zu erstellen. Bei späteren Anmeldungen zeigt die Fusion-Benutzeroberfläche eine Übersicht über Ihre Sammlungen und Systemsammlungen an:
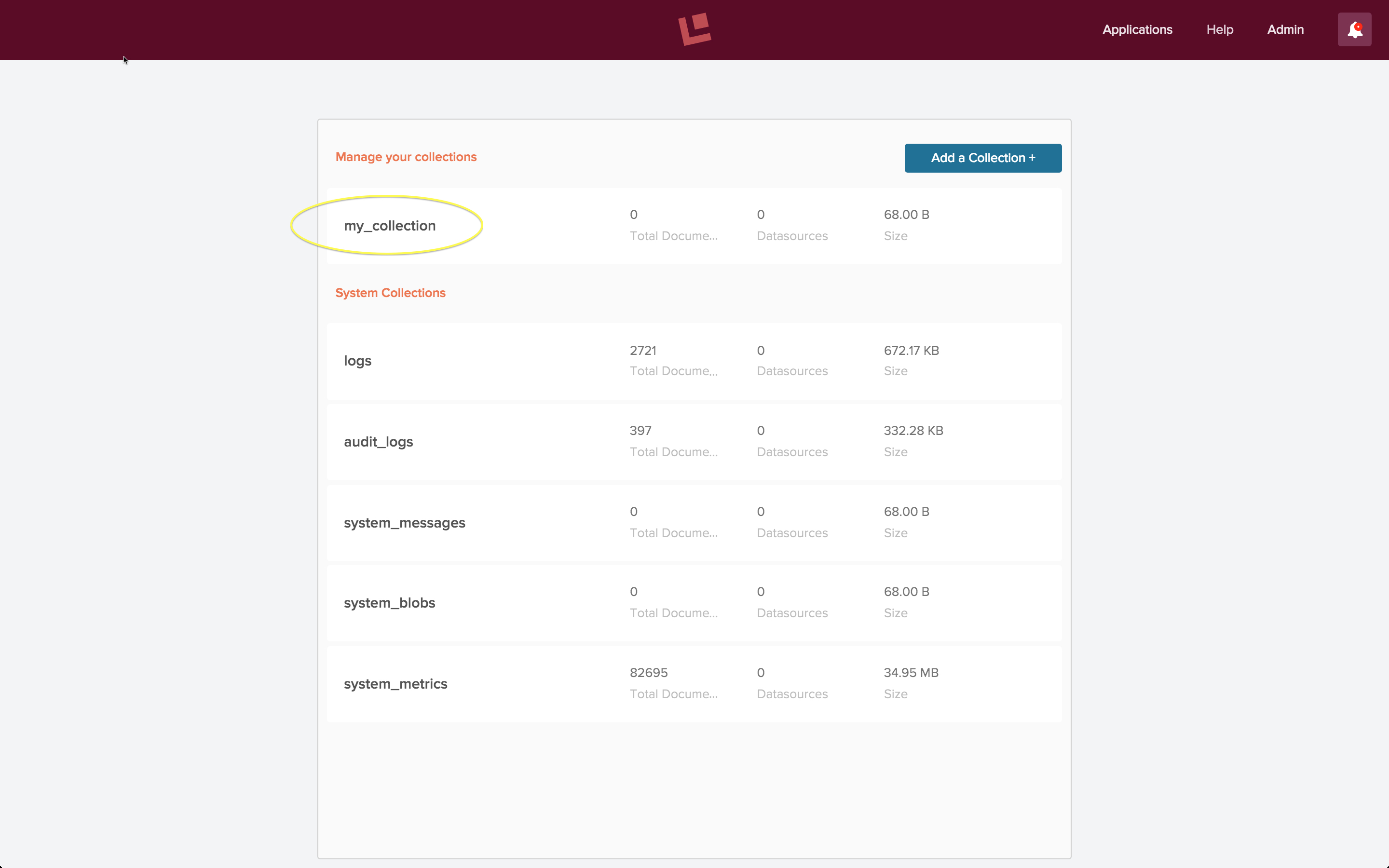
Der obige Screenshot zeigt die Seite mit den Fusion-Sammlungen bei einer Erstinstallation für Entwickler, kurz nach der ersten Anmeldung und der Erstellung einer neuen Sammlung namens „my_collection“, die gelb eingekreist ist. Wenn Sie auf diesen eingekreisten Namen klicken, gelangen Sie auf die Startseite der Sammlung „my_collection“:
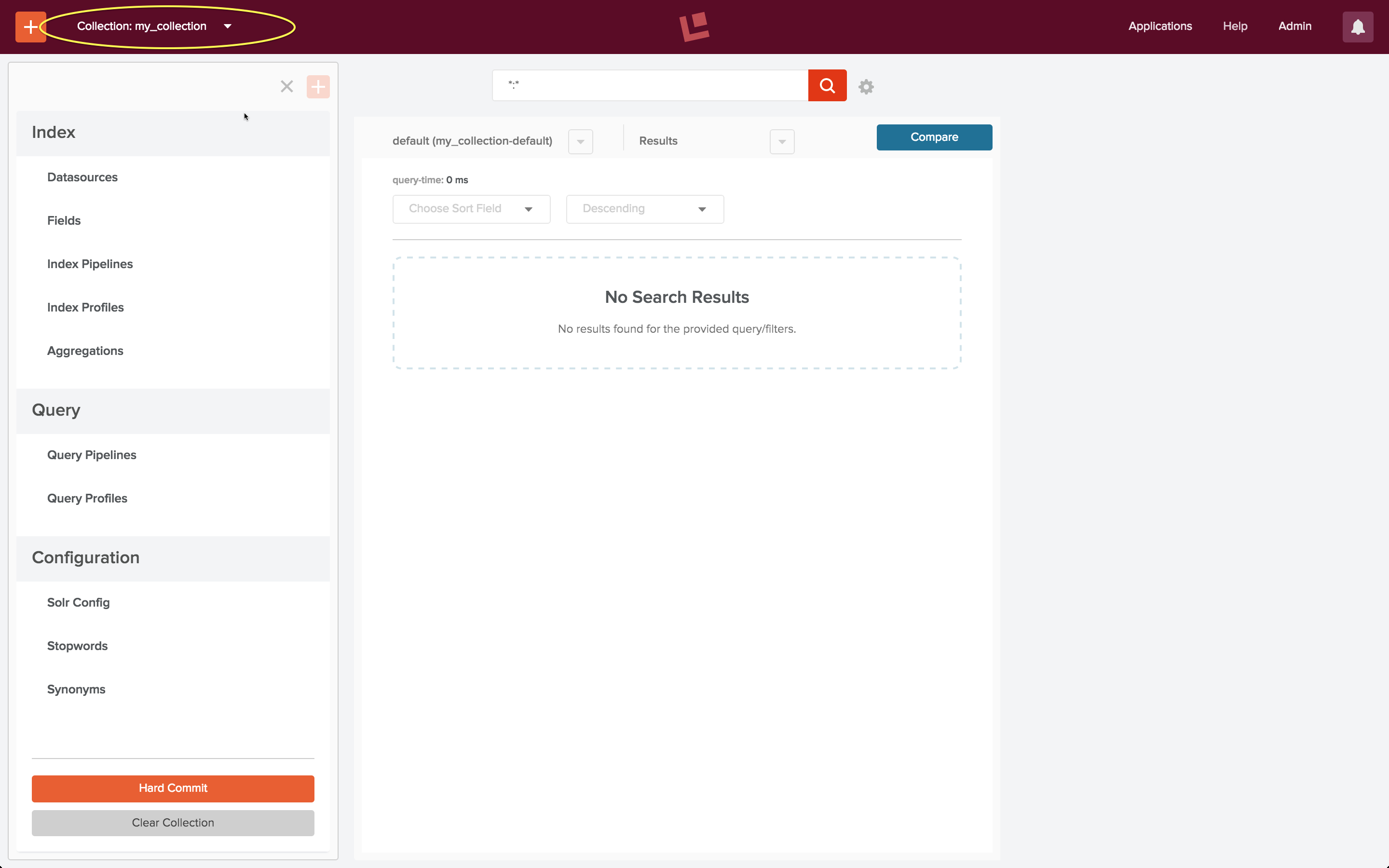
Die Startseite der Sammlung enthält Steuerelemente für die Suche und Indizierung. Da diese Sammlung noch keine Dokumente enthält, ist der Bereich für die Suchergebnisse leer.
Indizierung: Datenquellen und Pipelines
Das Bootstrapping einer Suchanwendung erfordert einen ersten Indizierungslauf über Ihre Daten, gefolgt von aufeinanderfolgenden Such- und Indizierungszyklen, bis Sie eine Suchanwendung haben, die das tut, was Sie wollen und was Suchbenutzer von ihr erwarten. Das Toolset für die Indizierung auf der Startseite von Collections enthält Steuerelemente für die Definition und Verwendung von Datenquellen und Pipelines.
Sobald Sie eine Sammlung erstellt haben, klicken Sie auf das Steuerelement „Datenquelle“, um das linke Bedienfeld in das Bedienfeld für die Konfiguration der Datenquelle umzuwandeln. Der erste Schritt bei der Konfiguration einer Datenquelle besteht darin, die Art des Datenspeichers festzulegen, mit dem eine Verbindung hergestellt werden soll. Fusion-Konnektoren sind eine Reihe von Programmen, die die Verbindung zu und den Abruf von Daten aus bestimmten Repository-Typen übernehmen. Um zum Beispiel eine Reihe von Webseiten zu indizieren, verwendet eine Datenquelle einen Web-Konnektor.
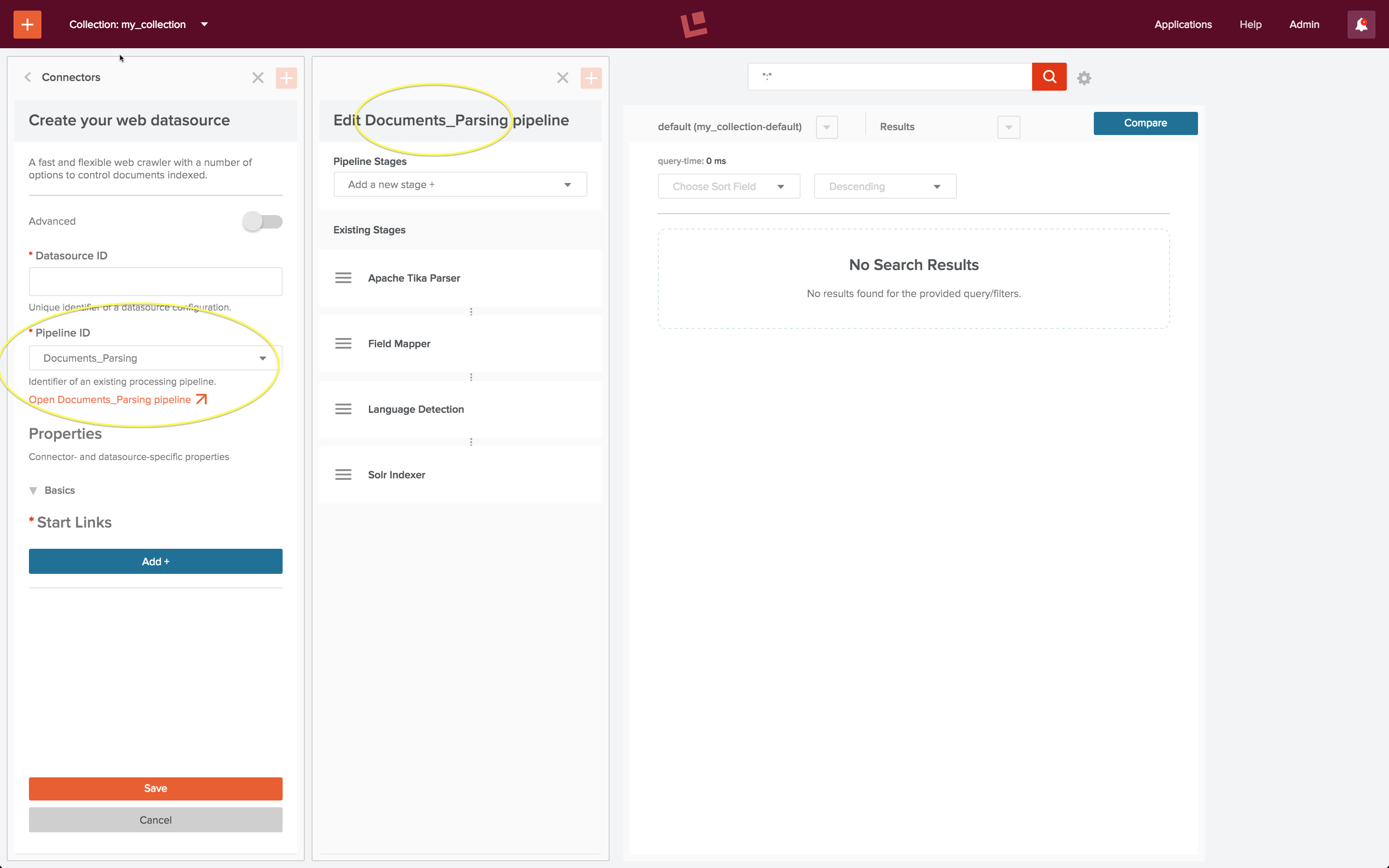
Um die Datenquelle zu konfigurieren, wählen Sie das Steuerelement „Bearbeiten“. Das Feld für die Konfiguration der Datenquelle steuert die Wahl der Indizierungspipeline. Alle Datenquellen sind mit einer Standard-Indizierungspipeline vorkonfiguriert. Die Indizierungspipeline „Documents_Parsing“ ist die Standardpipeline für die Verwendung mit einem Webconnector. Unter dem Steuerelement für die Pipeline-Konfiguration befindet sich ein Steuerelement “ <pipeline name> pipeline öffnen“. Wenn Sie darauf klicken, öffnet sich ein Pipeline-Bearbeitungsfenster neben dem Datenquellen-Konfigurationsfenster:
Sobald die Datenquelle konfiguriert ist, wird der Indizierungsauftrag über Steuerelemente im Datenquellenbedienfeld ausgeführt:
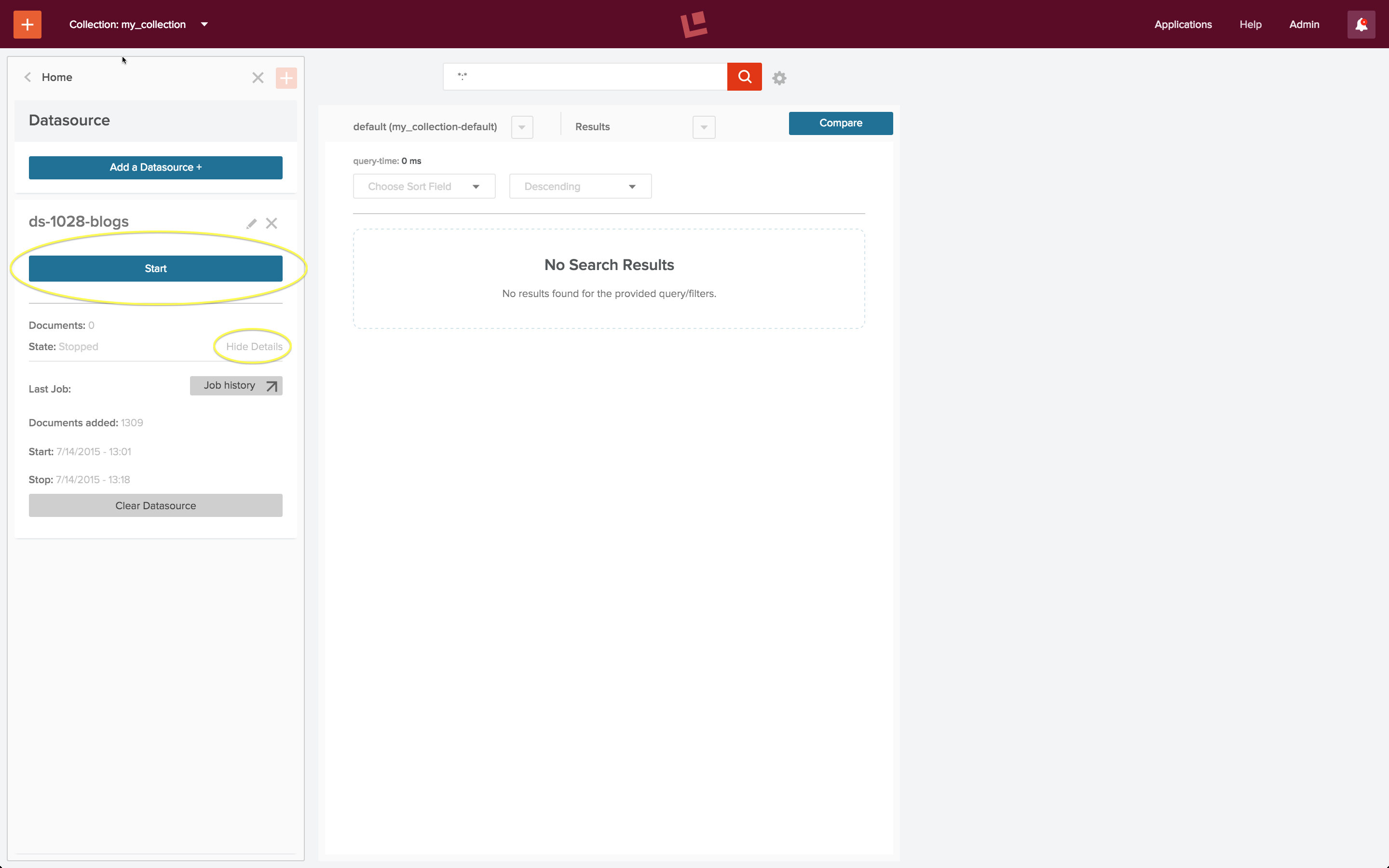
Wenn Sie auf die gelb eingekreiste Schaltfläche „Start“ klicken, werden die Steuerelemente „Stopp“ und „Abbruch“ angezeigt. Unter dieser Schaltfläche befindet sich ein Steuerelement „Details anzeigen“/“Details ausblenden“, das im geöffneten Zustand angezeigt wird.
Die Erstellung und Pflege eines vollständigen, aktuellen Indexes über Ihre Daten ist für eine gute Suche notwendig. Ein großer Teil dieses Prozesses besteht aus dem Mischen von Daten. Konnektoren und Pipelines machen diese Aufgabe überschaubar, wiederholbar und testbar. Mit den Mechanismen zur Auftragsplanung und Alarmierung von Fusion lässt sich dieser Prozess automatisieren.
Suche und Relevanz
Sobald eine Datenquelle konfiguriert und der Indizierungsauftrag abgeschlossen ist, kann die Sammlung mit dem Tool für Suchergebnisse durchsucht werden. Eine Platzhalterabfrage mit „:“ findet alle Dokumente in der Sammlung. Der folgende Screenshot zeigt das Ergebnis einer solchen Abfrage über das Suchfeld oben im Suchergebnisbereich:
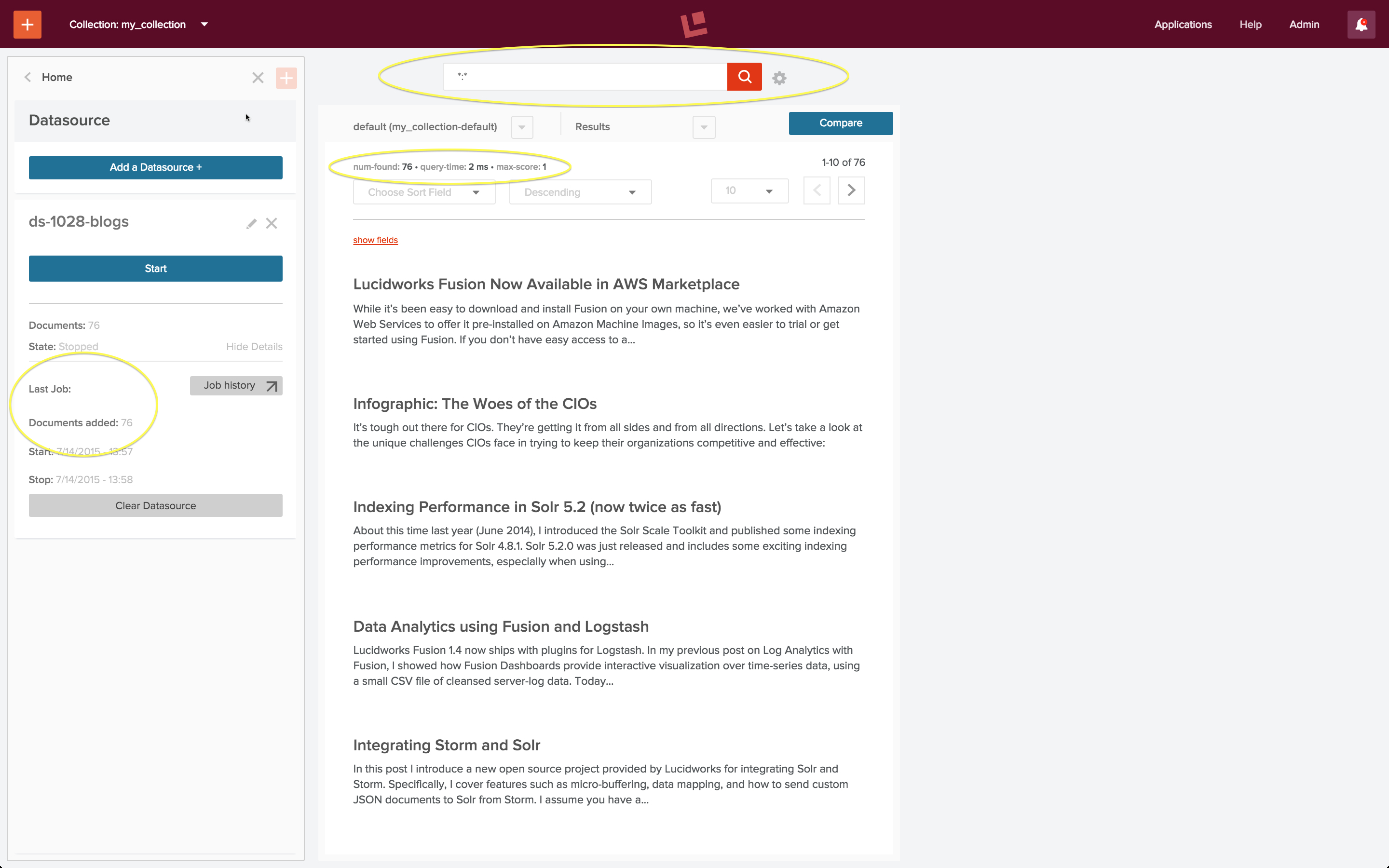
Nachdem Sie die Datenquelle genau einmal ausgeführt haben, besteht die Sammlung aus 76 Beiträgen aus dem Lucidworks-Blog, wie aus dem gelb eingekreisten Bericht „Last Job“ im Datenquellenbedienfeld hervorgeht. Dies stimmt mit der ebenfalls gelb eingekreisten „Anzahl gefunden“ oben auf der Seite mit den Suchergebnissen überein.
Die Suchanfrage „Fusion“ liefert die relevantesten Blogbeiträge über Fusion:
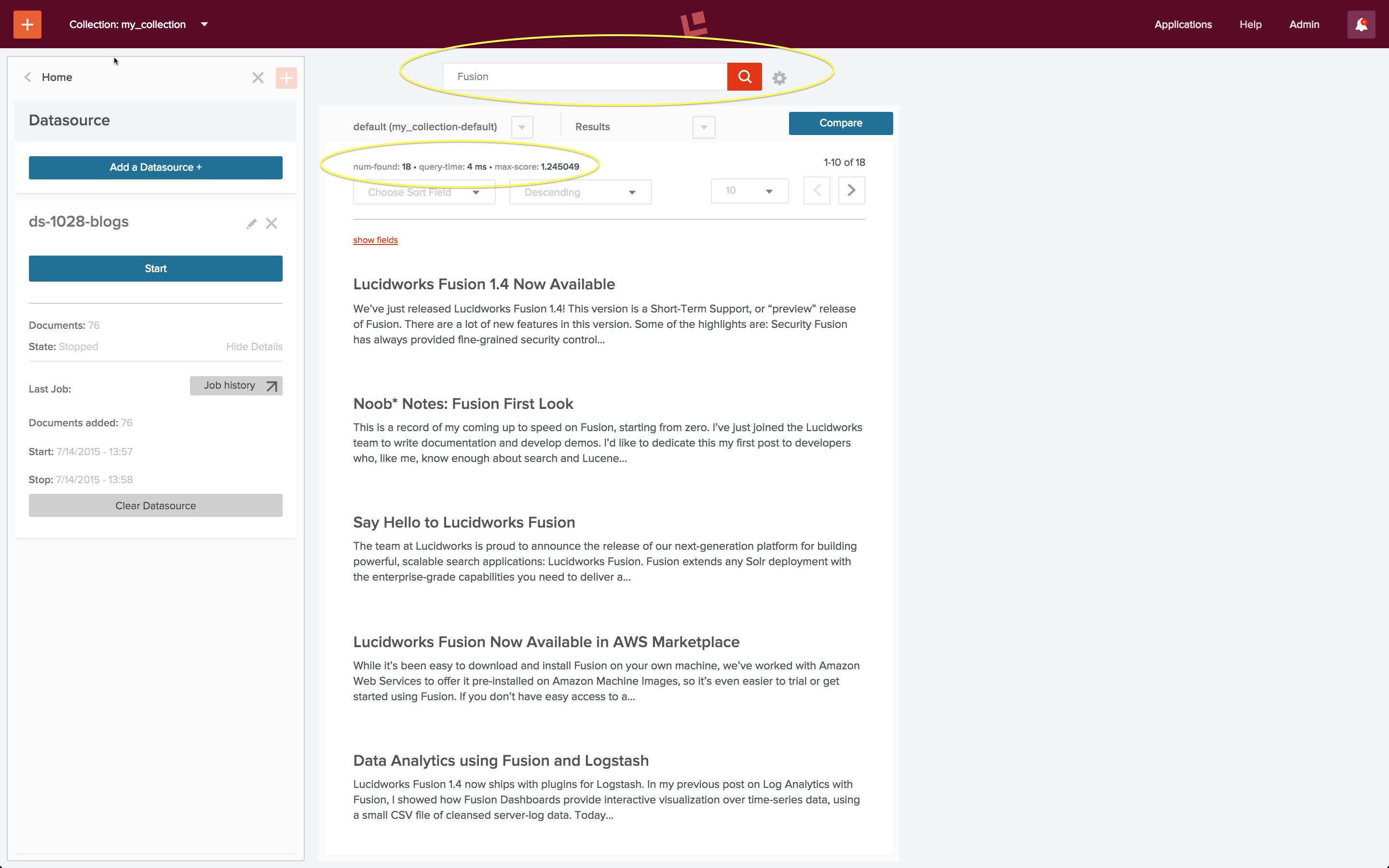
Es gibt insgesamt 18 Blog-Beiträge, die das Wort „Fusion“ entweder im Titel oder im Text des Beitrags enthalten. In diesem Screenshot sehen wir die 10 relevantesten Beiträge, in absteigender Reihenfolge.
Eine Suchanwendung nimmt eine Suchanfrage des Benutzers entgegen und liefert Suchergebnisse, die der Benutzer für relevant hält. Eine gut abgestimmte Suchanwendung ist eine Anwendung, bei der sowohl der Benutzer als auch das System über die Menge der relevanten Dokumente, die für eine Abfrage zurückgegeben werden, und die Reihenfolge, in der sie angeordnet sind, einig sind. Mit den Abfrage-Pipelines von Fusion können Sie Ihre Suche abstimmen und mit dem Tool für die Suchergebnisse können Sie Ihre Änderungen testen.
Fazit
Da dieser Beitrag eine kurze und behutsame Einführung in Fusion ist, habe ich einige Details ausgelassen und einige Schritte übersprungen. Dennoch hoffe ich, dass diese Einführung in die Grundlagen von Fusion Sie neugierig genug gemacht hat, um es selbst auszuprobieren.