Datenanalyse mit Fusion und Logstash
Lucidworks Fusion wird jetzt mit Plugins für Logstash ausgeliefert. In meinem letzten Beitrag über Log Analytics mit Fusion habe ich gezeigt, wie Fusion Dashboards eine interaktive Visualisierung von Zeitreihendaten anhand einer kleinen CSV-Datei mit bereinigten Server-Protokolldaten ermöglichen. Heute verwende ich Logstash, um die Logdateien von Fusion zu analysieren – echte, unordentliche Daten!
Logstash ist ein Open-Source-Tool für die Protokollverwaltung. Logstash nimmt Eingaben aus einer oder mehreren Protokolldateien entgegen, analysiert und filtert sie entsprechend einer Reihe von Konfigurationen und gibt einen Strom von JSON-Objekten aus, wobei jedes Objekt einem Protokollereignis entspricht. Fusion 1.4 wird mit einer Logstash-Bereitstellung und einer benutzerdefinierten Ruby-Klasse lucidworks_pipeline_output.rb ausgeliefert, die die Logstash-Ausgaben sammelt und sie zur Indizierung in eine Fusion-Sammlung an Solr sendet.
Logstash-Filter können verwendet werden, um Zeit- und Datumsformate zu normalisieren und so eine einheitliche Sicht auf eine Abfolge von Benutzeraktionen zu erhalten, die sich über mehrere Logdateien erstrecken. Wenn beispielsweise in einer E-Commerce-Anwendung die Suchanfragen der Benutzer vom Suchserver in einem bestimmten Format aufgezeichnet werden und die Aktionen des Benutzers beim Browsen vom Webserver in einem anderen Format aufgezeichnet werden, bietet Logstash eine Möglichkeit, diese Informationen zu normalisieren und zu einem klareren Bild des Benutzerverhaltens zu vereinheitlichen. Datums- und Zeitstempelformate sind einige der größten Probleme bei der Textverarbeitung. Fusion bietet eine benutzerdefinierte Datumsformatierung, denn Ihre Daten sind ein wichtiger Bestandteil Ihrer Daten. Bei der Analyse von Protokollen sind Zeitstempel die Schlüsseldaten, wenn die Visualisierung eine Zeitleiste enthält.
Um Logstash-Datensätze in Solr-Felddokumente abzubilden, benötigen Sie ein funktionierendes Logstash-Konfigurationsskript, das über Ihre Logdateien läuft. Wenn Sie neu in Logstash sind, brauchen Sie nicht in Panik zu geraten! Ich zeige Ihnen, wie Sie ein Logstash-Konfigurationsskript schreiben und es dann verwenden, um die eigenen Logdateien von Fusion zu indizieren. Alles, was Sie brauchen, ist eine laufende Instanz von Fusion 1.4 und Sie können dies zu Hause ausprobieren. Detaillierte Anweisungen finden Sie in der Online-Dokumentation von Fusion: Installieren von Lucidworks Fusion.
Fusion Komponenten und ihre Logdateien
Wie sehen die Protokolldateien von Fusion aus? Fusion integriert viele Open-Source- und proprietäre Tools in ein fehlertolerantes, flexibles und hoch skalierbares Such- und Indizierungssystem. Eine Fusion-Installation besteht aus den folgenden Komponenten:
- Solr – die Apache Open-Source-Suchmaschine Solr/Lucene.
- API – dieser Dienst wandelt Dokumente, Abfragen und Suchergebnisse um. Er kommuniziert direkt mit Solr, um die eigentliche Dokumentensuche und Indizierung durchzuführen.
- Connectors – der Connector-Dienst holt Rohdaten von externen Repositories ab und nimmt sie auf.
- UI – der Fusion UI-Dienst kümmert sich um die Benutzerauthentifizierung, so dass alle Aufrufe sowohl der browserbasierten GUI als auch der Fusion REST-API an die Fusion UI gehen. Die browserbasierten GUI-Steuerelemente übersetzen eine Benutzeraktion in die richtige Abfolge von Aufrufen an die API- und Connectors-Dienste und überwachen die Ergebnisse und geben Feedback dazu. REST-API-Aufrufe werden nach der Authentifizierung an die Backend-Dienste weitergeleitet.
Jede dieser Komponenten läuft als Prozess in ihrer eigenen JVM. Dies ermöglicht die Verteilung und Replizierung von Diensten auf verschiedene Server, um Leistung und Skalierbarkeit zu gewährleisten. Beim Start meldet Fusion seine Komponenten und die Ports, auf denen sie lauschen. Bei einer lokalen Installation mit nur einem Server und der Standardkonfiguration sieht die Ausgabe etwa so aus:
2015-04-10 12:26:44Z Starting Fusion Solr on port 8983 2015-04-10 12:27:14Z Starting Fusion API Services on port 8765 2015-04-10 12:27:19Z Starting Fusion UI on port 8764 2015-04-10 12:27:25Z Starting Fusion Connectors on port 8984
Alle Fusion-Dienste verwenden das Apache log4j-Protokollierungsprogramm. Bei der Standardbereitstellung von Fusion befinden sich die log4j-Direktiven in den Dateien: $FUSION/jetty/{service}/resources/log4j2.xml und die Logging-Ausgaben werden in Dateien geschrieben: $FUSION/logs/{service}/{service}.log Dabei steht service entweder für „api“, „connectors“, „solr“ oder „ui“ und $FUSION ist eine Abkürzung für den vollständigen Pfad zum obersten Verzeichnis des Fusion-Archivs. Wenn Sie z.B. den Fusion-Download in /opt/lucidworks entpackt haben, bezieht sich $FUSION auf das Verzeichnis /opt/lucidworks/fusion, auch bekannt als das Fusion-Home-Verzeichnis. Bei der Standardinstallation für jede dieser Komponenten sind die meisten Logfile-Meldungen auf „$INFO“ eingestellt, was zu einer Vielzahl von Logfile-Meldungen führt. Beim Start sendet Fusion ein paar hundert Meldungen an diese Protokolldateien. Wenn Sie Ihre Sammlung, Ihre Datenquelle und Ihre Pipeline konfiguriert haben, werden Sie eine Menge Daten haben, mit denen Sie arbeiten können!
Daten-Design: Logfile-Muster
Zunächst muss ich eine vorläufige Datenanalyse und ein Datendesign durchführen. Welche Logfile-Daten möchte ich extrahieren und analysieren?
Alle log4j2.xml Konfigurationsdateien für die Fusion-Dienste verwenden das gleiche Log4j-Muster:
<PatternLayout>
<pattern>%d{ISO8601} - %-5p [%t:%C{1}@%L] - %m%n</pattern>
</PatternLayout>
In der Log4j-Syntax folgt auf das Prozentzeichen ein Konvertierungsspezifizierer (denken Sie an printf im Stil von C). In diesem Muster werden die folgenden Konvertierungsspezifikationen verwendet:
- %d{ISO8601}: Datumsformat, mit Datumsspezifikation ISO8601
- %-5p : %p ist die Priorität des Protokollierungsereignisses, „-5“ steht für linksbündig, mit 5 Zeichen
- %t: thread
- %C{1}: %C gibt den vollständig qualifizierten Klassennamen des Aufrufers an, der die Protokollierungsanforderung stellt, {1} gibt die Anzahl der ganz rechten Komponenten des Klassennamens an.
- %L: Zeilennummer, in der diese Anfrage gestellt wurde
- %m: die von der Anwendung gelieferte Nachricht.
Hier sehen Sie, wie die resultierenden Meldungen in der Protokolldatei aussehen:
2015-05-21T11:30:59,979 - INFO [scheduled-task-pool-2:MetricSchedulesRegistrar@70] - Metrics indexing will be enabled 2015-05-21T11:31:00,198 - INFO [qtp1990213994-17:SearchClusterComponent$SolrServerLoader@368] - Solr version 4.10.4, using JavaBin protocol 2015-05-21T11:31:00,300 - INFO [solr-flush-0:SolrZkClient@210] - Using default ZkCredentialsProvider
Zunächst möchte ich den Zeitstempel, die Priorität des Protokollierungsereignisses und die von der Anwendung bereitgestellte Nachricht erfassen. Der Zeitstempel soll in einem Solr TrieDateField gespeichert werden, die Priorität des Ereignisses ist eine Reihe von Strings, die für die Facettierung verwendet werden, und die von der Anwendung bereitgestellte Nachricht soll als durchsuchbarer Text gespeichert werden. Ich möchte also in meinem Solr-Index Felder haben:
- log4j_Zeitstempel_tdt
- log4j_level_s
- log4j_message_t
Beachten Sie, dass diese Feldnamen alle Suffixe haben, die den Feldtyp kodieren: das Suffix „_tdt“ wird für Solr TrieDateFields verwendet, das Suffix „_s“ für Solr String-Felder und das Suffix „_t“ für Solr Textfelder.
Ein Grok-Filter wird auf die Eingabezeile(n) einer Protokolldatei angewendet und gibt ein Logstash-Ereignis aus, das eine Liste von Feld-Wert-Paaren ist, die durch Übereinstimmungen mit einem Grok-Muster erzeugt wurden. Ein Grok-Muster wird wie folgt angegeben: %{SYNTAX:SEMANTIC}, wobei SYNTAX das Muster ist, das abgeglichen werden soll, und SEMANTIC der Feldname im Logstash-Ereignis ist. Der für dieses Beispiel verwendete Logstash Grok-Filter ist:
%{TIMESTAMP_ISO8601:log4j_timestamp_tdt} *-* %{LOGLEVEL:log4j_level_s}s+*[*S+*]* *-* %{GREEDYDATA:log4j_msgs_t}
Dieser Filter verwendet drei Grok-Muster, um das log4j-Layout anzupassen:
- Das Logstash-Muster
TIMESTAMP_ISO8601entspricht dem log4j-Zeitstempelmuster%d{ISO8601}. - Das Logstash-Muster
LOGLEVELentspricht dem Prioritätsmuster%p. - Das Muster
GREEDYDATAkann verwendet werden, um alles abzugleichen, was in der Zeile steht.
Ich habe das Tool Grok Constructor verwendet, um meinen log4j Grok-Filter zu entwickeln und zu testen. Ich empfehle dieses Tool und die dazugehörige Website allen Logstash-Anfängern – ich habe eine Menge gelernt!
Um die Informationen von [thread:class@line] - zu überspringen, verwende ich die Regex "*[*S+*]* *-*". Hier wirken die Sternchen wie einfache Anführungszeichen, um Zeichen zu umgehen, die sonst syntaktisch sinnvoll wären. Diese Regex passt nicht auf Klassennamen, die Leerzeichen enthalten, aber sie scheitert konservativ, so dass das endgültige Greedy-Muster immer noch die gesamte Ausgabe der Anwendung erfasst.
Um diesen Filter auf meine Fusion-Logdateien anzuwenden, lautet das vollständige Logstash-Skript:
input {
file {
path => '/Users/mitzimorris/fusion/logs/ui/ui.log'
start_position => 'beginning'
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601} "
negate => true
what => previous
}
}
file {
path => '/Users/mitzimorris/fusion/logs/api/api.log'
start_position => 'beginning'
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601} "
negate => true
what => previous
}
}
file {
path => '/Users/mitzimorris/fusion/logs/connectors/connectors.log'
start_position => 'beginning'
codec => multiline {
pattern => "^%{TIMESTAMP_ISO8601} "
negate => true
what => previous
}
}
}
filter {
grok {
match => { 'message' => '%{TIMESTAMP_ISO8601:log4j_timestamp_tdt} *-* %{LOGLEVEL:log4j_level_s}s+*[*S+*]* *-* %{GREEDYDATA:log4j_msgs_t}' }
}
}
output {
}
Dieses Skript gibt die zu überwachenden Protokolldateien an. Da sich die Meldungen in den Logdateien über mehrere Zeilen erstrecken können, verwende ich für jede Logdatei einen Logstash codec, für mehrzeilige Dateien, entsprechend dem Beispiel in den Logstash-Dokumenten. Dieser Codec ist für alle Dateien gleich, muss aber auf jede Eingabedatei angewendet werden, um zu vermeiden, dass Zeilen aus verschiedenen Logdateien ineinander verschachtelt werden. Die eigentliche Arbeit wird in der filter Klausel durch den oben beschriebenen grok-Filter erledigt.
Indizierung von Logdateien mit Fusion und Logstash
Die Verwendung von Fusion zur Indizierung der Fusion-Protokolldateien erfordert Folgendes:
- Eine Fusion Collection, die die Logfile-Daten enthält
- Eine Fusion-Datenquelle, die die Logstash-Konfiguration zur Verarbeitung der Logdateien verwendet
- Eine Fusion Index Pipeline, die Logstash-Datensätze in ein Solr-Dokument umwandelt.
Fusion Kollektion: MyFusionLogfiles
Eine Fusion-Sammlung ist eine Solr-Sammlung plus eine Reihe von Fusion-Komponenten. Die Solr-Sammlung enthält alle Ihre Daten. Die Fusion-Komponenten umfassen zwei Fusion-Pipelines: eine für die Indizierung und eine für Suchanfragen.
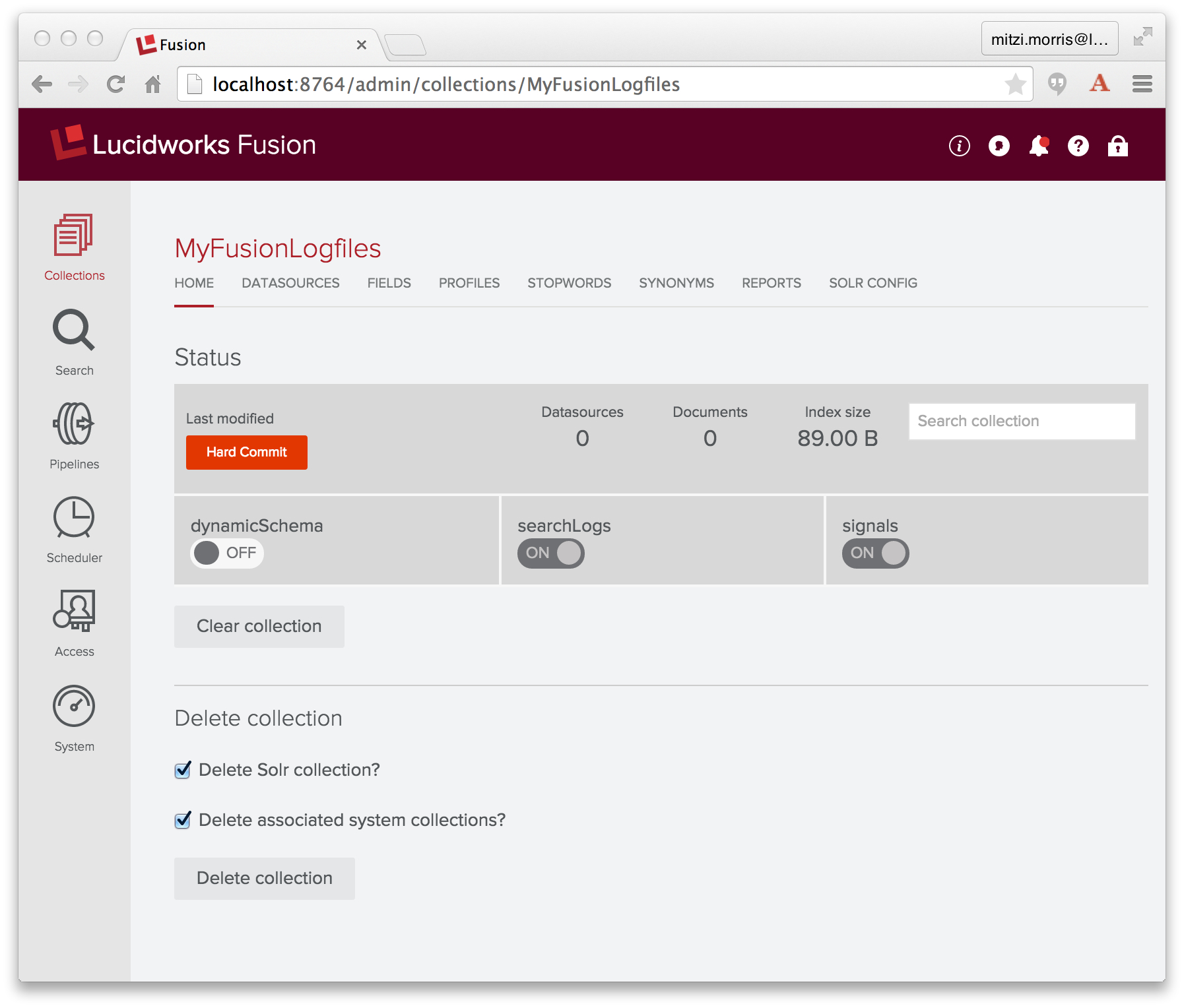
Ich erstelle eine Sammlung namens „MyFusionLogfiles“ mit dem Fusion UI Admin Tool. Fusion erstellt eine Indizierungspipeline mit dem Namen „MyFusionLogfiles-default“ sowie eine Abfragepipeline mit demselben Namen. Hier ist die ursprüngliche Sammlung:
Logstash Datenquelle: MyFusionLogfiles-datasource
Fusion ruft Logstash über eine Datenquelle auf, die für die Verbindung mit Logstash konfiguriert ist.
Datenquellen speichern Informationen darüber, wie Sie Daten einlesen können, und sie verwalten den laufenden Datenfluss in Ihre Anwendung: die Details des Datenspeichers, wie Sie auf den Speicher zugreifen, wie Sie Rohdaten zur Solr-Indizierung an eine Fusion-Pipeline senden und die Fusion-Sammlung, die den resultierenden Solr-Index enthält. Fusion zeichnet auch jedes Mal auf, wenn ein Datenquellenauftrag ausgeführt wird, und registriert die Anzahl der verarbeiteten Dokumente.
Datenquellen werden über das Fusion UI Admin Tool oder durch direkte Aufrufe der REST-API verwaltet. Das Admin Tool bietet eine Homepage für jede Sammlung sowie ein Datenquellen-Panel. Für die Sammlung „MyFusionLogfiles“ lautet die URL der Homepage der Sammlung: http://<server>:<port>/admin/collections/MyFusionLogfiles und die URL des Datenquellen-Panels lautet http://<server>:<port>/admin/collections/MyFusionLogfiles/datasources.
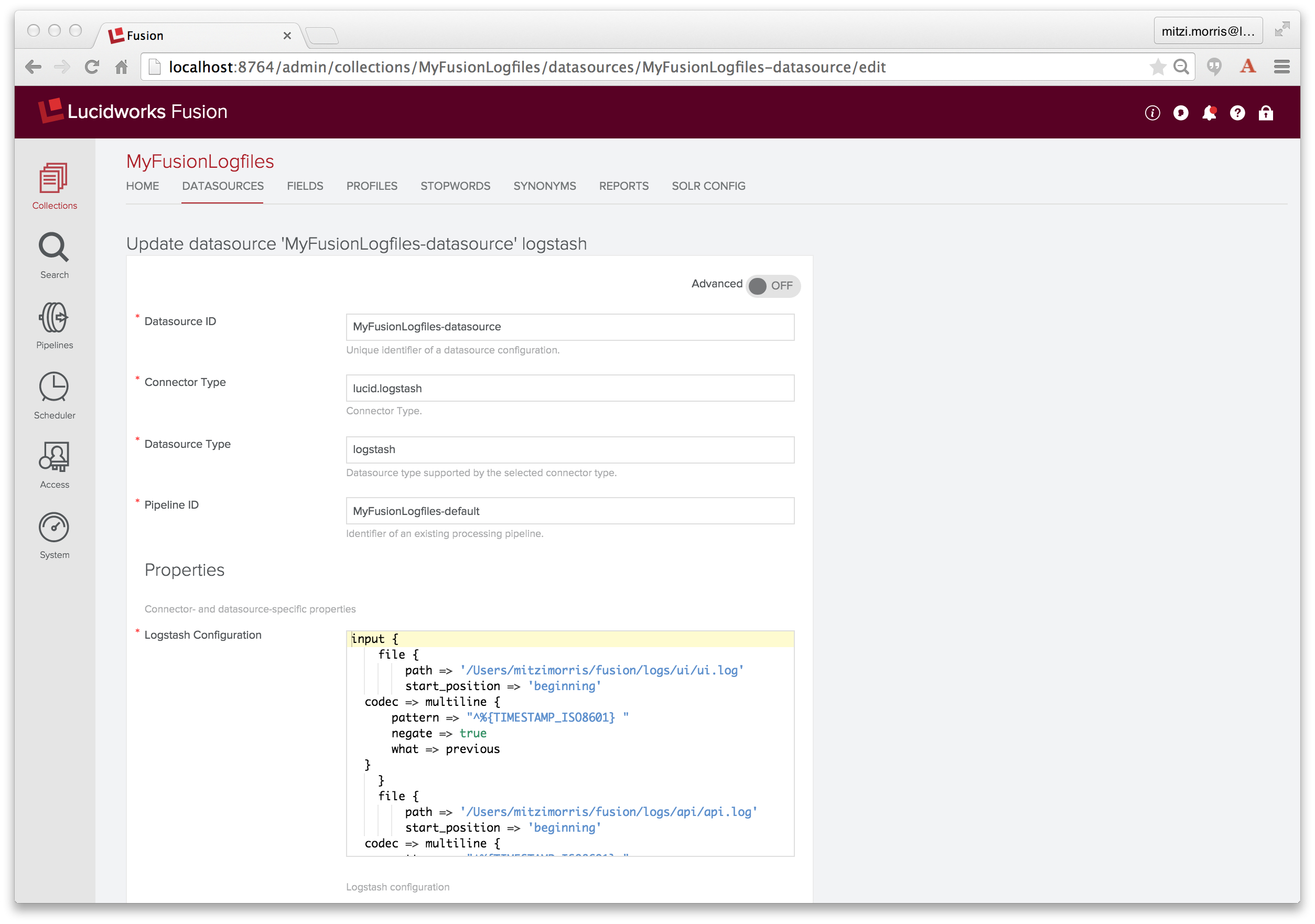
Um eine Logstash-Datenquelle zu erstellen, wähle ich die Datenquelle „Logging“ vom Typ „Logstash“. Im Konfigurationsfenster benenne ich die Datenquelle „MyFusionLogfiles-datasource“, gebe „MyFusionLogfiles-default“ als zu verwendende Index-Pipeline an und kopiere das Logstash-Skript in das Logstash-Konfigurations-Eingabefeld (das ein JavaScript-fähiges Texteingabefeld ist).
Index Pipeline: MyFusionLogfiles-default
Eine Index-Pipeline wandelt Logstash-Datensätze in feldbasierte Dokumente für die Indizierung durch Solr um. Fusion-Pipelines bestehen aus einer Abfolge von einer oder mehreren Stufen, wobei die Eingaben für eine Stufe die Ausgaben der vorherigen Stufe sind. Fusion-Phasen arbeiten mit PipelineDocument-Objekten, die die an die Pipeline übermittelten Daten in einer Liste von benannten Feld-Wert-Paaren organisieren (wie in einem früheren Blogbeitrag beschrieben). Alle PipelineDocument-Feldwerte sind Zeichenketten. Die Eingaben für die erste Stufe der Index-Pipeline sind die Ausgaben des Connectors. Die letzte Stufe ist eine Solr Indexer-Stufe, die ihre Ausgabe an Solr zur Indizierung in eine Fusion-Sammlung sendet.
Bei der Konfiguration der oben genannten Datenquelle habe ich die Indexpipeline „MyFusionLogfiles-default“ angegeben, die Indexpipeline, die zusammen mit der Sammlung „MyFusionLogfiles“ erstellt wurde, die, wie ursprünglich erstellt, aus einer Solr Indexer-Stufe besteht:
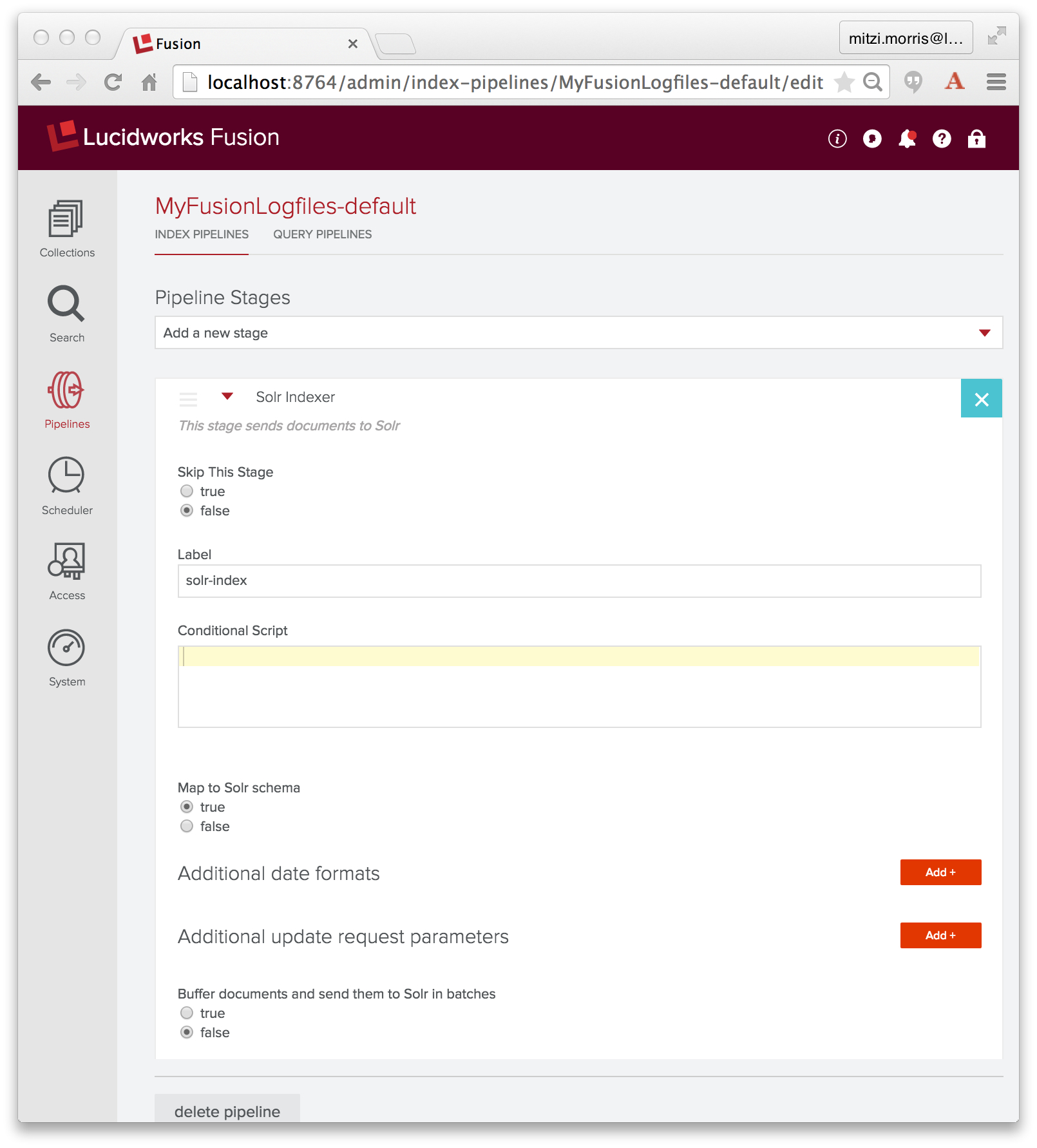
Die Aufgabe der Solr Indexer-Stufe besteht darin, das PipelineDocument in ein Solr-Dokument umzuwandeln. Solr bietet eine Vielzahl von Datentypen, darunter datetime und numerische Typen. Standardmäßig ist eine Solr Indexer-Stufe so konfiguriert, dass die Eigenschaft „enforceSchema“ auf true gesetzt ist, so dass die Solr Indexer-Stufe für jedes Feld im PipelineDocument den Feldnamen daraufhin überprüft, ob es sich um einen gültigen Feldnamen für das Solr-Schema der Sammlung handelt und ob der Feldinhalt in eine gültige Instanz des definierten Datentyps des Solr-Feldes umgewandelt werden kann oder nicht. Wenn der Feldname unbekannt ist oder das PipelineDocument-Feld als numerisches Solr-Feld oder Datetime-Feld erkannt wird, der Feldwert aber nicht in den richtigen Typ konvertiert werden kann, wandelt der Solr-Indexer den Feldnamen so um, dass der Feldinhalt der Sammlung als Textdatenfeld hinzugefügt wird. Das bedeutet, dass alle Ihre Daten in Solr indiziert werden, aber das Solr-Dokument möglicherweise nicht die Felder enthält, die Sie erwarten. Stattdessen befinden sich Ihre Daten in einem Feld mit einem automatisch generierten Feldnamen, das als Text indiziert ist.
Beachten Sie, dass ich oben den Grok-Filter sorgfältig spezifiziert habe, so dass die Feldnamen die Feldtypen kodieren: Feld „log4j_timestamp_tdt“ ist ein Solr TrieDateField, Feld „log4j_level_s“ ist ein Solr String-Feld und Feld „log4j_message_t“ ist ein Solr Textfeld.
Spoiler-Alarm: Das wird nicht funktionieren. Bleiben Sie dran für den Fehler und die Lösung.
Ausführen der Datasource
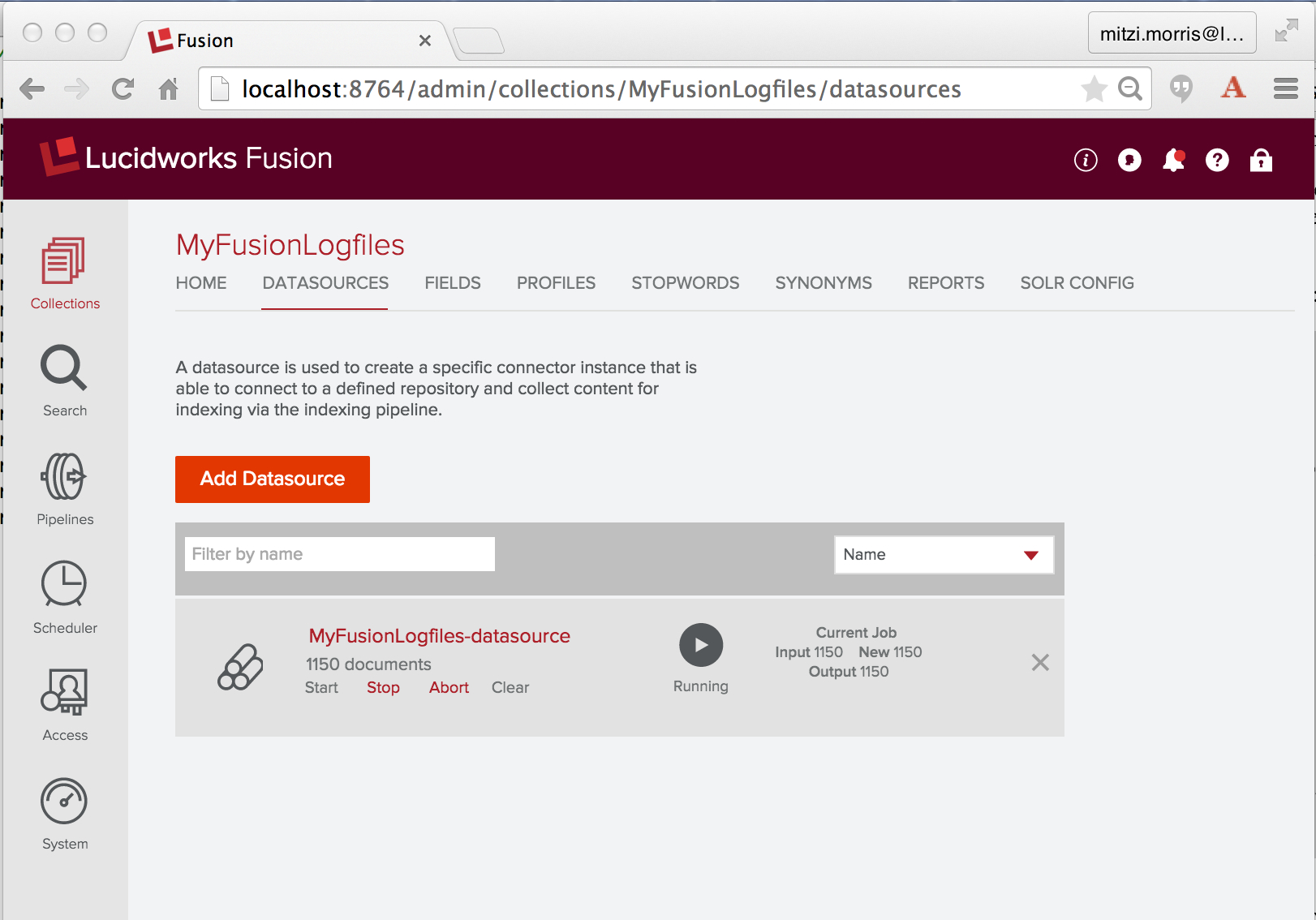
Um die Logstash-Daten aufzunehmen und zu indizieren, führe ich die konfigurierte Datenquelle mithilfe der Steuerelemente aus, die unter dem Namen der Datenquelle angezeigt werden. Hier sehen Sie einen Screenshot des Bereichs „Datenquellen“ des Fusion UI Admin Tools, während die Logstash-Datenquelle „MyFusionLogfiles-datasource“ ausgeführt wird:
Ein einmal gestarteter Logstash-Connector wird auf unbestimmte Zeit weiterlaufen. Da ich Fusion verwende, um seine eigenen Logdateien zu indizieren, einschließlich der Logdatei des Konnektors, wird die Ausführung dieser Datenquelle weiterhin neue Logdateieinträge für die Indizierung erzeugen. Bevor ich diesen Job starte, zähle ich kurz die Anzahl der Logfile-Einträge in den drei Logfiles, die ich indizieren werde:
> grep "^2015" api/api.log connectors/connectors.log ui/ui.log | wc -l 1537
Nach ein paar Minuten habe ich mehr als 2000 Dokumente indiziert, also klicke ich auf das Steuerelement „Stopp“. Dann gehe ich zurück zum „Home“-Bedienfeld und überprüfe meine Arbeit, indem ich eine Platzhaltersuche („*“) über die Sammlung „MyFusionLogfiles“ ausführe. Das erste Ergebnis sieht wie folgt aus:
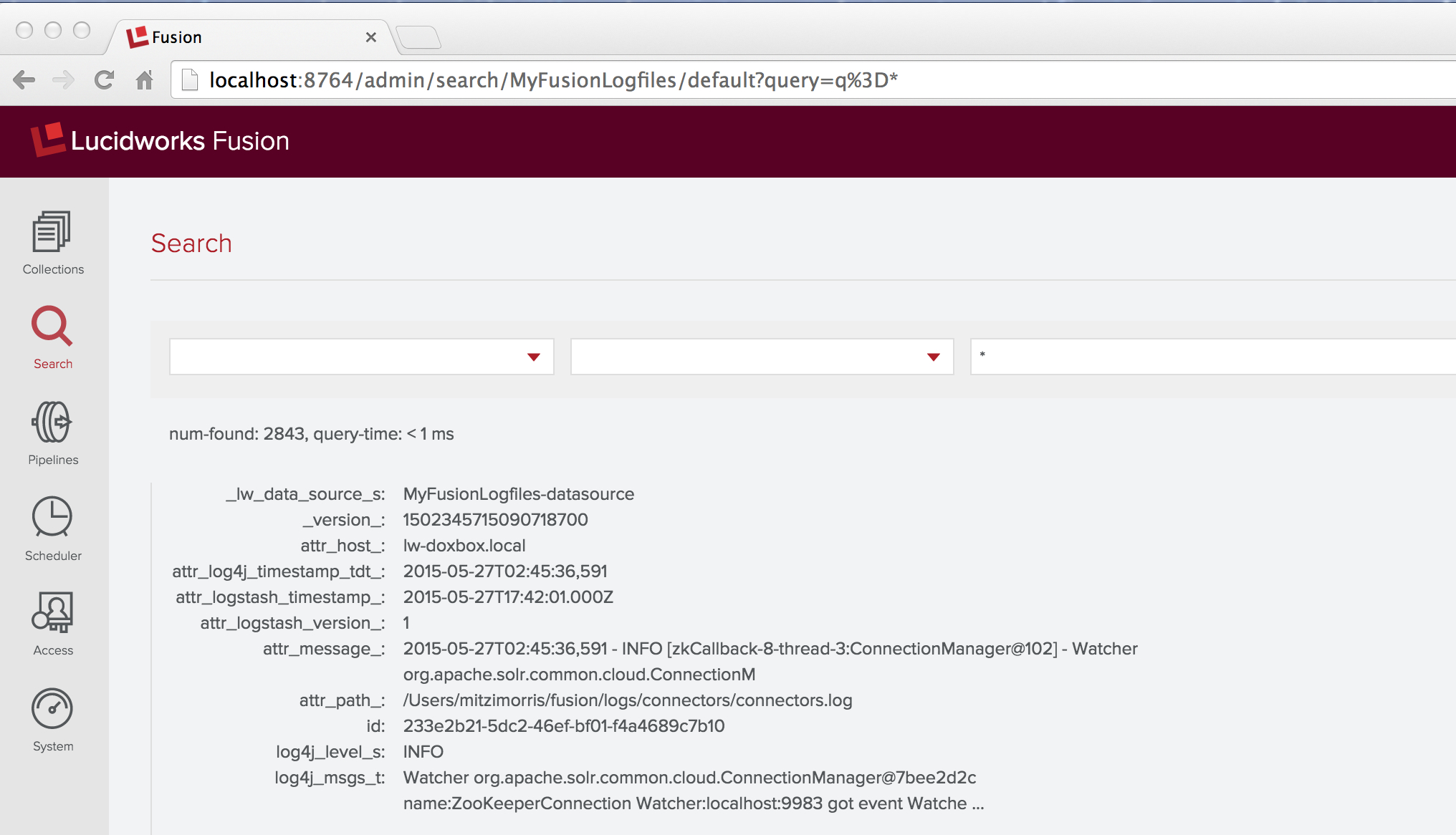
Dieses Ergebnis enthält den versprochenen Fehler. Die unbearbeitete Meldung in der Protokolldatei lautete:
2015-05-27T02:45:36,591 - INFO [zkCallback-8-thread-3:ConnectionManager@102] - Watcher org.apache.solr.common.cloud.ConnectionManager@7bee2d2c name:ZooKeeperConnection Watcher:localhost:9983 got event WatchedEvent state:Disconnected type:None path:null path:null type:None
Das Dokument enthält Felder mit den Namen „log4j_level_s“ und „log4j_msgs_t“, aber es gibt kein Feld mit dem Namen „log4j_timestamp_tdt“ – stattdessen gibt es ein Feld „attr_log4j_timestamp_tdt_“ mit dem Wert „2015-05-27T02:45:36,591“. Dies ist das Werk der Solr-Indexer-Stufe, die dieses Feld umbenannt hat, indem sie das Präfix „attr_“ sowie ein Suffix „_“ hinzugefügt hat. Die Solr-Schemas für Fusion-Sammlungen haben eine dynamische Felddefinition:
<dynamicField name="attr_*" type="text_general" indexed="true" stored="true" multiValued="true"/>
Dies erklärt die Besonderheiten des resultierenden Feldnamens und Feldtyps, aber es erklärt nicht , warum diese Neuzuordnung notwendig war.
Behebung des Fehlers
Warum ist der Log4j-Zeitstempel „2015-05-27T02:45:36,591“ kein gültiger Zeitstempel für Solr? Die Antwort ist, dass das Solr Datumsformat ist:
yyyy-MM-dd'T'HH:mm:ss.SSS'Z'
Z‘ ist der spezielle Bezeichner für die Koordinierte Weltzeit (UTC). Da Lucene/Solr Bereichsabfragen über Zeitstempel erfordern, dass Zeitstempel streng vergleichbar sind, müssen alle Datumsangaben in UTC ausgedrückt werden. Der Log4j-Zeitstempel wirft zwei Probleme auf:
- der Log4j-Zeitstempel verwendet ein Komma als Trennzeichen zwischen Sekunden und Millisekunden
- dem Log4j-Zeitstempel fehlt das ‚Z‘ und er enthält keine Zeitzoneninformationen.
Das erste Problem ist nur ein einfaches Formatierungsproblem. Das zweite Problem ist nicht trivial: Die Log4j-Zeitstempel sind nicht in UTC, sondern werden als aktuelle Ortszeit des Rechners ausgedrückt, auf dem der instrumentierte Code läuft. Glücklicherweise kenne ich die Zeitzone, da dies auf meinem Laptop lief, der auf die Zeitzone EDT (Eastern Daylight Time, UTC -0400) eingestellt ist.
Da Datums-/Zeitdaten ein wichtiger Datentyp sind, bietet Fusion eine Date Parsing-Indexstufe, die Datums-/Zeitdaten in Dokumentfeldern analysiert und normalisiert. Um dieses Problem zu beheben, füge ich der Index-Pipeline „MyFusionLogfiles-default“ eine Date-Parsing-Stufe hinzu, in der ich das Quellfeld als „log4j_timestamp_tdt“, das Datumsformat als „yyyy-MM-dd’T’HH:mm:ss,SSS“ und die Zeitzone als „EDT“ festlege:
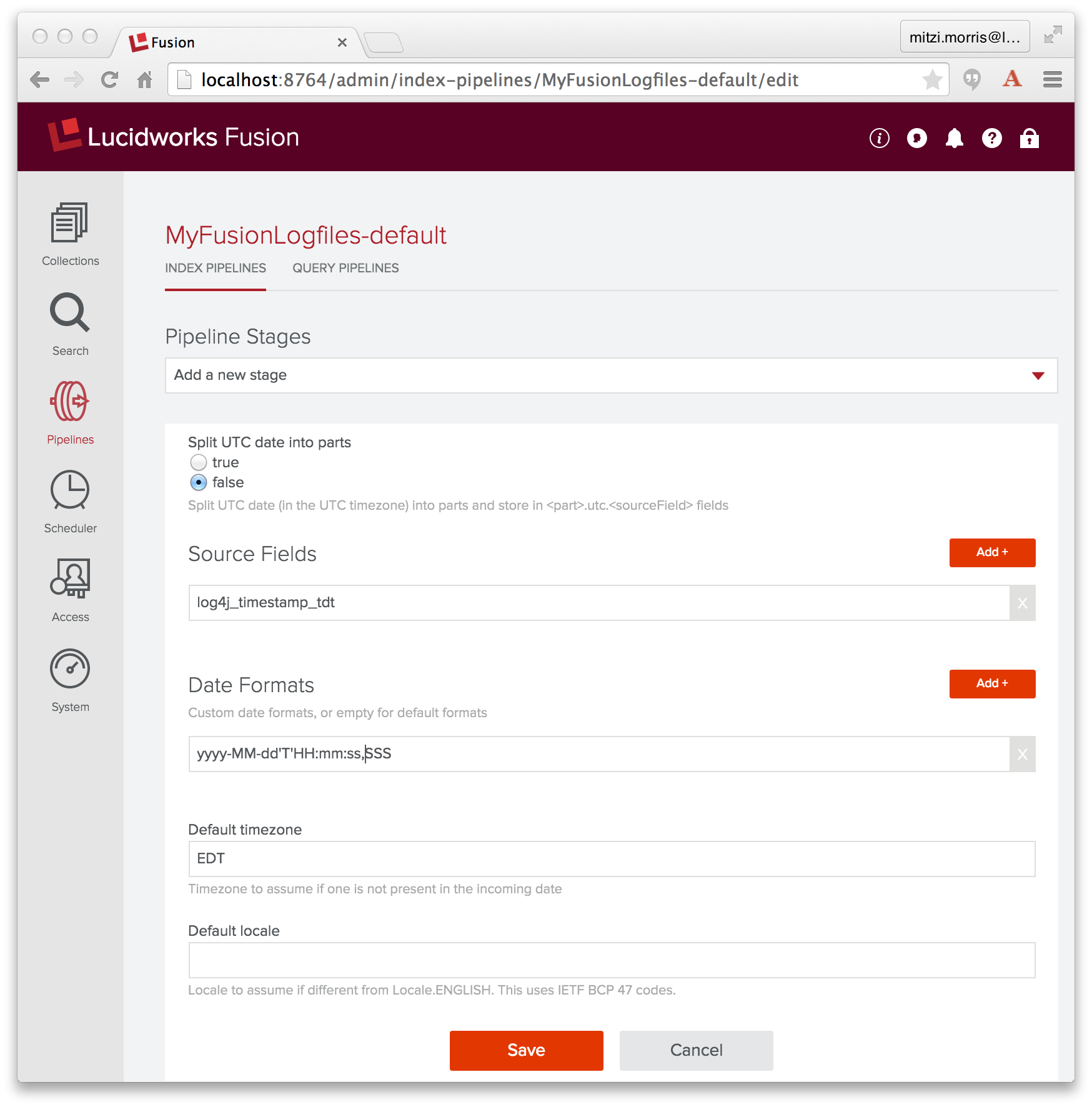
Diese Stufe muss vor der Solr Indexer-Stufe liegen. In der Fusion-Benutzeroberfläche wird ein neuer Schritt am Ende der Pipeline eingefügt. Ich muss also die Pipeline neu anordnen, indem ich den Schritt „Date Parsing“ so verschiebe, dass er vor dem Schritt „Solr Indexer“ steht.
Sobald diese Änderung erfolgt ist, lösche ich sowohl die Sammlung als auch die Datenquelle und führe den Indizierungsauftrag erneut aus. Ein ärgerliches Detail für den Logstash-Connector ist, dass ich zum Löschen der Datenquelle die Logstash-„since_db“-Dateien auf der Festplatte ausfindig machen muss, in denen die letzte gelesene Zeile in jeder der Logstash-Eingabedateien gespeichert ist (bekanntes Problem, CONN-881). Auf meinem Rechner finde ich in meinem Home-Verzeichnis ein Trio versteckter Dateien mit Namen, die mit „.sincedb_“ beginnen, gefolgt von IDs wie „1e63ae1742505a80b50f4a122e1e0810“, und lösche sie.
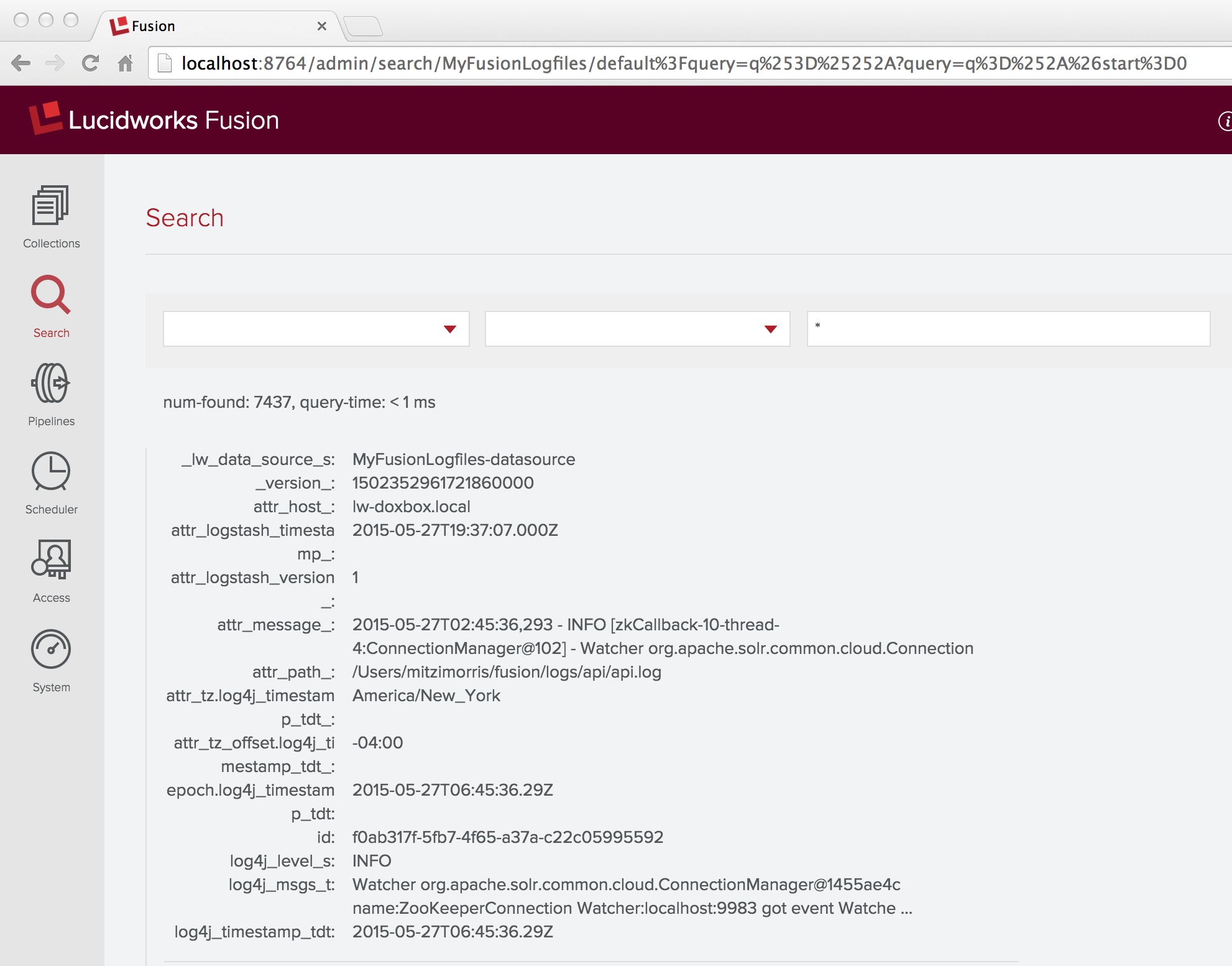
Problem gelöst! Eine Wildcard-Suche über alle Dokumente in der Sammlung „MyFusionLogfiles“ zeigt, dass die Menge der Dokumentfelder das Feld „log4j_timestamp_tdt“ enthält, zusammen mit mehreren Feldern, die von der Date Parsing Indexstufe hinzugefügt wurden:
Gelernte Lektionen
Mehr als 90% der Datenanalyse ist Datenmist, weil die Daten nie so sauber zusammenpassen, wie sie sollten.
Wenn Sie diese Tatsache erst einmal akzeptiert haben, werden Sie die Leistungsfähigkeit und Flexibilität der Fusion Pipeline-Indexstufen sowie die Leistungsfähigkeit und den Komfort der Tools auf der Fusion-Benutzeroberfläche zu schätzen wissen.
Fusion Log Analytics mit Fusion
Fusion Dashboards bieten interaktive Visualisierungen für Ihre Daten. Dies ist eine Wiederholung der Informationen in meinem vorherigen Beitrag über Log Analytics mit Fusion, in dem ich eine kleine CSV-Datei mit bereinigten Server-Logdaten verwendet habe. Jetzt, da ich drei Logdateien mit Daten habe, werde ich ein ähnliches Dashboard erstellen.
Das Tool Fusion Dashboards ist das Symbol ganz rechts auf der Fusion UI Launchpad-Seite. Sie können es direkt aufrufen unter: http://localhost:8764/banana/index.html#/dashboard. Wenn Sie das Dashboards-Tool über das Fusion-Launchpad öffnen, wird es in einer neuen Registerkarte mit der Bezeichnung „Banana 3“ angezeigt. Zeitserien-Dashboards zeigen Trends im Laufe der Zeit an, indem sie das Zeitstempelfeld zur Aggregation von Abfrageergebnissen verwenden. Um ein Zeitserien-Dashboard über die Sammlung „MyFusionLogfiles“ zu erstellen, klicke ich auf das Symbol für eine neue Seite in der oberen rechten Ecke des oberen Menüs und wähle die Option zum Erstellen eines neuen Zeitserien-Dashboards, wobei ich „MyFusionLogfiles“ als Sammlung und „log4j_timestamp_tdt“ als Feld angebe. Ich ändere das standardmäßige Zeitreihen-Dashboard erneut, indem ich ein Tortendiagramm hinzufüge, das die Aufschlüsselung der Protokollierungsereignisse nach Priorität zeigt:
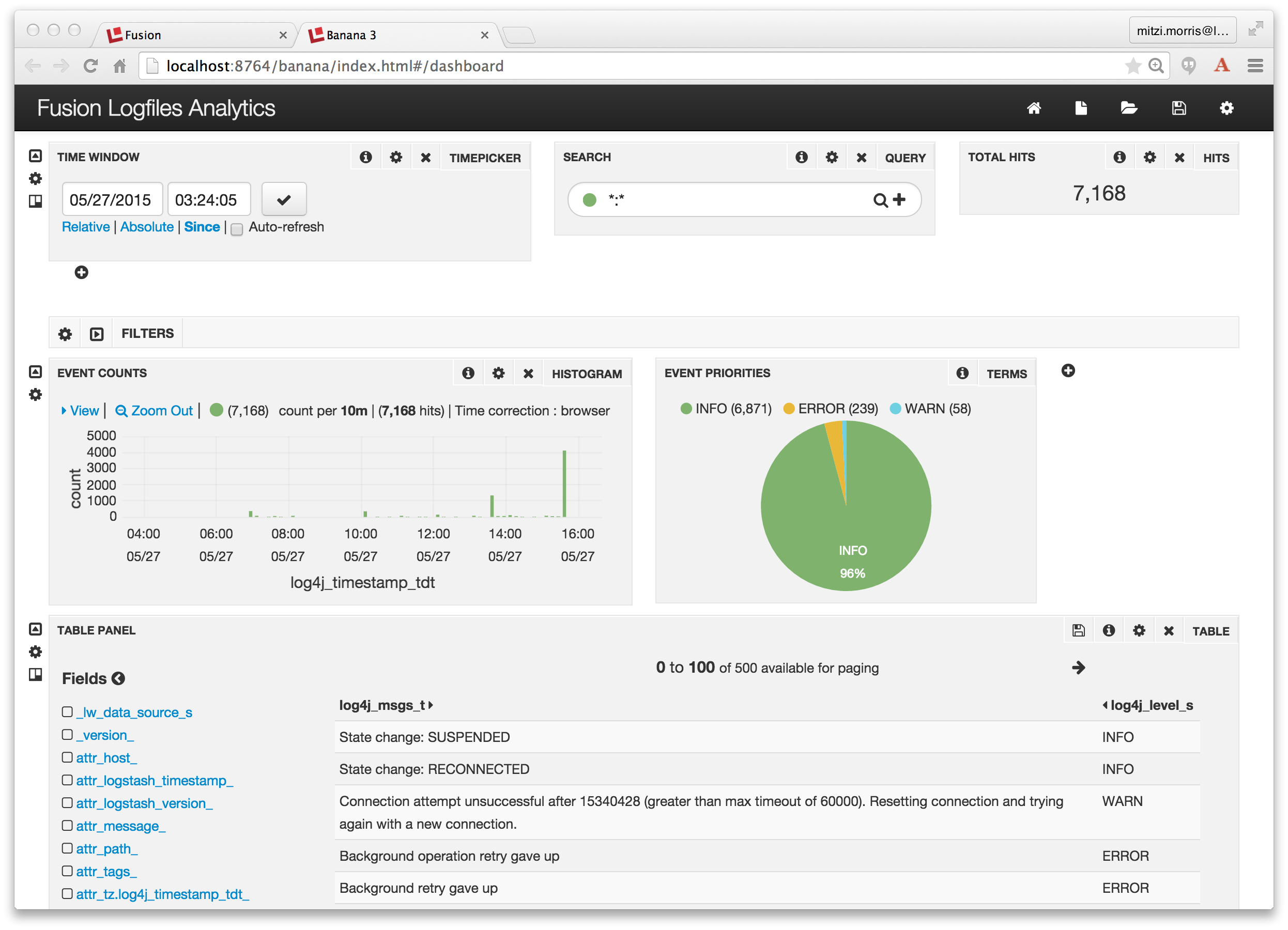
Et voilà! Es funktioniert einfach alles!