Hyperloglog Tutorial: Kardinalitätsstatistiken in Solr 5.2
In Anlehnung an die Unterstützung von Perzentilen, die der Solr StatsComponent in Version 5.1 hinzugefügt wurde, wird Solr 5.2 die effiziente Kardinalität von Mengen mit Hilfe des HyperLogLog-Algorithmus hinzufügen.
Grundlegende Verwendung
Wie die meisten der bestehenden Optionen für stat-Komponenten kann die Kardinalität eines Feldes (oder von Funktionswerten) mit einer einfachen lokalen param-Option mit einem true Wert. Zum Beispiel…
$ curl 'http://localhost:8983/solr/techproducts/query?rows=0&q=*:*&stats=true&stats.field=%7B!count=true+cardinality=true%7Dmanu_id_s'
{
"responseHeader":{
"status":0,
"QTime":3,
"params":{
"stats.field":"{!count=true cardinality=true}manu_id_s",
"stats":"true",
"q":"*:*",
"rows":"0"}},
"response":{"numFound":32,"start":0,"docs":[]
},
"stats":{
"stats_fields":{
"manu_id_s":{
"count":18,
"cardinality":14}}}}
Hier sehen wir, dass in den Beispieldaten von techproduct die 32 (numFound) Dokumente insgesamt 18 (count) Werte im Feld manu_id_s enthalten – und davon sind 14 (cardinality) eindeutig.
Und natürlich kann diese Statistik, wie alle Statistiken, mit Pivot-Facetten kombiniert werden, um z. B. die Anzahl der einzelnen Hersteller pro Kategorie zu ermitteln…
$ curl 'http://localhost:8983/solr/techproducts/query?rows=0&q=*:*&facet=true&stats=true&facet.pivot=%7B!stats=s%7Dcat&stats.field=%7B!tag=s+cardinality=true%7Dmanu_id_s'
{
"responseHeader":{
"status":0,
"QTime":4,
"params":{
"facet":"true",
"stats.field":"{!tag=s cardinality=true}manu_id_s",
"stats":"true",
"q":"*:*",
"facet.pivot":"{!stats=s}cat",
"rows":"0"}},
"response":{"numFound":32,"start":0,"docs":[]
},
"facet_counts":{
"facet_queries":{},
"facet_fields":{},
"facet_dates":{},
"facet_ranges":{},
"facet_intervals":{},
"facet_heatmaps":{},
"facet_pivot":{
"cat":[{
"field":"cat",
"value":"electronics",
"count":12,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":8}}}},
{
"field":"cat",
"value":"currency",
"count":4,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":4}}}},
{
"field":"cat",
"value":"memory",
"count":3,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":1}}}},
{
"field":"cat",
"value":"connector",
"count":2,
"stats":{
"stats_fields":{
"manu_id_s":{
"cardinality":1}}}},
...
cardinality=true gegen countDistinct=true
Aufmerksame Leser werden sich fragen: „Hat Solr nicht schon immer Kardinalität unterstützt, indem es die stats.calcdistinct=true Option?“ Die Antwort auf diese Frage lautet: gewissermaßen.
Die Option calcdistinct wurde nie für andere als triviale Anwendungsfälle empfohlen, da sie eine sehr naive Implementierung der Berechnung der Kardinalität von Datensätzen verwendete, nämlich: Sie erstellte im Speicher (und gab an den Client zurück) einen vollständigen Datensatz aller distinctValues. Dies funktioniert gut für kleine Datensätze, aber wenn die Kardinalität zunimmt, wird es trivial, einen Server mit einem OutOfMemoryError bei nur einer Handvoll gleichzeitiger Benutzer zum Absturz zu bringen. Bei einer verteilten Suche ist das Verhalten sogar noch schlimmer (und viel langsamer), da all diese vollständigen Sätze auf jedem Shard über die Leitung zum koordinierenden Knoten gesendet werden müssen, um zusammengeführt zu werden.
Solr 5.2 verbessert die Situation geringfügig, indem es die Option calcdistinct=true in zwei Teile aufspaltet und den Clients erlaubt, countDistinct=true unabhängig von der Menge aller distinctValues=true anzufordern. Unter der Haube verrichtet Solr immer noch dieselbe Arbeit (und bei verteilten Anfragen tauschen die Knoten immer noch dieselbe Menge an Daten aus), aber wenn Sie nur nach countDistinct=true fragen, müssen die Clients nicht mehr die gesamte Menge aller Werte erhalten.
Die neue Option cardinality unterscheidet sich dadurch, dass sie den probabilistischen Algorithmus „HyperLogLog“ (HLL) verwendet, um die Kardinalität der Mengen in einer festen Speichermenge zu schätzen. Wikipedia erklärt die Details viel besser, als ich es könnte, aber die wichtigsten Punkte, die Solr-Benutzer wissen sollten, sind:
- Die RAM-Nutzung ist immer auf eine Obergrenze begrenzt
- Werte werden gehasht
- Für „kleine“ Mengen sollten die Implementierung und die Ergebnisse genau die gleichen sein wie bei
countDistinct=true(vorausgesetzt, es gibt keine Hash-Kollisionen). - Bei „größeren“ Mengen ist der Kompromiss zwischen „Genauigkeit“ und der Obergrenze des Arbeitsspeichers pro Anfrage einstellbar
In den Beispielen, die wir bisher gesehen haben, wurde cardinality=true als lokaler Parameter verwendet – dies ist eigentlich nur ein syntaktischer Zucker für cardinality=0.33. Sie können eine beliebige Zahl zwischen 0,0 und 1,0 (einschließlich) angeben, um den Kompromiss zwischen RAM und Genauigkeit zu bestimmen:
cardinality=0.0– „Verwenden Sie die minimale unterstützte Ram-Menge, um mir einen sehr groben Näherungswert zu geben“cardinality=1.0– „Verwenden Sie die maximale unterstützte Ram-Menge, um mir einen möglichst genauen Näherungswert zu liefern“
Intern werden diese Fließkommawerte zusammen mit einigen grundlegenden Heuristiken über den Solr-Feldtyp (d.h.: 32-Bit-Feldtypen wie int und float haben eine viel geringere maximal mögliche Kardinalität als Felder wie long, double, strings usw.) verwendet, um die Optionen „log2m“ und „regwidth“ der zugrunde liegenden java-hll -Implementierung abzustimmen. Fortgeschrittene Solr-Benutzer können explizite Werte für diese Optionen mit den Localparams hllLog2m und hllRegwidth angeben, siehe die
StatsComponent Dokumentation für weitere Details.
Genauigkeit versus Leistung: Vergleichstest
Um die Kompromisse zwischen der Verwendung des alten countDistinct Logik, und die neue HLL-basierte cardinality Option, habe ich einen einfachen Benchmark erstellt, um sie zu vergleichen.
Die Ersteinrichtung ist ziemlich einfach:
- Verwenden Sie
bin/solr -e cloud -noprompt, um einen 2-Knoten-Cluster einzurichten, der 1 Sammlung mit 2 Shards und 2 Replikaten enthält. - Erzeugt 10.000.000 zufällige Dokumente, die jeweils 2 Felder enthalten:
long_data_ls: Ein mehrwertiges numerisches Feld mit 3 zufälligen „langen“ Wertenstring_data_ss: Ein mehrwertiges Stringfeld, das die gleichen 3 Werte enthält (als Strings)
- Erzeugen Sie 500 zufällige Bereichsabfragen für das Feld „id“, so dass die erste Abfrage mit 1000 Dokumenten übereinstimmt und jede weitere Abfrage mit weiteren 1000 Dokumenten
Da wir für jedes Dokument 3 zufällige Werte in jedem Feld generiert haben, erwarten wir, dass die Kardinalitätsergebnisse jeder Abfrage ~3x so hoch sind wie die Anzahl der Dokumente, die mit dieser Abfrage übereinstimmen. (Geringfügige Abweichungen sind möglich, wenn mehrere Dokumente zufällig die gleichen zufällig generierten Feldwerte enthalten).
Mit diesem vorgefertigten Index und diesem Satz von vorgenerierten Zufallsabfragen können wir dann den Abfragesatz
immer wieder mit verschiedenen Optionen zur Berechnung der Kardinalität ausführen. Konkret haben wir für unsere beiden Testfelder die folgenden stats.field Varianten getestet:
{!key=k countDistinct=true}{!key=k cardinality=true}(dasselbe wie 0,33){!key=k cardinality=0.5}{!key=k cardinality=0.7}
Für jedes Feld und jede stats.field wurden 3 Durchläufe des vollständigen Abfragesatzes sequentiell mit einem einzigen Client-Thread ausgeführt und sowohl die resultierende Kardinalität als auch der Mittelwert+stddev der Antwortzeit (wie vom Client beobachtet) aufgezeichnet.
Test Ergebnisse
Ein Blick auf die Diagramme der von den einzelnen Ansätzen gelieferten Rohdaten ist nicht sehr hilfreich. Im Grunde sieht es wie eine gerade Linie mit einer Steigung von 1 aus – was gut ist. Eine gerade Linie bedeutet, dass wir die Antworten erhalten haben, die wir erwarten.
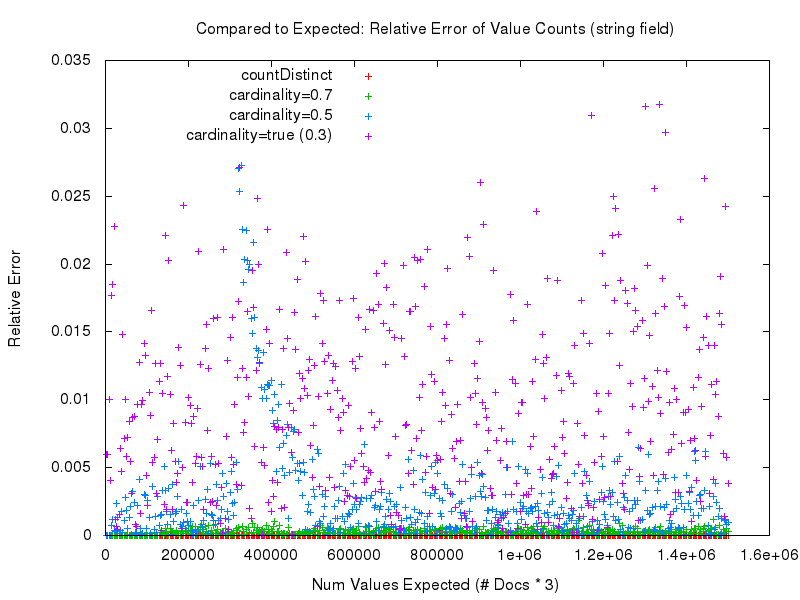
Aber der Teufel steckt im Detail. Was wir uns wirklich ansehen müssen, um die gemessene Genauigkeit der verschiedenen Ansätze sinnvoll zu vergleichen, ist der„relative Fehler„. Wie wir in diesem Diagramm unten sehen können, werden die genauesten Ergebnisse eindeutig mit countDistinct=true erzielt. Danach folgt cardinality=0.7, und die gemessene Genauigkeit verschlechtert sich, je niedriger der Abstimmungswert für die Option cardinality wird.
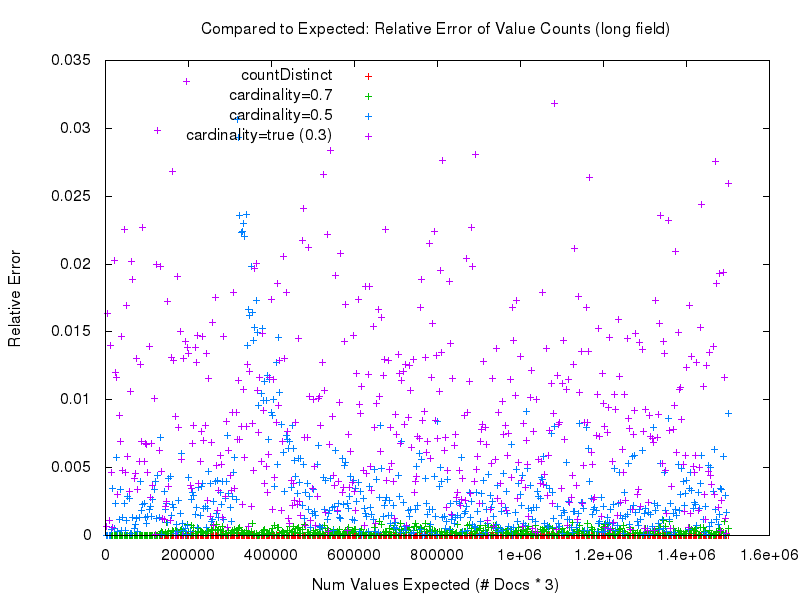
Wenn Sie sich diese Ergebnisse ansehen, fragen Sie sich vielleicht: Warum sollten Sie die neue Option cardinality überhaupt nutzen?
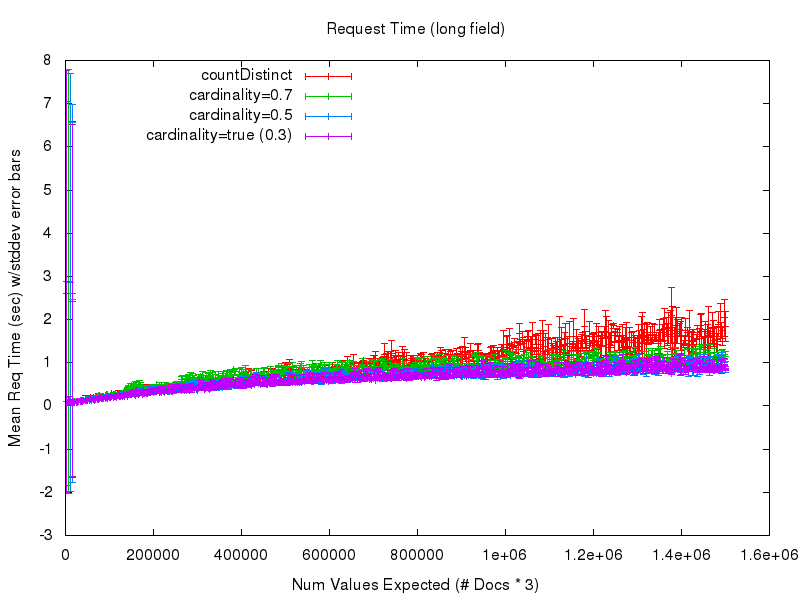
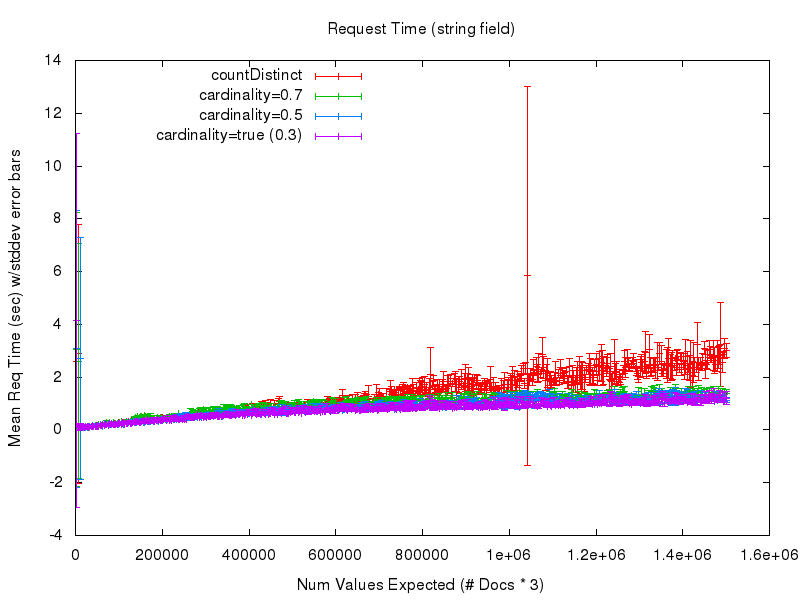
Um diese Frage zu beantworten, sehen wir uns die nächsten 2 Diagramme an. Das erste zeigt die durchschnittliche Anfragezeit (gemessen vom Abfrageclient), wenn die Anzahl der erwarteten Werte in der Menge wächst. In diesem Diagramm ist bei den niedrigen Werten viel Rauschen zu sehen, das auf schlecht aufwärmende Abfragen meinerseits im Testprozess zurückzuführen ist – daher zeigt das zweite Diagramm eine beschnittene Ansicht derselben Daten
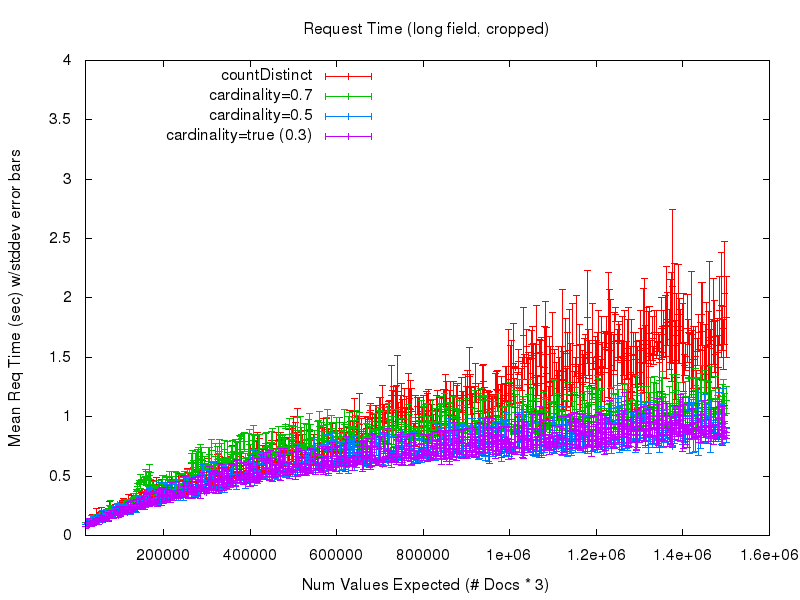
Hier beginnen wir, einen offensichtlichen Vorteil bei der Verwendung der Option cardinality zu erkennen. Während die Antwortzeiten von countDistinct weiter ansteigen und immer unvorhersehbarer werden – vor allem wegen der umfangreichen Garbage Collection – gleichen sich die Kosten (in Form von Verarbeitungszeit) bei Verwendung der Option cardinality praktisch aus. Es wird also ziemlich deutlich, dass Sie, wenn Sie eine kleine Annäherung in Ihrer Kardinalitätsstatistik akzeptieren können, eine Menge Vertrauen und Vorhersagbarkeit im Verhalten Ihrer Abfragen gewinnen können. Und wenn Sie den Parameter cardinality anpassen, können Sie die Genauigkeit gegen die Menge des bei der Abfrage verwendeten Arbeitsspeichers eintauschen, wobei die Auswirkungen auf die Antwortzeit relativ gering sind.
Wenn wir uns die Ergebnisse für das String-Feld ansehen, können wir feststellen, dass die Genauigkeit praktisch identisch ist mit der der numerischen Felder und die Anfragezeitleistung der Option cardinality mit der der numerischen Felder übereinstimmt (aufgrund des Hash-Verfahrens), während die Anfragezeitleistung von countDistinct völlig zusammenbricht – obwohl es sich um relativ kleine String-Werte handelt….
{kind=link}
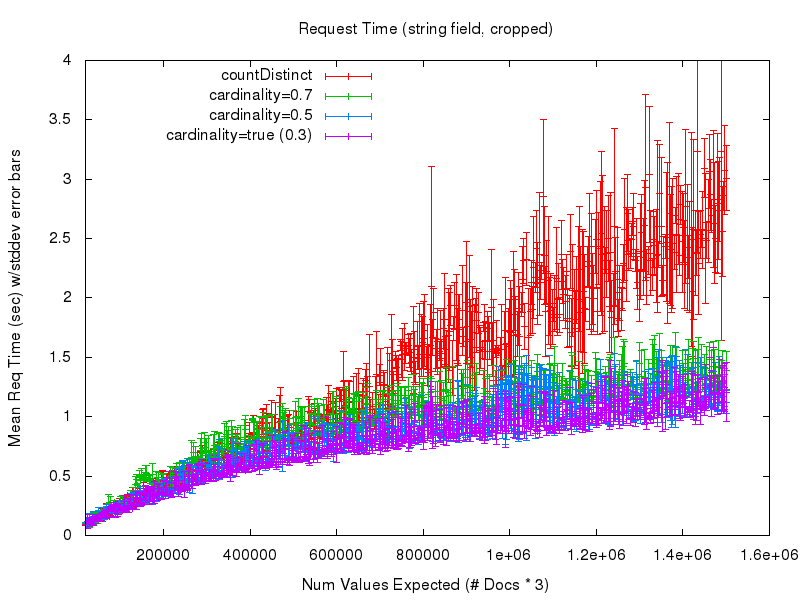
Ich würde niemandem empfehlen, countDistinct mit nicht trivialen Stringfeldern zu verwenden.
Nächste Schritte
Es gibt immer noch einige Dinge an der HLL-Implementierung, die mit ein paar weiteren Drehknöpfen/Einstellern für die Anforderungszeit „benutzerspezifisch“ eingestellt werden könnten, sobald die Benutzer die Möglichkeit haben, diese neue Funktion auszuprobieren und Feedback zu geben – aber ich denke, der größte Knaller für das Geld ist das Hinzufügen Unterstützung von Hashing für die Indexzeit – was bei der Beschleunigung der Antwortzeiten von Kardinalitätsberechnungen sehr hilfreich sein sollte, indem Sie den klassischen Kompromiss eingehen: Machen Sie mehr Arbeit zur Indexzeit und machen Sie Ihren Index auf der Festplatte etwas größer, um CPU-Zyklen zur Abfragezeit zu sparen und die Antwortzeit der Abfrage zu reduzieren.