Fusion, Solr, Wikipedia und ein bisschen Sommerspaß
Ich liebe es, Dinge zu katalogisieren, zu indizieren und zu *finden*. Es begann im Universität von Virginia’s Alderman Bibliothek, Suche nach „Objekten“ der Kunst und Poesie des 19. Jahrhunderts mit Solr und leuchtet dann mit Blacklight die Bestände und Sammlungen der Bibliothek aus. Schwarzlicht.
(Bei meinen Abenteuern in der Bibliothekswelt lernte ich auch zufällig den späteren Gründer von Lucid Imagination, jetzt Lucidworks, bei einer Veranstaltung des Lucene Summit for Libraries kennen).
Der Zugang zu mächtigen, nützlichen Informationen liegt hier tief in uns.
Um Ideen in die Tat umzusetzen, dachte ich, es wäre toll zu sehen, wohin ein paar junge, frische Köpfe die Welt der Wikipedia-Daten führen könnten.
Treffen Sie Annie und Dean
Annie und Dean haben ein Sommerpraktikum bei Lucidworks absolviert, das von der University of Virginia und der Industriepartnerschaft organisiert wurde, HackCvillenach vierwöchigen Intensivkursen in Data Science und Software Engineering. Eifrig, aber ohne wirklich zu wissen, worauf sie sich einlassen, nahmen sie einen Sommer lang mutig Woche für Woche Herausforderungen in Angriff.


Annie: Software-Ingenieurin, Praktikantin – ein UVa CS-Studium – „Sie freut sich darauf, bei Launch mit einem Team von Gleichgesinnten zusammenzuarbeiten und von denjenigen, die in Startups arbeiten, als Mentoren betreut zu werden.“ „Ihr Traumjob ist eine Kombination aus Projekten, die einen Einfluss auf die Gemeinschaft haben, der Mitarbeit in einem Team und einer großen Stadt.“ „Außerhalb der Schule engagiert sich Annie gerne ehrenamtlich im Charlottesville Health & Rehab Center und zeichnet.“
Dean: Datenwissenschaftler-Praktikant – ein UVa-Mathematikstudent, der zu Launch kam „freut sich auf das Praktikum bei Launch, um die Arbeit in einem Startup-Unternehmen kennenzulernen“ „freut sich darauf, durch sein Studium eine solide Grundlage in mathematischer Forschung zu erlangen. Er verfolgt sogar einen datengesteuerten Ansatz, um seine eigene Zeit produktiv einzuteilen, indem er toggl.com nutzt, um zu verfolgen, wie er seine Tage verbringt.“
Die „Herausforderung
Sie kannten Solr noch nicht, also gab ich ihnen eine faszinierende Aufgabe, um ihr Praktikum zu beginnen.
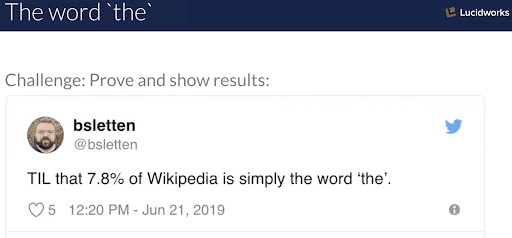
Mit Hilfe von StackOverflowing, Unix-Fu (eine Kunst, die wir alle üben sollten), einschließlich Python und Awk, und dem Erlernen von XML (Kinder lernen heutzutage nicht, wie die reale Welt aussieht!) wurde die Behauptung als genau erwiesen für enwiki (englischer Wikipedia-Artikel-Dump).
Unser ‚Projekt‘
Aus einer anfänglichen technologischen Lernherausforderung wurde ein sommerlanges Wikipedia-Datenfest.
Wikipedia: Die Daten
Die Verdauung der größten Online-Enzyklopädie der Welt stellt eine Reihe von Herausforderungen dar.
- Er ist umfangreich: Der Dump vom 1. Juli 2019, auf den wir zugegriffen haben, ist ein 16 GB großes, stark komprimiertes Archiv mit vielen bzipped XML-Dateipartitionen.
- Es ist schwierig: Es kostet Zeit und Ressourcen, die Rohdaten zu übertragen, zu speichern und zu verarbeiten.
- Neues, verwirrendes Terrain: Wikipedia hat eine Menge Geschichte und nuancierte, reichhaltige Daten, Metadaten und Metadaten über die Metadaten.
- Tricks beim Parsen von Vorlagen: In der XML-Datei einer Wikipedia-Seite befindet sich neben den Metadaten auch der eigentliche Text der Seite. Der Seitentext ist eine Kombination aus Freiform-Prosa in Verbindung mit einer speziellen Syntax für Hyperlinks sowie verschachtelten Vorlagen mit möglicherweise noch mehr Vorlagen.
Unser Data Scientist-Praktikant hat die Herausforderungen mit Bravour gemeistert und einen Arbeitsablauf wie im Diagramm dargestellt erstellt:

Parsen und Extrahieren
Viele Lucene- und Solr-Wikipedia-Demos gehen nur in die Texttiefe und ignorieren Metadaten oder fassen sie in einem allgemeinen Suchtextfeld zusammen. Unser Ziel war es, ein wenig tiefer zu gehen und „Typen“ aus verschachtelten Wikipedia-Infobox-Vorlagen zu extrahieren. Die folgenden Bilder veranschaulichen, wie dies auf einer repräsentativen Wikipedia-Seite aussieht:
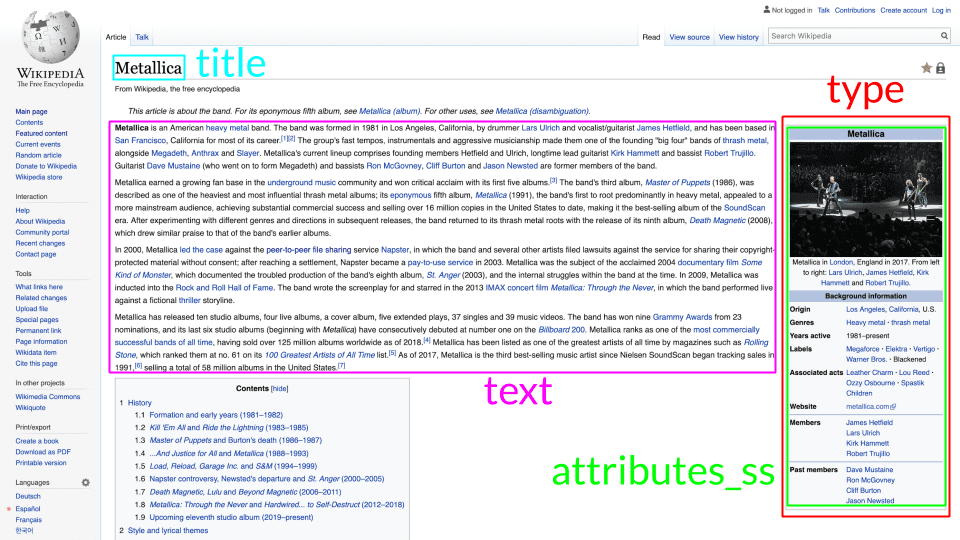
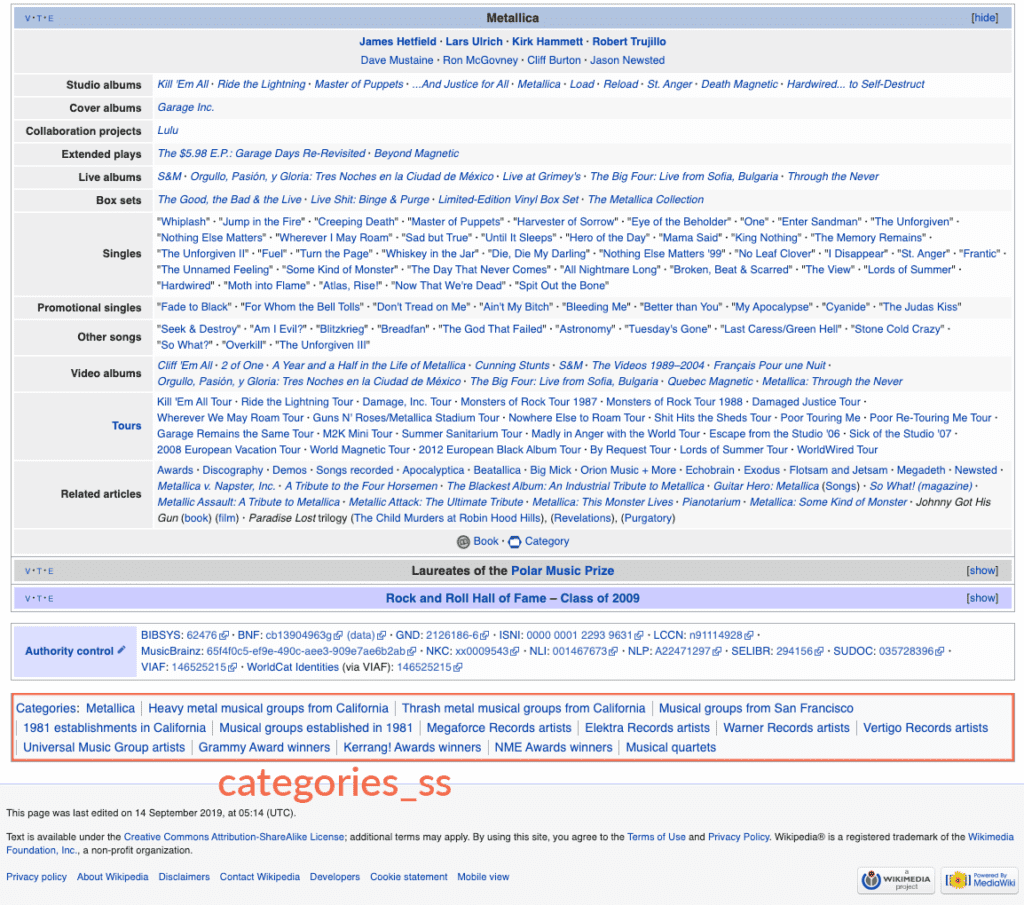
Unser Parser extrahiert Infoboxen, indem er die Namen der Infoboxen, die im Text einer Seite gefunden werden, einem Solr-Feld `Typ` zuordnet. Typen/Infoboxen sind Dinge wie `Person`, `Musikkünstler`, `Schule`, `Flughafen`, `Künstler`, `Fluss`, `Berg` und eine Menge anderer. Jede Infobox enthält Schlüssel/Wert-Paare mit detaillierten Metadaten über die jeweilige Infobox. Die Seite von Metallica hat zum Beispiel eine Infobox `musical_artist`, die ihre `years_active` als „1981-present“ beschreibt und ihre `website` als “ metallica.com„, und so weiter.
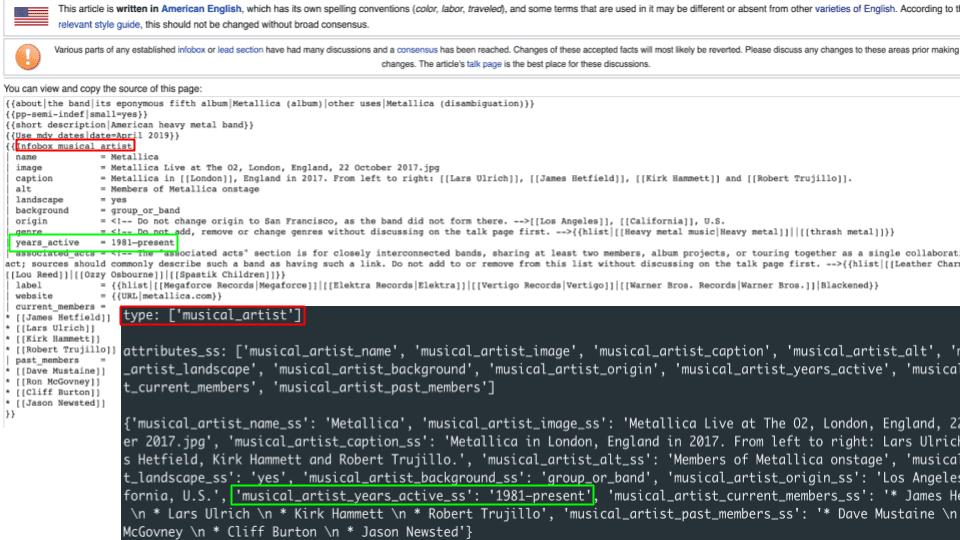
Ein einfaches Mittel, um die Seitendaten zu analysieren, sind die mit der Seite verbundenen Kategorien. Wikipedia-Kategorien umfassen verschiedene Granularitäten von Gruppierungen von Seiten wie z.B. „Heavy Metal-Musikgruppen aus Kalifornien“ und ermöglichen es der Wikipedia-Gemeinschaft, auf einfache Weise neue Kategorien zu erstellen und sie mit Seiten zu verknüpfen.
Wir haben dies so modelliert, als wäre jede Seite ein „Objekt“, das in Solr als Dokument indiziert ist, das durch die Namen der einzelnen Infoboxen typisiert ist, die im Allgemeinen „is-a“-Beziehungen darstellen (Metallica is-a musical_artist), mit einem hyperindizierten Bündel von Feldern mit Namensraum für jedes Attribut jeder Infobox. Einige Seiten haben mehrere Infoboxen, zum Beispiel Der Berg Davidson ist sowohl ein `Berg` als auch ein `Park` und hat jeweils seine eigenen Attribute wie „mountain_elevation_ft=928“ und „park_status=Open all year“.
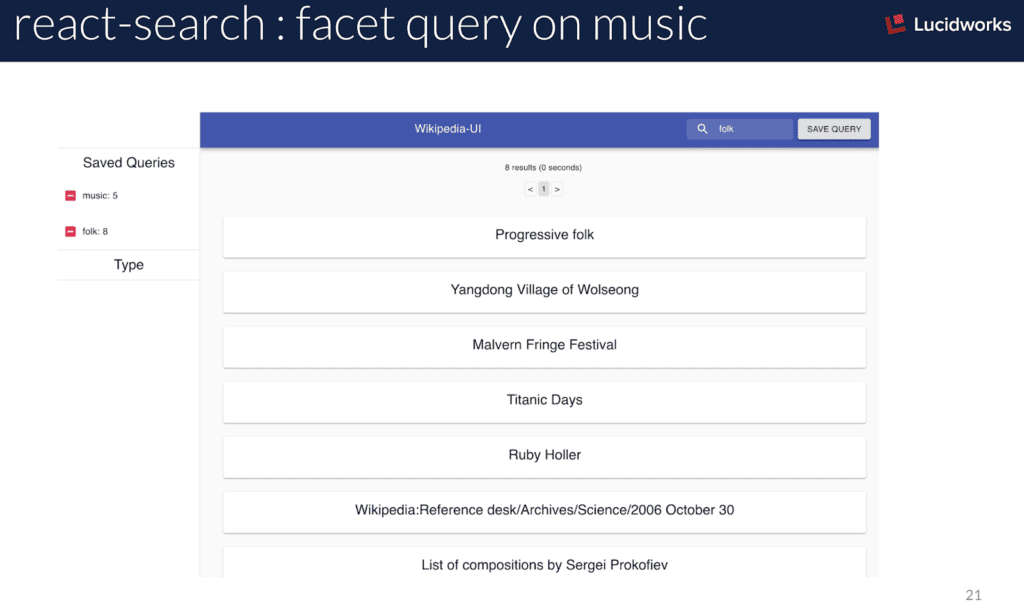
Navigieren in der Sammlung
Wir haben unsere Praktikantin im Bereich Softwaretechnik gebeten, eine Web-UI zur Anzeige von Suchergebnissen in einer Fusion-Abfrage-Pipeline zu erstellen. Sie hat React erlernt, also haben wir uns für dieses UI-Framework entschieden. Ihre kreative UI verhält sich etwas anders als die herkömmliche Suche und Ergebnisanzeige. Ihre React-Suchoberfläche erzeugt ohne jegliche Anweisung, wie sie sich verhalten soll, Suchergebnisse nach Typ und Facettierung. Die Facettierung nach Typ ermöglicht eine Mehrfachauswahl, eine sehr faszinierende Art und Weise, durch die Überschneidungen von Typen von Wikipedia-Dingen zu navigieren („Welche Schulen stehen auch im National Registry of Historic Places?“; „Welche Inseln sind auch Vulkane?“, „Welche Flüsse sind auch Schutzgebiete?“).
Außerdem können Abfragen im lokalen Status der Anwendung gespeichert und zu jeder Abfrage als Solr `facet.query` hinzugefügt werden, so dass die Kardinalität der aktuellen Abfrage mit jeder zuvor gespeicherten Abfrage überlappt. Die Verwendung einer Handvoll geschickt gestalteter `facet.query`s ist eine unterschätzte und zu wenig genutzte Funktion von Solr, die einen Einblick in verschiedene Teilmengen eines Universums von Dokumenten ermöglicht.
Lou lernt Wikipedia
Wir haben den größten Teil des Sommers damit verbracht, die oben beschriebenen Teile zu entwickeln und zu implementieren, so dass nur wenig Zeit für die Integration der Wunschliste „Chat“ blieb. Mit dem bereits brauchbaren `Lou`-Prototypen, an dem ich herumgebastelt habe, war es ein Leichtes, einen Teil unserer großen Wikipedia-Sammlung in eine `Dinge`-Sammlung zu importieren, um ein paar schnelle und schmutzige Frage-Antwort-Interaktionen zu demonstrieren:
„Wie groß ist der Berg <> ?“
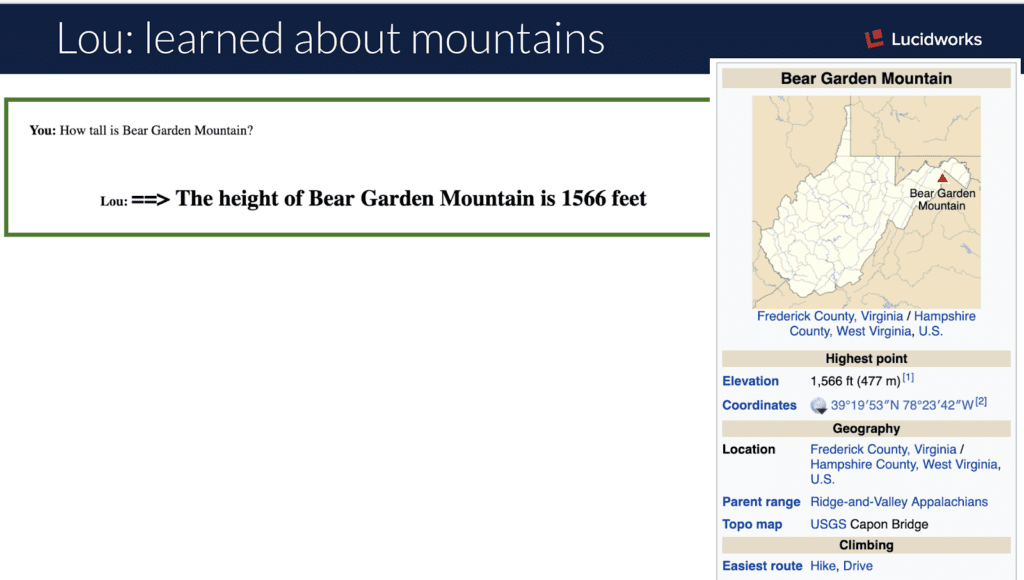
Wikipedia-Seiten, die Berge beschreiben, haben eine Infobox mit dem Namen `Berg`, die Informationen über die Höhe in verschiedenen Einheiten liefert, damit Sie auf dem Weg nach unten auf dem Laufenden bleiben. Die Lou-Webapplikation ruft eine Fusion-Pipeline auf, die die Abfrage zunächst mit dem Solr Tagger taggt und alle bekannten „Dinge“ in der Äußerung identifiziert. Die Abfrage wird dann mit den Typen der getaggten Dinge parametrisiert und sucht in einer zweiten Solr-Sammlung nach einer bestimmten generischen Grammatik, die eine Antwortvorlage enthält, um die Leerstellen des tatsächlich erwähnten „Dinges“ auszufüllen.
„Wofür ist <Wissenschaftler> bekannt?“

Ebenso bietet eine Infobox `Wissenschaftler` ein Attribut `bekannt_für`, das eine kurze Beschreibung der Highlights des Wissenschaftlers enthält. Mit dem Solr Tagger, ein wenig JavaScript und einem Slotted Grammar Lookup ist Lou in der Lage, alle möglichen grundlegenden Fragen aus Wikipedia zu beantworten.
Was kommt als Nächstes?
Dieses Projekt hat weitreichendere Auswirkungen als nur einen lustigen Sommer. Einige vorläufige Ergebnisse sehen vielversprechend aus, wenn man die extrahierten Typen als Mittel zur Erkundung von Solr’s semantischer Wissensgraph Verwandtschaft() Funktion. Welches sind die besten Objekttypen bei einem Text, z.B. einer Anfrage oder einer Äußerung? „Aufstieg in die Höhe“ zeigt an, dass `Berg` der beste Typ ist, während „Wasserfluss Stromschnellen“ anzeigt, dass `Fluss` der beste Typ ist.
Neben der Typennavigation und dem semantischen Bucketing können wir das Gleiche mit den extrahierten Kategorien tun.
Wir haben noch nicht damit begonnen, die Daten mit maschinellem Lernen zu bearbeiten, um sie zu kategorisieren usw., aber wir würden das gerne tun.
Die Daten selbst sind zwar hyperstrukturiert, haben aber auch einige Probleme mit der Integrität, und es ist noch mehr Arbeit nötig, um die Arten von Dingen in eine Taxonomie einzupassen. Es gibt zum Beispiel eine Infobox/einen Typ „Wissenschaftler“ und einige, aber nicht alle, haben auch eine Infobox/einen Typ „Person“.
Wir haben gerade erst begonnen, diese Daten zu erforschen und herauszufinden, was sie für uns tun können. Bleiben Sie dran, während wir daran arbeiten, unsere Demosysteme für die weltweite Verfügbarkeit vorzubereiten, damit wir alle ein von Fusion betriebenes Wikipedia erleben können.