Einführung in das Solr Scale Toolkit
SolrCloud ist eine Reihe von Funktionen in Apache Solr, die eine elastische Skalierung von verteilten Suchindizes durch Sharding und Replikation ermöglichen. Eine der Hürden für die Einführung von SolrCloud war das Fehlen von Tools für die Bereitstellung und Verwaltung eines SolrCloud-Clusters. In diesem Beitrag stelle ich das Solr Scale Toolkit vor, ein von Lucidworks(lucidworks.com) gesponsertes Open-Source-Projekt, das Tools und Anleitungen für die Bereitstellung und Verwaltung von SolrCloud auf Cloud-basierten Plattformen wie Amazon EC2 bietet. Im letzten Abschnitt verwende ich das Toolkit, um einige Leistungsvergleiche mit Solr 4.8.1 durchzuführen, um zu sehen, wie „skalierbar“ Solr wirklich ist.
Motivation
Wenn Sie eine aktuelle Version von Solr herunterladen (4.8.1 ist zum Zeitpunkt der Erstellung dieses Artikels die neueste), ist es eigentlich ganz einfach, einen SolrCloud-Cluster auf Ihrem lokalen Arbeitsplatzrechner zum Laufen zu bringen. Solr ermöglicht es Ihnen, eine eingebettete ZooKeeper-Instanz zu starten, um den „Cloud“-Modus mit einer einfachen Befehlszeilenoption zu aktivieren: -DzkRun. Wenn Sie dies noch nicht getan haben, empfehle ich Ihnen, den Anweisungen im Solr-Referenzhandbuch zu folgen: https://cwiki.apache.org
Wenn Sie sich erst einmal mit SolrCloud vertraut gemacht haben, werden Sie schnell feststellen, dass Sie Tools benötigen, die Sie bei der Automatisierung der Bereitstellung und der Systemadministration auf mehreren Servern unterstützen. Sobald Sie einen gut konfigurierten Cluster zum Laufen gebracht haben, gibt es außerdem laufende Systemwartungsaufgaben, die ebenfalls automatisiert werden sollten, wie z.B. rollierende Neustarts, externe Backups oder einfach nur der Versuch, eine Fehlermeldung in mehreren Protokolldateien auf verschiedenen Servern zu finden.
Bislang mussten die meisten Unternehmen den Betrieb von SolrCloud mit Tools wie Chef oder Puppet in eine bestehende Umgebung integrieren. Dies sind zwar immer noch gültige Ansätze, aber das Solr Scale Toolkit bietet eine einfache, Python-basierte Lösung, die leicht zu installieren und zu verwenden ist, um SolrCloud zu verwalten. In den verbleibenden Abschnitten dieses Beitrags führe ich Sie durch einige der wichtigsten Funktionen des Toolkits und lade Sie dazu ein, mitzumachen. Um das Toolkit zu verwenden, müssen Sie zunächst ein wenig einrichten.
Installation und Einrichtung
Es gibt drei grundlegende Schritte, um mit dem Solr Scale Toolkit auf Ihrer lokalen Workstation zu beginnen:
- Richten Sie ein Amazon Web Services (AWS)-Konto ein und konfigurieren Sie ein Schlüsselpaar für den Zugriff auf Instanzen über SSH
- Python-Abhängigkeiten installieren
- Klonen Sie das Solr Scale Toolkit von github und erstellen Sie das Projekt mit Maven
Amazon-Konto einrichten
Zunächst benötigen Sie ein Amazon Web Services-Konto. Wenn Sie kein Amazon AWS-Konto haben, müssen Sie eines einrichten, bevor Sie das Solr Scale Toolkit verwenden, siehe: http://docs.aws.amazon.com
Hinweis: Das Solr Scale Toolkit funktioniert vorerst nur mit Linux in Amazon Web Services, aber wir planen, in naher Zukunft auch andere Cloud-Anbieter zu unterstützen, indem wir das Apache libcloud-Projekt nutzen. https://libcloud.apache.org/
Das Toolkit erfordert einige Einrichtungsaufgaben, die Sie in der AWS-Konsole durchführen können. Zunächst müssen Sie eine Sicherheitsgruppe namens solr-scale-tk einrichten. Sie sollten mindestens den TCP-Verkehr zu den Ports zulassen: 8983-8985, SSH (22) und 2181 (ZooKeeper). Es liegt natürlich in Ihrer Verantwortung, die Sicherheitskonfiguration Ihres Clusters zu überprüfen und ihn entsprechend zu sperren. Die anfänglichen Einstellungen dienen lediglich dazu, Ihnen den Einstieg in die Nutzung des Toolkits zu erleichtern.
Außerdem müssen Sie ein Schlüsselpaar namens solr-scale-tk erstellen. Nachdem Sie die Datei des Schlüsselpaars (solr-scale-tk.pem) heruntergeladen haben, speichern Sie sie in ~/.ssh/ und ändern Sie die Berechtigungen mit:
chmod 600 ~/.ssh/solr-scale-tk.pem
Python-Abhängigkeiten
Sie benötigen Python 2.7.x auf Ihrem lokalen Arbeitsplatzrechner. Um zu überprüfen, welche Python-Version Sie verwenden, öffnen Sie eine Befehlszeilen-Shell und führen Sie aus: python –version. Auf meinem Mac lautet die Ausgabe:
[~]$ python --version Python 2.7.2
Wenn Sie Python nicht zur Verfügung haben, finden Sie auf dieser Seite Hilfe bei der Einrichtung für Ihr spezifisches Betriebssystem. https://www.python.org
Das Solr Scale Toolkit hängt von Fabric ab, einem Python-basierten Tool, das die Verwendung von SSH für die Anwendungsbereitstellung oder Systemadministrationsaufgaben rationalisiert. Eine Anleitung zur Installation von Fabric finden Sie unter http://fabric.readthedocs.org
Nach der Installation von Fabric müssen Sie die Python-Bibliothek boto für die Arbeit mit Amazon Web Services installieren. In den meisten Fällen können Sie dies mit pip install boto tun, aber weitere Informationen zur Installation von boto finden Sie unter https://github.com
cat ~/.boto [Credentials] aws_access_key_id = YOUR_ACCESS_KEY_HERE aws_secret_access_key = YOUR_SECRET_KEY_HERE
Weitere Informationen über Amazon-Zugangsschlüssel finden Sie unter: http://docs.aws.amazon.com
Als nächstes klonen Sie das pysolr-Projekt von github und installieren es mit:
git clone https://github.com/toastdriven /pysolr.git cd pysolr sudo python setup.py install
Das Solr Scale Toolkit verwendet pysolr, um grundlegende Operationen wie Abfragen und Übertragungen unter Verwendung der Solr HTTP API durchzuführen. Wenn Sie git nicht installiert haben, schauen Sie bitte unter: https://help.github.com
Klonen Sie das Solr Scale Toolkit github Projekt
Nachdem Sie nun Ihr Amazon-Konto und die Python-Abhängigkeiten korrekt eingerichtet haben, können Sie das Solr Scale Toolkit einrichten.
Klonen Sie das Projekt von github: https://github.com
Nach dem Klonen wechseln Sie in das Verzeichnis solr-scale-tk und führen aus: fab -l
Sie sollten eine Liste der verfügbaren Fabric-Befehle sehen, die vom Toolkit bereitgestellt werden.
Erstellen Sie die Solr Scale Toolkit JAR-Datei mit: mvn clean package.
Wenn Sie Maven nicht installiert haben, lesen Sie bitte: http://maven.apache.org
Puh! Sie sind nun bereit, das Solr Scale Toolkit für die Bereitstellung und Verwaltung eines SolrCloud-Clusters zu verwenden.
Starten von Instanzen
Eine der wichtigsten Aufgaben bei der Planung der Verwendung von SolrCloud besteht darin, zu bestimmen, wie viele Server Sie für Ihren Index bzw. Ihre Indizes benötigen. Leider gibt es keine einfache Formel, um dies zu bestimmen, da zu viele Variablen beteiligt sind. Die meisten erfahrenen SolrCloud-Benutzer sind sich jedoch einig, dass die einzige Möglichkeit, die Rechenressourcen für Ihren Produktionscluster zu bestimmen, darin besteht, mit Ihren eigenen Daten und Abfragen zu testen. In diesem Blog zeige ich Ihnen also, wie Sie die Rechenressourcen für einen kleinen Cluster bereitstellen, aber Sie sollten wissen, dass derselbe Prozess auch für größere Cluster funktioniert. In der Tat wurde das Toolkit entwickelt, um SolrCloud in großem Maßstab testen zu können. Ich überlasse es den Lesern, die Größe des Clusters selbst zu planen
.
Für diesen Beitrag planen wir den Start eines SolrCloud-Clusters mit zwei m3.xlarge-Instanzen und drei m3.medium-Instanzen für das Hosting eines ZooKeeper-Ensembles. Wir planen, zwei Solr-Knoten pro Instanz zu betreiben, so dass wir insgesamt 4 Solr-Knoten in unserem Cluster haben. Jeder Solr-Knoten wird über eine dedizierte SSD verfügen.
Das folgende Diagramm veranschaulicht unseren geplanten Cluster.

Eine der wichtigsten Entscheidungen bei der Entwicklung des Toolkits war die Verwendung eines eigenen AMI. Derzeit basiert das AMI auf RedHat Enterprise Linux 6.4. Auf dem benutzerdefinierten AMI sind Java, Solr 4.8.1, ZooKeeper 3.4.6 sowie einige zusätzliche Dienste, wie z.B. collectd, installiert. Die Idee hinter der Verwendung eines benutzerdefinierten AMI ist, dass Sie Kerndienste wie Java nicht jedes Mal einrichten müssen, wenn Sie eine neue Instanz starten. Wenn Sie kein Fan von RedHat sind, machen Sie sich keine Sorgen, denn wir planen, in naher Zukunft weitere Linux-Varianten wie Debian zu unterstützen.
Bei der Bereitstellung muss sich der Benutzer eigentlich nur um den Instanztyp und die Anzahl der zu startenden Instanzen kümmern. Hinter den Kulissen gibt es jedoch noch eine Reihe anderer Dinge zu beachten, wie z.B. die Konfiguration von Block-Geräte-Zuordnungen und das anschließende Mounten aller verfügbaren Instance-Speicher. Machen Sie sich keine Sorgen, wenn Sie nicht viel über Block Device Mappings wissen, da das Toolkit alle Details für Sie erledigt. Zum Beispiel haben m3.xlarge-Instanzen zwei 40 GB SSD-Instanzspeicher zur Verfügung. Das Toolkit erstellt auf jedem Laufwerk ein ext3-Dateisystem und mountet sie unter /vol0 bzw. /vol1.
ZooKeeper Ensemble
ZooKeeper ist ein verteilter Koordinationsdienst, der die zentrale Konfiguration, die Verwaltung des Cluster-Status und die Wahl des Leader für SolrCloud ermöglicht. In der Produktion müssen Sie mindestens drei ZooKeeper-Server in einem Cluster, einem sogenannten Ensemble, betreiben, um eine hohe Verfügbarkeit zu erreichen. Lassen Sie uns zunächst unser ZooKeeper-Ensemble auf drei m3.medium-Instanzen einrichten:
fab new_zk_ensemble:zk1
Das Wichtigste, was Ihnen bei diesem Befehl auffallen sollte, ist der Parameter zk1, die Cluster-ID, die ich dieser Gruppe von drei m3.medium-Instanzen gebe. Das Toolkit basiert auf dem Konzept eines benannten „Clusters“, so dass Sie sich keine Gedanken über Hostnamen oder IP-Adressen machen müssen; das Framework weiß, wie man Hosts für einen bestimmten Cluster sucht. Hinter den Kulissen werden Amazon-Tags verwendet, um Instanzen zu finden und ihre Hostnamen zu sammeln.
Sie fragen sich vielleicht, warum ich den Instanztyp und die Anzahl nicht angegeben habe. Werfen wir einen Blick in die Dokumentation des Befehls new_zk_ensemble mit:
fab -d new_zk_ensemble
Displaying detailed information for task 'new_zk_ensemble':
Configures, starts, and checks the health of a ZooKeeper
ensemble on one or more nodes in a cluster.
Arg Usage:
cluster (str): Cluster ID used to identify the ZooKeeper ensemble created by this command.
n (int, optional): Size of the cluster.
instance_type (str, optional):
Rückgabe:
zkHosts: Liste der ZooKeeper-Hosts für das Ensemble.
Argumente: cluster, n=3, instance_type=’m3.medium‘
Wie Sie aus dieser Dokumentation ersehen können, sind die Standardwerte für den Instanztyp und die Anzahl m3.medium bzw. 3. Denken Sie auch daran, dass Sie mit dem Befehl fab -d <> Nutzungsinformationen für jeden Befehl des Toolkits abrufen können.
Hinter den Kulissen führt der Befehl new_zk_ensemble die folgenden Operationen aus:
- Stellen Sie drei m3.medium-Instanzen in EC2 bereit, indem Sie das benutzerdefinierte Solr Scale Toolkit AMI verwenden. Das Toolkit überprüft die SSH-Verbindung zu jeder Instanz und versieht jede Instanz mit dem Tag cluster=zk1.
- Konfiguriert ein 3-Knoten-ZooKeeper-Ensemble mit Client-Port 2181. Jeder ZooKeeper-Server ist so konfiguriert, dass er den auf /vol0 gemounteten Instanzenspeicher verwendet. Das Toolkit prüft, ob ZooKeeper in Ordnung ist, bevor es den Erfolg meldet.
Die Ausführung des Befehls new_zk_ensemble ist gleichbedeutend mit der Ausführung der beiden folgenden Fabric-Befehle:
fab new_ec2_instances:zk1,n=3,instance_type=m3.medium fab setup_zk_ensemble:zk1
Wenn Sie einen der Fabric-Befehle des Toolkits ausführen, sind eine Reihe von Schlüsselkonzepten im Spiel, darunter:
- Ein großer Teil der Arbeit des Toolkits besteht darin, Wartezeiten und Statusüberprüfungen elegant zu handhaben. Sie werden also mehrere Meldungen über das Warten und Überprüfen verschiedener Ergebnisse sehen.
- Für die meisten Parameter gibt es sinnvolle Standardwerte. Natürlich gibt es für Parameter wie die Anzahl der zu startenden Knoten keine sinnvolle Voreinstellung, so dass Sie in der Regel Parameter vom Typ Sizing angeben müssen.
- Alle Befehle, die mit dem Präfix „new_“ beginnen, bedeuten, dass sie Knoten in EC2 bereitstellen, während Befehle, die mit dem Präfix „setup_“ beginnen, davon ausgehen, dass die Knoten bereits bereitgestellt sind.
Im Allgemeinen unterteilt das Toolkit die Aufgaben in 2 Phasen:
- die Bereitstellung von Instanzen unserer AMI, und
- das Konfigurieren, Starten und Überprüfen von Diensten auf den bereitgestellten Instanzen
Dieser zweistufige Prozess impliziert, dass, wenn Schritt 1 erfolgreich abgeschlossen wird, aber in Schritt 2 ein Fehler/Problem auftritt, die Knoten bereits provisioniert wurden und Sie die Knoten nicht erneut provisionieren sollten. Schauen wir uns ein Beispiel an, um dies zu verdeutlichen.
Stellen Sie sich vor, Sie erhalten einen Fehler, wenn Sie den Befehl new_zk_ensemble ausführen. Zunächst müssen Sie feststellen, ob die Knoten bereitgestellt wurden. In der Konsole sehen Sie dazu eine grüne Informationsmeldung, wie z.B.:
** 3 EC2-Instanzen wurden bereitgestellt **
Wenn Sie eine solche Meldung sehen, wissen Sie, dass Schritt 1 erfolgreich war und Sie sich nur um die Behebung des Problems kümmern und Schritt 2 erneut ausführen müssen, was in unserem Beispiel die Ausführung der Setup-Aktion wäre. In der Regel ist es jedoch sicher, den Befehl (z.B. new_zk_ensemble) mit demselben Clusternamen erneut auszuführen, da das Framework feststellen wird, dass die Knoten bereits bereitgestellt wurden und Sie einfach fragen wird, ob es sie wiederverwenden soll. In den meisten Fällen lautet die Antwort Ja.
Da wir nun ein ZooKeeper-Ensemble laufen haben, können wir einen neuen SolrCloud-Cluster bereitstellen.
SolrCloud-Cluster starten
Wie oben beschrieben, werden wir einen neuen SolrCloud-Cluster auf zwei m3.xlarge-Instanzen starten und zwei Solr-Knoten pro Instanz betreiben. Jeder Solr-Knoten sollte einen der SSD-Instanzspeicher verwenden, die für m3.xlarge-Instanzen bereitgestellt werden.
Bevor wir die Solr-Knoten starten, lassen Sie uns einige wichtige Begriffe aus dem Solr Scale Toolkit wiederholen:
- Instanz (auch Maschine genannt): Virtuelle Maschine, die in einem Rechenzentrum eines Cloud-Anbieters läuft, wie z.B. EC2
- Node: JVM-Prozess, der an einen bestimmten Port auf einer Instanz gebunden ist; hostet die Solr-Webanwendung, die in Jetty läuft
- Sammlung: Suchindex, der auf mehrere Knoten verteilt ist; jede Sammlung hat einen Namen, eine Shard-Anzahl und einen Replikationsfaktor
- Replikationsfaktor: Anzahl der Kopien eines Dokuments in einer Sammlung, z.B. Replikationsfaktor 3 für eine Sammlung mit 100 Mio. Dokumenten bedeutet, dass es insgesamt 300 Mio. Dokumente in allen Repliken gibt.
- Shard: Logischer Ausschnitt einer Sammlung; jeder Shard hat einen Namen, einen Hash-Bereich, einen Leader und einen Replikationsfaktor. Dokumente werden mit Hilfe einer Strategie zur Weiterleitung von Dokumenten einem einzigen Shard pro Sammlung zugewiesen.
- Replikat: Solr-Index, der eine Kopie eines Shards in einer Sammlung
beherbergt; hinter den Kulissen wird jede Replik als ein Solr-Kern implementiert. Beispiel: eine Sammlung mit 20 Shards und einem Replikationsfaktor von 2 in einem 10-Knoten-Cluster ergibt 4 Solr-Kerne pro Knoten. - Leader: Replikat in einem Shard, das spezielle Aufgaben übernimmt, die zur Unterstützung der verteilten Indizierung in Solr erforderlich sind. Jeder Shard hat immer nur einen Leader und die Leader werden automatisch mit ZooKeeper gewählt. Im Allgemeinen sollten Sie sich nicht darum kümmern, welche Replikate als Leader gewählt werden.
Das folgende Diagramm zeigt, wie jede Instanz in Amazon durch das Solr Scale Toolkit konfiguriert wird:

Wie im Diagramm dargestellt, gibt es zwei Solr JVM-Prozesse, die auf den Ports 8984 und 8985 laufen. Jeder Prozess hat ein eigenes 40 GB SSD-Laufwerk. Die Indizes sind so konfiguriert, dass sie die MMapDirectory-Implementierung verwenden, die Memory Mapped I/O zum Laden von Indexdatenstrukturen in den OS-Cache verwendet. Jeder JVM-Prozess ist mit einer konservativen maximalen Heap-Einstellung konfiguriert, um dem OS-Cache so viel Speicher wie möglich zur Verfügung zu stellen.
Starten wir einen neuen SolrCloud-Cluster namens „cloud1“ mit:
fab new_solrcloud:cloud1,n=2,zk=zk1,nodesPerHost=2,instance_type=m3.xlarge
Das meiste davon sollte ziemlich selbsterklärend sein. Mit zk=zk1 teilen Sie den Solr-Knoten die Adresse des ZooKeeper-Ensembles mit; Sie erinnern sich, dass wir das Ensemble benannt haben: zk1.
Wenn das gut geht, sehen Sie Meldungen ähnlich der folgenden:
4 Solr-Server sind in Betrieb!
Erfolgreicher Start des neuen SolrCloud-Clusters cloud1; visit: http://<host>:8984/solr/#/
Eine der Designentscheidungen im Toolkit war die Verwendung eines BASH-Skripts zur Steuerung jedes Solr-Knotens auf einer Instanz. Mit anderen Worten: Die Fabric-Befehle delegieren einen Teil der Arbeit zur Verwaltung von Solr an ein lokales BASH-Skript auf jeder Instanz, siehe: /home/ec2-user/cloud/solr-ctl.sh.
Die Hauptaufgabe des Skripts solr-ctl.sh besteht darin, Solr mit den richtigen JVM-Optionen und Systemeigenschaften zu starten. Hier ist ein Beispiel für den Startbefehl, mit dem ein Solr-Knoten im Cloud-Modus gestartet wird. Keine Sorge, ich erwarte nicht, dass Sie sich für die Details dieses Befehls interessieren, ich füge ihn hier nur ein, um Ihnen ein Gefühl dafür zu vermitteln, was das Skript solr-ctl.sh tut:
/home/ec2-user/jdk1.7.0_25/bin/java -Xss256k -server -XX:+UseG1GC -XX:MaxGCPauseMillis=5000 -XX:+HeapDumpOnOutOfMemoryError -DzkClientTimeout=5000 -verbose:gc -XX:+PrintHeapAtGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintTenuringDistribution -Xms3g -Xmx3g -XX:MaxPermSize=512m -XX:PermSize=256m -Djava.net.preferIPv4Stack=true -Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.local.only=false -Dcom.sun.management.jmxremote.ssl=false -Dcom.sun.management.jmxremote.authenticate=false -Djava.rmi.server.hostname=ec2-??-##-??-##.compute-1.amazonaws.com -Dcom.sun.management.jmxremote.port=1084 -Dcom.sun.management.jmxremote.rmi.port=1084 -Xloggc:/home/ec2-user/solr-4.7.1/cloud84/logs/gc.log -XX:OnOutOfMemoryError=/home/ec2-user/cloud/oom_solr.sh 84 %p -Dlog4j.debug -Dhost=ec2-??-##-??-##.compute-1.amazonaws.com -Dlog4j.configuration=file:////home/ec2-user/cloud/log4j.properties -DzkHost=ec2-??-##-??-##.compute-1.amazonaws.com:2181,...:2181/cloud1 -DSTOP.PORT=7984 -DSTOP.KEY=key -Djetty.port=8984 -Dsolr.solr.home=/home/ec2-user/solr-4.7.1/cloud84/solr -Duser.timezone=UTC -jar start.jar
Aus diesem Befehl sollte hoffentlich hervorgehen, dass das Toolkit Ihnen etwas Arbeit erspart, indem es Solr unter Verwendung von Optionen startet, die auf bewährten Praktiken der Solr-Gemeinschaft basieren. Beachten Sie zum Beispiel, dass dieser Befehl ein OutOfMemory-Handler-Skript registriert, das sicherstellt, dass der Prozess beendet wird, damit Sie keine Zombie-Knoten in Ihrem Cluster haben.
Wir werden gleich mit der Erstellung einer Sammlung und der Indizierung einiger Dokumente beginnen, aber zunächst möchte ich auf eine optionale, aber sehr nützliche Funktion des Solr Scale Toolkit eingehen: die Integration mit SiLK zur Überwachung und Protokollaggregation.
Meta-Knoten
Jeder Solr-Knoten im Cluster ist so konfiguriert, dass er in logs/solr.log protokolliert. Es wäre jedoch schön, wenn alle Warn- und Fehlermeldungen von allen Knoten an einem Ort gesammelt würden, um unseren Systemadministratoren bei der Identifizierung und Behebung von Problemen im Cluster zu helfen. Außerdem möchten Sie wahrscheinlich die wichtigsten Systemmetriken wie CPU-Auslastung, Netzwerk-E/A und Arbeitsspeicher genau im Auge behalten. Das Toolkit bietet Unterstützung für diese allgemeinen Anforderungen durch die Integration mit der SiLK-Lösung von Lucidworks, siehe: https://lucidworks.com
SiLK: Solr integriert mit Logstash und Kibana
SiLK gibt Benutzern die Möglichkeit, Ad-hoc-Suchen und -Analysen von riesigen Mengen an multistrukturierten Daten und Zeitreihen durchzuführen. Die Benutzer können ihre Ergebnisse schnell in Visualisierungen und Dashboards umwandeln, die problemlos im gesamten Unternehmen genutzt werden können.
Das folgende Diagramm zeigt, wie SiLK in das Solr Scale Toolkit integriert ist:

Wenn Sie das Diagramm von links nach rechts betrachten, hostet jede EC2-Instanz einen oder mehrere Solr-Knoten. Log4J ist so konfiguriert, dass alle Protokollmeldungen mit dem Schweregrad Warnung oder höher über den AMQP Log4J Appender an SiLK gesendet werden. Außerdem läuft auf jeder EC2-Instanz der Collectd-Client-Agent, um Systemmetriken (z.B. CPU-Auslastung) zu sammeln und an das Collectd-Plugin in Logstash4Solr zu senden. Logmeldungen von unseren SolrCloud-Knoten und Systemmetriken werden in Solr auf dem Meta-Knoten indiziert. Jedes Dokument hat ein event_timestamp-Feld zur Unterstützung der Zeitreihenanalyse. Sie können mit der Bananen-Benutzeroberfläche ein cooles Dashboard erstellen.
Um einen Metaknoten zu starten, gehen Sie wie folgt vor:
fab new_meta_node:meta1
Der Befehl schreibt die URL des Banana-Dashboards in die Konsole, z.B. so:
Banana UI @ http://ec2-##-##-###-###.compute-1.amazonaws.com:8983/banana
Sobald der Meta-Knoten in Betrieb ist, müssen Sie die SolrCloud-Knoten anweisen, Protokollnachrichten und Collectd-Metriken an SiLK zu senden:
fab attach_to_meta_node:cloud1,meta1
Navigieren Sie zum Bananen-Dashboard auf dem Meta-Knoten und Sie sollten nun die Collectd-Metriken (CPU-Auslastung) für Ihre Solr-Knoten sehen.
Alles zusammenfügen
Jetzt haben wir also einen SolrCloud-Cluster mit 4 Knoten, der auf zwei EC2-Instanzen läuft, ein hochverfügbares ZooKeeper-Ensemble und einen Meta-Knoten, auf dem SiLK läuft. Lassen Sie uns all das in Aktion sehen, indem wir eine neue Sammlung erstellen, einige Dokumente indizieren und einige Abfragen ausführen.
Verschaffen wir uns zunächst einen Überblick über alle Instanzen, die wir ausführen, indem wir Folgendes tun: fab mine
Dies sollte einen schönen Bericht darüber erstellen, welche Instanzen in welchen Clustern laufen, wie z.B.:
Finding instances tagged with username: thelabdude
*** user: thelabdude ***
{
"meta1": [
"ec2-54-84-??-??.compute-1.amazonaws.com: i-63c15040 (m3.large running for 0:44:05)"
],
"zk1": [
"ec2-54-86-??-??.compute-1.amazonaws.com: i-a535a386 (m3.medium running for 2:27:51)",
"ec2-54-86-??-??.compute-1.amazonaws.com: i-a435a387 (m3.medium running for 2:27:51)",
"ec2-54-86-??-??.compute-1.amazonaws.com: i-a635a385 (m3.medium running for 2:27:51)"
],
"cloud1": [
"ec2-54-84-??-??.compute-1.amazonaws.com: i-acdf4e
8f (m3.xlarge running for 0:48:19)",
"ec2-54-85-??-??.compute-1.amazonaws.com: i-abdf4e88 (m3.xlarge running for 0:48:19)"
]
}
Hinter den Kulissen werden die Instanzen mit Ihrem lokalen Benutzernamen gekennzeichnet, so dass Sie verfolgen können, welche Instanzen Sie ausführen. Wenn es sich um ein gemeinsames Konto handelt, können Sie auch fab mine:all verwenden, um alle laufenden Instanzen für alle Benutzer des Kontos zu sehen.
Lassen Sie uns nun mit der Erstellung einer Sammlung fortfahren:
fabnew_collection: cloud1, example1, rf=2,shards=2
Dadurch wird eine neue Sammlung mit dem Namen example1 mit 2 Shards und einem Replikationsfaktor von 2 erstellt. An dieser Stelle können Sie Ihre eigenen Daten in der Sammlung indizieren. Um die Dinge einfach zu halten, enthält das Toolkit eine SolrJ-Client-Anwendung, die synthetische Dokumente indiziert.
fab index_docs:cloud1, example1, 20000
Hinter den Kulissen verwendet dieser Befehl die Datei solr-scale-tk.jar, um 20K synthetische Dokumente in SolrCloud zu indizieren. Diese Anwendung ist ein gutes Beispiel dafür, wie Sie die Klasse CloudSolrServer in SolrJ für die Erstellung von Client-Anwendungen für SolrCloud verwenden können. Das Befehlszeilendienstprogramm dient auch als Ausgangspunkt für die Erstellung anderer Java-basierter Client-Tools für SolrCloud, insbesondere wenn eine Client-Anwendung Zugriff auf Cluster-Metadaten in ZooKeeper benötigt. Wenn Sie sich dafür interessieren, wie das funktioniert, schauen Sie sich das an: https://github.com
Hier sehen Sie einen Screenshot des Bananen-Dashboards nach der Indizierung.
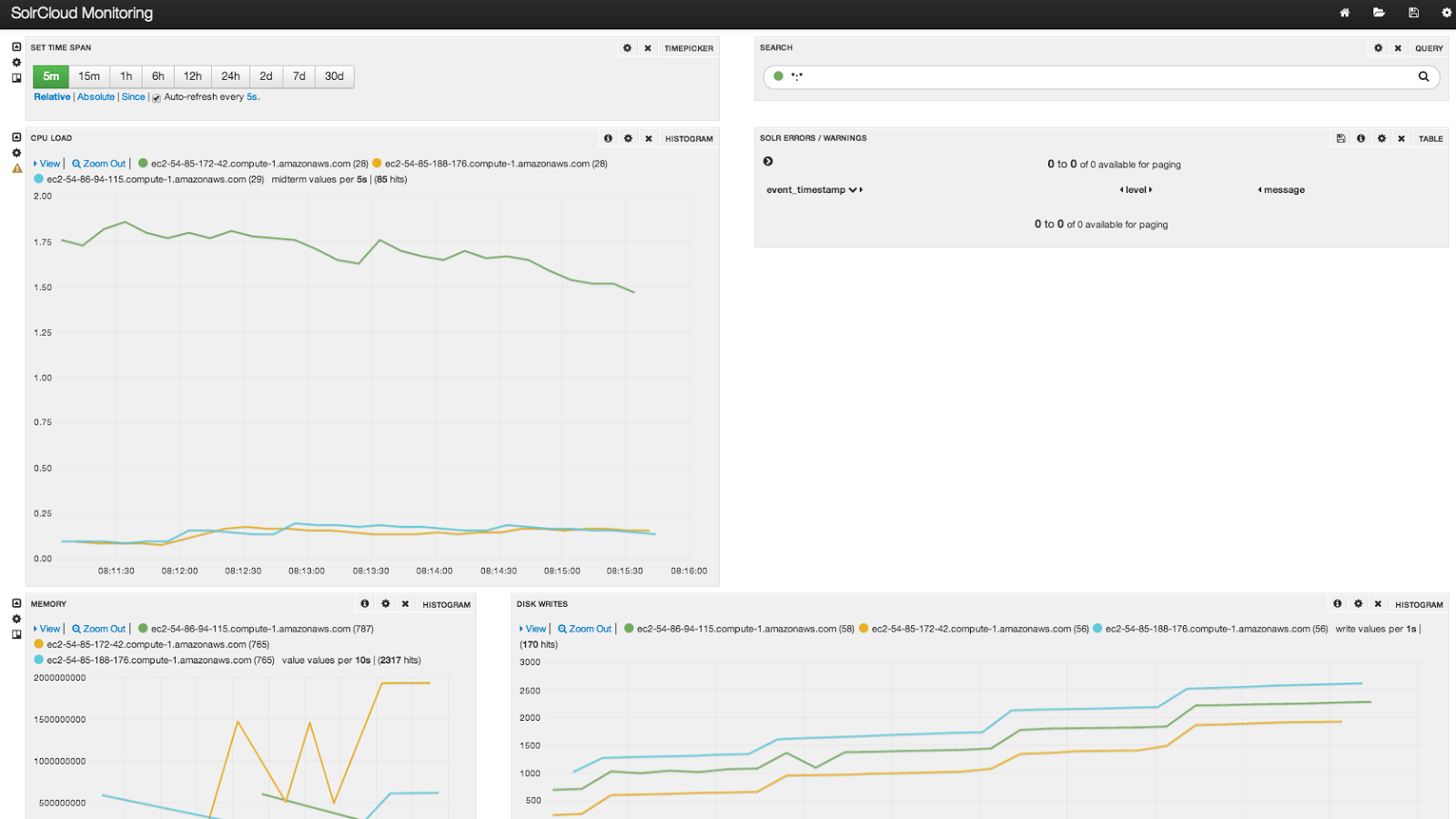
Der Knoten mit der höheren CPU-Last ist der Meta-Knoten, auf dem der Collectd-Server, SiLK und Rabbitmq laufen. Natürlich ist dies nur ein Beispiel für ein einfaches Bananen-Dashboard; ich empfehle Ihnen, die vollständige Tour durch SiLK zu machen: https://lucidworks.com/lucidworks-silk/
Andere Aufgaben
Sobald Sie Ihren Cluster zum Laufen gebracht haben, hilft Ihnen das Toolkit auch bei der Durchführung von Routinewartungsaufgaben. Lassen Sie uns einige dieser Aufgaben in Angriff nehmen, damit Sie einen Eindruck davon bekommen, was alles möglich ist. Eine vollständige Liste der unterstützten Befehle finden Sie unter: fab -l.
Stellen Sie ein Konfigurationsverzeichnis für ZooKeeper bereit
Das Beispiel-Solr-Konfigurationsverzeichnis (example/solr/collection1/conf) wird standardmäßig unter dem Konfigurationsnamen „cloud“ in ZooKeeper hochgeladen. Es ist jedoch durchaus üblich, dass Sie Ihre eigenen Solr-Konfigurationsdateien und Einstellungen haben. Das Toolkit bietet einen Befehl zum Hochladen eines Konfigurationsverzeichnisses von Ihrem Standortarbeitsplatz zu ZooKeeper. Wenn sich das Konfigurationsverzeichnis, das ich hochladen möchte, zum Beispiel in /tmp/solr_conf befindet, kann ich das tun:
fab
Das dritte Argument ist der Name der Konfiguration in ZooKeeper. Sie können diesen Namen verwenden, wenn Sie eine neue Sammlung erstellen, z. B:
fab
Sie sollten auch ein Muster bei den Fabric-Befehlen erkennen – sie verwenden alle die Cluster-ID als ersten Parameter, z.B. „cloud1“.
Solr lokal erstellen und remote patchen
Bevor ich zum Schluss komme, möchte ich Ihnen noch eine weitere nützliche Aufgabe für das Patchen Ihrer Solr-Server vorstellen. Stellen Sie sich vor, Sie haben einen Patch für ein Problem auf ein lokales Build von Solr 4.8.1 angewendet und müssen den Patch nun auf Ihrem Cluster in EC2 veröffentlichen. Angenommen, der lokale Solr-Build befindet sich in /tmp
fab
Dadurch werden die core- und solrj-JAR-Dateien von Ihrem lokalen Arbeitsplatzrechner auf den ersten Knoten im Cluster hochgeladen und dann per scp auf alle anderen Knoten übertragen. Dies ist dem Versuch, sie auf alle Server hochzuladen, vorzuziehen, da das Kopieren von einem Server zum anderen in Amazon sehr schnell ist. Nachdem die JARs aktualisiert wurden, wird ein rollierender Neustart durchgeführt, um die Aktualisierung anzuwenden.
Zeigen Sie uns doch schon mal den Maßstab!
Lassen Sie uns nun das Toolkit einsetzen, um zu sehen, wie gut Solr funktioniert und skaliert. Bei der Erstellung eines Leistungs-/Skalierbarkeitstests müssen wir drei Dinge berücksichtigen. Erstens brauchen wir eine Client-Anwendung, die Solr ausreichend Datenverkehr zuführen kann. Allzu oft sehe ich Benutzer, die sich über die Leistung von Solr beschweren, während in Wirklichkeit ihre Client-Anwendung nicht genug Last liefert und die Solr-Server im Hintergrund schlummern. Zu diesem Zweck werde ich Amazon Elastic MapReduce verwenden, mit dem ich so viele Client-Anwendungen hochfahren kann, wie ich möchte.
Zweitens brauche ich einen Datensatz, der einigermaßen realistisch ist. Zu diesem Zweck habe ich das PigMix-Datengenerator-Framework verwendet, um 130 Millionen synthetische Dokumente zu erstellen, die etwa 1K groß sind und eine Mischung aus zufällig generierten numerischen, Datums-/Zeit-, booleschen, String- und englischen Textfeldern enthalten; die englischen Textfelder folgen einer Zipf-Verteilung. Der Datensatz ist in S3 gespeichert, so dass ich ihn bei Bedarf aus Elastic MapReduce laden und einen Indizierungsleistungstest durchführen kann. Die Generierung von Text, der einer Zipf-Verteilung folgt, ist für Benchmarking-Zwecke eigentlich recht langsam, so dass die Vorberechnung der Daten bedeutet, dass unsere Leistungstests nicht durch die Kosten der Datengenerierung beeinträchtigt werden.
Drittens muss ich sicherstellen, dass die Netzwerkleitung von Elastic MapReduce zu Solr nicht eingeschränkt ist. Mit anderen Worten, ich möchte nicht, dass Solr während der Indizierung im Netzwerk auf Input wartet. Zu diesem Zweck habe ich mich für die Verwendung von r3.2xlarge-Instanzen mit aktiviertem Enhanced Networking und in einer EC2-Platzierungsgruppe entschieden. r3.2xlarge-Instanzen bieten einen hohen E/A-Durchsatz (siehe: http://aws.amazon.com/about-aws/whats-new/2014/04/10/r3-announcing-the-next-generation-of-amazon-ec2-memory-optimized-instances/). Auf der Hadoop-Seite ist die Netzwerkleistung von m1.xlarge-Instanzen ziemlich gut (siehe: http://flux7.com
Um Dokumente aus Hadoop in Solr zu übertragen, verwende ich ein einfaches Pig-Skript (verfügbar im Projekt solr-scale-toolkit), das mit der SolrStoreFunc von Lucidworks in Solr schreibt. Der Datensatz ist öffentlich auf S3 verfügbar unter: s3://solr-scale-tk
Zunächst wollte ich mir einen Eindruck von der reinen Indizierungsleistung ohne Replikation verschaffen. Also habe ich eine 10×1-Sammlung auf 10 Knoten indiziert, was mit 32 Reduzierern und einer Stapelgröße von 1.000 Dokumenten etwas mehr als 31 Minuten oder 68.783 Dokumente pro Sekunde benötigte. Als nächstes erhöhte ich die Anzahl der Reducer auf 48 mit einer Stapelgröße von 1.500, was zu 73.780 Dokumenten pro Sekunde führte. Insgesamt blieb die GC-Aktivität stabil und die CPUs hatten immer noch genügend Kapazität, um die Suche während der Indizierung zu unterstützen, siehe Screenshot von VisualVM unten. (HINWEIS: Der starke Rückgang der Heap-Größe ist wahrscheinlich ein Überbleibsel eines früheren Tests, die interessanten Teile befinden sich in diesem Diagramm rechts vom Rückgang).

Als Nächstes wollte ich die Auswirkungen der Replikation verstehen, also führte ich die gleichen Tests wie zuvor mit einer 10×2-Sammlung (immer noch auf 10 Knoten) durch, die nur einen Durchschnitt von 33.325 Dokumenten pro Sekunde erreichte. Da jeder Knoten jetzt 2 Solr-Kerne statt einem beherbergt, ist die CPU-Auslastung viel höher (siehe Grafik unten). Wahrscheinlich sind 48 Indizierungsreduzierer zu viel für diese Konfiguration, denn man würde nicht erwarten, dass die Replikation eine so starke Verlangsamung verursacht. Daher habe ich es mit nur 34 Reduzierern versucht und 34.881 Dokumente pro Sekunde erreicht, wobei die durchschnittliche/maximale CPU-Auslastung niedriger war, um die Abfrageausführung zu bewältigen. Die Lehre daraus ist, dass man es mit der Indizierung nicht übertreiben sollte, vor allem nicht bei der Replikation. Es sind weitere Tests erforderlich, um die optimale Anzahl der Indizierungsclients und die Stapelgröße zu ermitteln.
Bildschirmfoto bei der Indizierung von 10×2 mit 48 Reduzierern; durchschnittliche und maximale CPU sind zu hoch, um die Abfrageausführung zu unterstützen (mehr ist nicht immer besser).

Außerdem ist Oversharding eine gängige Strategie für die Skalierung von Solr. Daher habe ich die Tests mit einer 20×1- und 20×2-Sammlung durchgeführt, was 101.404 bzw. 40.536 Ergebnisse ergab. Es ist klar, dass ein gewisses Maß an Oversharding der Leistung zugute kommt, selbst bei Verwendung der Replikation. Solr schien bei den Tests mit 20 Shards mehr Kapazität zu haben, also erhöhte ich die Shard-Anzahl auf 30 auf 10 Knoten und die Ergebnisse verbesserten sich weiter: 121.495 für die 30×1 und 41.152 für die 30×2. Die 30×2-Ergebnisse machen deutlich, dass die Verwendung von 60 Reduzierern wahrscheinlich zu viel war, da die durchschnittliche CPU-Auslastung während der gesamten Dauer des Tests 95 % betrug und der Durchsatz gegenüber dem 20×2-Test nur leicht anstieg.
Und schließlich sollte das Hinzufügen weiterer Knoten zu einer nahezu linearen Skalierbarkeit führen. Bei meiner nächsten Testrunde habe ich 15×1 und 15×2 auf 15 Knoten ausgeführt. Bei der 15×1-Sammlung erreichte ich 117.541 Dokumente pro Sekunde bei stabiler CPU (Durchschnitt ca. 50-60%, Spitze ca. 85%). Das ist eine Steigerung des Durchsatzes um 59% bei einer Erhöhung der Knotenanzahl um 50%; besser als linear, weil ich bei meinem 15-Knoten-Test angesichts der erhöhten Kapazität des Clusters mehr Reduzierer (60 gegenüber 48) verwendet habe. Schließlich habe ich einen 30×1-Test mit dem 15-Knoten-Cluster durchgeführt und 157.195 Dokumente/Sek. erreicht, was ich wirklich beeindruckend finde!
Die folgende Tabelle fasst die Ergebnisse meiner Tests zusammen:
| Cluster Größe | Num Scherben | Replikationsfaktor | Verkleinerer (Kunden) | Zeit (Sek.) | Dokumente / Zweite |
| 10 | 10 | 1 | 48 | 1762 | 73,780 |
| 10 | 10 | 2 | 34 | 3727 | 34,881 |
| 10 | 20 | 1 | 48 | 1282 | 101,404 |
| 10 | 20 | 2 | 34 | 3207 | 40,536 |
| 10 | 30 | 1 | 72 | 1070 | 121,495 |
| 10 | 30 | 2 | 60 | 3159 | 41,152 |
| 15 | 15 | 1 | 60 | 1106 | 117,541 |
| 15 | 15 | 2 | 42 | 2465 | 52,738 |
| 15 | 30 | 1 | 60 | 827 | 157,195 |
| 15 | 30 | 2 | 42 | 2129 | 61,062 |
Es gibt einige interessante Erkenntnisse aus diesem ersten Durchgang des Solr-Leistungsbenchmarkings. Erstens basieren diese Ergebnisse auf der Standardversion von Solr 4.8.1 ohne „Tuning“ der Konfigurationseinstellungen für die Indizierungsleistung. Ich verwende die von Shawn Heisey vorgeschlagenen GC-Einstellungen (siehe: http://wiki.apache.org/solr/ShawnHeisey) auf Java 1.7.0 u55. Die einzige Konfigurationsänderung, die ich vorgenommen habe, bestand darin, die autoCommit-Einstellungen so zu setzen, dass alle 100.000 Dokumente ein Hard-Commit und alle 60 Sekunden ein Soft-Commit durchgeführt wird.
Zweitens trägt das Sharding natürlich zur Leistung bei (wie erwartet), aber die Replikation ist teuer. Die Indizierung einer 20×1-Sammlung (2 Solr-Kerne pro Knoten auf 10 Knoten) ergab beispielsweise 101.404 Dokumente pro Sekunde, während eine 10×2-Sammlung (ebenfalls mit 2 Kernen pro Knoten) nur 34.881 Dokumente pro Sekunde lieferte. Das ist ein enormer Unterschied in den Ergebnissen, wenn jeder Knoten im Grunde die gleiche Anzahl von Dokumenten hostet und ungefähr die gleiche Menge an Arbeit leistet. Der Grund, warum die Replikation langsamer ist, liegt darin, dass trotz der gleichen Anzahl von Kernen jeder Leader blockieren muss, bis er eine Antwort erhält, wenn er Aktualisierungsanforderungen an die Replikate weiterleitet. Oversharding hilft, weil die Client-Indizierungsanwendungen
lationen (in diesem Fall Hadoop-Reducer-Tasks) Aktualisierungen direkt an jeden Shard-Leader senden. Wenn ich die beiden Strategien zusammen verwende (20×2), erhalte ich 40.536 Dokumente pro Sekunde.
Die dritte Lektion in diesem Zusammenhang ist, dass Solr möglicherweise zu schnell Aktualisierungen akzeptiert, was zu einer schlechten Abfrageleistung oder schlimmer noch (Shard-Ausfall) führen kann. Sie müssen also den Indizierungsdurchsatz auf ein vertretbares Maß drosseln, da Solr keine Unterstützung für die Drosselung von Anfragen bietet. Für mich bedeutete dies, dass ich bei der Replikation weniger Reducer verwenden musste, z.B. 34 statt 48. Mein Ziel war es, zu vermeiden, dass die CPU-Auslastung in der Spitze über 85% liegt und im Durchschnitt nur etwa 50-60% beträgt, so dass genügend freie Zyklen für die Ausführung von Abfragen zur Verfügung stehen.
Natürlich kann man keinem Leistungsvergleich trauen, wenn er nicht von anderen wiederholt werden kann. Die gute Nachricht ist, dass jeder dieselben Tests mit dem quelloffenen Solr Scale Toolkit von Lucidworks und dem Hadoop-Framework von Lucidworks durchführen kann. Der Betrieb der Elastic MapReduce- und SolrCloud-Cluster kostet etwa $17 pro Stunde (10 Solr-Knoten x $0,70 + 20 m1.xlarge EMR-Kernknoten * $0,48 + 1 m1.large EMR-Master x $0,24).
Nachbereitung
Ich habe viele der wichtigsten Funktionen des Toolkits, wie es heute existiert, behandelt. Es gibt noch viele andere Funktionen, die ich aus Zeitgründen (meine und Ihre) nicht erwähnt habe. Ich möchte Sie daher ermutigen, das Toolkit weiter zu erkunden.
Sie sollten auch eine gute Vorstellung davon haben, welche Arten von Indizierungsarbeiten Solr unterstützen kann, aber das hängt von der Größe der Dokumente, der Komplexität Ihrer Textanalyse, der Netzwerkgeschwindigkeit und den Rechenressourcen ab. Ich habe vor, weitere Leistungsbenchmarks für Solr durchzuführen, sobald es die Zeit erlaubt. Dabei werde ich mich auf das Testen der Indizierungsleistung konzentrieren und auch Abfragen gegen den Index ausführen.
Und schließlich wird dieses Framework aktiv weiterentwickelt. Halten Sie also bitte in den kommenden Wochen Ausschau nach neuen Funktionen, Fehlerkorrekturen und Erweiterungen. Wie bei jedem neuen Open-Source-Projekt wird es wahrscheinlich ein paar Warzen, falsche Annahmen und Designfehler geben. Bitte testen Sie es und geben Sie uns Feedback, damit wir diese Lösung für die Solr-Community verbessern können. Viel Spaß beim Skalieren!