Abfrage-Explorer-Jobs in Fusion 3.1
Abfrage-Explorer-Jobs in Fusion 3.1
Einführung
Die Analyse von Suchanfragen ist das mächtigste Analysewerkzeug im Arsenal eines jeden Suchingenieurs. Anfragen sind die einzige Kommunikationslinie zwischen einem Kunden und einem Suchmaschinenadministrator. Doch die meisten Techniker verfügen nicht über die Tools, die ihnen helfen, ihre Abfragen besser zu verstehen. Hier kommt Lucidworks Fusion ins Spiel. Fusion 3.1 verfügt über einige sofort einsatzbereite Spark-Analysefunktionen, die Ihnen helfen, Ihre Abfragen und Daten besser zu verstehen. Im Folgenden finden Sie Beschreibungen und Anwendungsfälle für drei dieser Aufgaben.
Analyse der Kollektion
Dieser Auftrag sammelt einige grundlegende statistische Informationen über die Abfragen in einer bestimmten Sammlung. Der Auftrag zur Sammlungsanalyse berechnet den Prozentsatz der Abfragen, die einen, zwei, drei, vier, fünf und sechs oder mehr Begriffe enthalten, sowie die durchschnittliche Abfragelänge und die Standardabweichung1 in der Länge der Abfragen. Der Auftrag gibt diese Werte als Felder eines einzelnen Dokuments in der angegebenen outputCollection zurück.
Der Auftrag führt auch einige Ausreißerberechnungen durch. Der Parameter numDeviations gibt an, wie viele Standardabweichungen zugelassen werden sollen, ab denen die Länge der Abfrage als „Ausreißer“ gilt. Der Algorithmus berechnet, welche Abfragen eine Länge haben, die mehr als numDeviations Standardabweichungen vom Durchschnitt abweicht, und gibt diese Dokumente in der gleichen angegebenen Ausgabesammlung zurück. Das bedeutet, dass dieser einzelne Auftrag zwei Arten von Dokumenten in dieselbe Ausgabesammlung auffüllt. Sie können das Feld Typ verwenden, um zwischen den beiden Dokumenttypen zu unterscheiden. Das erste, das die im vorigen Absatz beschriebenen Statistiken liefert, hat das Feld „Typ“ „stats“ und das zweite den Typ „Ausreißer“.
Nachfolgend finden Sie eine Beispielkonfiguration und -ausgabe für den Auftrag.
{
"type" : "collection_analysis",
"id" : "collections",
"outputCollection" : "outputCollectionName",
"numDeviations" : 2,
"type" : "collection_analysis",
"trainingCollection" : "inputCollectionName",
"dataFormat" : "solr",
"trainingDataFilterQuery" : "*:*",
"trainingDataSamplingPercentage" : 1.0,
"randomSeed" : 8180,
"fieldToVectorize" : "query_s",
"sourceFields" : "raw"
}
Das FeldToVectorize entspricht dem Abfragefeld. Wenn Sie diesen Auftrag über eine Beispielabfrage ausführen, erhalten Sie zwei Arten von Dokumenten. Das erste ist ein einmaliges Dokument, das die Statistik über die Abfragelängen enthält. Ein Beispiel für dieses Dokument finden Sie unten.

Wie wir sehen können, haben etwa 37 Prozent der Abfragen nur einen Begriff, während fast 45 Prozent zwei Begriffe enthalten. Außerdem sehen wir, dass die Standardabweichung bei der Länge der Abfragen etwa 6,8 beträgt und die durchschnittliche Länge der Abfragen bei etwa 11 liegt.
Die anderen Dokumente sind diejenigen, die die Ausreißermenge bilden. Nachfolgend sehen Sie ein Beispiel dafür, wie eines dieser Dokumente aussehen könnte.

Wie wir sehen können, ist die Länge der Abfrage in diesem Dokument 26. Dies ist mehr als 2 Standardabweichungen vom Mittelwert entfernt und wird daher von der Aufgabe als „Ausreißer“ betrachtet.
Levenshtein-Rechtschreibprüfung
Diese Aufgabe erzeugt die Levenshtein-Edit-Distanz1 zwischen einer Reihe der beliebtesten Abfragen und jeder anderen Abfrage. Er gibt die Paare zurück, die innerhalb eines bestimmten Editierabstands zueinander liegen. Dieser Auftrag soll dazu dienen, häufige Rechtschreibfehler in beliebten Abfragen zu finden. Nachfolgend finden Sie eine Beispielkonfiguration.
{
"type" : "levenshtein",
"id" : "levenshteins",
"outputCollection" : "outputCollectionName",
"maxDistance" : 2,
"headSize" : 2,
"lenScale" : 1,
"sourceFields" : "query_s, title_s, url_s",
"type" : "levenshtein",
"trainingCollection" : "inputCollectionName",
"dataFormat" : "solr",
"trainingDataFilterQuery" : "*:*",
"trainingDataSamplingPercentage" : 1.0,
"randomSeed" : 8180,
"fieldToVectorize" : "query_s",
}
Dieser Auftrag macht sich die Idee zunutze, dass die beliebtesten Suchanfragen am wenigsten wahrscheinlich falsch geschrieben sind. Der Auftrag verwendet einen Parameter namens „headSize“. Dies ist die Größe der Menge, die wir als „Kopf“ betrachten möchten und die aus den beliebtesten Abfragen mit der höchsten „headSize“ besteht. In der obigen Auftragskonfiguration hat headSize zum Beispiel den Wert 2, so dass wir die beiden beliebtesten Abfragen als „head“-Abfragen betrachten. Die anderen Abfragen werden als „Schwanz“ bezeichnet, da es sich bei ihnen eher um einfache Falschschreibungen einer entsprechenden Hauptabfrage handelt. Der Job vergleicht jede „Tail“-Abfrage mit der Menge der „Head“-Abfragen und stellt fest, ob die Editierdistanz zwischen ihnen innerhalb der angegebenen „maxDistance“ liegt (in der obigen Konfiguration beträgt sie 2). Wenn die Endabfrage innerhalb der „maxDistance“-Editierdistanz zur Hauptabfrage liegt, gibt der Job das Paar aus Haupt- und Endabfrage, ihre Distanz und die Anzahl der Haupt- und Endabfragen aus. Nachfolgend sehen Sie ein Beispiel für ein Ausgabedokument.
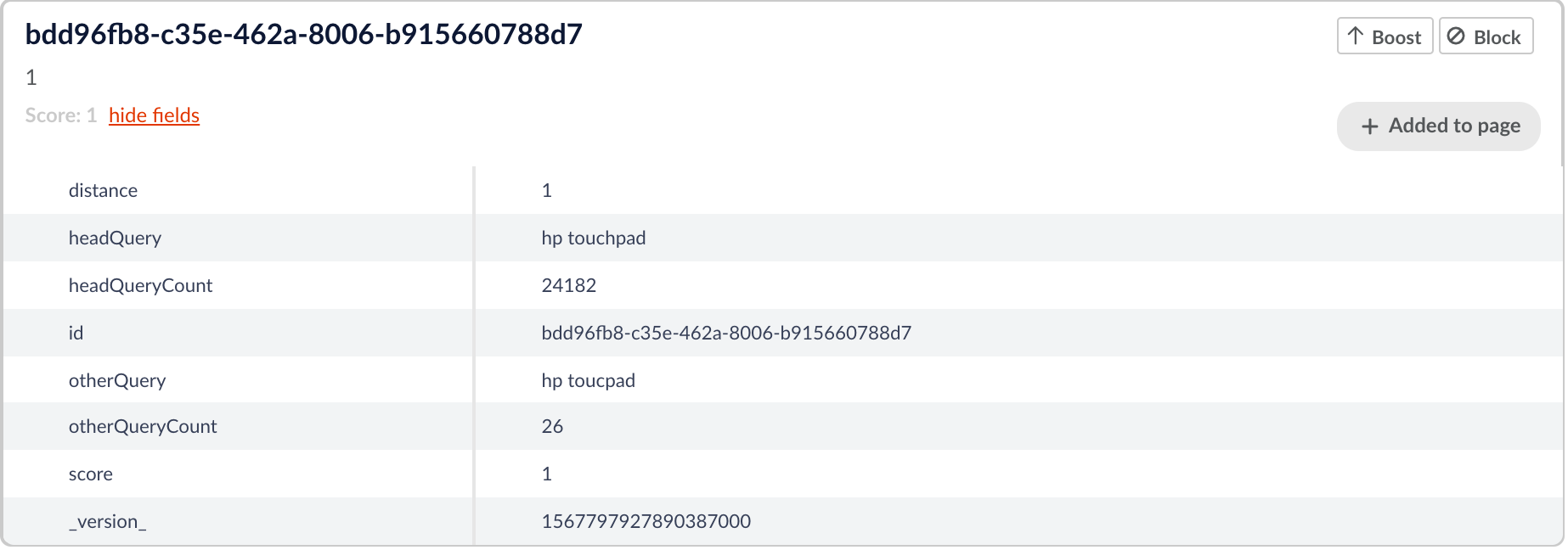
Hier sehen wir eine Hauptabfrage von „hp touchpad“ und eine Vergleichsabfrage von „hp toucpad“. Es ist sehr wahrscheinlich, dass es sich dabei um einfache Rechtschreibfehler handelt, und so gibt der Job das Paar und den Bearbeitungsabstand zwischen ihnen zurück.
Der Parameter lenScale hat bei dieser Aufgabe eine gewisse Bedeutung. Dieser Parameter skaliert den Bearbeitungsabstand effektiv mit der Länge der Abfrage. Die Skalierungsformel sorgt dafür, dass der Editierabstand <= Abfragelänge/Längenskala ist. Wenn wir z.B. length_scale=3 wählen, dann werden für query_length<=3 keine Paare gefunden. Bei Abfragen mit einer Länge zwischen 4 und 6 muss die Edit-Distanz 1 sein, um ausgewählt zu werden.
Statistisch interessante Phrasen
Diese Aufgabe unterscheidet sich etwas von den anderen. Er ist dafür gedacht, über einen Textkorpus und nicht über eine Reihe von Abfragen ausgeführt zu werden, und er erzeugt statistisch interessante Phrasen1 aus dem Textkorpus. Eine statistisch interessante Phrase ist eine Phrase, die in einem Textkorpus häufiger vorkommt, als man erwarten würde. Nachfolgend finden Sie ein anschauliches Beispiel.
{
"id": "sips",
"type": "sip",
"analyzerConfig": "{
"analyzers": [ { "name": "StdTokLowerStop",
"tokenizer": { "type": "standard" },
"filters": [
{ "type": "lowercase" },
{ "type": "stop" }] }],
"fields": [{ "regex": ".+", "analyzer": "StdTokLowerStop" } ]}",
"inputCollection": "inputCollectionName",
"outputCollection": "outputCollectionName",
"descriptionField": "longDescription",
"ngramSize":"2",
"minmatch":"2"
}
Der Auftrag benötigt einen Parameter „n“, der der Größe der „Phrase“ entspricht. Nachfolgend finden Sie ein Beispiel für eine Konfiguration eines Auftrags. Wenn n z.B. auf drei gesetzt ist, werden Zeichenketten mit drei Wörtern als Phrasen betrachtet und der Auftrag sucht nach statistisch interessanten Phrasen, die aus drei oder weniger Wörtern bestehen. Ein weiterer interessanter Parameter ist der minmatch. Dabei handelt es sich um die Mindestanzahl, mit der eine Phrase im Korpus vorkommen muss, um als statistisch interessant zu gelten. Nachfolgend sehen Sie ein Beispiel dafür, wie die Ausgabe des Auftrags aussieht.

Wie wir in den obigen Dokumenten sehen können, haben diese Wörter einen hohen llr-Wert, was bedeutet, dass sie häufiger zusammen vorkommen, als es statistisch gesehen wahrscheinlich ist. Dies deutet darauf hin, dass das Ngramm, das die Wörter bilden, wahrscheinlich eine „Phrase“ ist. Bei einer logischen Betrachtung der Ngramme würden die Ngramme „holds up“ und „stylish look“ in der englischen Sprache sicherlich als Phrasen betrachtet werden, so dass wir sehen können, dass der SIP-Job eine logische Ausgabe geliefert hat.
Das folgende Beispiel hat einen niedrigeren llr, aber immer noch einen über dem angegebenen Schwellenwert.
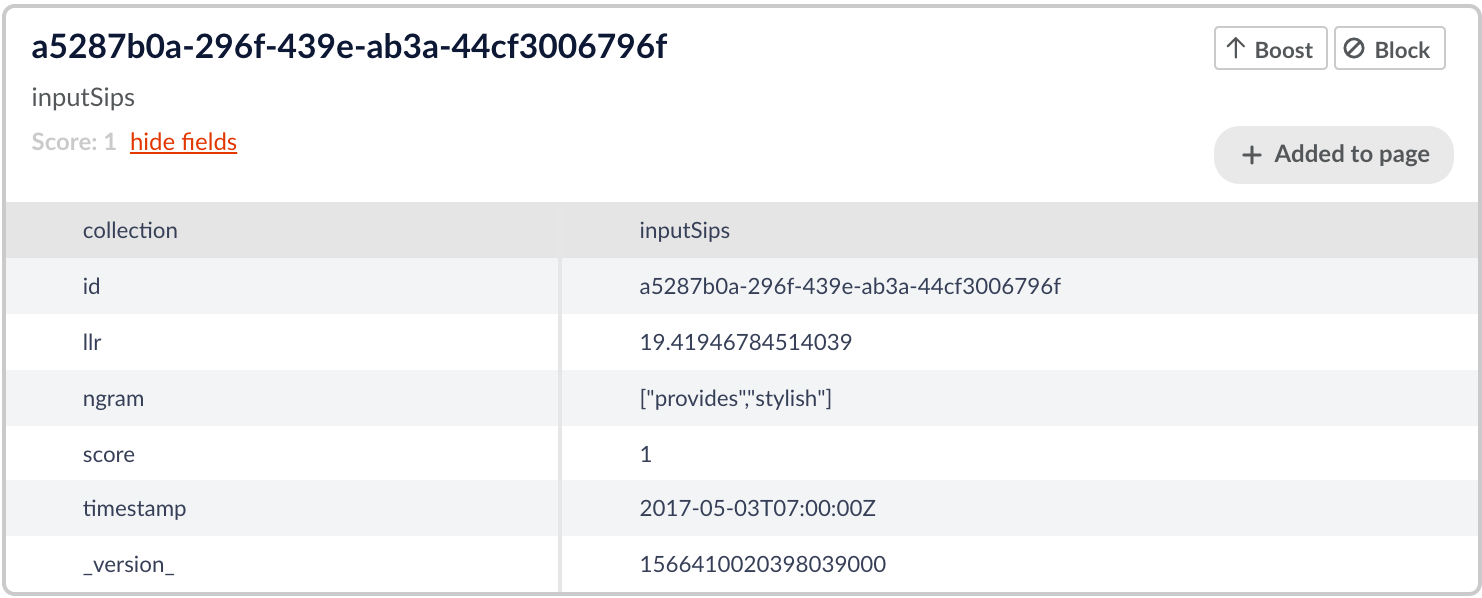
Wie wir sehen können, ist die Phrase „bietet stilvoll“ nicht sehr häufig, aber diese beiden Begriffe scheinen in einem Textkorpus dennoch wahrscheinlich zusammenzufallen und die Phrase „bietet stilvoll“ ist logisch. Nicht so wahrscheinlich wie die Phrasen in der obigen Abbildung, aber immer noch ziemlich wahrscheinlich.
Fazit
Mit diesen Aufträgen können Datentechniker ihre Abfrageprotokolle mit nur wenigen Klicks in Fusion untersuchen. Weitere Informationen finden Sie in der Fusion-Dokumentation.