
Das ABC des Rangordnungslernens
Beim Einkaufen genau das Richtige zu finden, kann anstrengend sein. Sie können Stunden damit verbringen, sich durch verwandte Ergebnisse zu wühlen, nur um dann frustriert aufzugeben. Vielleicht ist das der Grund, warum 79 Prozent der Menschen, denen das, was sie finden, nicht gefällt, das Schiff verlassen und eine andere Website aufsuchen.
Es muss einen besseren Weg geben, um Kunden mit einer besseren Website-Suche zu bedienen.
Und die gibt es. Learning to rank ist eine Methode des maschinellen Lernens, die Ihnen hilft, relevante Ergebnisse zu liefern und … warten Sie es ab … nach dieser Relevanz zu ranken.
Suchmaschinen nutzen das Lernen für das Ranking schon seit fast zwei Jahrzehnten. Sie fragen sich vielleicht, warum Sie noch nicht mehr darüber gehört haben.
Wie bei früheren Verfahren des maschinellen Lernens benötigten wir mehr Daten und verwendeten nur eine Handvoll von Merkmalen für das Ranking, darunter die Termhäufigkeit, die inverse Dokumenthäufigkeit und die Dokumentlänge.
79 Prozent der Menschen, denen das, was sie finden, nicht gefällt, werden das Schiff verlassen und eine andere Website suchen.
Also wurde von Hand getunt und immer wieder iteriert. Jetzt sind die Datenwissenschaftler die Erschöpften und nicht mehr die Käufer. Erschöpfung auf allen Seiten!
Heute haben wir größere Trainingssätze und bessere Möglichkeiten des maschinellen Lernens.
Aber es gibt immer noch Herausforderungen, insbesondere bei der Definition von Merkmalen, der Umwandlung von Suchkatalogdaten in praktische Trainingssätze, der Gewinnung relevanter Urteile, einschließlich expliziter Urteile von Menschen und impliziter Urteile auf der Grundlage von Suchprotokollen, und der Entscheidung, welche Zielfunktion für bestimmte Anwendungen optimiert werden soll.
Was ist Learning To Rank?
Learning to rank (LTR) ist eine Klasse von algorithmischen Techniken, die überwachtes maschinelles Lernen anwenden, um Ranking-Probleme bei der Relevanz von Websites zu lösen. Mit anderen Worten, es geht darum, die Suchergebnisse zu ordnen. Wenn es gut gemacht ist, haben Sie zufriedene Mitarbeiter und Kunden. Wenn es schlecht gemacht ist, haben Sie bestenfalls Frustrationen und schlimmer noch, sie kommen nie wieder.
Um Learning to Rank durchzuführen, benötigen Sie Zugang zu Trainingsdaten, Benutzerverhalten, Benutzerprofilen und eine leistungsstarke Suchmaschine wie SOLR.
Die Trainingsdaten für ein Learning-to-Rank-Modell bestehen aus einer Liste von Ergebnissen für eine Abfrage und einer Relevanzbewertung für jedes Ergebnis bezüglich der Abfrage. Datenwissenschaftler erstellen diese Trainingsdaten, indem sie die Ergebnisse untersuchen und entscheiden, ob sie jedes Ergebnis in den Datensatz aufnehmen oder ausschließen.
Dieser geprüfte Datensatz wird zum Goldstandard eines Modells, um Vorhersagen zu treffen. Wir nennen ihn die Grundwahrheit und messen unsere Vorhersagen an ihm.
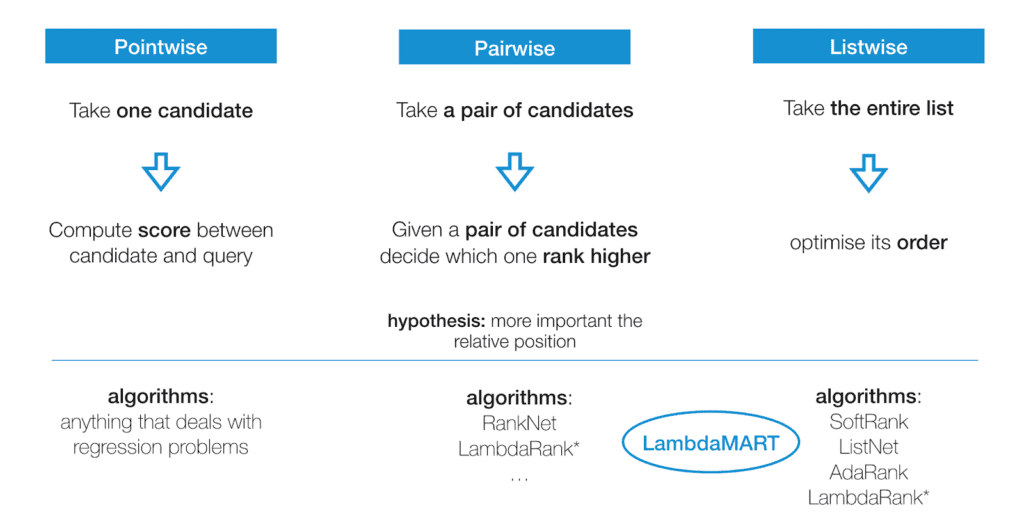
Punktweiser, paarweiser und listenweiser LTR-Ansatz
Die drei wichtigsten LTR-Ansätze sind punktweise, paarweise und listenweise.
Pointenweise
Punktuelle Ansätze betrachten ein einzelnes Dokument nach dem anderen und verwenden Klassifizierung oder Regression, um das beste Ranking für einzelne Ergebnisse zu ermitteln.
Klassifizierung bedeutet, dass ähnliche Dokumente in dieselbe Klasse eingeordnet werden – denken Sie an das Sortieren von Obst in Stapel nach Art: Erdbeeren, Brombeeren und Heidelbeeren gehören in den Beerenstapel (oder die Klasse), während Pfirsiche, Kirschen und Pflaumen in den Steinobstststapel gehören. (Video: Clustering vs. Klassifizierung)
Regression bedeutet, dass ähnlichen Dokumenten ein ähnlicher Funktionswert zugewiesen wird, um ihnen während des Ranking-Verfahrens ähnliche Präferenzen zuzuweisen.
Wir geben jedem Dokument Punkte dafür, wie gut es in diese Prozesse passt. Wir addieren diese Punkte und sortieren die Ergebnisliste. Beachten Sie hier, dass jede Dokumentbewertung in der Ergebnisliste für die Abfrage unabhängig von jeder anderen Dokumentbewertung ist, d.h. jedes Dokument wird als „Punkt“ für das Ranking betrachtet, unabhängig von den anderen „Punkten“.
Paarweise
Bei paarweisen Ansätzen werden zwei Dokumente zusammen betrachtet. Sie verwenden auch Klassifizierung oder Regression – um zu entscheiden, welches Paar höher eingestuft wird.
Wir vergleichen dieses höher-niedriger-Paar mit der „Ground Truth“ (dem Goldstandard für von Hand bewertete Daten, über den wir bereits gesprochen haben) und passen das Ranking an, wenn es nicht übereinstimmt. Das Ziel ist es, die Anzahl der Fälle zu minimieren, in denen das Ergebnispaar in der falschen Reihenfolge im Vergleich zur Basiswahrheit liegt (auch Invertierungen genannt).
Listwise
Listenweise Ansätze entscheiden über die optimale Reihenfolge einer ganzen Liste von Dokumenten. Es werden Ground-Truth-Listen ermittelt, und die Maschine verwendet diese Daten, um ihre Liste zu ordnen. Listenweise Ansätze verwenden Wahrscheinlichkeitsmodelle, um den Ordnungsfehler zu minimieren. Sie können im Vergleich zu den punktweisen oder paarweisen Ansätzen recht komplex werden.
Praktische Herausforderungen bei der Implementierung von Learning to Rank
Bevor Sie mit dem Bau Ihrer Modelle beginnen, müssen Sie sich entscheiden, welchen Ansatz Sie verfolgen wollen.
Ist es bei gleichen Daten besser, ein einziges Modell für alle zu trainieren oder mehrere Modelle für verschiedene Datensätze? Wie schneiden bekannte Modelle, die mit Hilfe der Rangfolge lernen, bei dieser Aufgabe ab?
Das müssen Sie auch tun:
- Entscheiden Sie sich für die Merkmale, die Sie darstellen möchten, und wählen Sie zuverlässige Relevanzurteile, bevor Sie Ihren Trainingsdatensatz erstellen.
- Wählen Sie das zu verwendende Modell und das zu optimierende Ziel.
Insbesondere sollten die trainierten Modelle in der Lage sein, zu generalisieren:
- Bisher ungesehene Abfragen, die nicht in der Trainingsmenge enthalten sind und
- Zuvor ungesehene Dokumente sollen für Abfragen im Trainingsset eingestuft werden.
- Außerdem verbessert eine Erhöhung der verfügbaren Trainingsdaten die Qualität des Modells, aber hochwertige Signale sind in der Regel spärlich, was zu einem Kompromiss zwischen der Quantität und der Qualität der Trainingsdaten führt.
Das Verständnis dieses Kompromisses ist entscheidend für die Erstellung von Trainingsdatensätzen.
Microsoft entwickelt Learning to Rank Algorithmen
Die Optionen für Learning-to-Rank-Algorithmen haben sich in den letzten Jahren erweitert, so dass Sie mehr Möglichkeiten haben, praktische Entscheidungen für Ihr Learning-to-Rank-Projekt zu treffen. Dies sind recht technische Beschreibungen, zögern Sie also nicht, uns bei Fragen zu kontaktieren.
RankNet, LambdaRank und LambdaMART sind beliebte Learning-to-Rank-Algorithmen, die von Forschern bei Microsoft Research entwickelt wurden. Alle verwenden ein paarweises Ranking.
RankNet führt die Verwendung des Gradientenabstiegs (GD) ein, um die Lernfunktion (Aktualisierung der Gewichte oder Modellparameter) für ein LTR-Problem zu lernen. Da der GD eine Gradientenberechnung erfordert, benötigt RankNet ein Modell, bei dem die Ausgabe eine differenzierbare Funktion ist – was bedeutet, dass ihre Ableitung immer an jedem Punkt in ihrem Bereich existiert (sie verwenden neuronale Netze, aber es kann jedes andere Modell mit dieser Eigenschaft sein).
Learning to rank (LTR) ist eine Klasse von algorithmischen Techniken, die überwachtes maschinelles Lernen anwenden, um Ranking-Probleme bei der Relevanz von Websites zu lösen. Mit anderen Worten, es geht darum, die Suchergebnisse zu ordnen. Wenn es gut gemacht ist, haben Sie zufriedene Mitarbeiter und Kunden. Wenn es schlecht gemacht ist, haben Sie bestenfalls Frustrationen, und schlimmer noch, sie kommen nie wieder.
RankNet ist ein paarweiser Ansatz und verwendet die GD, um die Modellparameter zu aktualisieren und die Kosten zu minimieren (RankNet wurde mit der Cross-Entropy-Kostenfunktion vorgestellt). Das ist so, als würden Sie die Kraft und die Richtung festlegen, die bei der Aktualisierung der Positionen der beiden Kandidaten angewendet werden soll (derjenige, der in der Liste weiter oben steht und der andere weiter unten, aber mit der gleichen Kraft). Als abschließende Optimierungsentscheidung beschleunigen sie den Prozess mit dem Mini-Batch Stochastic Gradient Descent (Berechnung aller Gewichtungsaktualisierungen für eine bestimmte Abfrage, bevor sie tatsächlich angewendet werden).
LambdaRank basiert auf der Idee, dass wir die gleiche Richtung (Gradient, der aus dem Kandidatenpaar geschätzt wird, definiert als Lambda) für den Tausch verwenden können, ihn aber bei jedem Schritt durch die Änderung der endgültigen Metrik, wie z.B. nDCG, skalieren (z.B. das Paar tauschen und sofort das nDCG-Delta berechnen). Dies ist ein sehr praktikabler Ansatz, da er jedes Modell (mit differenzierbarer Ausgabe) mit der Ranking-Metrik unterstützt, die wir in unserem Anwendungsfall optimieren möchten.
LambdaRank lehnt sich an LambdaMART an, basiert aber auf einer Familie von Modellen namens MART (Multiple Additive Regression Trees). Diese Modelle nutzen die Gradient Boosted Trees, eine Kaskade von Bäumen, bei der die Gradienten nach jedem neuen Baum berechnet werden, um die Richtung abzuschätzen, die die Verlustfunktion minimiert (der Beitrag des nächsten Baums skaliert das). Mit anderen Worten: Jeder Baum trägt zu einem Gradientenschritt in die Richtung bei, die die Verlustfunktion minimiert. Das Ensemble dieser Bäume ist das endgültige Modell (d.h. die Gradient Boosting Trees). LambdaMART verwendet dieses Ensemble, ersetzt aber den Gradienten durch den Lambda-Wert (Gradient, der anhand der Kandidatenpaare berechnet wird), der in LambdaRank dargestellt wird.
Dieser Algorithmus wird oft als paarweise betrachtet, da der Lambda-Wert Paare von Kandidaten berücksichtigt. Dennoch muss er die gesamte Rangliste kennen (d.h. er skaliert den Gradienten mit einem Faktor der nDCG-Metrik, die die gesamte Liste berücksichtigt) – mit einer offensichtlichen Eigenschaft eines listenweisen Ansatzes.
Lernen Sie, Anwendungen in der Industrie zu bewerten
Wayfair
In einem Beitrag in seinem Tech-Blog spricht Wayfair darüber, wie es das Lernen nutzt, um für Suchbegriffe zu ranken. Wayfair ist ein börsennotiertes E-Commerce-Unternehmen, das Haushaltswaren vertreibt. Die Suchtechnologie ist daher entscheidend für das Kundenerlebnis. Wayfair geht dieses Problem an, indem es LTR in Verbindung mit maschinellem Lernen und Techniken zur Verarbeitung natürlicher Sprache (NLP) einsetzt, um die Absicht eines Kunden zu verstehen und entsprechende Ergebnisse zu liefern.
Das Diagramm unten zeigt das Suchsystem von Wayfair. Sie extrahieren Textinformationen aus verschiedenen Datensätzen, darunter Nutzerbewertungen, Produktkataloge und Clickstreams. Anschließend werden verschiedene NLP-Techniken verwendet, um Entitäten zu extrahieren, Stimmungen zu analysieren und Daten zu transformieren.
Wayfair speist die Ergebnisse dann in die hauseigene Query Intent Engine ein, um die Absicht der Kunden bei einem Großteil der eingehenden Suchanfragen zu erkennen und viele Nutzer direkt auf die richtige Seite mit gefilterten Ergebnissen zu schicken. Wenn die Intent Engine keine direkte Übereinstimmung herstellen kann, wird das Modell der Stichwortsuche verwendet. An dieser Stelle kommt LTR zum Einsatz.
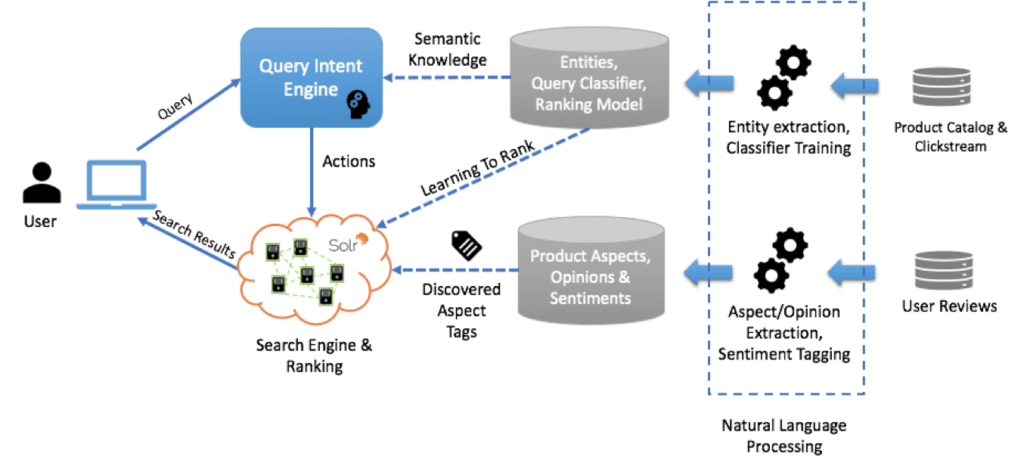
Bei der Schlüsselwortsuche gibt Wayfair die eingehende Suche so aus, dass sie Ergebnisse aus dem gesamten Produktkatalog liefert. Unter der Haube wurde ein LTR-Modell trainiert (das von Solr verwendet wird), um den einzelnen Produkten, die für die eingehende Suchanfrage zurückgegeben werden, eine Relevanzbewertung zuzuweisen. Wayfair trainiert dann sein LTR-Modell anhand von Clickstream-Daten und Suchprotokollen, um den Score für jedes Produkt vorherzusagen. Diese Punktzahlen bestimmen letztendlich die Position eines Produkts in den Suchergebnissen. Das Modell verbessert sich im Laufe der Zeit selbst, da es Feedback aus den täglich neu generierten Daten erhält.
Die Ergebnisse zeigen, dass dieses Modell die Konversionsrate von Wayfair bei Kundenanfragen verbessert hat
Slack
Das Team für Suche, Lernen und Intelligenz bei Slack nutzte LTR auch, um die Qualität der Suchergebnisse von Slack zu verbessern. Genauer gesagt haben sie eine personalisierte Relevanzsortierung und eine Bereichssuche namens Top-Ergebnisse entwickelt, die personalisierte und aktuelle Ergebnisse in einer Ansicht präsentiert. Beachten Sie hier, dass sich eine Suche in Slack von einer typischen Webseitensuche unterscheidet, da jeder Slack-Benutzer Zugriff auf einen einzigartigen Satz von Dokumenten hat und sich das, was zum jeweiligen Zeitpunkt relevant ist, häufig ändert.
Slack bietet zwei Strategien für die Suche: kürzlich und relevant. Die aktuelle Suche findet die Nachrichten, die mit allen Begriffen übereinstimmen, und zeigt sie dann in umgekehrter chronologischer Reihenfolge an. Bei der relevanten Suche wird die Altersbeschränkung gelockert und berücksichtigt, wie gut das Dokument den Suchbegriffen entspricht.
Die Mitarbeiter von Slack stellten fest, dass die relevante Suche etwas schlechter abschnitt als die kürzliche Suche, wenn man die Qualitätskennzahlen der Website-Suche betrachtet, wie z.B. die Anzahl der Klicks pro Suche und die Klickrate der Website-Suchergebnisse auf den ersten Positionen.
Die Einbeziehung zusätzlicher Funktionen würde das Ranking der Ergebnisse für relevante Suchen verbessern. Um dies zu erreichen, verwendet das Slack-Team einen zweistufigen Ansatz: (1) Nutzung der benutzerdefinierten Sortierfunktion von Solr, um eine Reihe von Nachrichten abzurufen, die nur nach den wenigen Merkmalen eingestuft sind, die für Solr leicht zu berechnen waren, und (2) Neueinstufung dieser Nachrichten in der Anwendungsschicht nach dem vollständigen Satz von Merkmalen, die entsprechend gewichtet sind. Bei der Erstellung eines Modells zur Bestimmung dieser Gewichte bestand die erste Aufgabe darin, einen beschrifteten Trainingssatz zu erstellen. Das Slack-Team nutzte die bereits erwähnte paarweise Technik, um die relative Relevanz von Dokumenten innerhalb einer einzelnen Suche anhand von Klicks zu beurteilen.
Dieser Ansatz wurde in das Modul für die Top-Ergebnisse von Slack integriert, das einen deutlichen Anstieg der Website-Suchsitzungen pro Benutzer, einen Anstieg der Klicks pro Suche und eine Verringerung der Suchvorgänge pro Sitzung zeigt. Dies deutet darauf hin, dass Slack-Benutzer das Gesuchte schneller finden können.
Skyscanner
Skyscanner, eine Reise-App, mit der Benutzer nach Flügen suchen und eine ideale Reise buchen können, verwendet LTR für die Suche nach Flugrouten.
Die Suchtechnologie der Website umfasst Preise, verfügbare Zeiten, Flüge mit Zwischenstopps, Reisezeitfenster und mehr. Skyscanner möchte seinen Nutzern helfen, die besten Flüge für ihre Situation zu finden.
Das Skyscanner-Team übersetzt das Problem der Rangfolge von Artikeln in eine binäre Regression. Sie bezeichnen ihre Daten über Artikel, die Nutzer als relevant für ihre Suchanfragen ansehen, als positive Beispiele und Daten über Artikel, die Nutzer als nicht relevant für ihre Suchanfragen ansehen, als negative Beispiele. Anschließend verwenden sie diese Daten, um ein maschinelles Lernmodell zu trainieren, das die Wahrscheinlichkeit vorhersagt, dass ein Nutzer einen Flug findet, der für die Suchanfrage auf der Website relevant ist. Genauer gesagt ist Relevanz definiert als die Verpflichtung, auf die Website der Fluggesellschaft und des Reisebüros zu klicken, um den Flug zu kaufen, da dies viele Handlungsschritte des Benutzers erfordert.
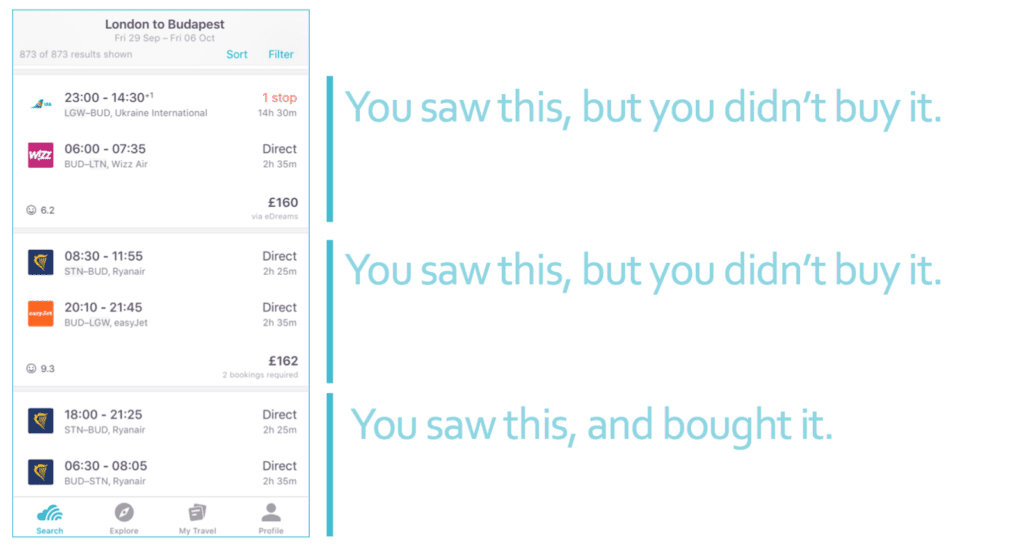
Nachdem sie LTR auf die Daten angewendet haben, führen sie Offline- und Online-Experimente durch, um die Leistung des Modells zu testen. Insbesondere vergleichen sie die Nutzer, die Empfehlungen mit maschinellem Lernen erhalten haben, mit denen, die Empfehlungen mit einer Heuristik erhalten haben, die nur den Preis und die Dauer berücksichtigt hat, und mit denen, die keine Empfehlungen erhalten haben. Die Ergebnisse deuten darauf hin, dass das LTR-Modell mit maschinellem Lernen zu besseren Konversionsraten führt – also dazu, wie oft Nutzer einen vom Skyscanner-Modell empfohlenen Flug kaufen würden.
Diese Beispiele zeigen, wie LTR-Ansätze die Site-Suche für Benutzer verbessern können.
Alle drei LTR-Ansätze vergleichen unklassifizierte Daten mit einem Datensatz der „goldenen Wahrheit“, um zu bestimmen, wie relevant die Suchergebnisse einer Website sind. Da die Datensätze weiter wachsen, wird auch die Genauigkeit von LTR zunehmen.
Weitere Lektüre zum Thema Learning to Rank und maschinelles Lernen bei der Suche sowie ein Video, das erklärt, wie LTR für das Ranking von Suchergebnissen verwendet wird.