Integration von Storm und Solr
In diesem Beitrag stelle ich ein neues Open-Source-Projekt von Lucidworks vor, das die Integration von Solr und Storm ermöglicht. Dabei gehe ich insbesondere auf Funktionen wie Micro-Buffering, Data Mapping und das Senden von benutzerdefinierten JSON-Dokumenten von Storm an Solr ein. Ich gehe davon aus, dass Sie ein grundlegendes Verständnis der Funktionsweise von Storm haben. Wenn Sie jedoch eine kurze Auffrischung benötigen, lesen Sie bitte die Dokumentation zu Storm-Konzepten.
Während Sie diesen Beitrag lesen, wird es hilfreich sein, den Quellcode des Projekts auf Ihrem lokalen Rechner zu haben. Nachdem Sie https://github.com/Lucidworks/storm-solr geklont haben , führen Sie einfach aus: mvn clean package. Dadurch wird das vereinheitlichte Paket storm-solr-1.0.jar im Verzeichnis target/ für das Projekt erstellt.
Das hier besprochene Projekt begann mit einem einfachen Bolt für die Indizierung von Dokumenten in Solr. Mein erster Versuch, einen Solr-Bolzen zu erstellen, war recht einfach, aber dann tauchten eine Reihe von Fragen auf, die meinen einfachen Bolzen nicht ganz so einfach machten. Zum Beispiel, wie kann ich …
- Trenne ich die Geschäftslogik meiner Anwendung vom Storm-Boilerplate-Code?
- Unit-Test der Anwendungslogik in meinen Bolzen und Ausläufen?
- Eine Topologie lokal ausführen, während Sie entwickeln?
- Meine Solr-Schraube so konfigurieren, dass sie umgebungsspezifische Einstellungen wie den von SolrCloud benötigten ZooKeeper-Verbindungsstring angibt?
- Meine Topologie in etwas verpacken, das in einem Storm-Cluster eingesetzt werden kann?
- Die Leistung meiner Komponenten während der Laufzeit messen?
- Integration mit anderen Diensten und Datenbanken beim Aufbau einer realen Topologie?
- Tupel in meiner Topologie in einem Format abbilden, das Solr verarbeiten kann?
Dies ist nur ein kleines Beispiel für die Art von Fragen, die beim Aufbau einer leistungsstarken Streaming-Anwendung mit Storm auftreten. Mir wurde schnell klar, dass ich mehr als nur einen Solr-Bolzen benötigte. Daher entwickelte sich das Projekt zu einem Toolset, das die Integration von Storm und Solr erleichtert und alle oben aufgeworfenen Fragen beantwortet.
Ich erspare Ihnen die kleinsten Details des Frameworks, das die Integration von Solr mit Storm unterstützt. Wenn Sie daran interessiert sind, finden Sie in der README des Projekts weitere Einzelheiten darüber, wie das Framework entwickelt wurde.
Zusammenstellen und Ausführen einer Sturmtopologie
Lassen Sie uns zunächst verstehen, wie Sie eine Topologie in Storm betreiben. Es gibt zwei grundlegende Modi für die Ausführung einer Storm-Topologie: den lokalen und den Cluster-Modus. Der lokale Modus eignet sich hervorragend, um Ihre Topologie lokal zu testen, bevor Sie sie an einen entfernten Storm-Cluster (z.B. Staging oder Produktion) weitergeben. Zunächst müssen Sie Ihren Code und alle seine Abhängigkeiten in eine einheitliche JAR-Datei mit einer Hauptklasse kompilieren und verpacken, die Ihre Topologie ausführt.
Für dieses Projekt verwende ich das Maven Shade-Plugin, um das einheitliche JAR mit Abhängigkeiten zu erstellen. Der Vorteil des Shade-Plugins ist, dass es Klassen auf Bytecode-Ebene in verschiedene Pakete verschieben kann, um Abhängigkeitskonflikte zu vermeiden. Dies ist sehr nützlich, wenn Ihre Anwendung von Bibliotheken von Drittanbietern abhängt, die mit Klassen auf dem Storm-Klassenpfad in Konflikt stehen. Sie können in der Datei pom.xml des Projekts nachlesen, wie ich das Shade-Plugin verwende. Für den Moment genügt es zu sagen, dass das Projekt es sehr einfach macht, ein Storm JAR für Ihre Anwendung zu erstellen. Sobald Sie eine einheitliche JAR-Datei (storm-solr-1.0.jar) haben, können Sie Ihre Topologie in Storm ausführen.
Das Projekt enthält eine Hauptklasse namens com.lucidworks.storm.StreamingApp, mit der Sie eine Topologie lokal oder in einem entfernten Storm-Cluster ausführen können. Im Einzelnen bietet die StreamingApp Folgendes:
- Trennt den Prozess der Definition einer Storm-Topologie von dem Prozess der Ausführung einer Storm-Topologie in verschiedenen Umgebungen. So können Sie sich auf die Definition einer Topologie für Ihre spezifischen Anforderungen konzentrieren.
- Bietet einen sauberen Mechanismus zum Trennen von umgebungsspezifischen Konfigurationseinstellungen.
- Minimiert doppelten Standardcode bei der Entwicklung mehrerer Topologien und bietet Ihnen einen gemeinsamen Ort zum Einfügen wiederverwendbarer Logik, die Sie für alle Ihre Topologien benötigen.
Um StreamingApp zu verwenden, müssen Sie lediglich die Schnittstelle StormTopologyFactory implementieren, die die Spouts und Bolts in Ihrer Topologie definiert:
public interface StormTopologyFactory {
String getName();
StormTopology build(StreamingApp app) throws Exception;
}
Schauen wir uns ein einfaches Beispiel für eine StormTopologyFactory-Implementierung an, die eine Topologie für die Indizierung von Tweets in Solr definiert:
class TwitterToSolrTopology implements StormTopologyFactory {
static final Fields spoutFields = new Fields("id", "tweet")
String getName() { return "twitter-to-solr" }
StormTopology build(StreamingApp app) throws Exception {
// setup spout and bolts for accessing Spring-managed POJOs at runtime
SpringSpout twitterSpout =
new SpringSpout("twitterDataProvider", spoutFields);
SpringBolt solrBolt =
new SpringBolt("solrBoltAction", app.tickRate("solrBolt"));
// wire up the topology to read tweets and send to Solr
TopologyBuilder builder = new TopologyBuilder()
builder.setSpout("twitterSpout", twitterSpout,
app.parallelism("twitterSpout"))
builder.setBolt("solrBolt", solrBolt, app.parallelism("solrBolt"))
.shuffleGrouping("twitterSpout")
return builder.createTopology()
}
}
In dieser Auflistung sollten Ihnen ein paar Dinge auffallen. Erstens: Es gibt keine Befehlszeilenanalyse, keine umgebungsspezifische Konfigurationsbehandlung und keinen Code, der mit der Ausführung dieser Topologie zusammenhängt. Alles, was Sie hier sehen, ist Code, der eine StormTopology definiert; StreamingApp erledigt all die langweiligen Dinge für Sie. Zweitens ist der Code recht einfach zu verstehen, weil er nur eine Sache tut. Und schließlich ist diese Klasse in Groovy statt in Java geschrieben, was dazu beiträgt, die Dinge schön und ordentlich zu halten, und ich finde, Groovy macht mehr Spaß beim Schreiben. Wenn Sie Groovy nicht verwenden möchten, können Sie natürlich auch Java verwenden, da das Framework beides nahtlos unterstützt.
Das folgende Diagramm stellt die TwitterToSolrTopologie dar. Ein wichtiger Aspekt der Lösung ist die Verwendung des Spring-Frameworks für die Verwaltung von Beans, die anwendungsspezifische Logik in Ihrer Topologie implementieren, und die Arbeit mit Storm-Boilerplates wird wiederverwendbaren Komponenten überlassen: SpringSpout und SpringBolt.
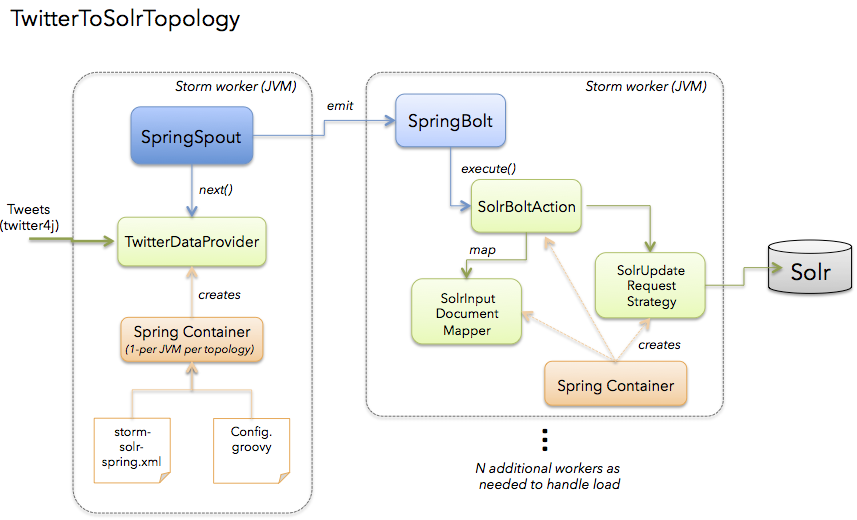
Wir werden uns in Kürze mit den spezifischen Details der Implementierung befassen, aber sehen wir uns zunächst an, wie Sie TwitterToSolrTopology mit dem StreamingApp-Framework ausführen. Für den lokalen Modus würden Sie dies tun:
java -classpath $STORM_HOME/lib/*:target/storm-solr-1.0.jar com.lucidworks.storm.StreamingApp example.twitter.TwitterToSolrTopology -localRunSecs 90
Mit dem obigen Befehl wird TwitterToSolrTopology 90 Sekunden lang auf Ihrem lokalen Arbeitsplatzrechner ausgeführt und dann heruntergefahren. Die gesamte Einrichtungsarbeit wird von der Klasse StreamingApp übernommen. Um die Daten an einen entfernten Cluster zu übermitteln, müssen Sie Folgendes tun:
$STORM_HOME/bin/storm jar target/storm-solr-1.0.jar com.lucidworks.storm.StreamingApp example.twitter.TwitterToSolrTopology -env staging
Beachten Sie, dass ich das Flag -env verwende, um anzugeben, dass ich in meiner Staging-Umgebung arbeite. Es ist üblich, eine Storm-Topologie in verschiedenen Umgebungen auszuführen, z. B. in der Test-, der Staging- und der Produktionsumgebung, daher ist dies in das StreamingApp-Framework integriert.
Bisher habe ich Ihnen gezeigt, wie Sie eine Topologie definieren und wie Sie sie ausführen. Lassen Sie uns nun in die Details gehen, wie man Komponenten in einer Topologie implementiert. Sehen wir uns insbesondere an, wie man einen Bolt erstellt, der Daten in Solr indiziert, da dies viele der wichtigsten Funktionen des Frameworks veranschaulicht.
SpringBolt
In Storm führt ein Bolt eine Operation mit einem Tupel durch und gibt optional Tupel in den Stream aus. In der obigen Beispiel-Twitter-Topologiedefinition sehen wir diesen Code:
SpringBolt solrBolt = new SpringBolt("solrBoltAction", app.tickRate("solrBolt"));
Dadurch wird eine Instanz von SpringBolt erstellt, die die Nachrichtenverarbeitung an eine von Spring verwaltete Bean mit der ID „solrBoltAction“ delegiert.
Der Hauptvorteil von SpringBolt besteht darin, dass wir damit Storm-spezifische Logik und Boilerplate-Code von der Anwendungslogik trennen können. Die Klasse com.lucidworks.storm.spring.SpringBolt ermöglicht es Ihnen, Ihre Bolt-Logik als einfaches, von Spring verwaltetes POJO (Plain Old Java Object) zu implementieren. Um SpringBolt zu nutzen, müssen Sie lediglich die Schnittstelle StreamingDataAction implementieren:
public interface StreamingDataAction {
SpringBolt.ExecuteResult execute(Tuple input, OutputCollector collector);
}
Zur Laufzeit erstellt Storm eine oder mehrere Instanzen von SpringBolt pro JVM. Die Anzahl der erstellten Instanzen hängt von dem für den Bolt konfigurierten Hinweis auf Parallelität ab. Im Twitter-Beispiel haben wir einfach die Anzahl der Aufgaben für den Solr-Bolt aus unserer Konfiguration übernommen:
// wire up the topology to read tweets and send to Solr
...
builder.setBolt("solrBolt", solrBolt, app.parallelism("solrBolt"))
...
Der SpringBolt benötigt einen Verweis auf die solrBoltAction-Bean aus dem Spring ApplicationContext. Die solrBoltAction-Bean ist in resources/storm-solr-spring.xml definiert als:
<bean id="solrBoltAction"
class="com.lucidworks.storm.solr.SolrBoltAction"
scope="prototype">
<property name="solrInputDocumentMapper" ref="solrInputDocumentMapper"/>
<property name="maxBufferSize" value="${maxBufferSize}"/>
<property name="bufferTimeoutMs" value="${bufferTimeoutMs}"/>
</bean>
Bei dieser Bean-Definition gibt es einige interessante Aspekte zu beachten. Erstens ist die Bean mit Prototyp-Scope definiert, was bedeutet, dass Spring für jede SpringBolt-Instanz, die Storm zur Laufzeit erzeugt, eine neue Instanz erstellt. Das ist wichtig, denn es bedeutet, dass nur jeweils ein Thread auf Ihre Bean-Instanz zugreift, so dass Sie sich keine Gedanken über Thread-Sicherheitsprobleme machen müssen. Beachten Sie auch, dass die Eigenschaften maxBufferSize und bufferTimeoutMs mit der dynamischen Variablenauflösungssyntax von Spring gesetzt werden, z.B. ${maxBufferSize}. Diese Eigenschaften werden während der Bean-Erstellung aus einer Konfigurationsdatei namens resources/Config.groovy aufgelöst.
Wenn SpringBolt eine Referenz auf die Bean solrBoltAction benötigt, muss es zunächst den Spring ApplicationContext abrufen. Die Klasse StreamingApp ist für das Bootstrapping des Spring ApplicationContext mit storm-solr-spring.xml verantwortlich. StreamingApp stellt sicher, dass pro JVM-Instanz und Topologie nur ein Spring-Kontext initialisiert wird, da mehrere Topologien in derselben JVM ausgeführt werden können.
Wenn Sie sich Sorgen machen, dass der Spring-Container zu schwerfällig ist, können Sie beruhigt sein: Es wird nur ein Container pro JVM und Topologie initialisiert und Bolts und Spouts sind langlebige Objekte, die von Storm nur einmal pro Aufgabe initialisiert werden müssen. Einfach ausgedrückt: Der Overhead von Spring ist ziemlich minimal, insbesondere bei lang laufenden Streaming-Anwendungen.
Das Framework bietet auch einen SpringSpout, mit dem Sie einen Datenanbieter als einfaches von Spring verwaltetes POJO implementieren können. Ich verweise Sie auf den Quellcode, um mehr über SpringSpout zu erfahren, aber im Grunde folgt es denselben Designmustern wie SpringBolt.
Umgebungsspezifische Konfiguration
Ich habe in den letzten Jahren mehrere Storm-Produktionstopologien implementiert und ein Muster, das immer wieder auftaucht, ist die Notwendigkeit, Konfigurationseinstellungen für verschiedene Umgebungen zu verwalten. Zum Beispiel müssen wir für Staging und Produktion in einen anderen SolrCloud-Cluster indexieren. Um diesem Bedarf gerecht zu werden, können Sie mit dem Spring-gesteuerten Framework alle umgebungsspezifischen Konfigurationseigenschaften in derselben Konfigurationsdatei speichern, siehe resources/Config.groovy.
Machen Sie sich keine Sorgen, wenn Sie Groovy nicht kennen. Die Syntax der Datei Config.groovy ist sehr einfach zu verstehen und ermöglicht es Ihnen, die Eigenschaften für die folgenden Umgebungen sauber zu trennen: test, dev, staging und production. Vereinfacht gesagt, können Sie mit diesem Ansatz die Topologie in mehreren Umgebungen ausführen, indem Sie einen einfachen Befehlszeilenschalter verwenden, um die Umgebungseinstellungen festzulegen, die angewendet werden sollen -env.
Metriken
Storm bietet High-Level-Metriken für Bolts und Spouts, aber wenn Sie mehr Einblick in das Innenleben Ihrer anwendungsspezifischen Logik benötigen, dann verwenden Sie üblicherweise die Java-Metrikenbibliothek, siehe: https://dropwizard.github.io/metrics/3.1.0/. Glücklicherweise gibt es Open-Source-Optionen für die Integration von Metriken in Spring, siehe: https://github.com/ryantenney/metrics-spring.
Die Spring-Kontextkonfigurationsdatei resources/storm-solr-spring.xml wird mit der gesamten Infrastruktur vorkonfiguriert, die Sie benötigen, um Metriken in Ihre Bean-Implementierungen zu integrieren.
Wenn Sie Ihre StreamingDataAction (bolt) oder Ihren StreamingDataProvider (spout) implementieren, können Sie Spring veranlassen, automatisch Metrikobjekte zu verdrahten, indem Sie die @Metric-Annotation verwenden, wenn Sie metrikbezogene Membervariablen deklarieren. Die Klasse SolrBoltAction verwendet zum Beispiel einen Timer, um zu verfolgen, wie lange es dauert, Batches an Solr zu senden.
@Metric public Timer sendBatchToSolr;
Die Klasse SolrBoltAction bietet mehrere Beispiele für die Verwendung von Metriken in Ihren Bean-Implementierungen.
An dieser Stelle sollten Sie ein grundlegendes Verständnis der wichtigsten Funktionen des Frameworks haben. Wenden wir uns nun einigen Solr-spezifischen Funktionen zu.
Mikro-Pufferung und Ack’ing Eingabe-Tupel
Es ist möglich, dass Tausende von Dokumenten pro Sekunde in jeden Solr-Bolt fließen. Um zu vermeiden, dass zu viele Anfragen an Solr gesendet werden und die Topologie zu sehr blockiert wird, verwendet der Bolt einen internen Puffer, um Dokumente in kleinen Stapeln an Solr zu senden. Dies trägt dazu bei, die Anzahl der Netzwerkumläufe zwischen Ihrem Bolt und Solr zu reduzieren. Der Bolt unterstützt eine Einstellung für die maximale Puffergröße, mit der Sie festlegen können, wann der Puffer geleert werden soll. Die Standardeinstellung ist 100.
Die Pufferung wirft in einer Streaming-Topologie zwei grundlegende Probleme auf. Erstens verwenden Sie Storm wahrscheinlich, um eine Datenverarbeitungsanwendung nahezu in Echtzeit zu betreiben. Wir wollen also nicht, dass Dokumente zu lange in Solr verzögert werden. Um dies zu unterstützen, unterstützt der Bolt eine Puffer-Timeout-Einstellung, die angibt, wann ein Puffer geleert werden sollte, um sicherzustellen, dass die Dokumente rechtzeitig in Solr eingehen. Folglich wird der Puffer geleert, wenn entweder die Größenschwelle oder das Zeitlimit erreicht ist.
Es gibt einen subtilen Nebeneffekt, der normalerweise einen Hintergrund-Thread erfordern würde, um den Puffer zu leeren, wenn es eine Verzögerung bei den Nachrichten gibt, die von vorgelagerten Komponenten an den Bolt gesendet werden. Glücklicherweise bietet Storm einen einfachen Mechanismus, der es Ihrem Bolt ermöglicht, in regelmäßigen Abständen einen speziellen Typ von Tupel zu empfangen, ein so genanntes TickTuple. Jedes Mal, wenn die SolrBoltAction-Bean ein TickTuple empfängt, prüft sie, ob der Puffer geleert werden muss. Dadurch wird vermieden, dass Dokumente zu lange aufbewahrt werden, und ein Hintergrund-Thread zur Überwachung des Puffers wird überflüssig.
Feld Kartierung
Die SolrBoltAction Bean kümmert sich um das effiziente Senden von Dokumenten an SolrCloud, aber sie funktioniert nur mit SolrInputDocument Objekten aus SolrJ. Es ist unwahrscheinlich, dass Ihre Storm-Topologie nativ mit SolrInputDocument-Objekten arbeitet. Daher delegiert die SolrBoltAction-Bean das Mapping von Eingabe-Tupeln auf SolrInputDocument-Objekte an eine von Spring verwaltete Bean, die die Schnittstelle com.lucidworks.storm.solr.SolrInputDocumentMapper implementiert. Dies passt gut zu unserem Design-Ansatz, bei dem es darum geht, die Anliegen in unserer Topologie zu trennen.
Die im Projekt bereitgestellte Standardimplementierung (DefaultSolrInputDocumentMapper) verwendet Java-Reflection, um Daten aus einem Java-Objekt zu lesen und die Felder des SolrInputDocuments zu füllen. Im Twitter-Beispiel verwendet die Standardimplementierung Java-Reflection, um Daten aus einem Twitter4J-Statusobjekt zu lesen, um dynamische Felder in einer SolrInputDocument-Instanz zu füllen.
Es sollte jedoch klar sein, dass Sie Ihre eigene SolrInputDocumentMapper-Implementierung mit Spring in die Bolt Bean einfügen können, wenn die Standardimplementierung Ihren Anforderungen nicht genügt.
JSON
Ab Solr 5 können Sie beliebige JSON-Dokumente an Solr senden und die Dokumente für die Indizierung parsen lassen. Weitere Informationen über diese coole Funktion in Solr finden Sie unter: https://lucidworks.com/post/indexing-custom-json-data/
Wenn Sie beliebige JSON-Objekte an Solr senden und die Dokumente während des JSON-Parsings indizieren lassen möchten, müssen Sie die Bean solrJsonBoltAction anstelle von solrBoltAction verwenden. Für unser Twitter-Beispiel könnten Sie die solrJsonBoltAction-Bean wie folgt definieren:
<bean id="solrJsonBoltAction"
class="com.lucidworks.storm.solr.SolrJsonBoltAction"
scope="prototype">
<property name="split" value="/"/>
<property name="fieldMappings">
<list>
<value>$FQN:/**</value>
</list>
</property>
</bean>
Lucidworks Fusion
Wenn Sie Lucidworks Fusion verwenden (und das sollten Sie), können Sie die Dokumente nicht direkt an Solr senden, sondern mit der Klasse FusionBoltAction an eine Fusion-Indizierungspipeline. FusionBoltAction sendet JSON-Dokumente an den Fusion-Proxy, der Ihnen Sicherheit und die volle Leistungsfähigkeit der Fusion-Pipelines für die Erzeugung von Solr-Dokumenten bietet.