Intelligentere Bildsuche in Fusion mit Googles Vision API
Nach fünf Tagen in Mexiko, in denen Sie mit Ihren Freunden an den sonnigen, abgelegenen Point Breaks auf der Pazifikseite von Baja gesurft sind, sind Sie auf dem Rückweg nach Hause und schielen auf eine übermäßig dichte Fotogalerie auf Ihrem Handy (oder schlimmer noch, Sie wühlen sich durch eine Sammlung von Dateien in Ihrem DCIM-Ordner mit Namen wie DSC10000.JPG) und versuchen, das eine Foto von dem klassischen 1948er Woodie Station Wagon mit dem einflossigen Surfbrett auf dem Dachträger zu finden.

Zugegeben, auch wenn Sie kein Surfer oder Autoliebhaber sind, gibt es bessere Argumente für eine intelligente Bildersuche, z.B. die allgegenwärtige Suche nach „blauen Wildlederschuhen“ auf Ihrer Lieblings-Commerce-Website, in sozialen Netzwerken und bei Anwendungen zur Gesichtserkennung, um nur einige zu nennen. Unternehmen wie Google, Facebook und Pinterest haben viel in die Bilderkennung und -klassifizierung mit Hilfe von künstlicher Intelligenz und Deep-Learning-Technologien investiert, und die Benutzer, die sich an diese Funktionalität gewöhnt haben, erwarten nun dasselbe Verhalten in ihren Suchanwendungen für Unternehmen.
Lucidworks Fusion kann Bilder und andere unstrukturierte Dokumentformate wie HTML, PDF, Microsoft Office Dokumente, OpenOffice, RTF, Audio und Video indizieren. Zu diesem Zweck verwendet Fusion den Apache Tika-Parser, um diese Dateien zu verarbeiten. Tika ist ein sehr vielseitiger Parser, der umfassende Metadaten zu Bilddateien liefert, z.B. Abmessungen, Auflösung, Farbpalette, Ausrichtung, Kompressionsrate und sogar Marke und Modell der Kamera und des Objektivs, von dem das Foto stammt, wenn diese Informationen von der Bildbearbeitungssoftware hinzugefügt werden. Allerdings sind solche Metadaten auf niedriger Ebene nicht nützlich genug, wenn Sie nach einem „roten Auto mit Weißwandreifen“ suchen…
Geben Sie die Google Cloud Vision API ein
Die Google Cloud Vision API ist ein REST-Dienst, der es Entwicklern ermöglicht, den Inhalt eines Bildes einfach zu verstehen, während die zugrunde liegenden Modelle für maschinelles Lernen vollständig abstrahiert werden. Sie klassifiziert Bilder schnell in Kategorien (z.B. „Surfbrett“, „Auto“, „Strand“, „Urlaub“), erkennt einzelne Objekte und Gesichter in Bildern, extrahiert gedruckte Wörter in Bildern und kann sogar anstößige Inhalte über die Stimmungsanalyse von Bildern mäßigen. Wenn die GCV API verwendet wird, um die Bildanalysefunktionen von Fusion Server zu erweitern, können die kombinierten Metadaten von Fusion AppStudio verwendet werden, um eine anspruchsvolle Bildsuche zu ermöglichen.
GCV aus Fusion verwenden
Um die GCV API-Funktionalität in Ihre Suchanwendung zu integrieren, folgen Sie diesen drei einfachen Schritten:
- Fügen Sie eine Tika Parser-Stufe zur Index-Pipeline hinzu. Stellen Sie sicher, dass die Optionen Bilder einbeziehen und Originaldokumentinhalt (Rohbytes) hinzufügen aktiviert sind und dass die Option Zusammengesetzte Dokumente glätten nicht aktiviert ist.
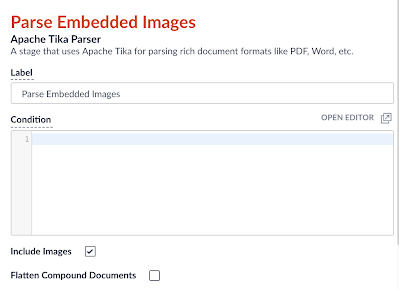
Abbildung 2: Tika Parser - Fügen Sie eine JavaScript-Phase zu Ihrer Fusion Index Pipeline hinzu. Der folgende Codeschnipsel konvertiert das Binärformat, in dem Tika das Bild speichert, in eine base64-kodierte Zeichenkette:
function (doc) { if (null != doc.getId()) { var ByteArrayInputStream = java.io.ByteArrayInputStream; var ByteArrayOutputStream = java.io.ByteArrayOutputStream; var DatatypeConverter = javax.xml.bind.DatatypeConverter; var raw = doc.getFirstFieldValue("_raw_content_"); if (null != raw) { var bais = new ByteArrayInputStream(raw); if (null != bais) { var bytes; var imports = new JavaImporter( org.apache.commons.io.IOUtils, org.apache.http.client); with(imports) { var baos = new ByteArrayOutputStream(); IOUtils.copy(bais, baos); bytes = baos.toByteArray(); var base64Input = DatatypeConverter.printBase64Binary(bytes); doc.setField("base64image_t", base64Input); } } } } return doc; }Hinweis: Das Skript verwendet die Klasse javax.xml.bind.DatatypeConverter. Um diese Klasse zur Laufzeit zu laden, müssen Sie die JAXB-Bibliothek zum Klassenpfad des Konnektors hinzufügen und den Konnektor-Classic-Prozess neu starten, wie folgt:
cp $FUSION_HOME/apps/spark/lib/jaxb-api-2.2.2.jar $FUSION_HOME/apps/libs/ ./bin/connectors-classic stop ./bin/connectors-classic start
- Fügen Sie eine REST-Abfrage zu Ihrer Fusion Index Pipeline hinzu. Konfigurieren Sie die REST-Abfrage wie in den folgenden Abbildungen gezeigt:
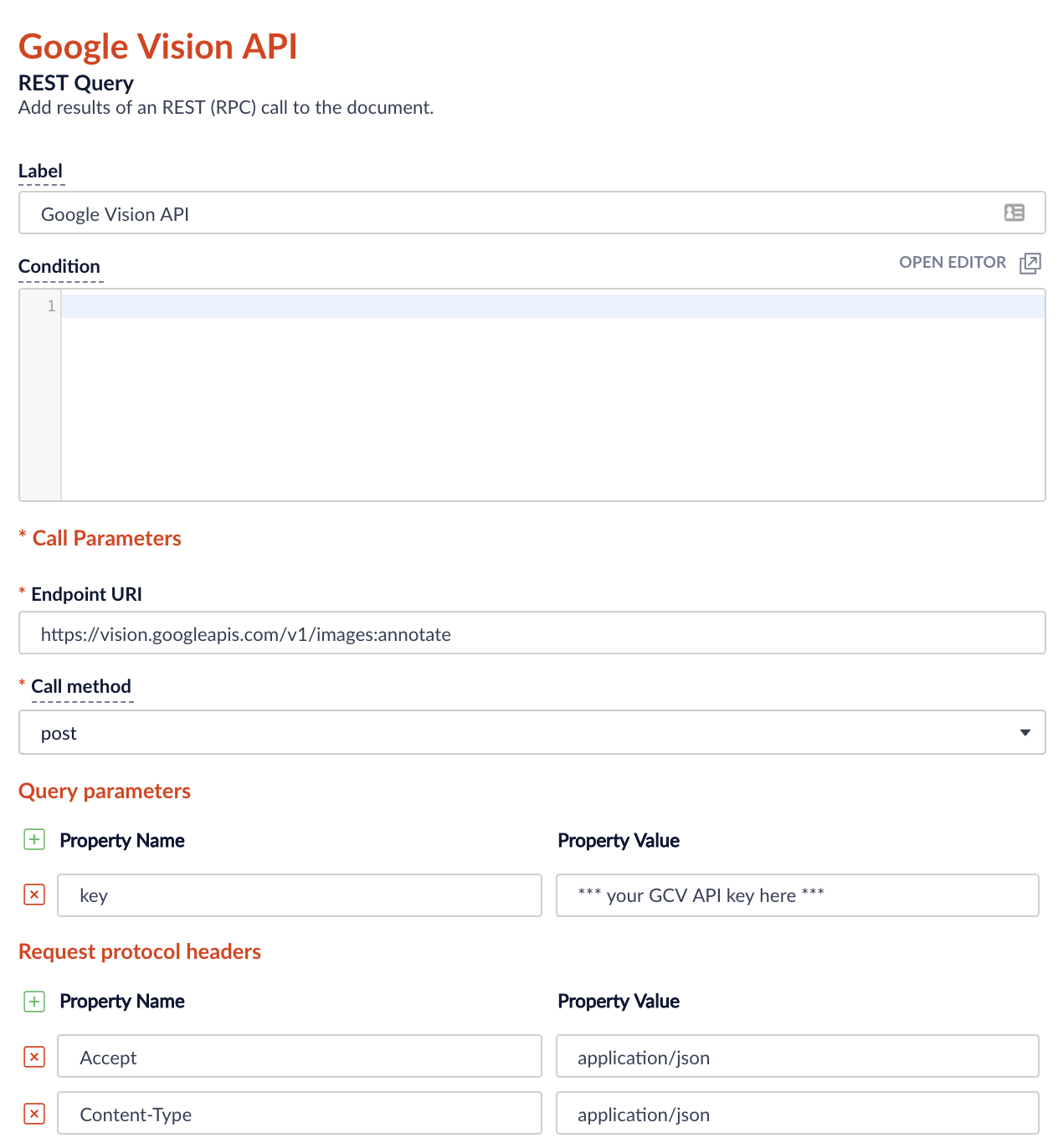
Abbildung 3: HTTP-Parameter Hinweis: Sie können Ihren eigenen API-Schlüssel in der Google Cloud Console generieren.
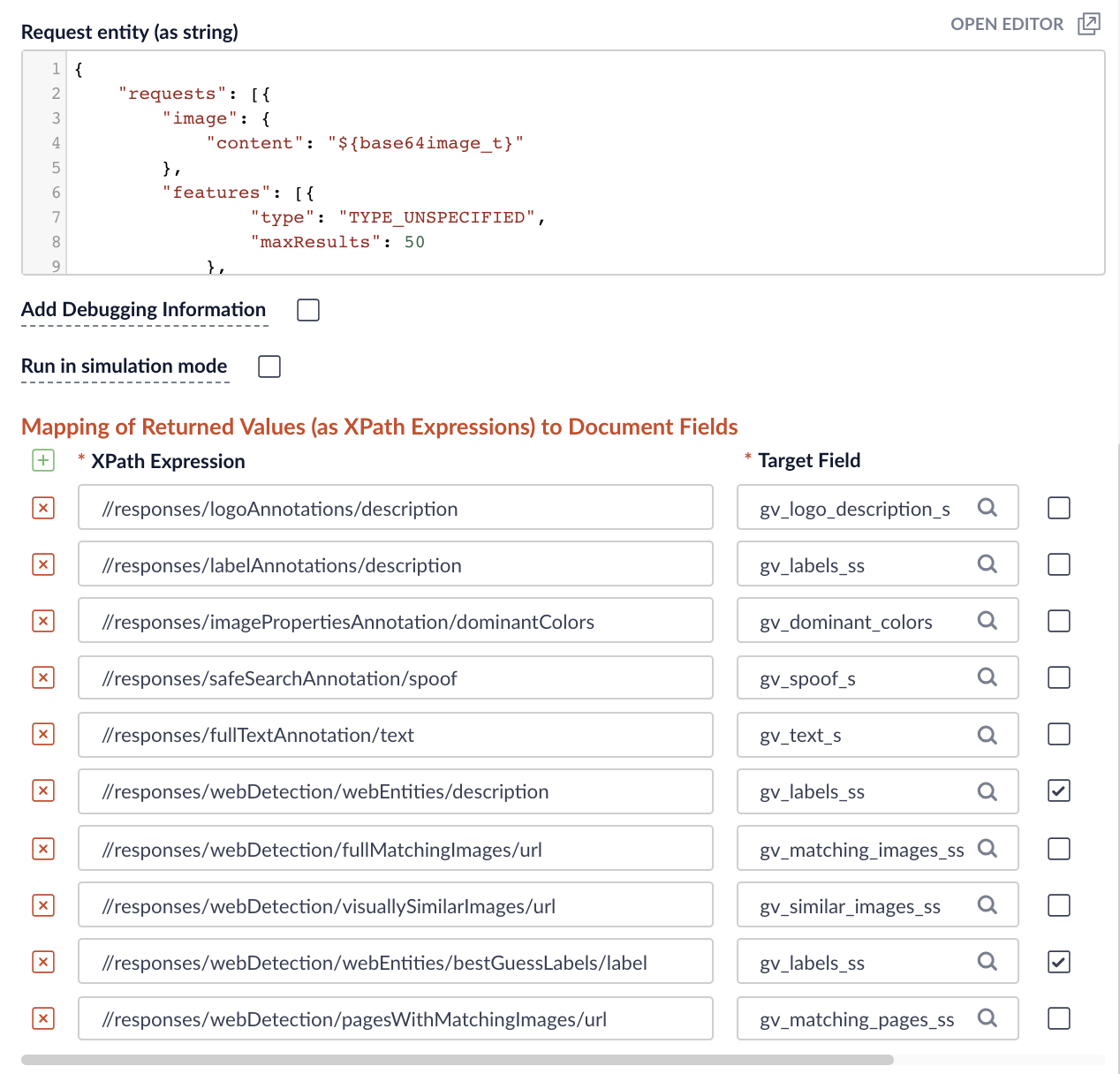
Abbildung 4: Feldzuordnungen Verwenden Sie das folgende JSON als Anfrage-Entität. Beachten Sie die Verwendung des Feldes ${base64input}, das im vorangegangenen JavaScript-Schritt als Wert für die Abfrageeigenschaft image.content definiert wurde.
{ "requests": [{ "image": { "content": "${base64image_t}" }, "features": [ { "type": "TYPE_UNSPECIFIED", "maxResults": 50 }, { "type": "LANDMARK_DETECTION", "maxResults": 50 }, { "type": "FACE_DETECTION", "maxResults": 50 }, { "type": "LOGO_DETECTION", "maxResults": 50 }, { "type": "LABEL_DETECTION", "maxResults": 50 }, { "type": "TEXT_DETECTION", "maxResults": 50 }, { "type": "SAFE_SEARCH_DETECTION", "maxResults": 50 }, { "type": "IMAGE_PROPERTIES", "maxResults": 50 }, { "type": "CROP_HINTS", "maxResults": 50 }, { "type": "WEB_DETECTION", "maxResults": 50 } ] }] } - Bonus: Verwenden Sie Name That Color, um den Namen der Farbe zu finden, die dem dominanten RGB-Code des Bildes am nächsten kommt. Fügen Sie der Index-Pipeline eine weitere JavaScript-Stufe mit folgendem Code hinzu:
function (doc) { /* +---------------------------------------------------------+ | paste the content of http://chir.ag/projects/ntc/ntc.js | | right below this comment +---------------------------------------------------------+ */ if (null != doc.getId()) { var reds = doc.getFieldValues( "gv_dominant_colors.colors.color.red"); var greens = doc.getFieldValues( "gv_dominant_colors.colors.color.green"); var blues = doc.getFieldValues( "gv_dominant_colors.colors.color.blue"); var scores = doc.getFieldValues( "gv_dominant_colors.colors.score"); if (null != reds && null != greens && null != blues && null != scores) { var dominant = -1; var highScore = -1; var score = -1; for (var i = 0; i < scores.size(); i++) { score = scores.get(i); if (null != score && parseFloat(score) > highScore) { highScore = score; dominant = i; } } if (dominant >= 0) { var red = parseInt(reds.get(dominant)).toString(16); if (red.length == 1) red = "0" + red; var green = parseInt(greens.get(dominant)).toString(16); if (green.length == 1) green = "0" + green; var blue = parseInt(blues.get(dominant)).toString(16); if (blue.length == 1) blue = "0" + blue; var rgb = "#" + red + green + blue; score = parseFloat(scores.get(dominant)); if (null != rgb && null != score) { var match = ntc.name(rgb); if (null != match && undefined != match && match.length > 0) { if (rgb != match[0]) { doc.setField( "gv_dominant_color_s", match[0]); doc.setField( "gv_dominant_color_score_d", score); } if (match.length > 1) { doc.setField( "gv_dominant_color_name_s", match[1]); } } } } } } }
Als nächstes starten Sie einen Crawl Ihrer Web- oder Dateisystemdatenquelle. In dieser Demo indiziere ich ein Verzeichnis mit Fotos, die ich zuvor aus dem Internet heruntergeladen habe und die von einem lokalen Webserver bereitgestellt werden.
Hinweis: Achten Sie darauf, dass die Dropdown-Liste Parser leer bleibt, da wir stattdessen eine Tika Parser-Stufe verwenden.
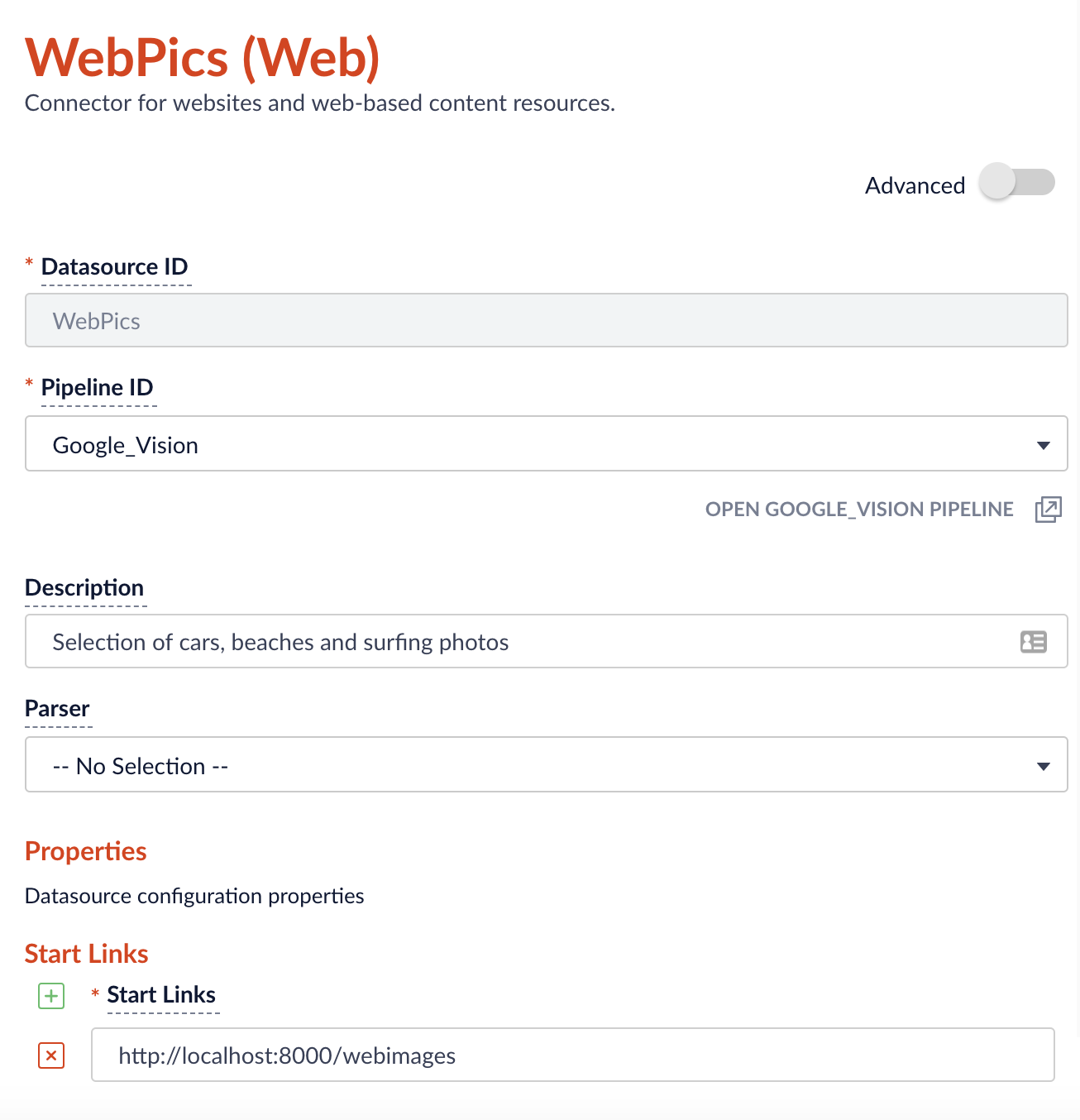
Sobald wir einige indizierte Inhalte haben, können wir mit der Query Workbench einige Facetten einrichten.
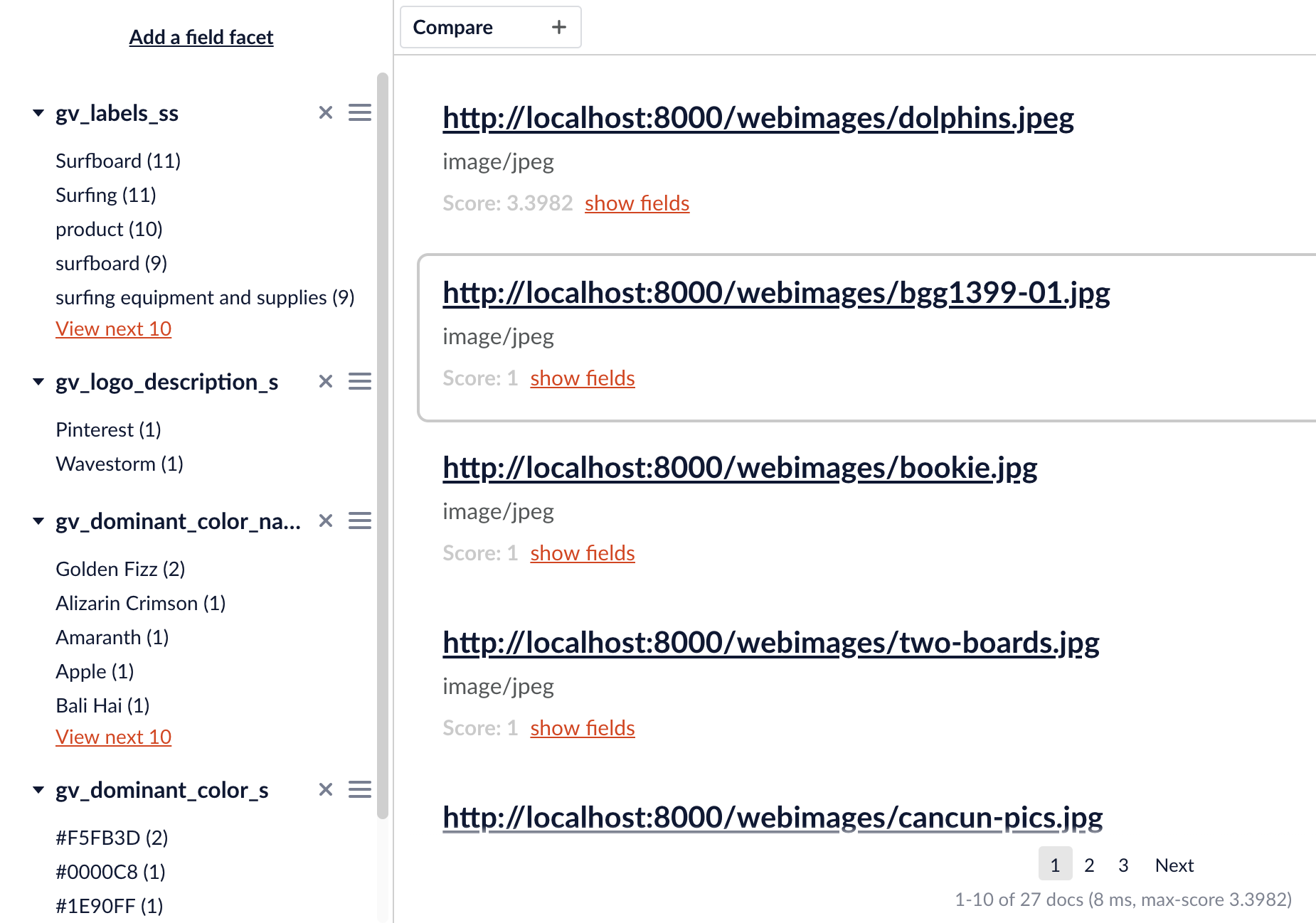
Alles zusammenfügen
Mit den neu angereicherten Metadaten kann meine neue Suchanwendung nun aussagekräftige Ergebnisse für Suchanfragen wie „Surfbrett aus Holz“ und ein „Auto mit Weißwandreifen und Surfbrett“ liefern. Als zusätzlichen Bonus hat das GCV AOPI auch einen Reverse Image Lookup für die Bilder auf meinem lokalen Server durchgeführt und die Originalbilder oder Hosting-Seiten im Internet gefunden.
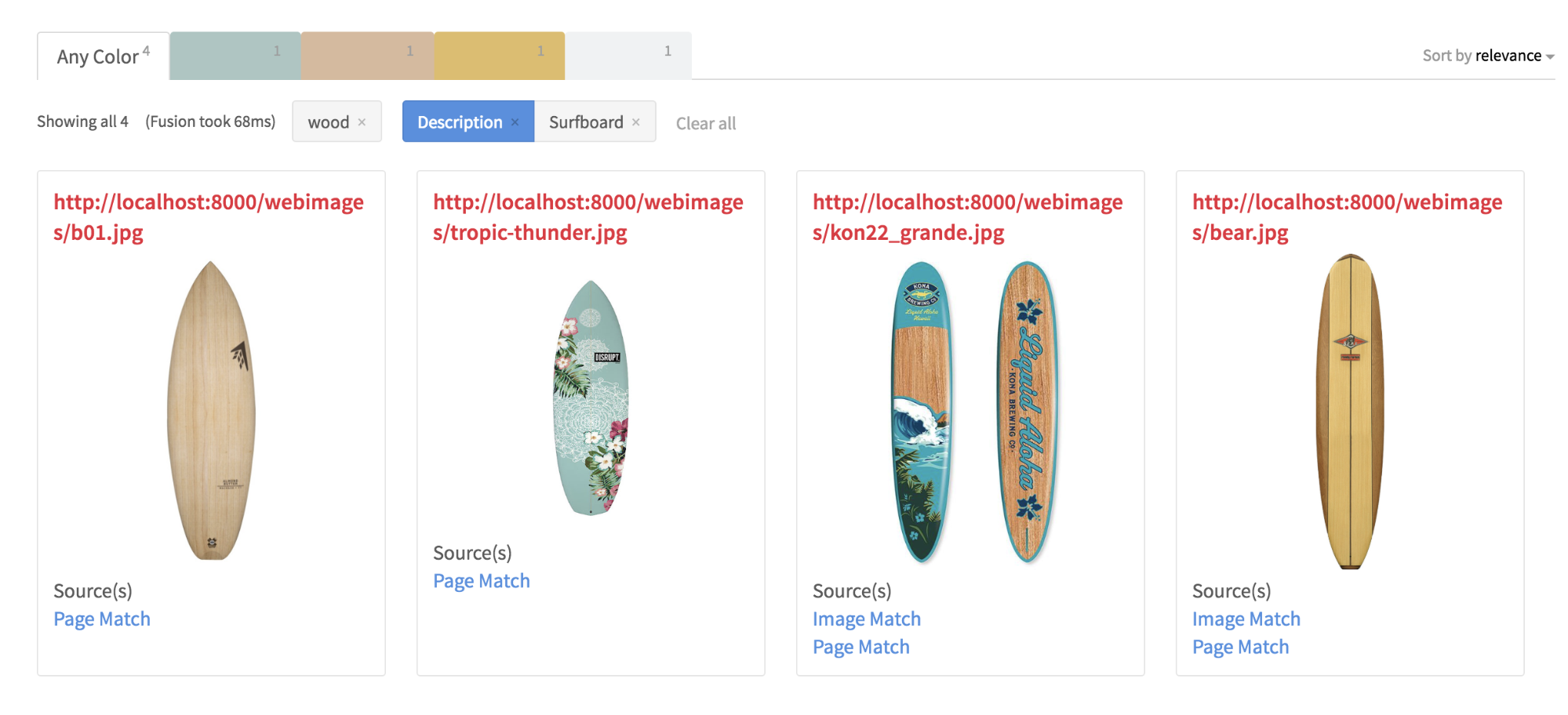
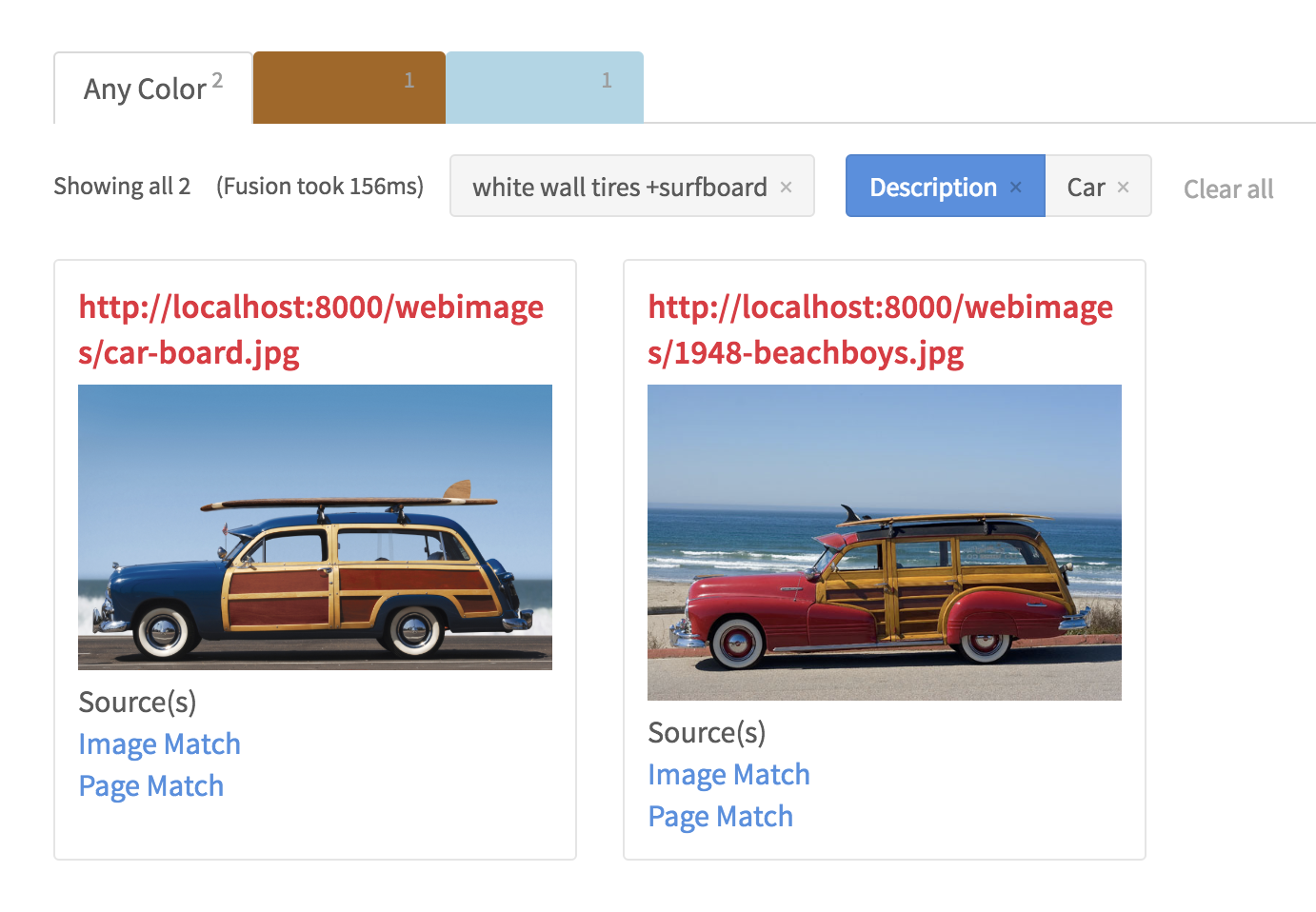
Fazit
Lucidworks Fusion ist eine leistungsstarke und skalierbare Suchplattform, die auf der offenen Grundlage von Apache Solr und Spark aufbaut. Die Index-Pipelines von Fusion wandeln eingehende Daten über eine Reihe konfigurierbarer Stufen in Dokumentobjekte um, die vom Solr-Kern von Fusion indiziert werden. Die REST Query- und JavaScript-Phasen bieten eine schnelle und einfache Erweiterbarkeit des Dateneingabeprozesses, um externe APIs wie die Cloud Vision API von Google einzubeziehen, die die von Suchanwendungen verwendeten Metadaten weiter anreichern.
Nächste Schritte
- Sehen Sie sich meinen Webcast Using Google Vision Image Search in Fusion an und besuchen Sie das Webinar A/B Testing in Fusion 4 von Lasya Marla
- Sehen Sie sich unsere zuvor aufgezeichnete Fusion 4 Übersicht an
- Kontaktieren Sie uns, wir helfen Ihnen gerne.