Apache Superset und Lucidworks Fusion (Teil 1)
Die meisten Datenexperten haben inzwischen von Apache Superset gehört. Wenn Sie es noch nicht kennen, ist es noch nicht zu spät, es auszuprobieren. Es wurde vom Datenteam von AirBnB entwickelt und von Tausenden von Unternehmen auf der ganzen Welt übernommen, die nach einer Open-Source-Alternative zur Datenvisualisierung suchen.
Ich habe mich anfangs wegen des Enthusiasmus dafür interessiert, bin dann aber wegen der immensen Visualisierungsmöglichkeiten dabei geblieben. Ich weiß, dass einige Entwickler und Datenwissenschaftler, die mit einem hohen Abfragevolumen und einer hohen Kardinalität zu tun haben, auf diese Weise sehr von der Leistung von Fusion hinter Superset profitieren werden.
Nachdem ich zu Lucidworks gekommen war, begann ich mit Fusion zu spielen und erkannte, dass es Superset mit einigen erweiterten Datenverarbeitungs- und Abfragemöglichkeiten versorgen könnte. Unter der Haube der Fusion SQL Engine optimiert Apache Spark große Abfragen, damit sie nicht umfallen oder zu viel Zeit benötigen. Alle Codeschnipsel für diesen Blogbeitrag sind in einem Repo am Ende des Blogbeitrags enthalten.
Superset hat nicht den Anspruch, eine Suchmaschine für die Analyse von Millionen von Dokumenten zu sein. Wenn die Suchmaschine (in diesem Fall Fusion) eine Verbindung zu Superset unterstützt und offensichtlich die darin enthaltenen Datenmengen bewältigen kann, liegt es nahe, die beiden miteinander zu verbinden. In einem späteren Blogbeitrag werde ich die Anbindung von Superset an eine unserer verwalteten Solr-Instanzen näher erläutern.
Kurz gesagt, hier sind die Schritte zur Installation von Superset für die Arbeit mit Fusion:
- Apache Superset herunterladen und installieren
- Lucidworks Fusion herunterladen und installieren
- Konfigurieren Sie Lucidworks Fusion so, dass es im „binären“ Modus arbeitet.
- Starten Sie Apache Superset und Lucidworks Fusion.
- Erstellen Sie eine App in Lucidworks Fusion und indizieren Sie die Daten, so dass Sie mindestens eine Sammlung haben.
- Verbinden Sie Lucidworks Fusion mit Superset in der Superset-Benutzeroberfläche und fügen Sie Tabellen aus Ihrer Fusion-Sammlung zu Superset hinzu.
- Erstellen Sie Ihr erstes Diagramm
Apache Superset herunterladen und installieren
Apache Superset ist super einfach herunterzuladen, zu installieren und zum Laufen zu bringen. Diese Schritte sind der offiziellen Dokumentation entnommen:
Hinweis: Bevor Sie beginnen, vergewissern Sie sich bitte, dass Sie Python >= 3.6 und Pandas 23.4 installiert haben (24 funktioniert nicht). Ich empfehle die Verwendung einer virtuellen Python-Umgebung.
# Install the latest versions of pip and setuptools pip install --upgrade setuptools pip #Install superset pip install superset # Create an admin user (you will be prompted to set a username, first and last name before setting a password) fabmanager create-admin --app superset # Initialize the database superset db upgrade # Load some data to play with superset load_examples # Create default roles and permissions superset init # To start a development web server on port 8088, use -p to bind to another port superset runserver -d
Alternativ können Sie Superset auch mit Docker installieren
Lucidworks Fusion herunterladen (Überspringen, wenn bereits verwendet)
Rufen Sie die Lucidworks-Website auf, um Fusion auf Ihren Computer herunterzuladen: https://lucidworks.com/download/.
# Unpack the fusion tarball in the directory where you want Fusion to live tar -xf fusion-version.x.tar.gz
Wenn Sie die Java-Version Ihres Systems kürzlich auf 11 aktualisiert haben, unterstützt Fusion nur Java 8, so dass Sie möglicherweise einen Befehl ausführen müssen. Führen Sie java -version aus, um dies zu überprüfen. Wenn Sie vorübergehend auf 8 zurückgehen müssen, um es zu starten, führen Sie diesen Befehl aus:
Export JAVA_HOME=`/usr/libexec/java_home -v 1.8`
Konfigurieren Sie Lucidworks Fusion für die Unterstützung von Apache Thrift im Binärmodus
In diesem Blogbeitrag wird eine Möglichkeit vorgestellt, Fusion so zu konfigurieren, dass es eine Verbindung zu Superset unterstützt. Superset so zu konfigurieren, dass es mit Fusion läuft, ist möglich, erfordert aber etwas mehr Aufwand. Im Folgenden finden Sie die Schritte, mit denen Sie Fusion so konfigurieren, dass es den Binärmodus in Thrift unterstützt, so dass Sie SQL-Abfragen direkt von der leistungsstarken Visualisierungs-Engine von Superset aus durchführen können.
Wechseln Sie von Ihrem fusion -Verzeichnis, dem Ergebnis des Entpackens des tar-Balls aus Schritt 2, auf das Sie in ${FUSION_HOME} verweisen, in das Konfigurationsverzeichnis, in dem Sie Ihre Änderungen vornehmen werden:
cd conf/
Öffnen Sie ${FUSION_HOME}/conf/sql-log4j.xml und fügen Sie diese Zeile am Ende der Datei hinzu, nach allen anderen Logger-Konfigurationen:
<logger name="org.apache.thrift.server.TThreadPoolServer" level="FATAL"/>
Dadurch werden einige der unschädlichen Fehler „Keine Daten oder keine sasl-Daten im Stream“ abgeschwächt.
Öffnen Sie dann die Hive-Konfigurationsdatei, ${FUSION_HOME}/conf/hive-site.xml, und nehmen Sie einige Änderungen vor.
Ändern Sie zunächst hive.server2.transport.mode von http in binary und die folgenden Konfigurationen für den Port und die Berechtigungen auf dem Hive scratchdir:
<property> <name>hive.server2.thrift.port</name> <value>8768</value> </property> <property> <name>hive.scratch.dir.permission</name> <value>733</value> </property>
Öffnen Sie schließlich ${FUSION_HOME}/conf/fusion.properties und fügen Sie spark-master, und spark-worker als Gruppenvorgaben hinzu. Wenn Sie bereits Fusion verwenden, vergewissern Sie sich, dass sql auch dort enthalten ist.
Lucidworks Fusion starten
So starten Sie Fusion:
${FUSION_HOME}/4.1.2/bin/fusion start
Erstellen Sie eine Sammlung in Lucidworks Fusion (überspringen Sie diese, wenn sie bereits existiert)
Der einfachste Weg, eine Sammlung in Fusion zu erstellen, ist die Verwendung der Beispieldaten, die wir mit der Fusion-Demo mitgeliefert haben. Um diesen Prozess noch weiter zu vereinfachen, habe ich unten eine Reihe von Schritten eingefügt, die Ihnen zeigen, wie Sie eine Fusion-Sammlung mit den Spirituosenverkäufen in Iowa zur Verwendung in Superset erstellen können:
Klicken Sie auf dem Startbildschirm auf die Schaltfläche zum Erstellen einer neuen App:

Erstellen Sie eine App namens supersettest:
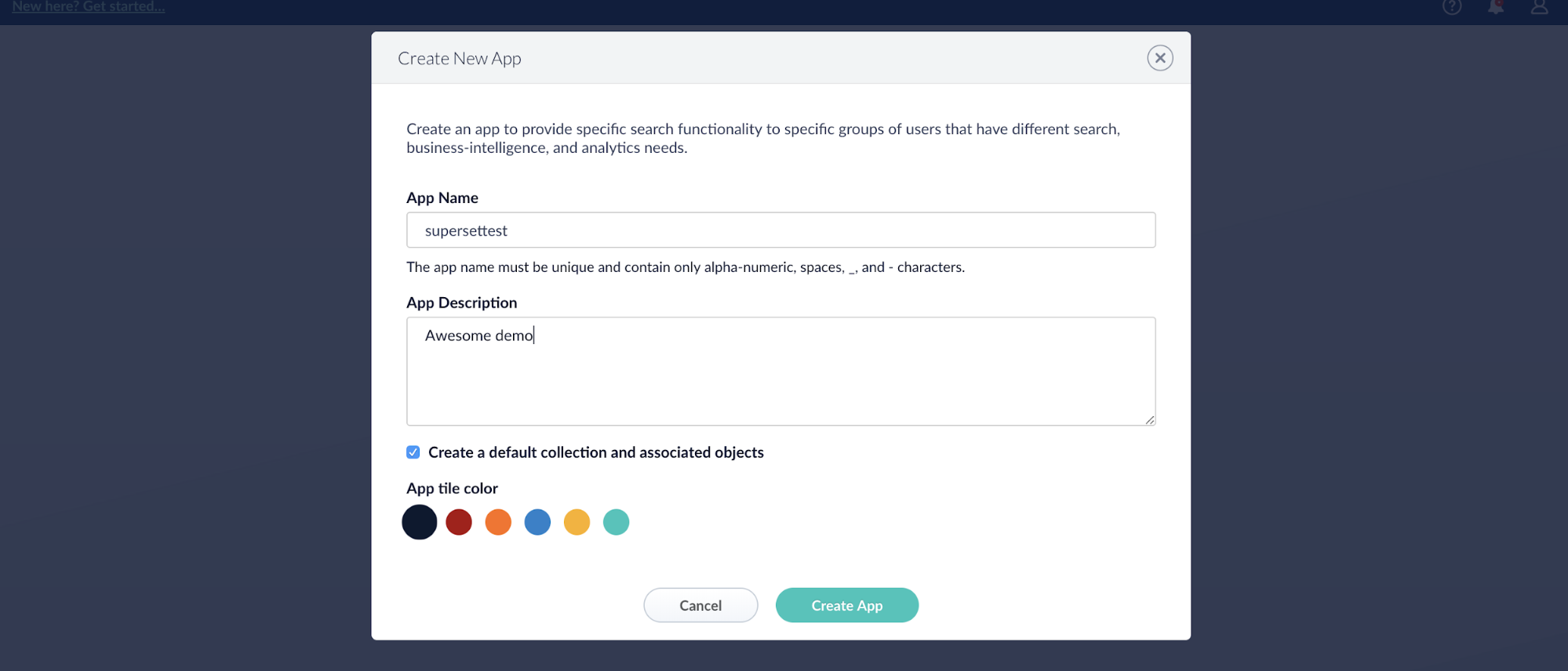
Wenn Sie oben links in der Anwendung „Neu hier? Starten…“ sehen, klicken Sie auf diesen Link. Wenn Sie den Link nicht sehen, klicken Sie in der oberen linken Ecke der Anwendung auf „Zurück zum Launcher“, wo der Link „Neu hier? Erste Schritte…“ in der oberen linken Ecke zu finden ist. Dort können Sie einem recht einfachen Schnellstart-Assistenten folgen, um Daten zu indizieren, die Ihre erste Sammlung sein werden.
Für dieses Tutorial sollten Sie einige wichtige Dinge beachten:
- Wenn Sie „Indexdaten“ erreichen, wählen Sie Iowa „Liquor Sales Data“.
- Wenn Sie zu „Daten abfragen“ gelangen, klicken Sie auf das X in der oberen rechten Ecke, um den Schnellstart-Assistenten zu schließen.
Verbindung zu Lucidworks Fusion in der Apache Superset UI
Loggen Sie sich in die Superset-Benutzeroberfläche ein, fahren Sie mit dem Mauszeiger über Quellen und klicken Sie auf Datenbanken in der Navigationsleiste oben auf der Seite. Auf der Seite Datenbanken bearbeiten müssen Sie einen Namen und die SQLAlchemy UI für Ihre Datenbank angeben.
Für den Namen geben Sie supersettest oder einen Namen Ihrer Wahl ein.
Für die SQLAlchemy-URI müssen Sie den folgenden Wert eingeben, wobei Benutzername und Passwort Ihr Fusion-Benutzername und -Passwort und die IP Ihre Fusion-IP ist:
hive://<username>:<password>@<ip>:8768/default;transportMode=binary?auth=CUSTOM
Sobald Sie die Informationen eingegeben haben, klicken Sie auf die Schaltfläche, um die Verbindung zu testen. Wenn Sie das Dialogfeld „Scheint OK zu sein“ sehen, ist die Verbindung hergestellt und Sie können fast mit der Erstellung von Visualisierungen beginnen.
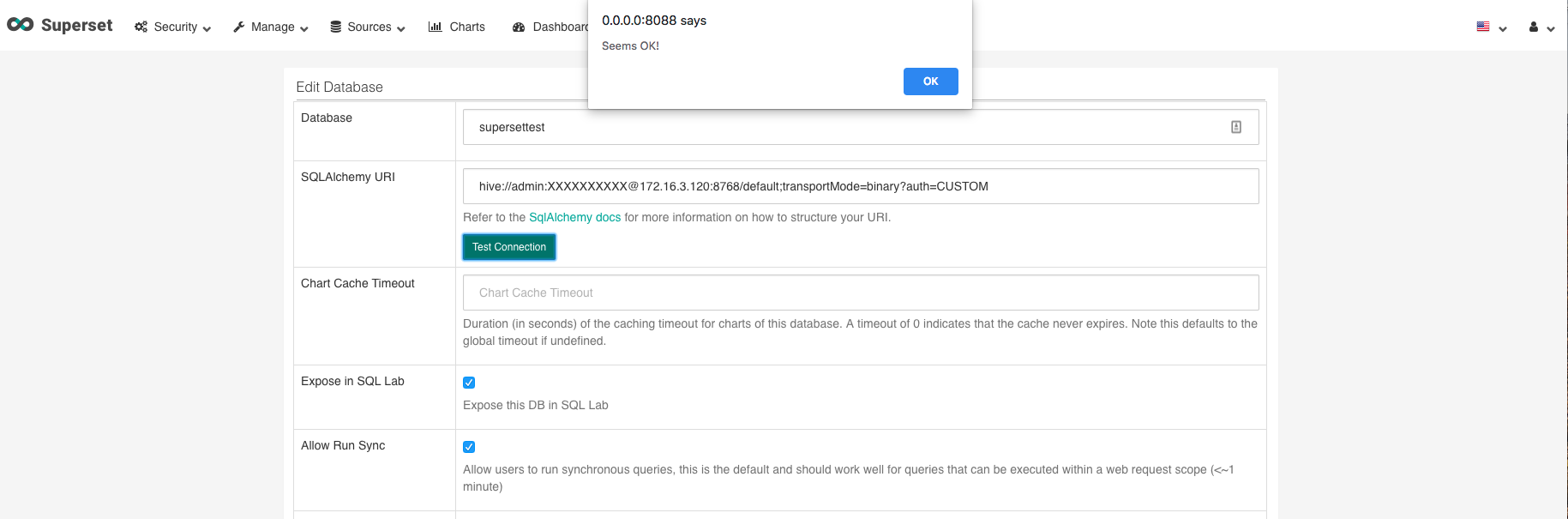
Klicken Sie dann auf die Schaltfläche „Speichern“.
Kehren Sie nach dem Speichern zur oberen Navigation zurück und klicken Sie auf Quellen > Tabellen. Im Feld Datenbank fügen Sie supersettest hinzu. Sie müssen auch ein Schema und einen Tabellennamen hinzufügen. Das Schema sollte Standard sein, während der Tabellenname der Name Ihrer Fusion-Sammlung sein sollte. In Fusion sehen Sie den Namen der Sammlung im Sammlungsmanager oben links in Fettschrift. Zu diesem Zeitpunkt sind keine weiteren Konfigurationen erforderlich.
Erstellen Sie Ihr erstes Chart
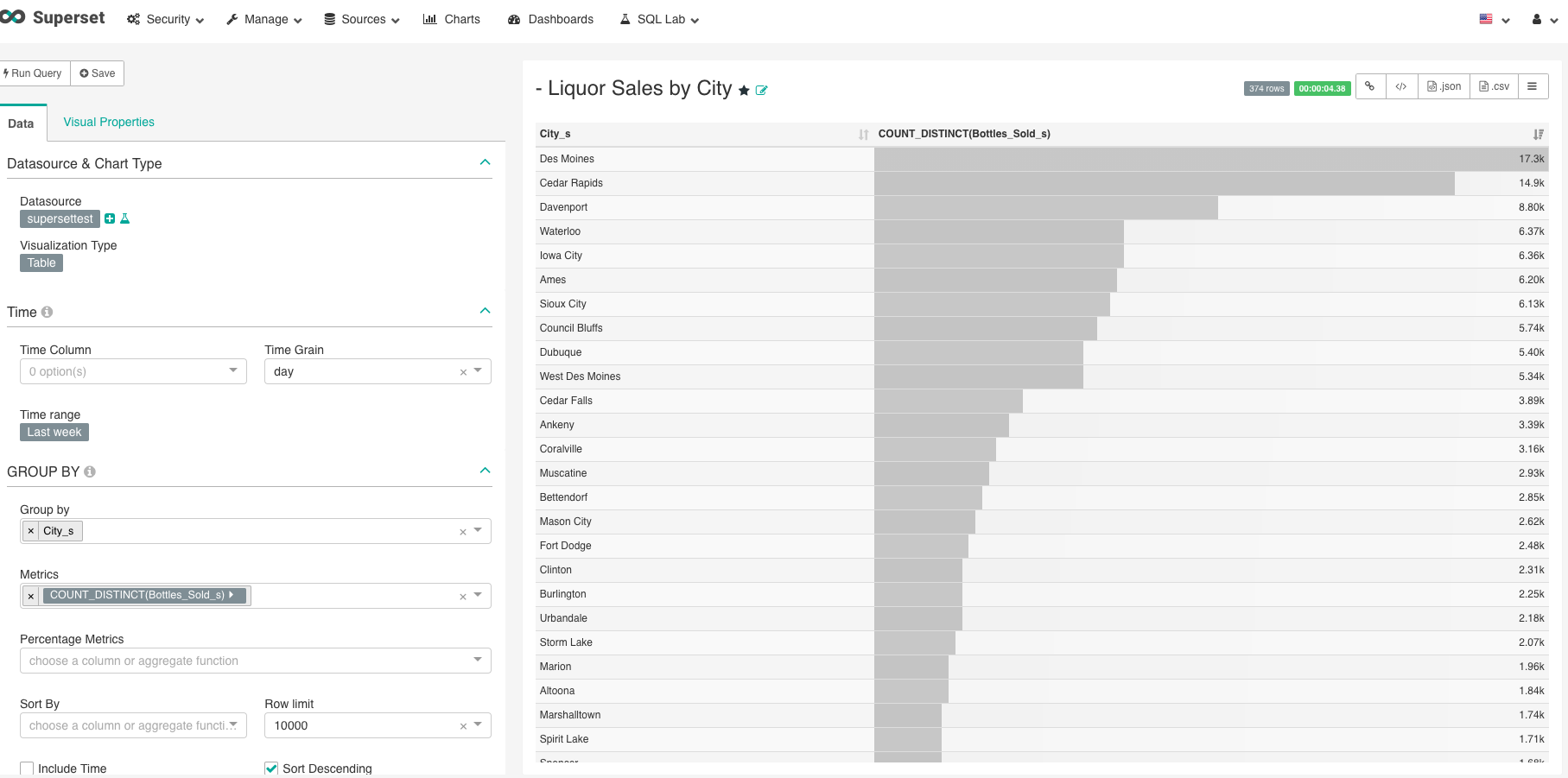
- Klicken Sie in der oberen Navigation auf Diagramme
- Klicken Sie auf das Pluszeichen oben rechts in der Listenansicht, rechts neben Filter hinzufügen
- Für Datasource wählen Sie supersettest
- Für Visualisierungstyp wählen Sie Tabelle
- Für Group_by wählen Sie „Stadt_s“.
- Wählen Sie für Metriken „Flaschen_verkauft_s“.
- Klicken Sie dann auf „Abfrage ausführen“.
- Profitieren Sie von einer sehr guten Datenvisualisierungssuite auf der Grundlage einer bewährten und robusten Datenverarbeitungs-Engine.
Wenn Sie Hilfe beim Debuggen dieser Integration oder bei Problemen mit diesem Tutorial benötigen, öffnen Sie ein Problem auf GitHub im Repo für dieses Tutorial oder kommentieren Sie diesen Beitrag.
Im nächsten Teil dieses Tutorials zeige ich Ihnen, wie Sie schnell eine große Datenmenge in einem Dokumentenkorpus für die Visualisierung in Apache Superset umwandeln können.
Mehr erfahren
- Lesen Sie Tableau, SQL und Suche für schnelle Datenvisualisierungen verwenden
- Kontaktieren Sie uns, wir helfen Ihnen gerne