LUCIDWORKSBeyond search: AI-driven experiences that understand your users.Transform mountains of data into meaningful experiences in real time.
Get a DemoTake the mystery out of being the best in your industry.
Grow faster by delivering AI-powered search that understands user intent and improves real-time digital experiences. Data-driven decision-making: the competitive advantage you’ve been missing.
Join hundreds of the world’s leading companies revolutionizing their search and digital experiences with Lucidworks. Our Core Packages make launching AI-driven search easy so you can focus on what matters most: getting ahead. Quickly implement AI for business transformation, improve search, insights, and digital experiences, and see proof of value from day one. Get expert help when needed, and deploy how you want.

Enterprise AI solutions for search and digital experience teams.
Our goal is to help you get ahead quicker. With quick-start packages, no-code solutions, and brilliant design, Lucidworks has built our technology to reduce risk and bring insights to life.
Now, you can transform data into value.
Lucidworks Packages
Fast start, fast value for B2C or B2B. Pre-built templates, access to Studios, and expert help to help you succeed.
✔ 25% less development time
✔ 30% less risk for launch
✔ 15% higher conversion rate
Lucidworks Studios
No-code, business user control over analytics, commerce, knowledge management, and AI apps.
✔ 10% customer value increase
✔ 15 hrs/wk saved by analysts
✔ 13% boost in conversions
Lucidworks AI
Orchestrate key areas of AI efficiently. Manage AI costs and security, LLM options and training, and get expert help.
✔ 25% less engineering time
✔ 20% faster to market
✔ 75% less vulnerability risk
Enterprise tested, everyday easy.
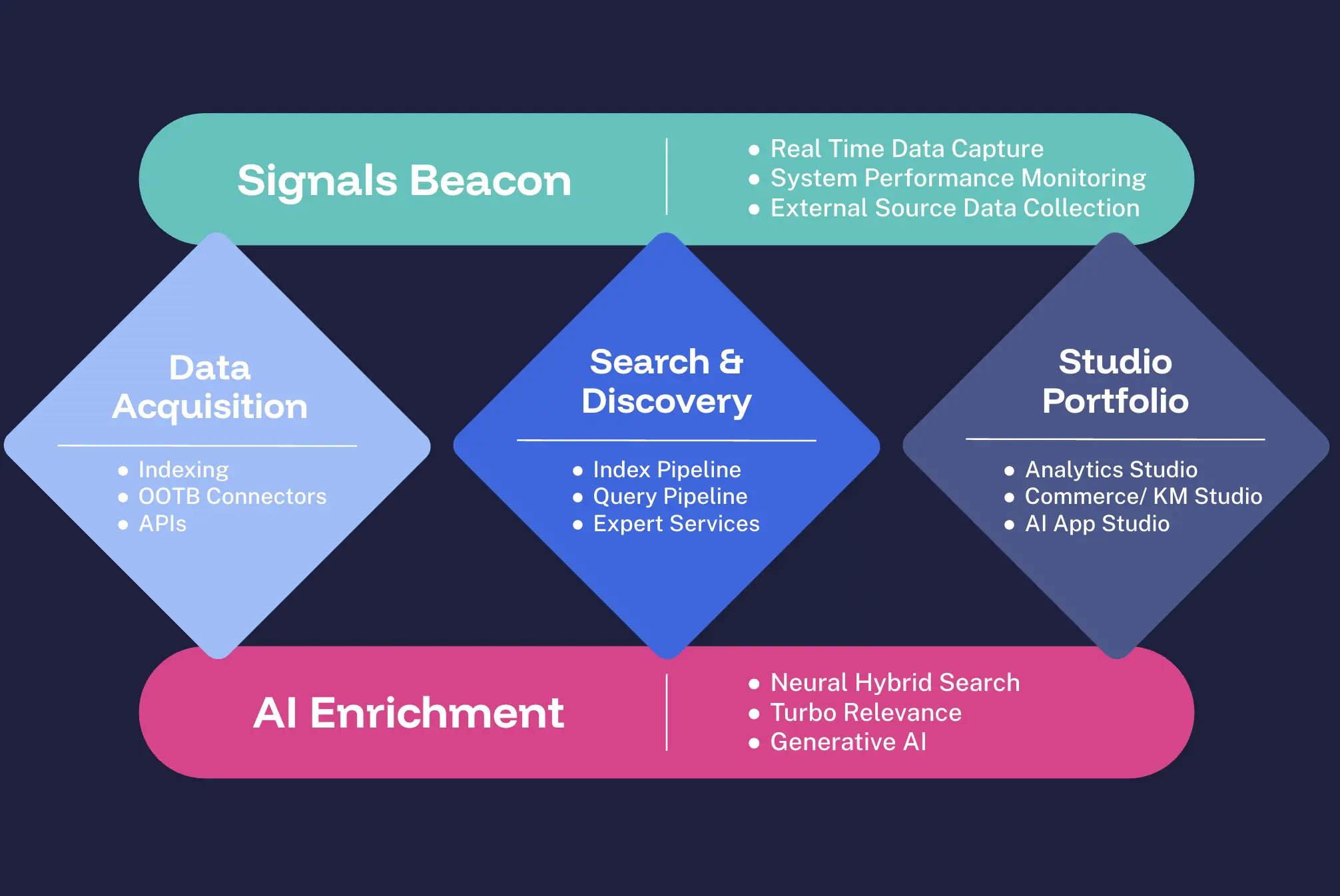
The Lucidworks Platform is your all-in-one solution for intelligent enterprise search, discovery, and personalization. With Signals, Data Acquisition, Lucidworks Search™, Lucidworks AI, and our innovative Lucidworks Studios™, we provide the tools you need to launch impactful experiences quickly.
Our platform offers out-of-the-box connectors for seamless integrations alongside intuitive visual editors for easy customization. We deliver modern query and index pipelines for optimal performance, complemented by built-in A/B testing and KPI management for continuous improvement. With no-code AI deployment, you can effortlessly improve experiences across your digital properties.
“We’ve had some dramatic growth. The results that we’ve had with Lucidworks are nothing short of astounding.”
Marc Desormeau, Global Search Lead, Lenovo
Forrester's Total Economic Impact study found that companies using Lucidworks achieve a 391% ROI within three years, with payback beginning in less than six months.
Download ROI StudyREI leveraged Lucidworks to create a personalized search experience that increased product discovery and drove significant revenue during peak seasons.
Explore REI’s SuccessLenovo increased annual revenue contribution by 95% and improved search relevance by 55% using Lucidworks' AI-powered search solutions.
Watch Lenovo's Story
Your deployment, your way.
Only Lucidworks gives you this many ways to set up your solution. You choose what works for your business now and what will grow with you in the future—no forcing you into a one-size-fits-all approach.
SaaS
A modern no-code platform with everything business, search, and digital teams need to create, manage, and optimize search and product discovery for agencies or B2B and B2C companies in any industry. Fast deployment, continually updated, secure, and scalable with automatic feature updates.
Self-Hosted
A self-hosted platform with everything business, search, and digital teams need to create, manage, and optimize search and product discovery for agencies or B2B and B2C companies in any industry. Ultimate control, secure, scalable, and customizable to your environment.
Hybrid-SaaS
A combined solution offering our self-hosted platform with secure access to additional SaaS features. Everything teams need to create, manage, and optimize search and product discovery for agencies or B2B and B2C companies in any industry. Flexible, secure, and scalable deployment options.
Expert Services
We're with you every step of the way.
We support you through every part of your journey, a distinctive advantage of working with Lucidworks.
Our global expert teams advise in search and digital program design, relevance improvement and optimization, B2B and B2C ROI, and full lifecycle implementation and support.
Technology is essential, but so are the people who partner with you for your success.
