Erstellen einer Rechtschreibprüfung mit Solr
Einführung
In einem früheren Beitrag habe ich über die Funktionsweise der Solr-Rechtschreibprüfung gesprochen und Ihnen dann einige Testergebnisse zu deren Leistung gezeigt. Jetzt werden wir uns einen anderen Ansatz für die Rechtschreibprüfung ansehen.
Diese Methode verwendet, wie viele andere auch, ein zweistufiges Verfahren. Eine recht schnelle Auswahl von „Wortkandidaten“ und dann eine Bewertung dieser Wörter. Wir werden verschiedene Methoden aus den von Solr verwendeten auswählen und ihre Leistung testen. Unser Hauptziel ist die Effektivität der Korrektur und in einem zweiten Schritt die Schnelligkeit der Ergebnisse. Wir können eine etwas langsamere Leistung tolerieren, wenn man bedenkt, dass wir dadurch einen Gewinn an Korrektheit der Ergebnisse erzielen.
Unsere Strategie besteht darin, einen speziellen Lucene-Index zu verwenden und diesen mit Fuzzy-Abfragen abzufragen, um eine Kandidatenliste zu erhalten. Dann werden wir die Kandidaten mit einem Python-Skript bewerten (das leicht in eine Solr-Unterklasse für die Rechtschreibprüfung umgewandelt werden kann, wenn wir bessere Ergebnisse erzielen).
Auswahl der Kandidaten
Fuzzy-Abfragen galten in der Vergangenheit im Vergleich zu anderen Abfragen als langsam, aber da sie in der Version 1.4 optimiert wurden, sind sie eine gute Wahl für den ersten Teil unseres Algorithmus. Die Idee ist also ganz einfach: Wir werden einen Lucene-Index erstellen, in dem jedes Dokument ein Wörterbuchwort ist. Wenn wir ein falsch geschriebenes Wort korrigieren müssen, führen wir eine einfache Fuzzy-Abfrage für dieses Wort durch und erhalten eine Liste von Ergebnissen. Die Ergebnisse sind Wörter, die dem von uns eingegebenen Wort ähnlich sind (d.h. mit einem geringen Bearbeitungsabstand). Ich habe festgestellt, dass wir mit etwa 70 Kandidaten hervorragende Ergebnisse erzielen können.
Mit unscharfen Abfragen decken wir alle Tippfehler ab, denn wie ich im vorherigen Beitrag sagte, haben die meisten Tippfehler eine Bearbeitungsdistanz von 1 in Bezug auf das richtige Wort. Aber obwohl dies der häufigste Fehler ist, den Menschen beim Tippen machen, gibt es noch andere Arten von Fehlern.
Wir können drei Arten von Rechtschreibfehlern finden [Kukich]:
- Typografische Fehler
- Kognitive Fehler
- Phonetische Fehler
Typografische Fehler sind die Tippfehler, die entstehen, wenn jemand die richtige Schreibweise kennt, aber beim Tippen einen motorischen Koordinationsfehler macht. Die kognitiven Fehler sind diejenigen, die durch mangelndes Wissen der Person verursacht werden. Phonetische Fehler schließlich sind ein Sonderfall der kognitiven Fehler, d.h. Wörter, die richtig klingen, aber orthographisch falsch sind. Typografische Fehler haben wir bereits mit der Fuzzy-Abfrage abgedeckt, aber wir können auch etwas für die phonetischen Fehler tun. Solr verfügt in seinem Analysepaket über einen phonetischen Filter, der u.a. den doppelten Methaphon-Algorithmus enthält. Auf die gleiche Weise, wie wir eine Fuzzy-Abfrage durchführen, um ähnliche Wörter zu finden, können wir das methaphone Äquivalent des Wortes indizieren und eine Fuzzy-Abfrage darauf durchführen. Wir müssen das Methaphone-Äquivalent des Wortes manuell ermitteln (da der Lucene Query Parser keine unscharfen Abfragen analysiert) und eine unscharfe Abfrage mit diesem Wort konstruieren.
In wenigen Worten: Für die Kandidatenauswahl konstruieren wir einen Index mit dem folgenden Solr-Schema:
<fieldType name="spellcheck_text" positionIncrementGap="100" autoGeneratePhraseQueries="true">
<analyzer type="index">
<tokenizer/>
<filter/>
<filter encoder="DoubleMetaphone" maxCodeLength="20" inject="false"/>
</analyzer>
</fieldType>
<field name=“original_word“ type=“string“ indexed=“true“ stored=“true“ multiValued=“false“/>
<field name=“analysiertes_wort“ type=“rechtschreibprüfung_text“ indexed=“true“ stored=“true“ multiValued=“false“/>
<field name=“freq“ type=“tfloat“ stored=“true“ multiValued=“false“/>
Wie Sie sehen können, enthält das Feld analyzed_word den „soundslike“ des Wortes. Das Feld freq wird in der nächsten Phase des Algorithmus verwendet. Es ist einfach die Häufigkeit des Begriffs in der Sprache. Wie können wir die Häufigkeit eines Wortes in einer Sprache schätzen? Durch Zählen der Häufigkeit des Wortes in einem großen Textkorpus. In diesem Fall ist die Quelle der Begriffe die Wikipedia und wir verwenden die TermComponents von Solr, um zu zählen, wie oft jeder Begriff in der Wikipedia erscheint.
Aber die Wikipedia wird von gewöhnlichen Menschen geschrieben, die Fehler machen! Wie können wir darauf vertrauen, dass sie ein „korrektes Wörterbuch“ ist? Wir machen uns das „kollektive Wissen“ der Menschen zunutze, die die Wikipedia schreiben. Dieses Wörterbuch mit Begriffen aus der Wikipedia enthält sehr viele Begriffe! Über 1.800.00, und die meisten davon sind nicht einmal Wörter. Es ist wahrscheinlich, dass Wörter mit einer hohen Häufigkeit in der Wikipedia richtig geschrieben sind. Dieser Ansatz, ein Wörterbuch aus einem großen Korpus von Wörtern zu erstellen und die häufigsten Wörter als korrekt zu betrachten, ist nicht neu. In [Cucerzan] wird dasselbe Konzept angewandt, allerdings unter Verwendung von Abfrageprotokollen zur Erstellung des Wörterbuchs. Es scheint, dass Googles „Haben Sie gemeint“ ein ähnliches Konzept verwendet.
Wir können hier kleine Optimierungen vornehmen. Ich habe festgestellt, dass wir einige Wörter entfernen können und gute Ergebnisse erhalten. Ich habe zum Beispiel Wörter mit der Häufigkeit 1 und Wörter, die mit Zahlen beginnen, entfernt. Wir können weiterhin Wörter nach anderen Kriterien entfernen, aber wir belassen es dabei.
Das Verfahren zur Erstellung des Index ist also einfach: Wir extrahieren alle Begriffe aus dem Wikipedia-Index über die TermsComponent von Solr zusammen mit den Häufigkeiten und erstellen dann mit SolrJ einen Index in Solr.
Kandidaten-Ranking
Nun die Einstufung der Kandidaten. Für die zweite Phase des Algorithmus werden wir die Informationstheorie nutzen, insbesondere das Modell des verrauschten Kanals. Das Modell des verrauschten Kanals geht davon aus, dass der Mensch die korrekte Schreibweise eines Wortes kennt, dass aber ein Rauschen im Kanal den Fehler einbringt und wir als Ergebnis ein anderes, falsch geschriebenes Wort erhalten. Intuitiv wissen wir, dass es sehr unwahrscheinlich ist, dass wir ’sarasa‘ erhalten, wenn wir versuchen, ‚Haus‘ zu tippen, also führt das Modell des verrauschten Kanals eine gewisse Formalität ein, um herauszufinden, wie wahrscheinlich ein Fehler war.
Wir haben zum Beispiel ‚houze‘ falsch geschrieben und wollen wissen, welches das wahrscheinlichste Wort ist, das wir tippen wollten. Zu diesem Zweck haben wir ein großes Wörterbuch mit möglichen Wörtern, aber nicht alle sind gleich wahrscheinlich. Wir möchten das Wort mit der höchsten Wahrscheinlichkeit erhalten, das wir tippen wollten. In der Mathematik nennt man das bedingte Wahrscheinlichkeit. Wenn wir ‚houze‘ getippt haben, wie hoch ist die Wahrscheinlichkeit, dass jedes der richtigen Wörter das beabsichtigte Wort ist? Die Notation der bedingten Wahrscheinlichkeit lautet: P(‚Haus’|’houze‘), das steht für die Wahrscheinlichkeit von ‚Haus‘ bei ‚houze‘. 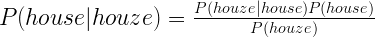
Dieses Problem kann aus zwei Blickwinkeln betrachtet werden: Wir können denken, dass die häufigsten Wörter wahrscheinlicher sind, z.B. ‚Haus‘ ist wahrscheinlicher als ‚Schlauch‘, weil das erstere ein häufigeres Wort ist. Andererseits denken wir auch intuitiv, dass ‚Haus‘ wahrscheinlicher ist als ‚Fotosynthese‘, weil die beiden Wörter sich stark unterscheiden. Beide Aspekte werden formal durch das Bayes-Theorem hergeleitet:
Wir müssen diese Wahrscheinlichkeit maximieren, und dazu haben wir nur einen Parameter: das richtige Kandidatenwort („Haus“ in dem gezeigten Fall).

Aus diesem Grund ist die Wahrscheinlichkeit des falsch geschriebenen Wortes konstant und wir sind nicht daran interessiert. Die Formel reduziert sich auf
Und um dem Ganzen mehr Struktur zu verleihen, haben Wissenschaftler diesen beiden Faktoren Namen gegeben. Der Faktor P(‚houze’|’house‘) ist das Fehlermodell (oder Kanalmodell) und gibt an, wie wahrscheinlich es ist, dass der Kanal beim Versuch, das zweite Wort zu schreiben, diesen speziellen Rechtschreibfehler einführt. Der zweite Term P(‚Haus‘) wird als Sprachmodell bezeichnet und gibt uns eine Vorstellung davon, wie häufig ein Wort in einer Sprache vorkommt.
Bis zu diesem Punkt habe ich nur die mathematischen Aspekte des Modells vorgestellt. Jetzt müssen wir uns ein konkretes Modell für diese beiden Wahrscheinlichkeiten ausdenken. Für das Sprachmodell können wir die Häufigkeit des Begriffs im Textkorpus verwenden. Ich habe die Erfahrung gemacht, dass es viel besser funktioniert, den Logarithmus der Häufigkeit zu verwenden als die Häufigkeit allein. Vielleicht liegt das daran, dass wir das Gewicht der sehr häufigen Begriffe stärker reduzieren wollen als das der weniger häufigen, und der Logarithmus bewirkt genau das.
Es gibt nicht nur einen Weg, ein Channel-Modell zu erstellen. Es wurden bereits viele verschiedene Ideen vorgeschlagen. Wir werden eine einfache Methode verwenden, die auf dem Damerau-Levenshtein-Abstand basiert. Aber ich habe auch festgestellt, dass die unscharfe Abfrage der ersten Phase bei der Suche nach den Kandidaten gute Arbeit leistet. Sie liefert in mehr als der Hälfte der Testfälle mit einigen Datensätzen das richtige Wort an erster Stelle. Das Kanalmodell wird also eine Kombination aus der Damerau-Levenshtein-Distanz und der Punktzahl sein, die Lucene für die Begriffe der Fuzzy-Abfrage erstellt hat.
Die Formel für die Rangliste lautet wie folgt: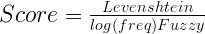
Ich habe ein kleines Skript (Python) programmiert, das all das tut, was zuvor gesagt wurde:
from urllib import urlopen
import doubleMethaphone
import levenshtain
import json
server = „http://benchmarks:8983/solr/testSpellMeta/“
def spellWord(word, candidateNum = 70):
#fuzzy + soundlike
metaphone = doubleMethaphone.dm(word)
query = „original_word:%s~ OR analyzed_word:%s~“ % (Wort, metaphone[0])
if metaphone[1] != None:
query = query + “ OR analyzed_word:%s~“ % metaphone[1]
doc = urlopen(server + „select?rows=%d&wt=json&fl=*,score&omitHeader=true&q=%s“ % (candidateNum, query)).read( )
response = json.loads(doc)
suggestions = response[‚response‘][‚docs‘]
if len(Vorschläge) > 0:
#score
scores = [(sug[‚original_word‘], scoreWord(sug, word)) for sug in suggestions]
scores.sort(key=lambda candidate: candidate[1])
return scores
else:
return []
def scoreWord(vorschlag, falsch geschrieben):
distance = float(levenshtain.dameraulevenshtein(vorschlag[‚original_wort‘], falsch geschrieben))
if distance == 0:
distance = 1000
fuzzy = vorschlag[’score‘]
logFreq = vorschlag[‚freq‘]
return Abstand/(fuzzy*logFreq)
Zu der vorherigen Auflistung muss ich einige Anmerkungen machen. In Zeile 2 und 3 verwenden wir Bibliotheken von Drittanbietern für Levenshtein-Distanz- und Metaphon-Algorithmen. In Zeile 8 sammeln wir eine Liste von 70 Kandidaten. Diese Zahl wurde empirisch ermittelt. Bei einer höheren Anzahl von Kandidaten ist der Algorithmus langsamer und bei einer geringeren Anzahl ist er weniger effektiv. Außerdem schließen wir in Zeile 30 das falsch geschriebene Wort aus der Kandidatenliste aus. Da wir die Wikipedia als Quelle verwendet haben, ist es üblich, dass das falsch geschriebene Wort im Wörterbuch zu finden ist. Wenn also die Leveshtain-Distanz 0 ist (gleiches Wort), addieren wir 1000 zu seiner Distanz hinzu.
Tests
Ich habe einige Tests mit diesem Algorithmus durchgeführt. Der erste wird mit dem Datensatz durchgeführt, den Peter Norvig in seinem Artikel verwendet hat. Ich habe in etwa 80% der Fälle den richtigen Vorschlag für das Wort an der ersten Position gefunden!!! Das ist ein wirklich gutes Ergebnis. Norvig hat mit dem gleichen Datensatz (aber mit einem anderen Algorithmus und Trainingssatz) 67% erreicht.
Lassen Sie uns nun einige der Tests aus dem vorherigen Beitrag wiederholen, um die Verbesserung zu sehen. In der folgenden Tabelle zeige ich Ihnen die Ergebnisse.
| Testsatz | % Solr | % neu | Solr-Zeit [Sekunden] | Neue Zeit [Sekunden] | Verbesserung | Zeitverlust |
FAWTHROP1DAT.643 |
45,61% |
81,91% |
31,50 |
74,19 |
79,58% |
135,55% |
batch0.tab |
28,70% |
56,34% |
21,95 |
47,05 |
96,30% |
114,34% |
SHEFFIELDDAT.643 |
60,42% |
86,24% |
19,29 |
35,12 |
42,75% |
82,06% |
Wir können sehen, dass wir sehr gute Verbesserungen in der Effektivität der Korrektur erhalten, aber es dauert etwa doppelt so lange.
Künftige Arbeit
Wie können wir diese Rechtschreibprüfung verbessern? Nun, wenn man die Kandidatenliste studiert, stellt man fest, dass das richtige Wort in der Regel (in 95% der Fälle) darin enthalten ist. Unsere Bemühungen sollten also darauf abzielen, den Bewertungsalgorithmus zu verbessern.
Es gibt viele Möglichkeiten, das Kanalmodell zu verbessern. Mehrere Arbeiten zeigen, dass die Berechnung ausgefeilterer Distanzen, bei denen die verschiedenen Buchstabentransformationen anhand von Sprachstatistiken gewichtet werden, uns ein besseres Maß liefern kann. Wir wissen zum Beispiel, dass die Schreibweise ‚houpe‘ unwahrscheinlicher ist als die Schreibweise ‚houze‘.
Für das Sprachmodell können große Verbesserungen erzielt werden, wenn dem Wort mehr Kontext hinzugefügt wird. Wenn wir z.B. ’nouse‘ falsch geschrieben haben, ist es sehr schwierig zu erkennen, ob das richtige Wort ‚Haus‘ oder ‚Maus‘ ist. Wenn wir jedoch weitere Wörter hinzufügen, wie z.B. „male meine Maus“, ist es offensichtlich, dass das gesuchte Wort ‚Haus‘ ist (es sei denn, Sie haben seltsame Angewohnheiten in Bezug auf Nagetiere). Diese werden auch als Ngramme bezeichnet (in diesem Fall jedoch aus Wörtern und nicht aus Buchstaben). Google hat eine große Sammlung von Ngrammen mit ihren Häufigkeiten zum Herunterladen bereitgestellt.
Nicht zuletzt kann die Leistung durch die Programmierung des Skripts in Java verbessert werden. Ein Teil des Algorithmus war in Python.
Auf Wiedersehen!
Dieser Blogeintrag kann auch in meinem persönlichen Blog http://emmaespina.wordpress.com gefunden werden .
Als Update für alle Interessierten teilte mir Robert Muir in der Solr-Benutzerliste mit, dass es eine neue Rechtschreibprüfung, DirectSpellChecker, gibt, die damals im Stamm war und nun Teil von Solr 3.1 sein sollte. Sie verwendet eine ähnliche Technik wie die, die ich in diesem Eintrag vorgestellt habe, ohne die Leistungseinbußen.
Referenzen
[Kukich] Karen Kukich – Techniken zur automatischen Korrektur von Wörtern in Texten – ACM Computing Surveys – Band 24 Ausgabe 4, Dez. 1992
[Cucerzan] S. Cucerzan und E. Brill Rechtschreibkorrektur als iterativer Prozess, der das kollektive Wissen der Internetnutzer nutzt. Juli 2004