Noob* Anmerkungen: Fusion Erster Blick
Dies ist ein Bericht darüber, wie ich mich in Fusion eingearbeitet habe, angefangen bei Null. Ich bin gerade dem Lucidworks-Team beigetreten, um Dokumentation zu schreiben und Demos zu entwickeln. Ich möchte diesen ersten Beitrag den Entwicklern widmen, die wie ich genug über die Suche und Lucene und/oder Solr wissen, um gefährlich zu sein, die aber Fusion noch nicht benutzt haben.
Erste Schritte
Ich klicke gerne zuerst und lese die Dokumente später, also suche ich als erstes die Download-Seite von Fusion auf. Ich lade Fusion (Version 1.1.1) herunter. Es handelt sich um einen gzipped tarball mit einer README.txt Datei, die auf die Online-Dokumentation verweist. Es sieht so aus, als müsste ich die Dokumentation eher früher als später lesen.
Die Installationsanweisungen sind ganz einfach. Auf meinem Mac läuft Java7 JDK (Build 1.7.0_71-b14), aber ich habe keine bestehende Solr-Installation, also muss ich Fusion mit der eingebetteten Solr-Instanz starten. Ich führe den Befehl bin/fusion start aus, richte den Chrome-Webbrowser auf http://localhost:8764 und melde mich an. Die Fusion-Benutzeroberfläche zeigt 5 Symbole an: Admin, Quick Start, Relevancy Workbench, Search, Banana Dashboards. Ich klicke mich nacheinander durch die Symbole. Das Banana Dashboard ist besonders beeindruckend. Das sieht ganz anders aus als die Solr Admin UI, das steht fest.
Die Anweisungen auf der Seite Erste Schritte beginnen mit der Admin-App. Ich folge den Schritten in den ersten 5 Minuten mit Fusion und erstelle eine Sammlung mit dem Namen getStarted und eine Webdatenquelle mit dem Namen lucidworks. Das Konzept Collection ist aus Solr bekannt; es handelt sich um einen logischen Index. Datenquellen werden verwendet, um Daten in einen Index zu ziehen. Wenn Sie die Lucidworks-Webseiten ab der URL https://lucidworks.com indizieren, erhalten Sie 1180 Dokumente.

Bei einer langsamen Kabel-Internetverbindung dauerte dies 5 Minuten. Zu diesem Zeitpunkt habe ich etwa 3 Minuten damit verbracht, die Admin UI anzustarren und mich durchzuklicken, und 5 Minuten damit, die Lucidworks-Dokumente zu lesen. Es ist immer ratsam, eine Zeitschätzung mit 2 (oder 3) zu multiplizieren. Wenn ich also einige Suchvorgänge in weniger als 2 Minuten durchführen kann, haben meine ersten 5 Minuten mit Solr 10 Minuten meiner Zeit in Anspruch genommen, plus 5 Minuten für die Indexierung. Ich führe eine Reihe von Suchen durch: „Lucidworks“ liefert 1175 Dokumente, „Lucidworks AND Fusion“ liefert 1174 Dokumente, „Java AND Python“ liefert 15 Dokumente, „unicorn“ liefert 0 Dokumente. Das hat überhaupt keine Zeit gekostet. Ich habe eine Sammlung und die Suchergebnisse sehen vernünftig aus. Indem ich den Anweisungen folge und alles ignoriere, was ich nicht verstehe, sind meine ersten 5 Minuten mit Fusion ein voller Erfolg gewesen.
Ein echtes Problem
Bis jetzt habe ich die Reifen getreten und eine Runde auf dem Parkplatz gedreht. Jetzt ist es an der Zeit, ein paar neue Inhalte zu indizieren. Mein bevorzugter Testfall sind die Inhalte der National Library of Medicine. Die NLM unterhält Datenbanken zu Medikamenten, Chemikalien, Krankheiten, Genen, Proteinen und Enzymen sowie MEDLINE/PubMed, eine Sammlung von mehr als 24 Millionen Zitaten biomedizinischer Literatur aus MEDLINE, biowissenschaftlichen Fachzeitschriften und Online-Büchern. Die NLM vermietet MEDLINE/PubMed an US-amerikanische und nicht-US-amerikanische Einzelpersonen oder Organisationen und stellt sie in Form eines Satzes von XML-Dateien zur Verfügung, deren oberstes Element <MedlineCitationSet> ist. Jeder Zitationssatz enthält ein oder mehrere lt;MedlineCitation> Elemente. Jedes Jahr veröffentlicht die NLM eine neue Version von MEDLINE, eine überarbeitete DTD und einen Beispieldatensatz. Kann ich die Beispieldaten von MEDLINE/PubMed 2015 so einfach indizieren wie lucidworks.com?
Die Antwort lautet: Ja, ich kann die Daten indizieren, aber es erfordert ein wenig mehr Arbeit, da ein spezieller Dokumentensatz einen speziellen Index erfordert. Ich demonstriere dies anhand eines Fehlers. Über die Fusion Admin UI erstelle ich eine neue Sammlung namens Medsamp2015. Wie zuvor erstelle ich eine Webdatenquelle namens medsamp2015xml und verweise auf die Beispieldatei MEDLINE/PubMed 2015. Fusion verarbeitet diese URL zu einem einzigen Dokument.
Da es nur ein Dokument im Index gibt, verwende ich die Platzhaltersuche „*“, um es zu untersuchen.
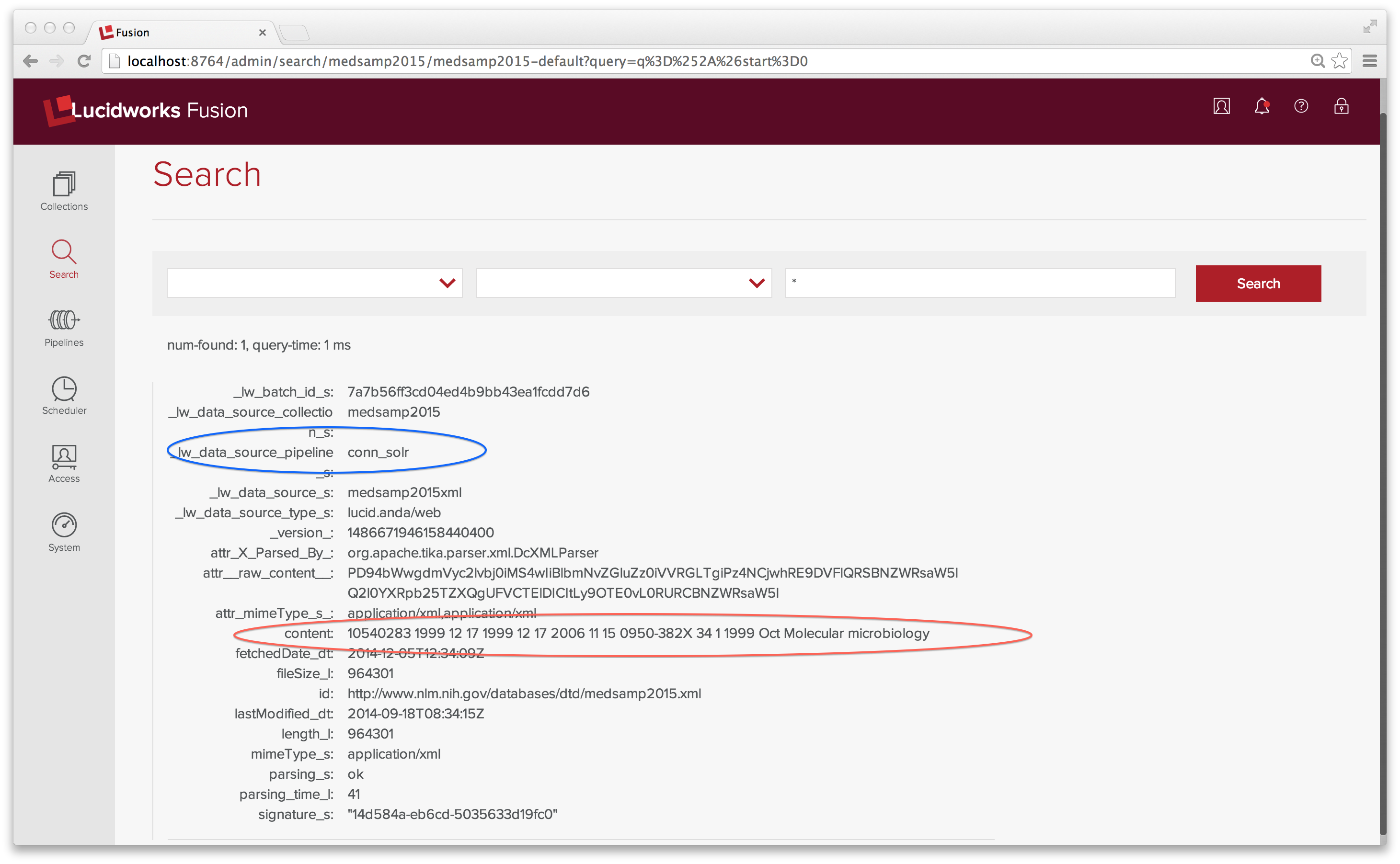
Das Feld content enthält den Text aller Elemente in der XML-Datei. Definitiv nicht die Indizierungsstrategie, die ich im Sinn hatte. Die MEDLINE 2015 Beispieldatei hat ein Top-Level-Element <MedlineCitationSet> und 165 <MedlineCitation> Elemente. Ich möchte jedes <MedlineCitation> Element als eigenes Dokument indizieren.
Eine echte Lösung
Eine Fusion-Datenquelle ist mit einer Index-Pipeline gekoppelt. Pipelines sind leistungsstark, müssen aber konfiguriert werden. Mit ein wenig Hilfe der Fusion-Entwickler konnte ich eine Indexierungs-Pipeline für die Medline-Daten erstellen. Hier ist ein Bericht darüber, was ich getan habe, was funktioniert hat und was nicht.
Pipelines bestehen aus einer Abfolge von Stufen. Die Pipeline conn_solr ist eine Allzweck-Pipeline für das Parsen von Dokumenten, die aus folgenden Stufen besteht: einer Apache Tika Parser Index-Stufe, einer Field Mapper Index-Stufe, einer Multi-Value Resolver-Stufe und einer Solr Indexer-Stufe. Die Tika Parser-Schnittstelle bietet einen einzigen Mechanismus zur Extraktion von Metadaten und Daten aus vielen verschiedenen Arten von Dokumenten, einschließlich HTML, XML und XHTML. Die Stufe Field Mapper Index ordnet allgemeine Dokumentelemente definierten Feldern im Standardschema von Solr zu. Die Stufe Multi-Value Resolver löst Konflikte auf, die sonst entstehen würden, wenn ein Dokument mehrere Werte für ein Solr-Feld enthält, das nicht mehrwertig ist. Schließlich sendet die Stufe Solr-Indexer die Dokumente zur Indizierung an Solr.
Da eine enge Verbindung zwischen einer Datenquelle und der auf diese Daten angewandten Verarbeitung besteht, bietet die Fusion Admin UI, wenn möglich, eine Standard-Indexpipeline-ID. Bei einer Web-Datenquelle ist die Standard-Index-Pipeline die conn_solr -Pipeline, die Feldzuordnungen für häufig vorkommende Elemente auf HTML-Seiten bereitstellt. Im obigen Beispiel für Erste Schritte gab es eine Eins-zu-Eins-Entsprechung zwischen Webseiten und Dokument im Solr-Index.
Bei einer Medline-XML-Datei ist eine zusätzliche Verarbeitung erforderlich, um jedes Zitat in ein mit Feldern versehenes Dokument für Solr umzuwandeln. Die erforderliche Indizierungspipeline sieht wie folgt aus:
- Apache Tika Parser
- XML-Transformation
- Feld-Mapper
- Solr Indexer
Diese Pipeline sieht oberflächlich betrachtet ähnlich aus wie die conn_solr Index-Pipeline, aber sowohl die Tika Parser- als auch die Field Mapper-Phase sind ganz anders konfiguriert und eine XML Transform-Phase wird verwendet, um bestimmte Elemente des Medline-XML auf benutzerdefinierte Felder im Solr-Dokument zu mappen. Eine Multi-Value Resolver-Stufe ist nicht notwendig, da ich das Mapping so eingerichtet habe, dass mehrwertige Elemente auf mehrwertige Felder abgebildet werden. Die Konfiguration des Solr Indexers bleibt unverändert.
Mit dem neuen Fusion Admin UI Pipelines-Kontrollfeld können Sie sowohl Index- als auch Abfrage-Pipelines definieren. Es ist auch möglich, Pipelines über die Fusion REST API zu definieren. Als Neuling bleibe ich bei der Admin UI. Nachdem ich mich zum Pipelines-Kontrollfeld, Registerkarte Index-Pipelines, durchgeklickt habe, erstelle ich eine neue Index-Pipeline mit dem Namen medline_xml und füge dann nacheinander die einzelnen Phasen hinzu.
Wenn eine neue Stufe hinzugefügt wird, zeigt das Pipeline-Panel die für diese Stufe erforderlichen Konfigurationsoptionen an.
Apache Tika Parser Konfiguration
Um die MEDLINE XML-Datei zu verarbeiten, muss ich Tika so konfigurieren, dass es nicht versucht, den Textinhalt zu extrahieren, sondern die XML-Datei an die nächste Stufe der Indizierungspipeline weitergibt. Ich habe die Konfiguration, die ich benötige, im folgenden Screenshot festgehalten und die Einstellung, die ich gegenüber der aktuellen Standardeinstellung ändern musste, rot eingekreist:
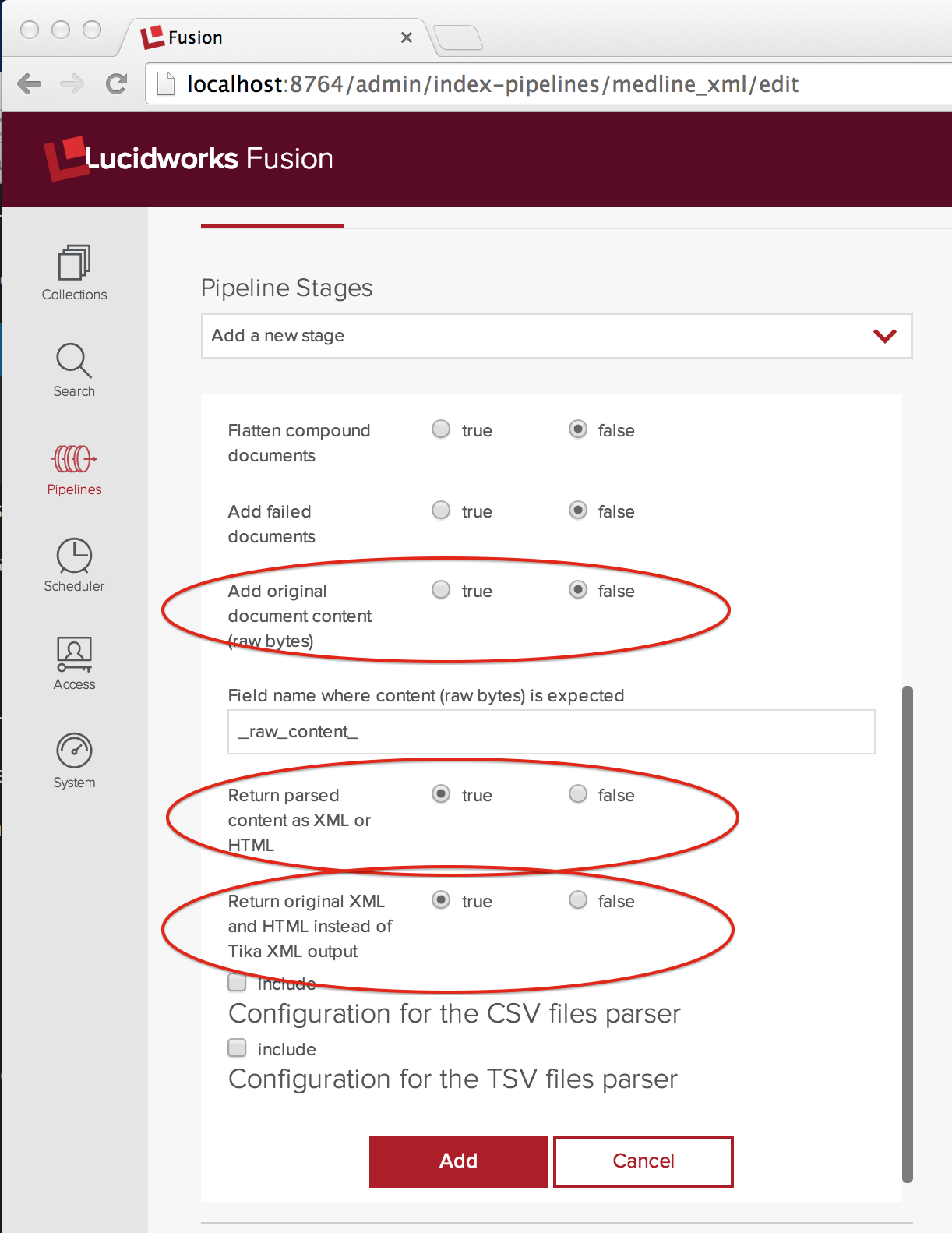
Das Steuerelement addOriginalContent ist auf false gesetzt und die beiden Steuerelemente „Geparsten Inhalt als XML oder HTML zurückgeben“ und „Original XML und HTML statt Tika XML zurückgeben“ sind auf true gesetzt. Die beiden letztgenannten Steuerelemente scheinen überflüssig zu sein, sind es aber nicht und Sie müssen beide auf true gesetzt haben, damit es funktioniert. Vertrauen Sie mir.
XML-Transformationskonfiguration
Die XML-Transformationsstufe sorgt für das Mapping von verschachtelten XML-Elementen in ein feldbasiertes Dokument für Solr. Nachdem ich eine XML-Transform-Stufe zu meiner Pipeline hinzugefügt und benannt habe, kann ich das Mapping festlegen. Der folgende Screenshot zeigt die wichtigsten Konfigurationen:
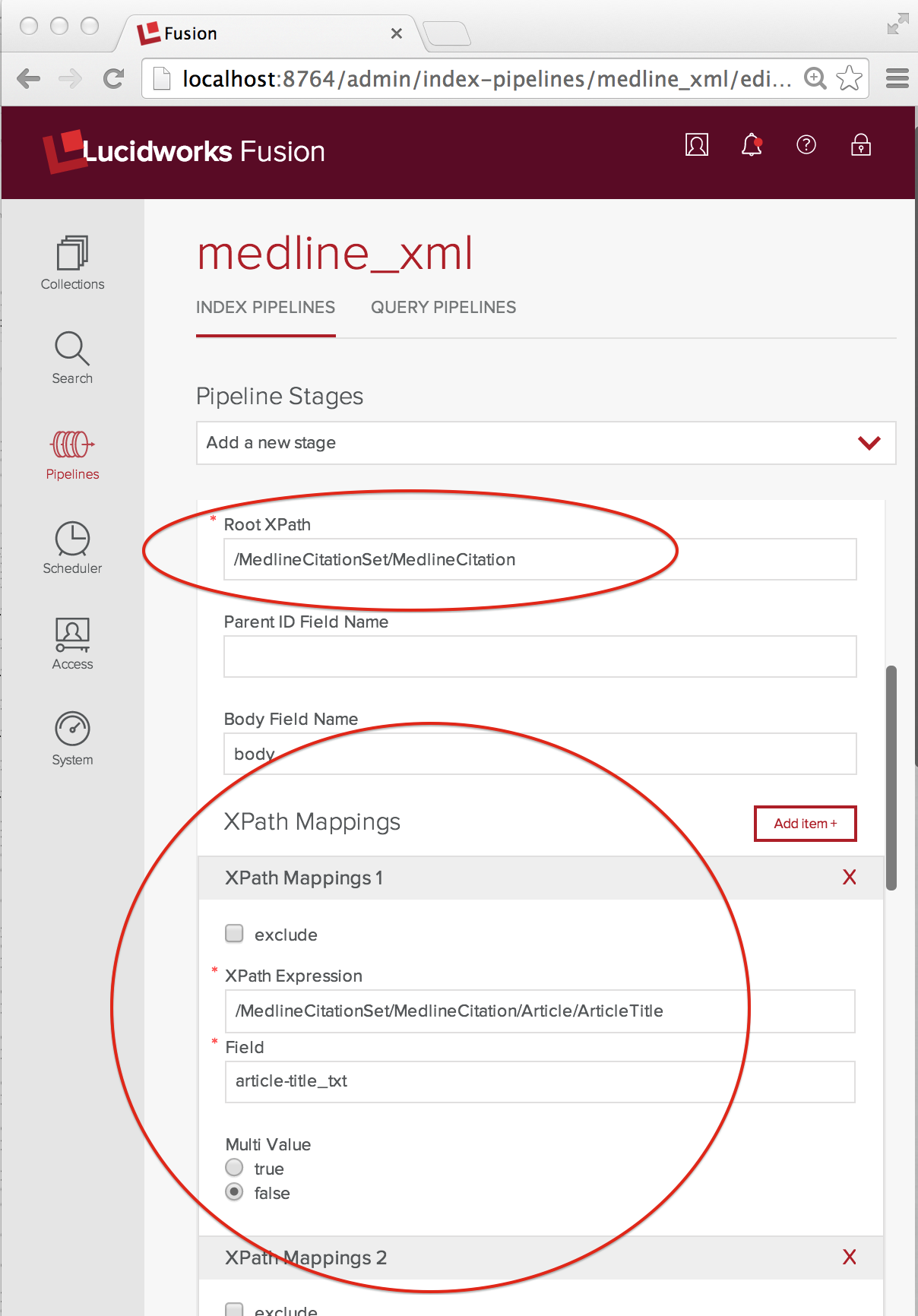
Da wir jedes MedlineCitation-Element als eigenes Dokument indizieren möchten, wird das Root XPath-Element auf den vollständigen XPath „/MedlineCitationSet/MedlineCitation“ gesetzt. XPathMappings wählt die Elemente aus, die den Feldern in diesem Dokument entsprechen. Für meine Dokumentfelder verwende ich die dynamischen Feldbenennungskonventionen von Solr. Jeder MedlineCitation wird eine eindeutige ganzzahlige Kennung zugewiesen, die PMID (PubMed ID). In diesem Beispiel ist die Umwandlung von MEDLINE XML in ein Solr-Dokument ganz einfach. Die verwendeten XPathMappings sind:
- „/MedlineCitationSet/MedlineCitation/Article/ArticleTitle“ entspricht „article-title_txt“, Multi Value false
- „/MedlineCitationSet/MedlineCitation/Artikel/Abstract/AbstractText“ entspricht „article-abstract_txt“, Multi Value true
- „/MedlineCitationSet/MedlineCitation/MeshHeadingList/MeshHeading/DescriptorName“ entspricht „mesh-heading_txt“, Multi Value true.
Es gibt noch viele weitere Informationen, die Sie aus der XML-Datei extrahieren können, aber das reicht erst einmal aus.
Feld Mapper Konfiguration
Es ist kompliziert, aber da ich Tika und eine XML-Transformation verwende, brauche ich eine Field Mapper-Stufe, um einige der von Tika erstellten Dokumentfelder zu entfernen, bevor ich das Dokument zur Indizierung an Solr sende. Auf Anraten meines lokalen Assistenten erstelle ich Mappings für die Felder „_raw_content_“, „parsing“, „parsing_time“, „Content-Type“ und „Content-Length“ und setze den Modus auf „delete“.
Solr Indexer Konfiguration
Ich habe die Option „Dokumente puffern“ für Solr auf true gesetzt. Dies ist nicht unbedingt notwendig. Es scheint nur eine gute Sache zu sein.
Überprüfen der Konfiguration mit dem Pipeline-Ergebnisvorschau-Tool
Dies ist eine Menge zu konfigurieren, und ich hätte es ohne das Tool „Pipeline-Ergebnisvorschau“, das sich auf der rechten Seite der Pipeline-Benutzeroberfläche befindet, nicht geschafft. Das Vorschau-Tool nimmt als Eingabe eine Liste von Dokumenten, die als JSON-Objekte kodiert sind, und lässt sie durch die Indizierungspipeline laufen. Ein Dokumentobjekt hat zwei Mitglieder: id und fields. Hier hat unsere Eingabe genau ein Feld mit dem Namen „body“, dessen Wert eine JSON-kodierte Zeichenfolge des rohen XML (oder eine Teilmenge davon) ist. Die JSON-Eingabe kann Strings nicht zeilenübergreifend aufteilen, was bedeutet, dass das JSON-kodierte XML so gut wie unlesbar ist. Nach mehreren Versuchen erhalte ich ein wohlgeformtes MedlineCitationSet-Beispiel, das aus drei MedlineCitation-Elementen besteht, die ordnungsgemäß in JSON umgewandelt wurden und in einer Zeile zusammengeklemmt sind.
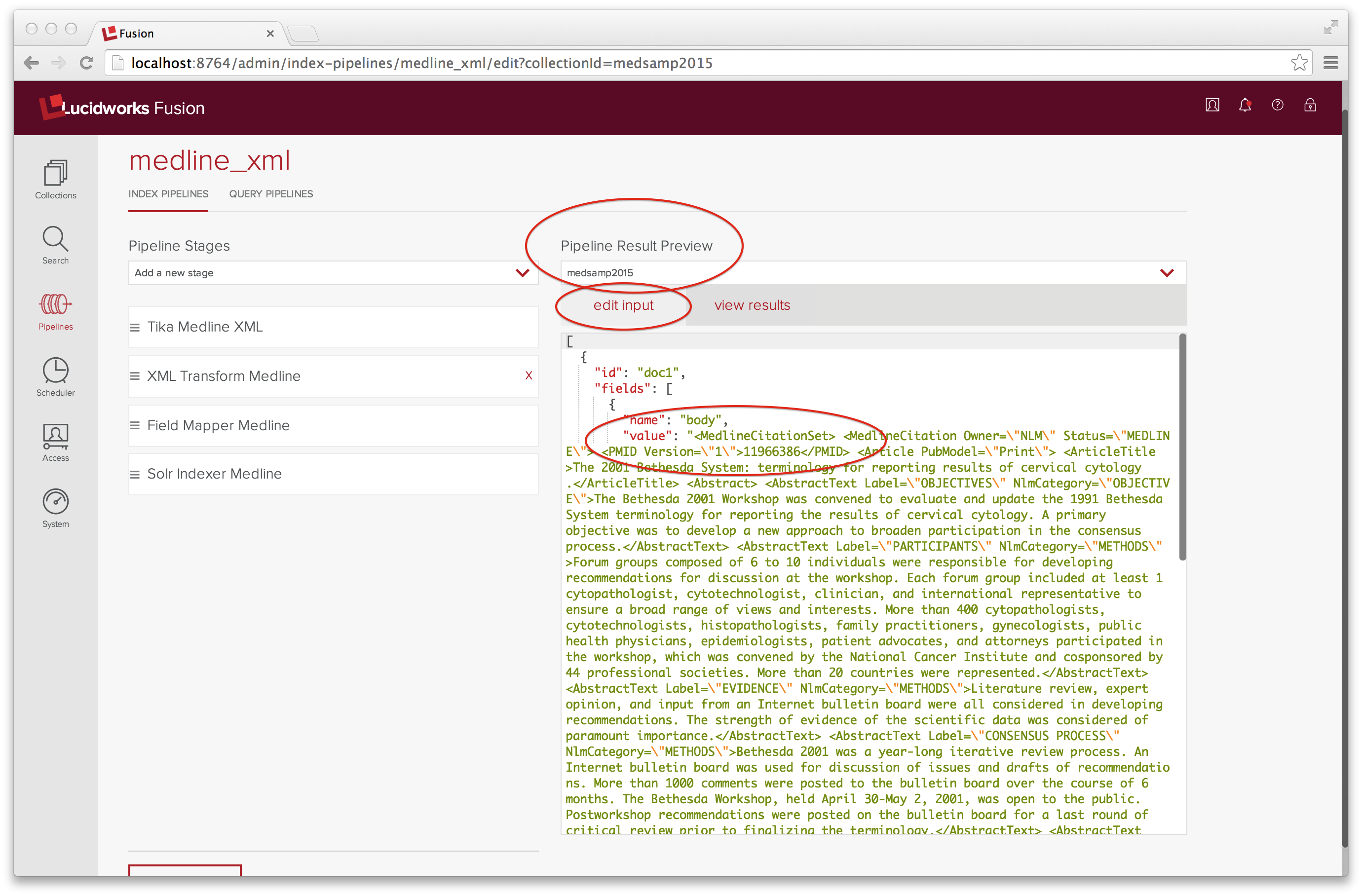
Auf der Registerkarte „Ergebnisse anzeigen“ sehen Sie das Ergebnis des Durchlaufs dieser Eingabe durch die medline_xml Indizierungspipeline:
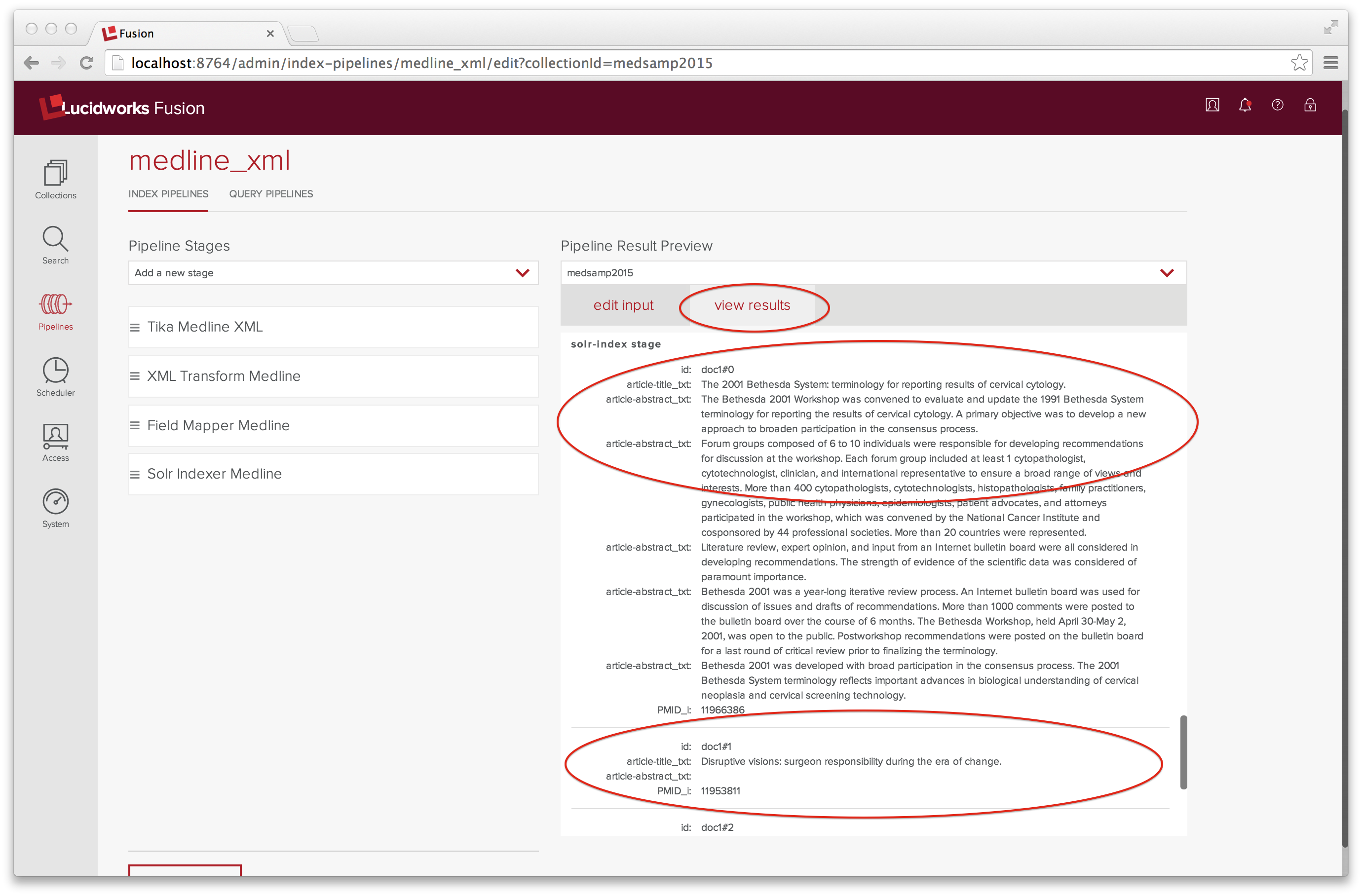
Ich habe nach unten gescrollt, um die Eingabe für den Solr Indexer anzuzeigen, die aus drei Dokumenten besteht, die doc1#0 bis doc1#2 heißen.
Indizierung
Von der Fusion Admin UI aus kehre ich zum Sammlungen-Panel für die Sammlung namens medsamp2015. Wie zuvor erstelle ich eine Webdatenquelle mit dem Namen medsamp2015xml_v2 und verweise auf die Beispieldatei MEDLINE 2015, wobei ich darauf achte, die medline_xml-Pipeline im Eingabefeld „Pipeline ID“ anzugeben.

Eine Eingabe wurde verarbeitet und der Index enthält jetzt 165 Dokumente. Ich habe es geschafft, neue Inhalte zu indizieren!
Suche und Ergebnisse
Als ersten Test führe ich eine Stichwortsuche nach dem Wort „Gen“ durch. Diese Suche liefert keine Dokumente. Ich führe eine Stichwortsuche nach „*“ durch. Diese Suche liefert 165 Dokumente, von denen das allererste das Wort „Gen“ sowohl im Titel als auch in der Zusammenfassung des Artikels enthält. Auch hier liegt das Problem in der Pipeline, die ich verwende. Die Standardabfrage-Pipeline durchsucht nicht die Felder „article-title_txt“, „article-abstract_txt“ oder „mesh-heading_txt“.
Die Abstimmung der Suchabfrageparameter erfolgt über das Bedienfeld Query Pipeline. Nachdem ich den Satz der Suchfelder und Rückgabefelder in „medsamp2015-default“ so geändert habe, dass er diese Felder enthält, führe ich einige weitere Testabfragen durch. Jetzt liefert eine Suche nach „Gen“ 11 Ergebnisse und gibt nur die relevanten Felder zurück.
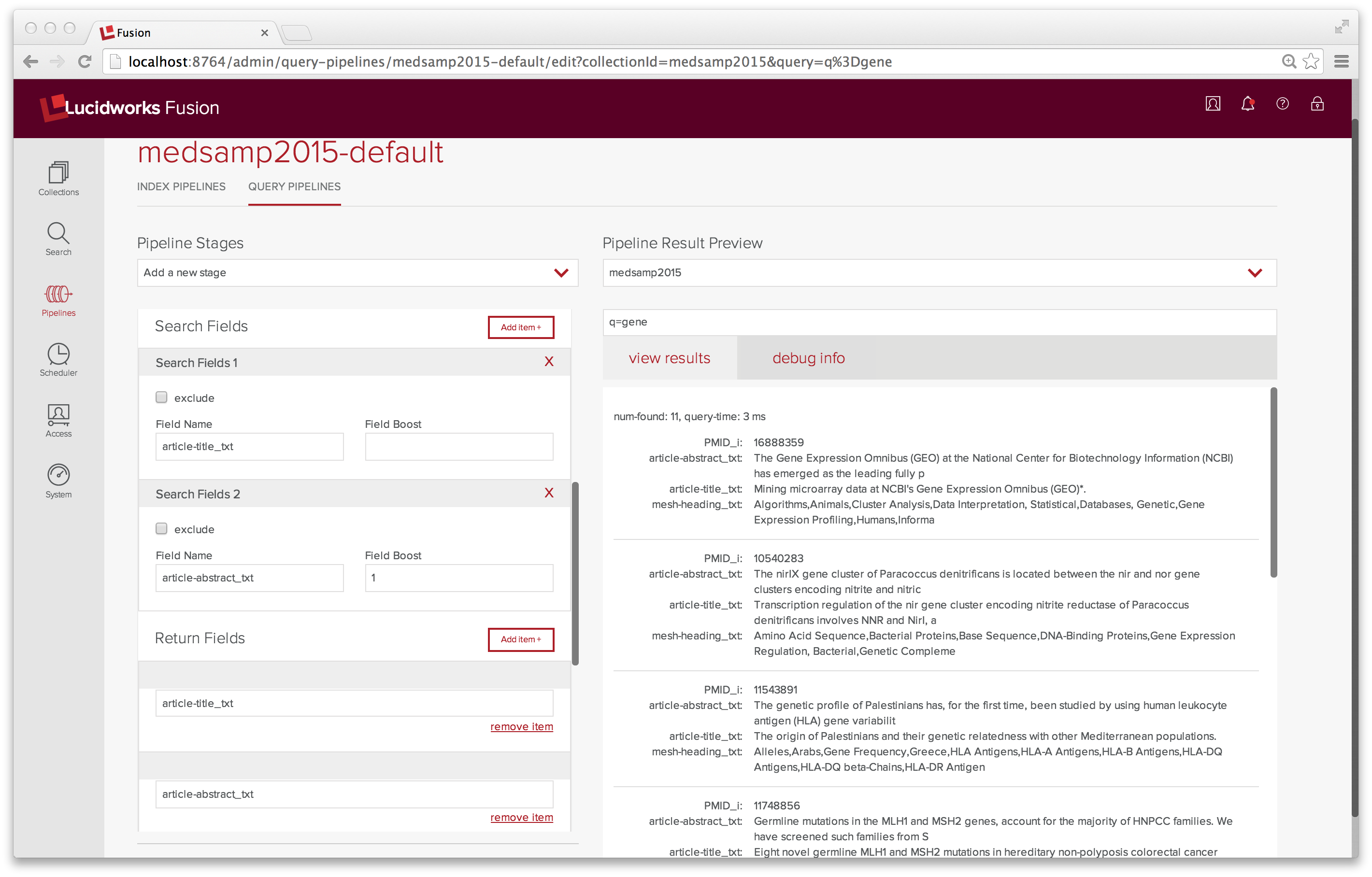
Zusammenfassend kann ich sagen, dass es mir gelungen ist, die Fusion Admin UI zum Suchen und Indizieren meiner Daten zu verwenden. Ich habe die Enterprise noch nicht auf Warp-Geschwindigkeit gebracht. Vielleicht nächste Woche. In der Zwischenzeit habe ich eine Menge gelernt und ich hoffe, Sie auch.
*Wagen Sie es, neue Dinge zu lernen, wagen Sie es, ein Noob zu sein