Grundlagen der Speicherung von Signalen in Solr mit Fusion für Dateningenieure
Im April veröffentlichten wir einen Gastbeitrag Mixed Signals: Using Lucidworks Fusion’s Signals API, der eine großartige Einführung in die Fusion Signals API ist. In diesem Beitrag gehe ich einen realen E-Commerce-Datensatz durch, um zu zeigen, wie schnell Sie mit der Fusion-Plattform Signale aus den Protokollen von Suchanfragen nutzen können, um die Suchergebnisse für einen Produktkatalog schnell und drastisch zu verbessern.
Signale, wozu sind sie gut?
Generell sind Signale immer dann nützlich, wenn Informationen über externe Aktivitäten, wie z.B. das Nutzerverhalten, genutzt werden können, um die Qualität der Suchergebnisse zu verbessern. Signale sind besonders nützlich in E-Commerce-Anwendungen, wo sie sowohl für Empfehlungen als auch für die Verbesserung der Suche verwendet werden können. Signaldaten stammen aus Serverprotokollen und Transaktionsdatenbanken, die Artikel aufzeichnen, die Benutzer suchen, ansehen, anklicken, mögen oder kaufen. So werden beispielsweise Clickstream-Daten, die die Suchanfrage eines Benutzers zusammen mit dem Artikel aufzeichnen, auf den schließlich geklickt wurde, als ein „Klick“-Signal behandelt und können verwendet werden, um:</p
- die Ergebnismenge für diese Suchanfrage bereichern, d.h. die für diese Anfrage zurückgegebenen Artikel verbessern
- die Informationen über den angeklickten Artikel anreichern, d.h. die Abfragen für diesen Artikel verbessern
- Ähnlichkeiten zwischen Artikeln aufdecken, d.h. Artikel auf der Grundlage anderer Klicks auf für Abfragen clustern
- Empfehlungen für das Formular abgeben:
- „andere Kunden, die diese Anfrage eingegeben haben, haben darauf geklickt“
- „Kunden, die dies gekauft haben, haben auch das gekauft“
Signale Schlüsselkonzepte
- Ein Signal ist eine Information, ein Ereignis oder eine Aktion, z.B. Benutzerabfragen, Klicks und andere aufgezeichnete Aktionen, die mit einem oder mehreren Dokumenten in Verbindung gebracht werden können, die in einer Fusion-Sammlung gespeichert sind, die als „Primärsammlung“ bezeichnet wird.
- Ein Signal hat einen Typ, eine ID und einen Zeitstempel. Zum Beispiel sind Signale aus Clickstream-Informationen vom Typ „Klick“ und Signale aus Abfrageprotokollen vom Typ „Abfrage“.
- Signale werden in einer Hilfssammlung gespeichert und die Namenskonventionen verbinden die beiden so, dass der Name der Signalsammlung der Name der primären Sammlung plus dem Suffix „_signals“ ist.
- Eine Aggregation ist das Ergebnis der Verarbeitung eines Stroms von Signalen in eine Reihe von Zusammenfassungen, die zur Verbesserung des Sucherlebnisses verwendet werden können. Die Aggregation ist notwendig, weil in der Regel eine große Menge an Signalen in das System einfließt, aber jedes Signal für sich genommen nur eine kleine Menge an Informationen enthält.
- Die Aggregationen werden in einer Hilfssammlung gespeichert und die Namenskonventionen verbinden die beiden so, dass der Name der Aggregations-Sammlung der Name der primären Sammlung plus dem Suffix „_signals_aggr“ ist.
- Abfrage-Pipelines verwenden aggregierte Signale, um die Suchergebnisse zu verbessern.
- Fusion bietet eine umfangreiche Bibliothek von Aggregationsfunktionen, mit denen sich komplexe Modelle des Nutzerverhaltens erstellen lassen. Insbesondere die Datum-Zeit-Funktionen bieten eine zeitliche Abklingfunktion, so dass ältere Signale im Laufe der Zeit automatisch heruntergewichtet werden.
- Der Job Scheduler von Fusion bietet den Mechanismus für die Verarbeitung von Signalen und Aggregations-Sammlungen in nahezu Echtzeit.
Einige Montage erforderlich
In einer kanonischen E-Commerce-Anwendung ist Ihre primäre Fusion-Sammlung die Sammlung über Ihre Produkte, Dienstleistungen, Kunden und ähnliches. Ereignisinformationen aus Transaktionsdatenbanken und Serverprotokollen würden in einer Hilfssammlung von Rohsignaldaten indiziert und anschließend in einer aggregierten Signalsammlung verarbeitet. Die Informationen aus der aggregierten Signalsammlung werden verwendet, um die Suche in der primären Sammlung zu verbessern und den Benutzern Produktempfehlungen zu geben.
In Ermangelung einer voll funktionsfähigen E-Commerce-Website enthält die Fusion-Distribution ein Beispiel für Signale und ein Skript, das diese Signaldaten mithilfe der Fusion Signals REST-API zu einer aggregierten Signalsammlung verarbeitet. Das Skript und die Datendateien befinden sich im Verzeichnis $FUSION/examples/signals (wobei $FUSION das oberste Verzeichnis der Fusion-Distribution ist). Dieses Verzeichnis enthält:
signals.json– einen Beispieldatensatz von 20.000 Signalereignissen. Dies sind ‚Klick‘-Ereignisse.signals.sh– ein Skript, das Signale lädt, einen Aggregationsauftrag ausführt und Empfehlungen aus den aggregierten Signalen abruft.aggregations_definition.json– Beispiele dafür, wie Sie eigene Aggregationsfunktionen schreiben können. Diese Beispiele demonstrieren verschiedene fortgeschrittene Funktionen der Aggregations-Skripterstellung, die alle über den Rahmen dieser Einführung hinausgehen.
Die Beispielsignaldaten stammen aus einem synthetischen Datensatz über die Suchprotokolle von Best Buy aus dem Jahr 2011. Jeder Datensatz enthält die Suchanfrage des Benutzers, die gesuchten Kategorien und den Artikel, auf den letztendlich geklickt wurde. In den nächsten Abschnitten erstelle ich den Produktkatalog, die Rohsignale und die aggregierten Signalsammlungen.
Produktdaten: die primäre Sammlung ‚bb_catalog‘.
Um die Verwendung von Signalen in einen Kontext zu stellen, stelle ich zunächst eine Teilmenge des Produktkatalogs von Best Buy nach. Lucidworks kann die Produktkatalogdaten von Best Buy, auf die sich die Beispielsignaldaten beziehen, nicht verteilen, aber diese Daten sind über die Best Buy Developer API verfügbar, die eine großartige Ressource sowohl für Daten als auch für Beispielanwendungen darstellt. Ich habe eine Kopie der zuvor heruntergeladenen Produktdaten, die zu einer einzigen Datei mit einer Liste von Produkten verarbeitet wurden. Jedes Produkt ist ein separates JSON-Objekt mit vielen Attribut-Werte-Paaren. Um Ihren eigenen Best Buy Produktkatalog-Datensatz zu erstellen, müssen Sie sich über die oben genannte URL als Entwickler registrieren. Dann können Sie das Abfragetool der Best Buy Entwickler-API verwenden, um Produktdatensätze auszuwählen, oder Sie können eine Reihe von JSON-Dateien über die kompletten Produktarchive herunterladen.
Ich erstelle mit der Fusion 2.0-Benutzeroberfläche eine Datensammlung namens „bb_catalog“. Damit werden standardmäßig auch Sammlungen für die Signale und aggregierten Signale erstellt.
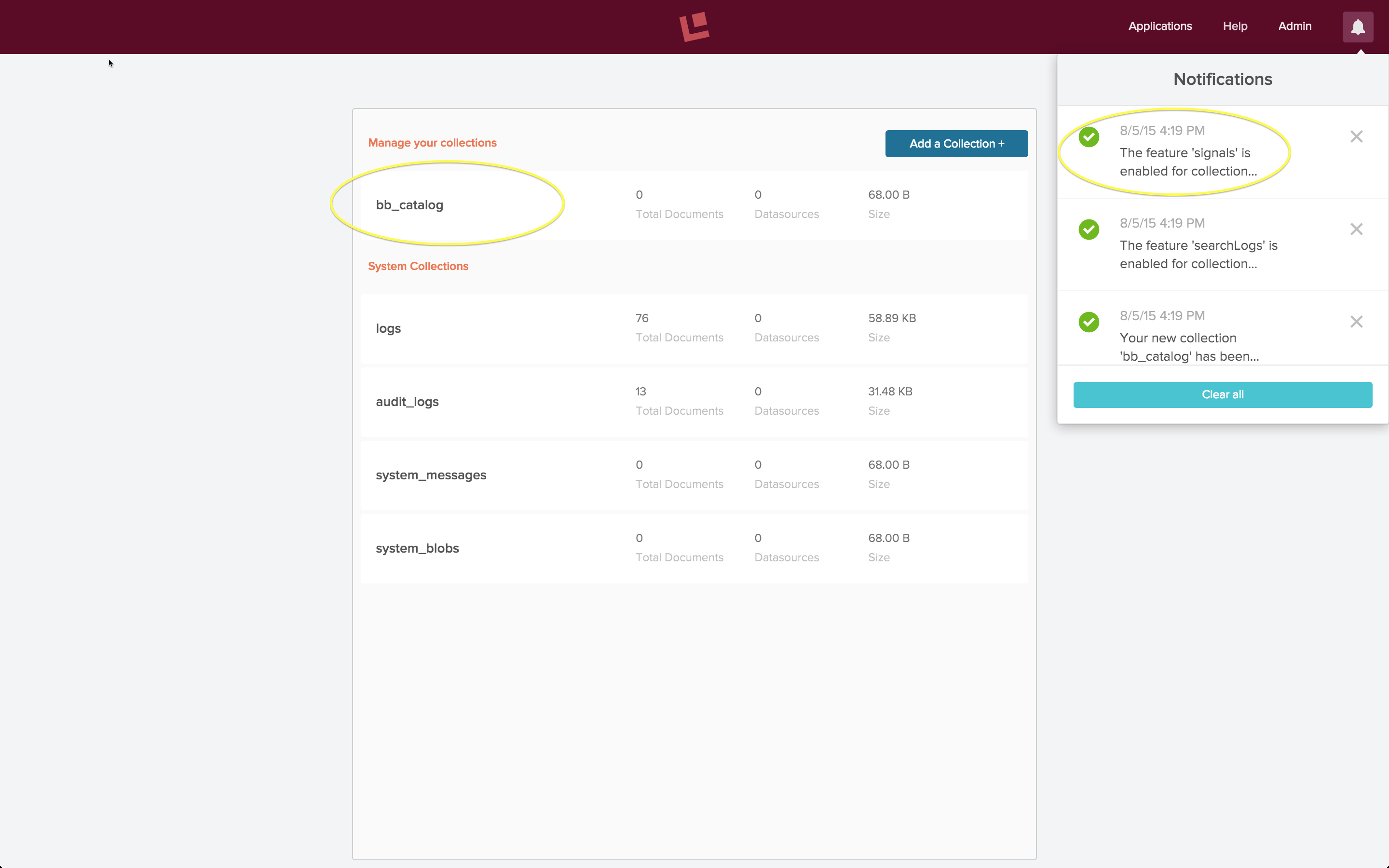
Obwohl im Sammlungen-Panel nur die Sammlung „bb_catalog“ angezeigt wird, wurden auch die Sammlungen „bb_catalog_signals“ und „bb_catalog_signals_aggr“ erstellt. Wenn ich die Sammlung „bb_catalog“ anschaue, lautet die im Browser angezeigte URL: „localhost:8764/panels/bb_catalog“:
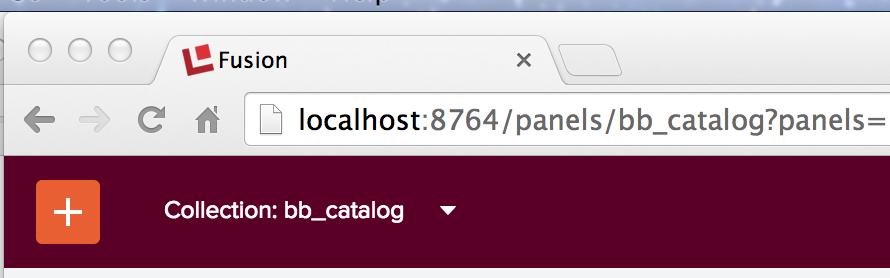
Wenn ich den Namen der Sammlung in „bb_catalog_signals“ oder „bb_catalog_signals_aggr“ ändere, kann ich die (leeren) Inhalte der Hilfssammlungen anzeigen:
Als nächstes indiziere ich die Produktkatalogdaten von Best Buy in der Sammlung „bb_catalog“. Wenn Sie sich dafür entscheiden, die Daten im JSON-Format zu erhalten, können Sie sie mit der Indizierungspipeline „JSON“ in Fusion einlesen. Im Blogbeitrag Vorläufige Datenanalyse in Fusion 2 finden Sie weitere Einzelheiten zur Konfiguration und Ausführung von Datenquellen in Fusion 2.
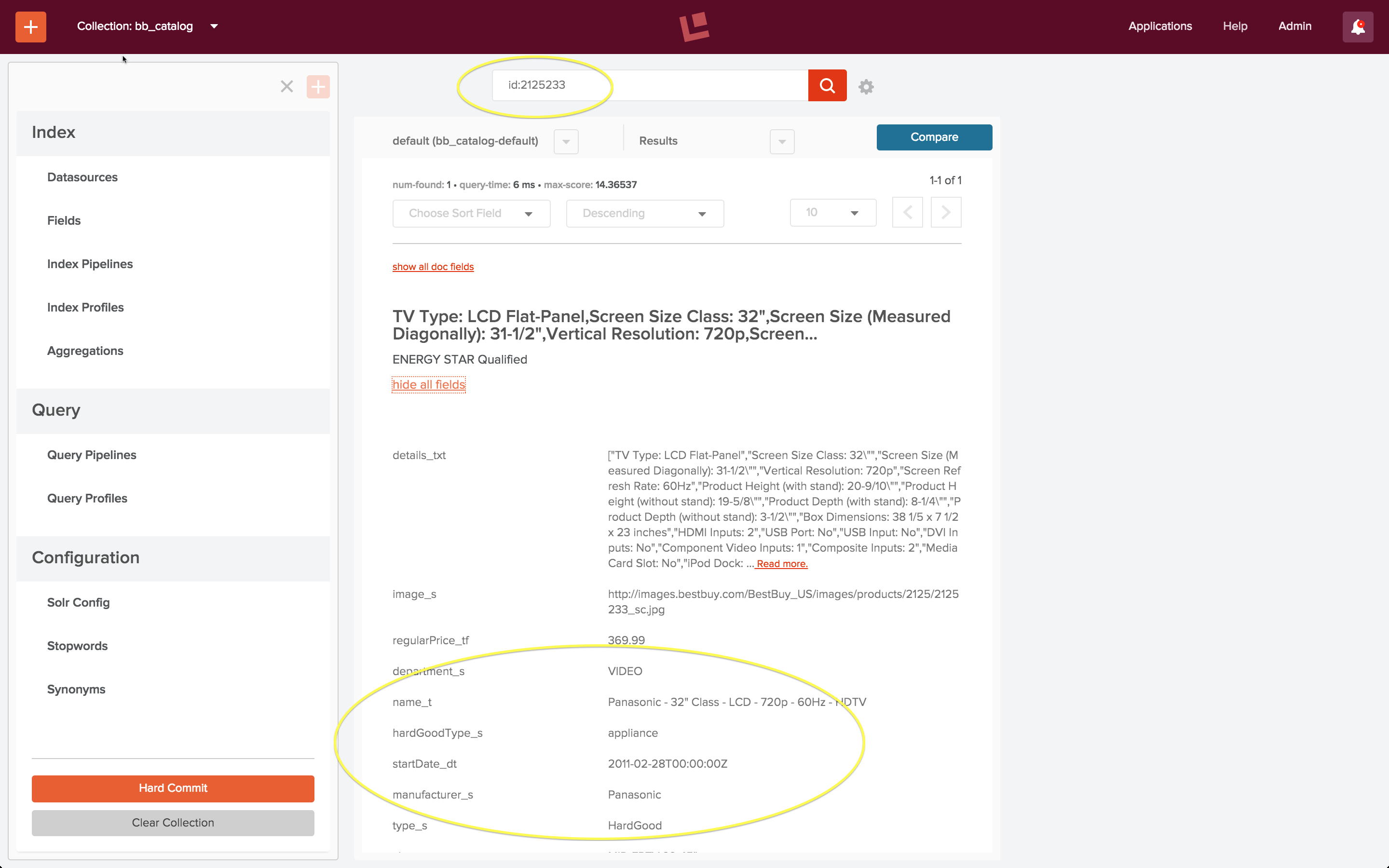
Nach dem Laden des Produktkatalogdatensatzes prüfe ich, ob die Sammlung „bb_catalog“ die Produkte enthält, auf die die Signaldaten verweisen. Der erste Eintrag in der Beispielsignaldatei „signals.json“ ist eine Suchabfrage mit dem Abfragetext: „Televisiones Panasonic 50 pulgadas“ und docId: „2125233“. Ich führe eine Schnellsuche durch, um ein Produkt mit dieser ID in der Sammlung „bb_catalog“ zu finden, und die Ergebnisse sind wie erwartet:
Signal-Rohdaten: die Hilfssammlung ‚bb_catalog_signals‘.
Die rohen Signaldaten in der Datei „signals.json“ sind der synthetische Best Buy-Datensatz. Ich habe die Zeitstempel in den Suchprotokollen so verändert, dass sie wie frische Protokolldaten aussehen. Dies ist das erste Signal (Zeitstempel aktualisiert):
{
"timestamp": "2015-06-01T23:44:52.533Z",
"params": {
"query": "Televisiones Panasonic 50 pulgadas",
"docId": "2125233",
"filterQueries": [
"cat00000",
"abcat0100000",
"abcat0101000",
"abcat0101001"
]
},
"type": "click"
},
Die Top-Level-Attribute dieses Objekts sind:
- Typ – Wie bereits erwähnt, müssen alle Signale einen „Typ“ haben. Wie im früheren Beitrag „Gemischte Signale“, Abschnitt „Senden von Signalen“, erwähnt, sollte der Wert konsistent angewendet werden, um eine genaue Aggregation zu gewährleisten. In dem Beispieldatensatz sind alle Signale vom Typ „Klick“.
- timestamp – Diese Daten enthalten Zeitstempelinformationen. Wenn sie im Rohsignal nicht vorhanden ist, wird sie vom System generiert.
- id – Diese Signale haben keine eindeutigen IDs; sie werden automatisch vom System generiert.
- params – Dieses Attribut enthält eine Reihe von Schlüssel-Wert-Paaren, die eine Reihe von vordefinierten Schlüsseln verwenden, die für die Ereignisinformationen der Suchabfrage geeignet sind. In diesem Datensatz umfassen die erfassten Informationen die vom Benutzer eingegebene Freitextsuchanfrage, die Dokument-ID des angeklickten Artikels und die Kategorien der Best Buy-Website, auf die die Suche beschränkt war. Dabei handelt es sich um Codes für Kategorien und Unterkategorien wie „Elektronik“ oder „Fernsehgeräte“.
Zusammenfassend lässt sich sagen, dass dieser Datensatz eine unauffällige Momentaufnahme des Nutzerverhaltens zwischen Mitte August und Ende Oktober 2011 ist (aktualisiert auf Mai bis Juni 2015).
Das Beispielskript „signals.sh“ lädt das Rohsignal über eine POST-Anfrage an den Fusion REST-API Endpunkt:
/api/apollo/signals/<collectionName>
wobei <collectionName> der Name der primären Sammlung selbst ist. Um also rohe Signaldaten in die Fusion-Sammlung „bb_catalog_signals“ zu laden, sende ich eine POST-Anfrage an den Endpunkt:
/api/apollo/signals/bb_catalog
Wie bei allen Indizierungsprozessen wird eine Indizierungspipeline verwendet, um die rohen Signaldaten in eine Reihe von Solr-Dokumenten zu verarbeiten. Die hier verwendete Pipeline ist die standardmäßige Signal-Indizierungspipeline namens „_signals_ingest“. Diese Pipeline besteht aus drei Stufen, von denen die erste eine Signalformatierungsstufe ist, gefolgt von einer Field Mapper Stufe und schließlich einer Solr Indexer Stufe.
(Beachten Sie, dass in einem Produktionssystem anstelle eines einmaligen Uploads einiger Serverprotokolldaten rohe Signaldaten kontinuierlich in eine Signalsammlung gestreamt werden könnten, indem ein Logstash- oder JDBC-Konnektor zusammen mit einer Signals-Indizierungspipeline verwendet wird. Einzelheiten zur Verwendung eines Logstash-Konnektors finden Sie im Blogbeitrag über Fusion mit Logstash).
Hier ist der curl-Befehl, mit dem ich Fusion lokal im Einzelservermodus auf dem Standardport ausgeführt habe:
curl -u admin:password123 -X POST -H 'Content-type:application/json' http://localhost:8764/api/apollo/signals/bb_catalog?commit=true --data-binary @new_signals.json
Dieser Befehl wird ohne Probleme ausgeführt. Um meine Arbeit zu überprüfen, verwende ich die Fusion 2-Benutzeroberfläche, um die Signalsammlung anzuzeigen, indem ich explizit die URL „localhost:8764/panels/bb_catalog_signals“ eingebe. Dies zeigt, dass alle 20K Signale indiziert wurden:
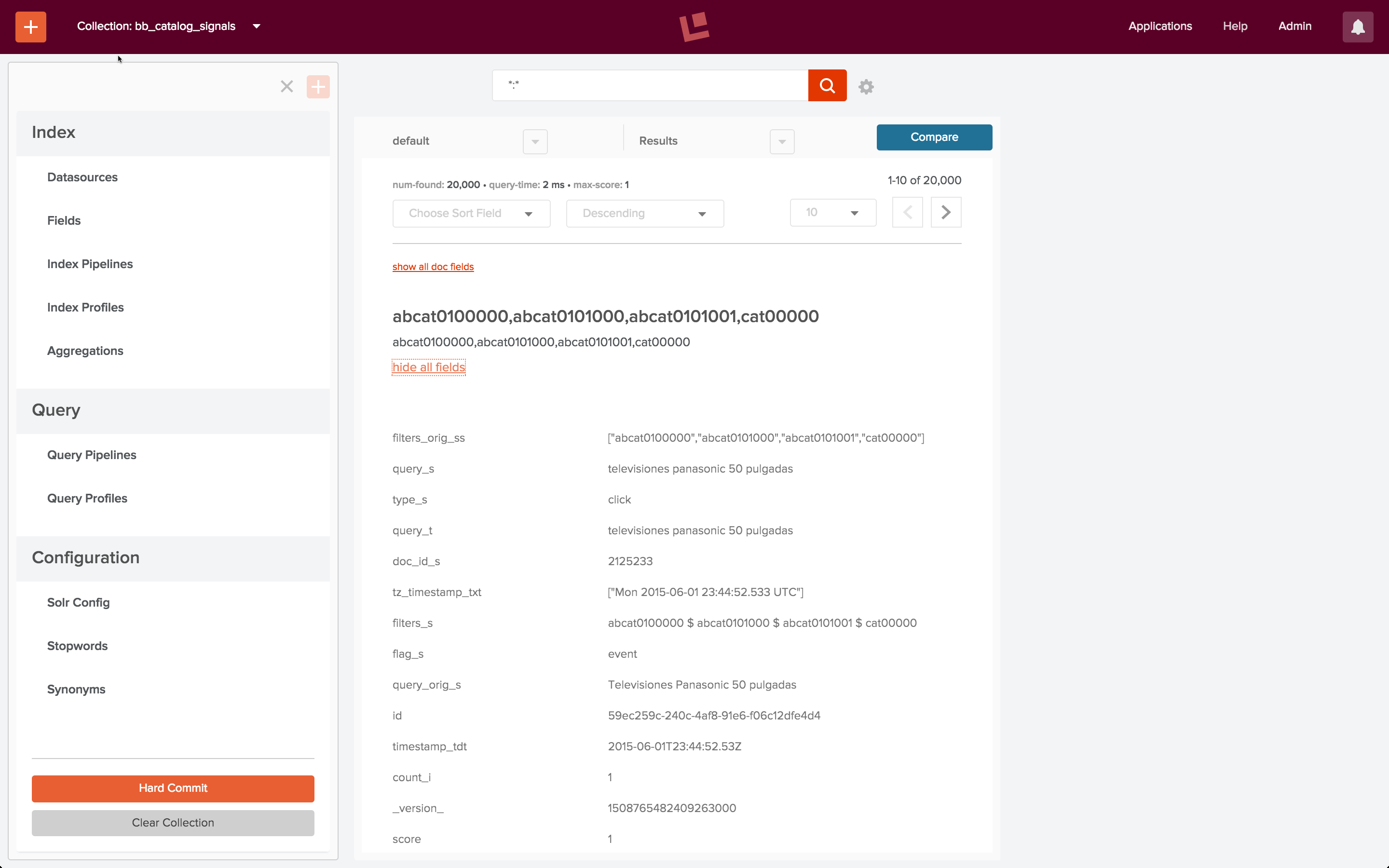
Sie können die Daten mit Hilfe von Fusion Dashboards weiter untersuchen. Um ein Fusion Dashboard mit Banana 3 zu konfigurieren, gebe ich die URL „localhost:8764/banana“ an. (Einzelheiten und Anweisungen zu Banana 3 Dashboards finden Sie in diesem Beitrag über Log Analytics). Ich konfiguriere ein Dashboard für Signale und sehe mir die Ergebnisse an:
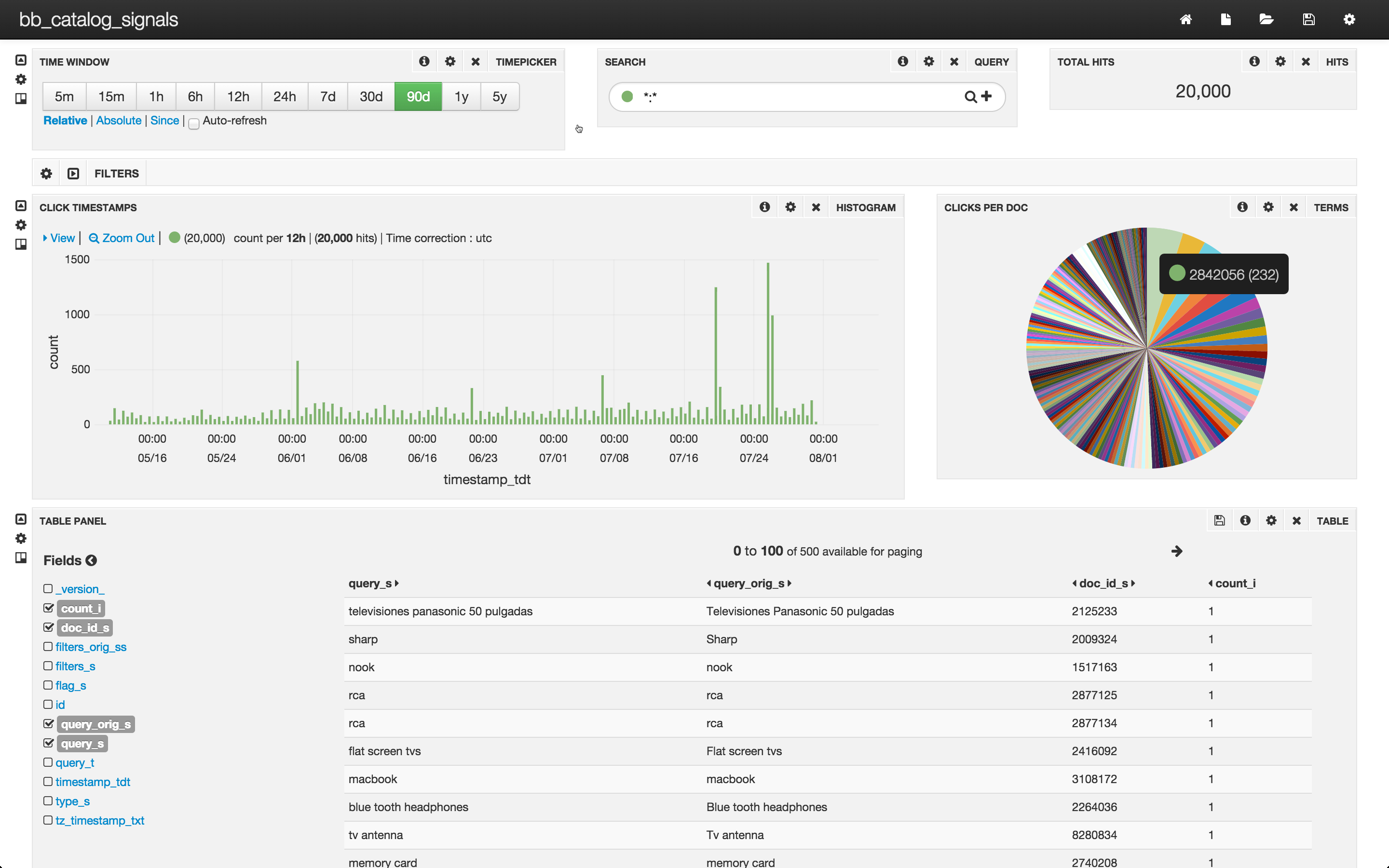
Die oberste Zeile dieses Dashboards zeigt, dass es 20.000 Klicks in der Sammlung bb_catalog_signals gibt, die in den letzten 90 Tagen aufgezeichnet wurden. Die mittlere Zeile enthält ein Balkendiagramm mit dem Zeitpunkt, zu dem die Klicks erfolgten, und ein Tortendiagramm mit den 200 am häufigsten angeklickten Dokumenten. Die untere Zeile ist eine Tabelle über alle Signale – jedes Signal enthält nur einen Klick.
Mit dem Tortendiagramm können wir eine einfache Aggregation der Klicks pro Dokument visualisieren. Das beliebteste Dokument erhielt 232 Klicks, etwa 1 % der gesamten Klicks. Das 200. beliebteste Dokument erhielt 12 Klicks, und die überwiegende Mehrheit der Dokumente erhielt nur einen Klick pro Dokument. Um Informationen über angeklickte Dokumente zu nutzen, müssen wir diese Informationen in einer Form zur Verfügung stellen, die Solr nutzen kann. Mit anderen Worten, wir müssen eine Sammlung von aggregierten Signalen erstellen.
Aggregierte Signaldaten: die Hilfssammlung ‚bb_catalog_signals_aggr‘.
Die Aggregation ist der „verarbeitende“ Teil der Signalverarbeitung. Die Fusion führt Abfragen über die Dokumente in der Rohsignalsammlung aus, um neue Dokumente für die aggregierte Signalsammlung zu synthetisieren. Die Synthese reicht von Zählungen bis hin zu ausgefeilten statistischen Funktionen. Die Art der gesammelten Signale bestimmt die Art der durchgeführten Aggregationen. Bei Klick-Signalen aus Abfrageprotokollen ist die Verarbeitung unkompliziert: Ein Datensatz für aggregierte Signale enthält eine Suchanfrage, eine Zählung der Anzahl der Rohsignale, die diese Suchanfrage enthielten, und aggregierte Informationen aus allen Rohsignalen: Zeitstempel, IDs der angeklickten Dokumente, Einstellungen für die Suchanfrage, in diesem Fall die Produktkatalogkategorien, über die diese Suche durchgeführt wurde.
Um die Rohsignale in der Sammlung „bb_catalog_signals“ von der Fusion 2-Benutzeroberfläche aus zu aggregieren, wähle ich das Steuerelement „Aggregationen“, das im Abschnitt „Index“ des Home-Panels „bb_catalog_signals“ aufgeführt ist:
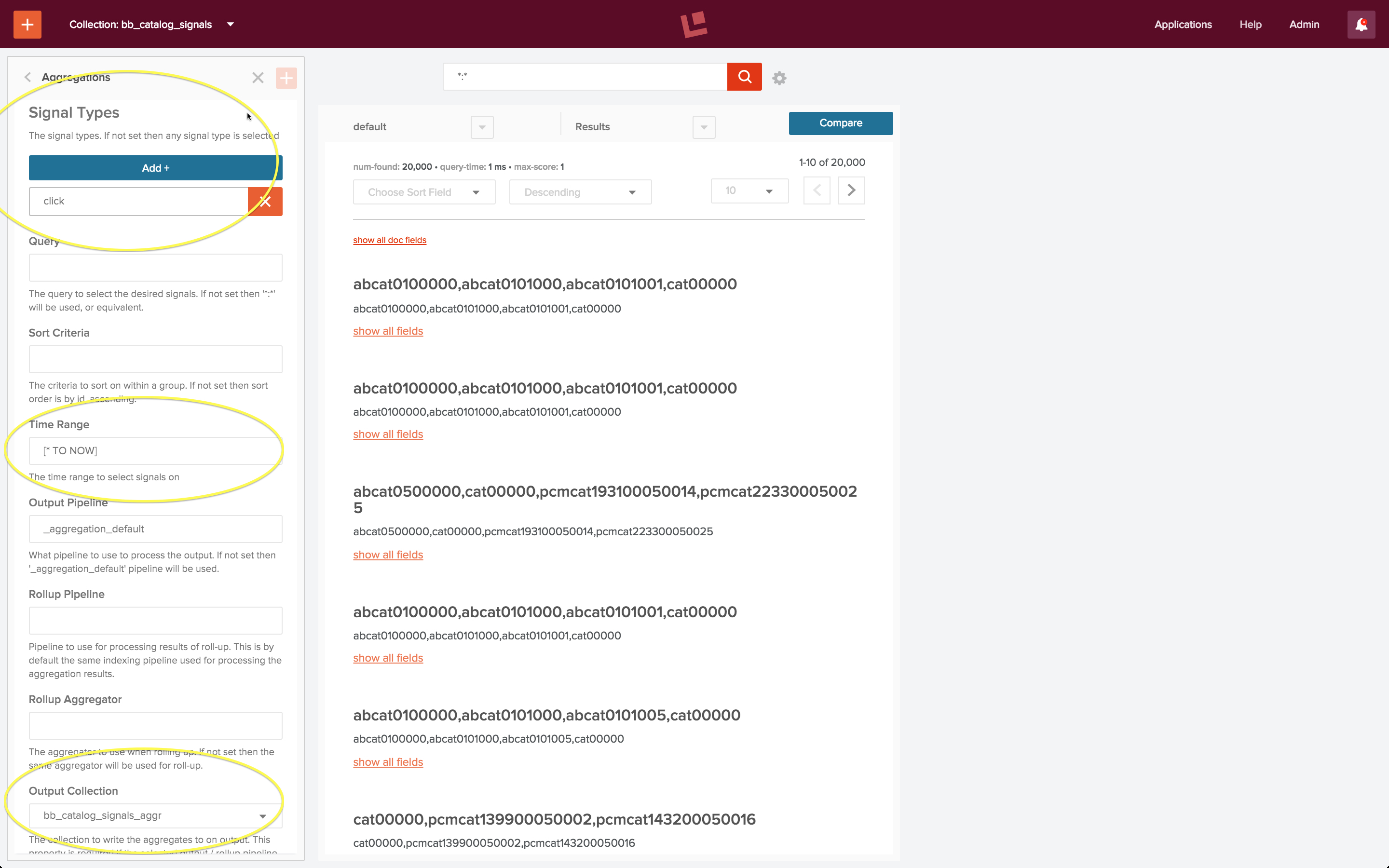
Ich erstelle eine neue Aggregation namens „bb_aggregation“ und definiere Folgendes:
- Signalarten = „Klick“
- Zeitbereich = „[* TO NOW]“ (alle Signale)
- Ausgabe Sammlung = „bb_catalog_signale_aggr“
Der folgende Screenshot zeigt die konfigurierte Aggregation. Die eingekreisten Felder sind die Felder, die ich explizit angegeben habe; alle anderen Felder wurden auf ihren Standardwerten belassen.
Sobald die Aggregation konfiguriert ist, wird sie über die Steuerelemente im Aggregationsbedienfeld ausgeführt. Die Ausführung dieser Aggregation dauert nur wenige Sekunden. Wenn sie beendet ist, wird die Anzahl der verarbeiteten Rohsignale und der erstellten aggregierten Signale unter den Steuerelementen Start/Stop angezeigt. Dieser Screenshot zeigt, dass die 20.000 Rohsignale in 15.651 aggregierte Signale synthetisiert wurden.
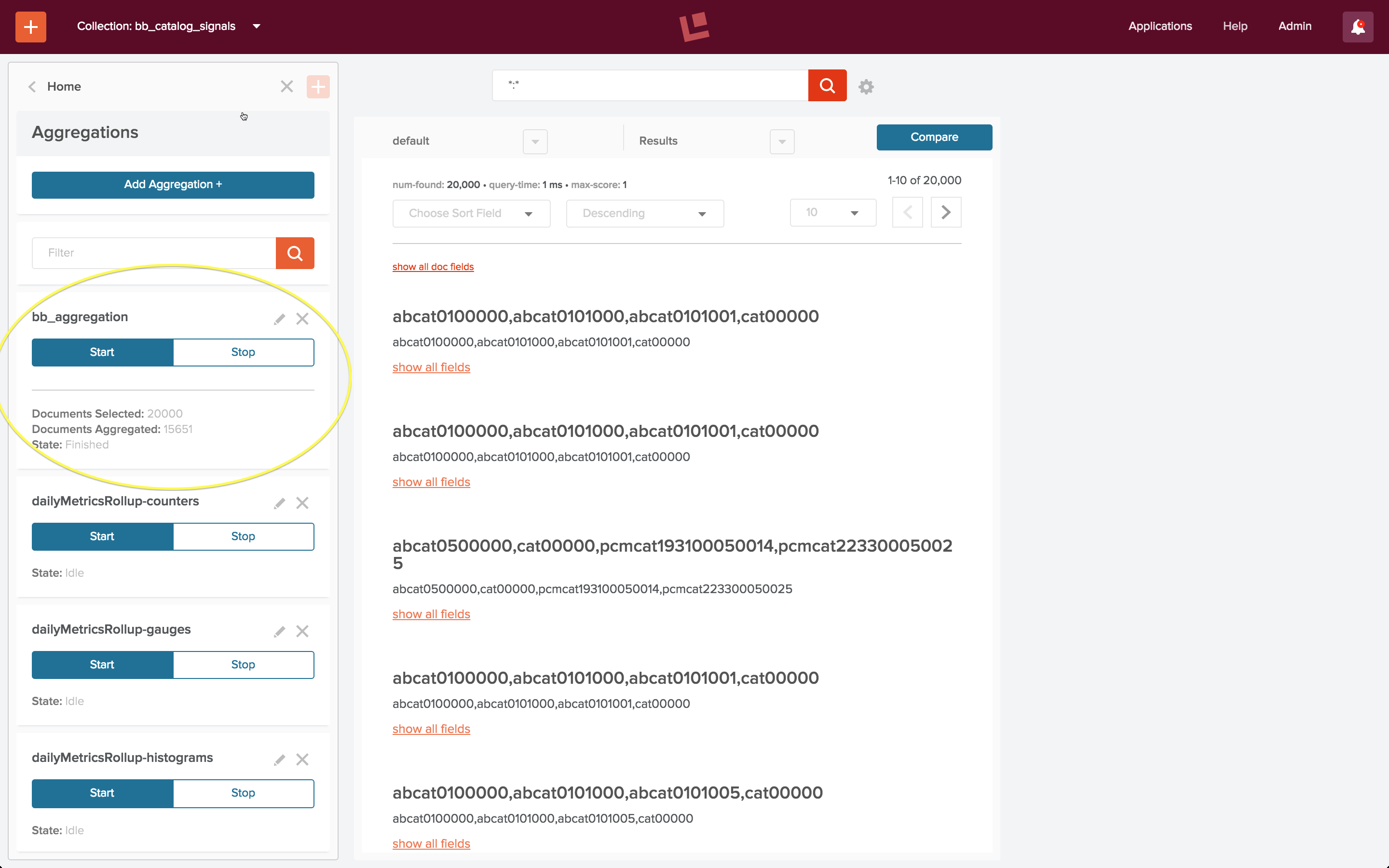
Um meine Arbeit zu überprüfen, verwende ich die Fusion 2-Benutzeroberfläche, um die Sammlung der aggregierten Signale anzuzeigen, indem ich explizit die URL „localhost:8764/panels/bb_catalog_signals_aggr“ angebe. Aggregierte Klick-Signale haben ein Feld „count“, das die Anzahl der Vorkommen der Kombination Suchanfrage + Dokument-ID angibt. (Hinweis: In meinem ursprünglichen Beitrag wurde fälschlicherweise behauptet, dass diese Sortierung die beliebtesten Suchanfragen anzeigt – das ist nicht der Fall. Die Zählung bezieht sich auf Suchanfrage + Aktion, was eine komplexere und nützlichere Information ist). Der folgende Screenshot zeigt diese Sortierreihenfolge:
Die Suchanfragen über den Best Buy-Katalog, die starke Muster im Nutzerverhalten zeigen, sind Suchanfragen nach großen elektronischen Konsumgütern: Fernsehgeräte und Computer, zumindest laut diesem speziellen Datensatz.
Fusion REST-API Empfehlungsdienst
Der letzte Teil des Beispielskripts „signals.sh“ ruft die Empfehlungsdienst-Endpunkte „itemsForQuery“, „queriesForItem“ und „itemsForItems“ der Fusion REST-API auf. Der erste Endpunkt, „itemsForQuery“, gibt die Liste der Elemente zurück, die für eine Abfragephrase angeklickt wurden. Im Beispiel „signals.sh“ lautet die Abfragezeichenfolge „laptop“. Wenn ich mit der Standard-Suchpipeline eine Suche nach dem Suchbegriff „laptop“ in der Sammlung „bb_catalog“ durchführe, enthalten die Ergebnisse keine Laptops:
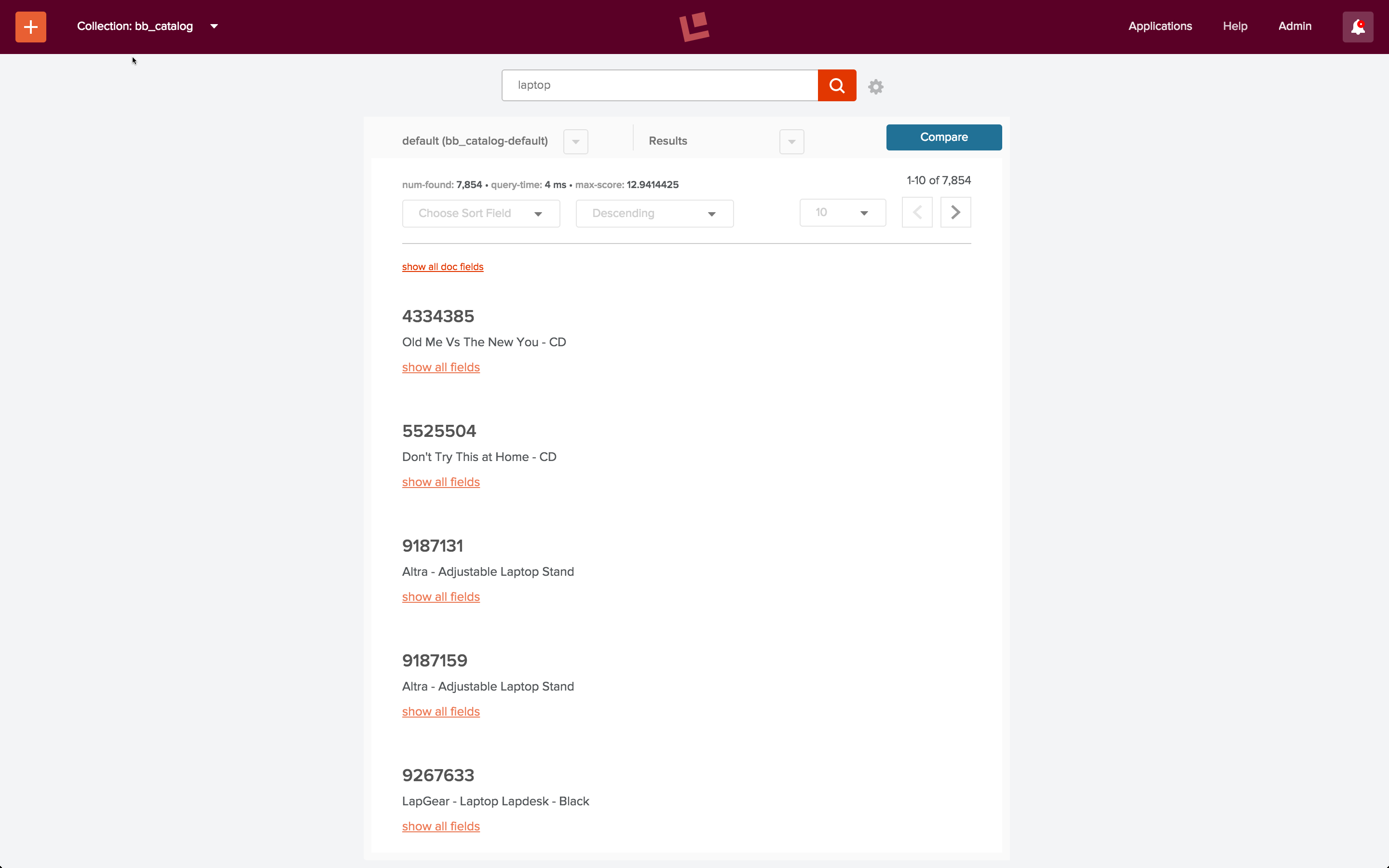
Mit richtig spezifizierten Feldern, Filtern und Boosts könnten die Ergebnisse wahrscheinlich verbessert werden.
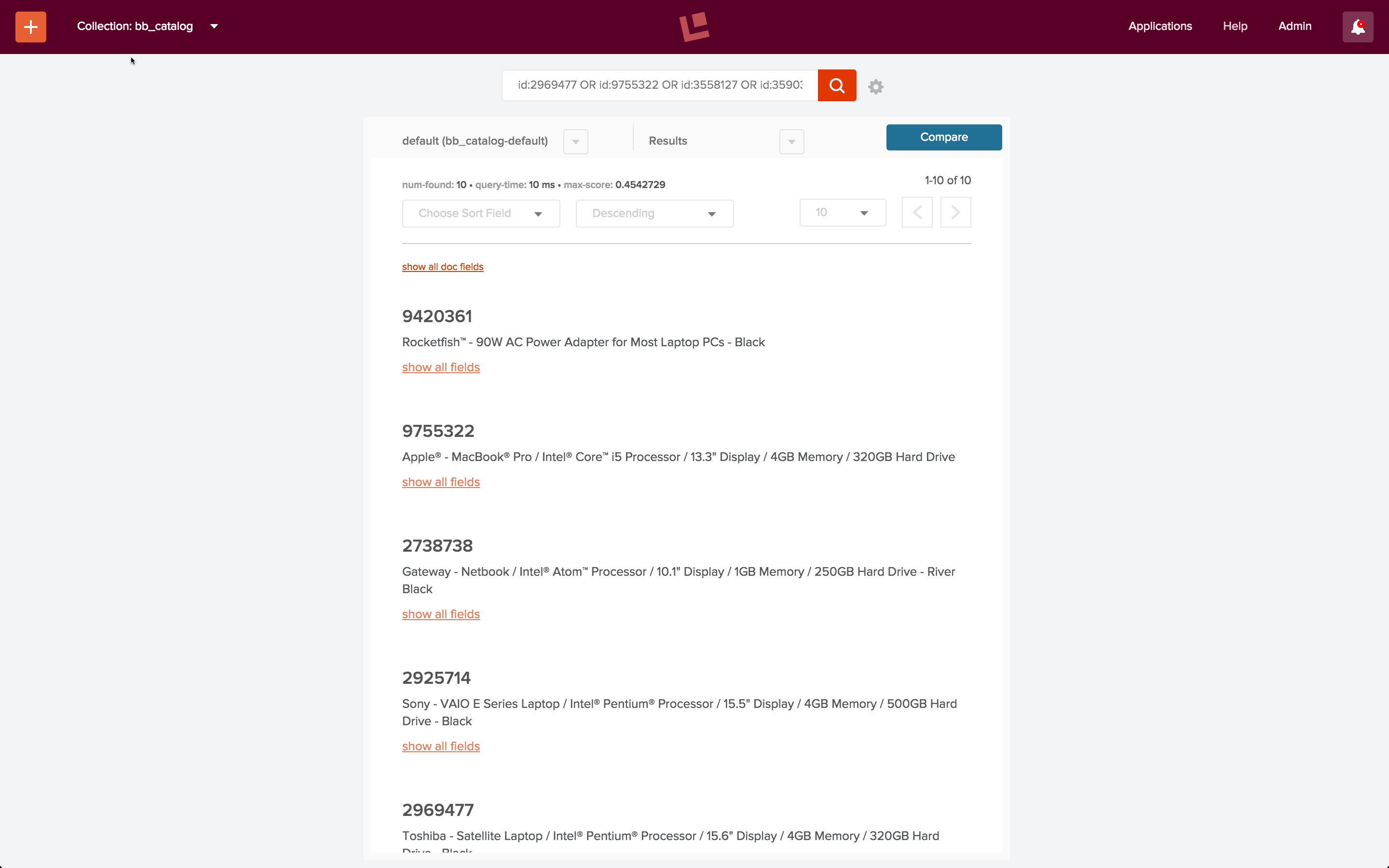
Mit aggregierten Signalen sehen wir sofort Verbesserungen. Ich kann Empfehlungen mit dem Endpunkt „itemsForQuery“ über einen curl-Befehl erhalten:
curl -u admin:password123 http://localhost:8764/api/apollo/recommend/bb_catalog/itemsForQuery?q=laptop
Dies ergibt die folgende Liste von IDs: [ 2969477, 9755322, 3558127, 3590335, 9420361, 2925714, 1853531, 3179912, 2738738, 3047444 ], von denen die meisten beliebte Laptops sind:
Wann Sie keine Signale verwenden sollten
Wenn der Textinhalt der Dokumente in Ihrer Sammlung genügend Informationen bietet, so dass die zurückgegebenen Dokumente für eine bestimmte Abfrage die relevantesten verfügbaren Dokumente sind, dann brauchen Sie keine Fusion-Signale. (Wenn es nicht kaputt ist, reparieren Sie es nicht.) Wenn die einzigen Informationen über Ihre Dokumente die Dokumente selbst sind, können Sie keine Signale verwenden. (Benutzen Sie keinen Hammer, wenn Sie keine Nägel haben.)
Fazit
Fusion bietet die Tools zum Erstellen, Verwalten und Pflegen von Signalen und Aggregationen. Es ist möglich, extrem anspruchsvolle Aggregationsfunktionen zu erstellen und aggregierte Signale auf viele verschiedene Arten zu verwenden. Es ist auch möglich, Signale auf einfache Weise zu verwenden, wie ich es in diesem Beitrag getan habe, mit schnellen und beeindruckenden Ergebnissen.
In den nächsten Beiträgen dieser Serie werden wir Ihnen dies zeigen:
- Wie Sie Abfrage-Pipelines schreiben, um diese Leistung für eine bessere Suche über Ihre Daten auf Ihre Weise zu nutzen.
- Wie Sie die Leistung von Apache Spark für eine hochskalierbare Signalverarbeitung nahezu in Echtzeit nutzen können.