Parsing und Indizierung von mehrwertigen Feldern in Fusion
Vor kurzem habe ich einen Kunden bei der Umstellung von einer reinen Apache Solr-Implementierung auf Lucidworks Fusion unterstützt. Ein Teil dieser Arbeit bestand in der Wiederherstellung von Indizierungsprozessen (die mit den REST-APIs von Solr implementiert wurden) in der Fusion-Umgebung. Dabei wurden die Vorteile von Indexierungspipelines genutzt, um die erforderliche ETL von Solr zu entkoppeln und wiederverwendbare Komponenten für die zukünftige Verarbeitung bereitzustellen.
Eine besondere Funktion, die in der vorherigen Umgebung stark genutzt wurde, war die Definition von „Feldtrennern“ in den REST-API-Aufrufen an den Solr UpdateCSV Request Handler. Zum Beispiel:
curl "http://localhost:8888/solr/collection1/update/csv/?commit=true&f.street_names.split=true&f.street_names.separator=%0D" --data-binary @input.csv -H 'Content-type:text/plain; charset=utf-8'
Der obige curl-Befehl sendet eine CSV-Datei an den /update/csv Request Handler, wobei die Request-Parameter "f.aliases.split=true" und "f.aliases.separator=%0D" das Feld in der Spalte „aliases“ als mehrwertiges Feld mit dem Zeichen „r“ als Trennzeichen zwischen den Werten kennzeichnen (%0D ist ein Mechanismus, um den Wagenrücklauf zu umgehen, indem der hexadezimale ASCII-Code für „r“ angegeben wird). Auf diese Weise lassen sich mehrwertige Felder, die als abgegrenzte Zeichenketten gespeichert wurden, bequem analysieren und indizieren. Weitere Informationen zu diesem Parameter finden Sie hier.
Nach der Untersuchung möglicher Ansätze in Fusion wurde festgestellt, dass der einfachste Weg, dies zu erreichen (und ein gewisses Maß an Flexibilität und Wiederverwendbarkeit zu bieten) darin bestand, eine Index-Pipeline mit einer JavaScript-Stufe zu erstellen.
Die Index-Pipeline
Index-Pipelines sind ein Rahmenwerk, mit dem Sie eine Reihe von atomaren Schritten, so genannte „Stages“, zusammenfügen können, die die während der Indizierung einfließenden Dokumente dynamisch bearbeiten können. Pipelines können über die Verwaltungskonsole erstellt werden, indem Sie im linken Menü auf „Pipelines“ klicken, dann eine eindeutige und beliebige ID eingeben und auf „Pipeline hinzufügen“ klicken – siehe unten.
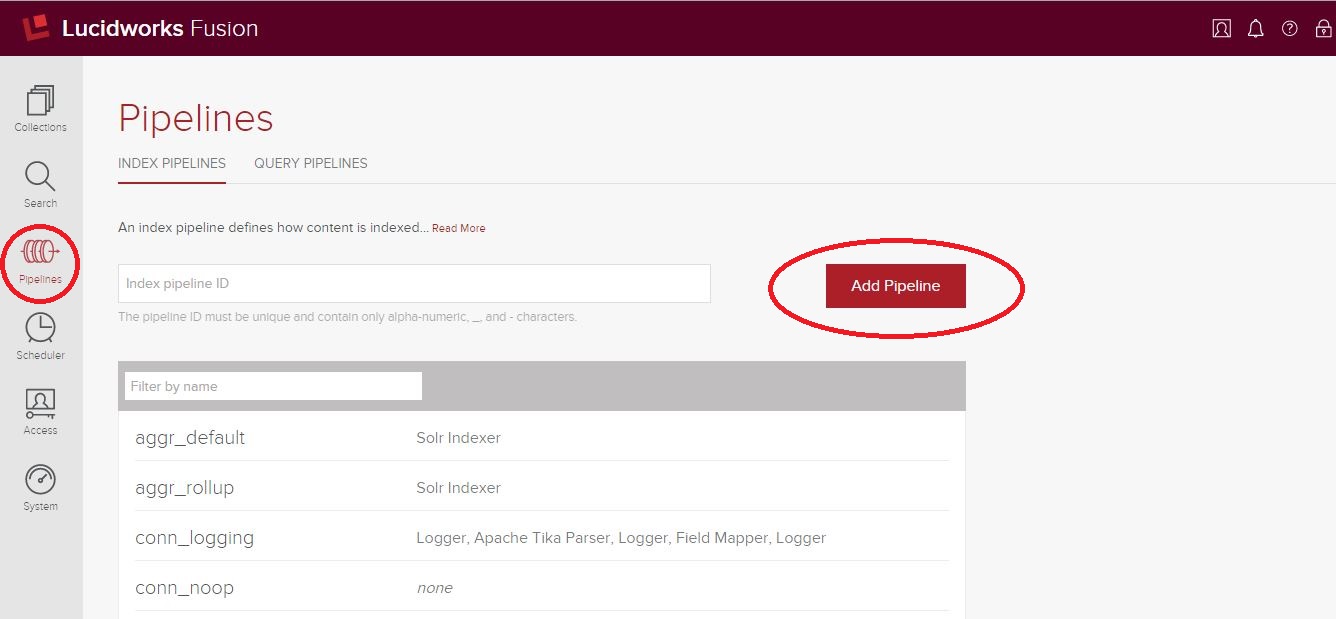
Nachdem Sie Ihre Pipeline erstellt haben, müssen Sie Stufen hinzufügen. In unserem Fall haben wir eine recht einfache Pipeline mit nur zwei Stufen: eine JavaScript-Stufe und eine Solr Indexer-Stufe. Jede Stufe hat ihren eigenen Kontext und ihre eigenen Eigenschaften und wird in der von Fusion konfigurierten Reihenfolge ausgeführt. Da es in diesem Beitrag um die Manipulation von Dokumenten geht, werde ich nicht näher auf die Solr Indexer-Stufe eingehen; weitere Informationen dazu finden Sie hier. Nachfolgend sehen Sie unsere Pipeline mit den beiden neuen Phasen, die so konfiguriert sind, dass die JavaScript-Phase vor der Solr Indexer-Phase ausgeführt wird.
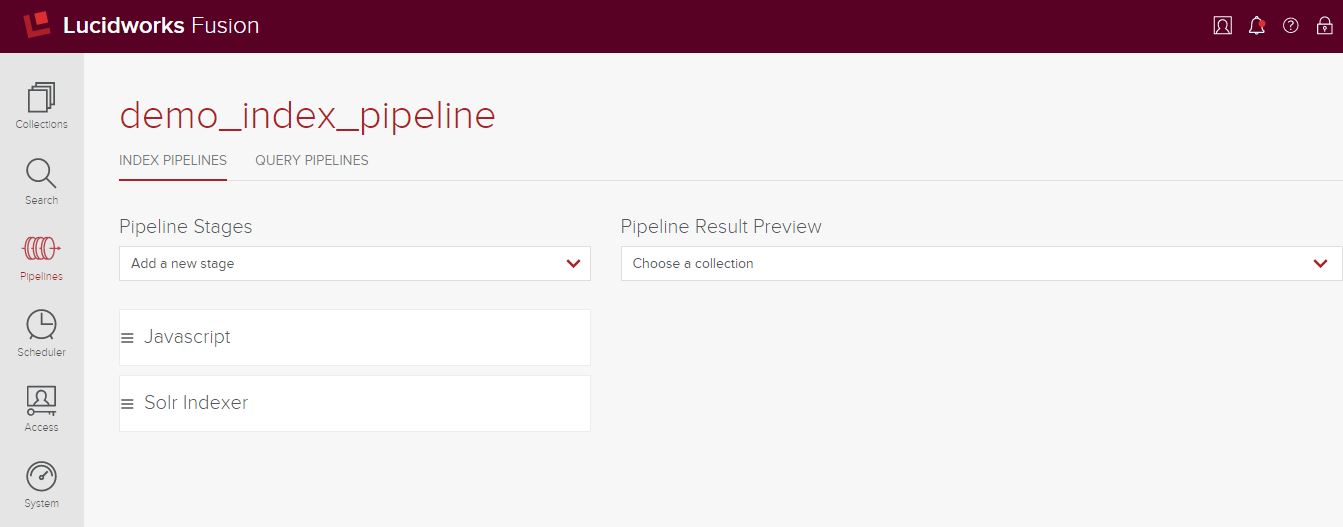
Die JavaScript-Indexstufe
Wir haben für unseren Ansatz eine JavaScript-Bühne gewählt, die uns die Möglichkeit gibt, jedes indizierte Dokument über Standard-JavaScript direkt zu bearbeiten – ein äußerst leistungsstarker und bequemer Ansatz. Die JavaScript-Stufe hat vier Eigenschaften:
- „Diese Phase überspringen“ – ein Flag, das angibt, ob diese Phase ausgeführt werden soll
- „Label“ – eine optionale Eigenschaft, mit der Sie der Bühne einen freundlichen Namen zuweisen können
- „Bedingtes Skript“ – JavaScript, das vor jedem anderen Code ausgeführt wird und true oder false zurückgeben muss. Bietet einen Mechanismus zum Filtern von Dokumenten, die von dieser Stufe verarbeitet werden; wenn false zurückgegeben wird, wird die Stufe übersprungen.
- „Script Body“ – erforderlich; das JavaScript, das für jedes indizierte Dokument ausgeführt wird (wenn das Skript in „Conditional Script“, falls vorhanden, true zurückgegeben hat)
Unten sehen Sie unsere JavaScript-Stufe mit der Einstellung „Diese Stufe überspringen“ auf false und der Bezeichnung „JavaScript_Split_Fields“.
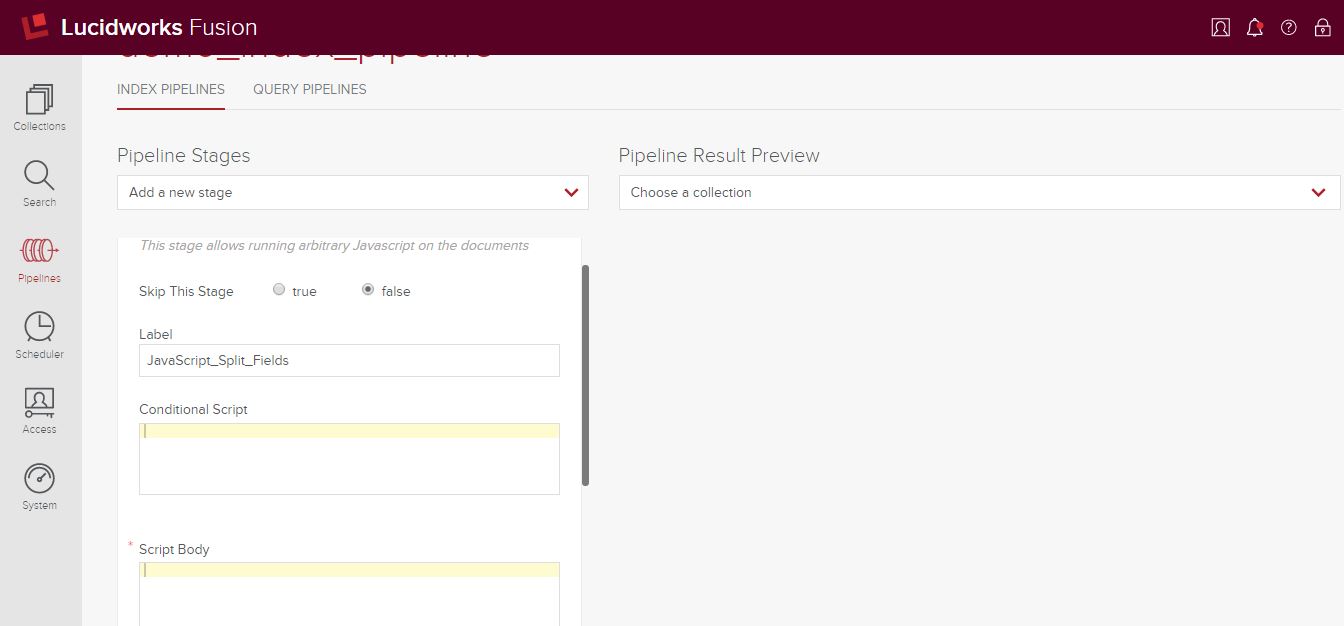
Unser Ziel ist es, ein Feld (genannt „Alias“) in jedem Dokument bei einem Wagenrücklauf (CTRL-M) aufzuteilen. Zu diesem Zweck definieren wir einen „Script Body“, der JavaScript enthält, das jedes Dokument auf das Vorhandensein eines bestimmten Feldes prüft, es gegebenenfalls aufteilt und die resultierenden Werte diesem Feld zuweist.
Die in „Script Body“ definierte Funktion kann ein (doc, das Pipeline-Dokument) oder zwei (doc und _context, der von Fusion verwaltete Pipeline-Kontext) Argumente annehmen. Da diese Phase die erste ist, die in der Pipeline ausgeführt wird, und es keine benutzerdefinierten Variablen gibt, die an die nächste Phase übergeben werden müssen, benötigt die Funktion nur das Argument doc. Die Funktion ist dann verpflichtet, doc (wenn das Dokument indiziert werden soll) oder null (wenn es nicht indiziert werden soll) zurückzugeben. In Wirklichkeit werden wir niemals null zurückgeben, da der Zweck dieser Phase darin besteht, Dokumente zu manipulieren und nicht zu bestimmen, ob sie indiziert werden sollen.
function (doc) {
return doc;
}
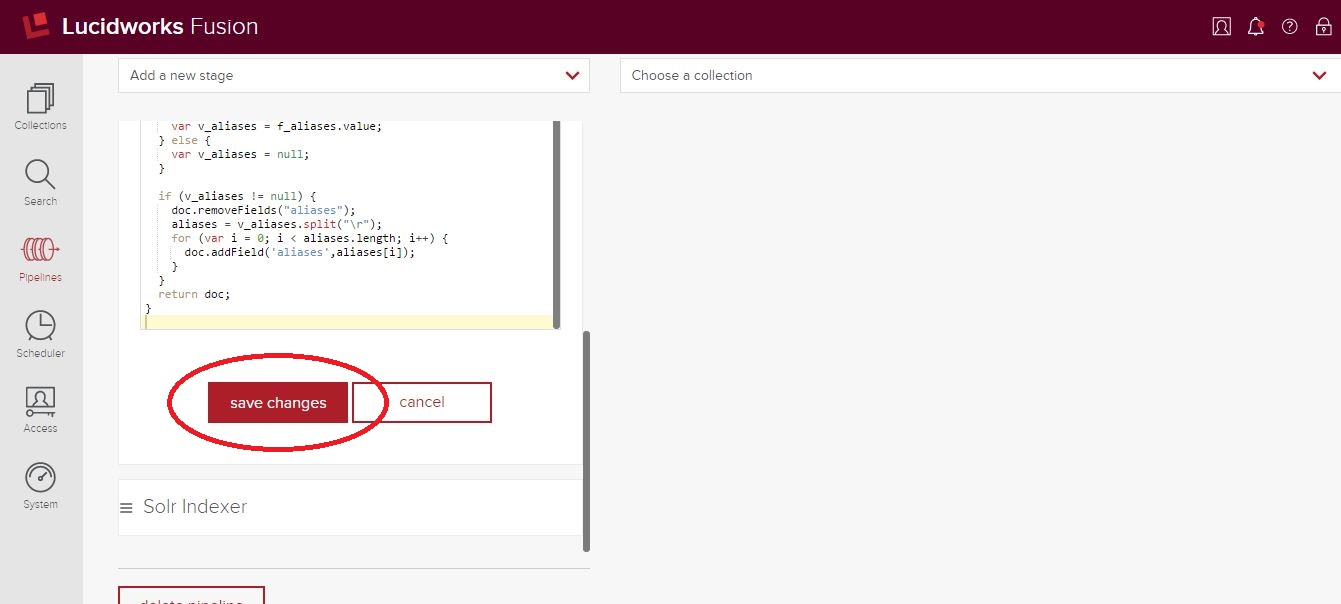
Da wir nun einen Verweis auf das Dokument haben, können wir nach dem Feld „aliases“ suchen und es entsprechend aufteilen. Nach der Aufteilung müssen wir den vorherigen Wert entfernen und die neuen Werte zu „aliases“ hinzufügen (das in unserem Solr-Schema als mehrwertiges Feld definiert ist). Hier ist der endgültige Code:
function (doc) {
var f_aliases = doc.getFirstField("aliases");
if (f_aliases != null) {
var v_aliases = f_aliases.value;
} else {
var v_aliases = null;
}
if (v_aliases != null) {
doc.removeFields("aliases");
aliases = v_aliases.split("r");
for (var i = 0; i < aliases.length; i++) {
doc.addField('aliases',aliases[i]);
}
}
return doc;
}
Klicken Sie unten in den Eigenschaften dieser Stufe auf „Änderungen speichern“.
Alles unter einen Hut bringen
Jetzt haben wir eine Index-Pipeline – sehen wir uns an, wie sie funktioniert! In Fusion ist eine Index-Pipeline nicht an eine bestimmte Sammlung oder Datenquelle gebunden, so dass sie leicht wiederverwendet werden kann. Wir müssen diese Pipeline mit der Datenquelle verknüpfen, aus der wir „Aliase“ abrufen. Dies geschieht, indem wir die Pipeline-ID in dieser Datenquelle so einstellen, dass sie auf unsere neu erstellte Pipeline verweist.
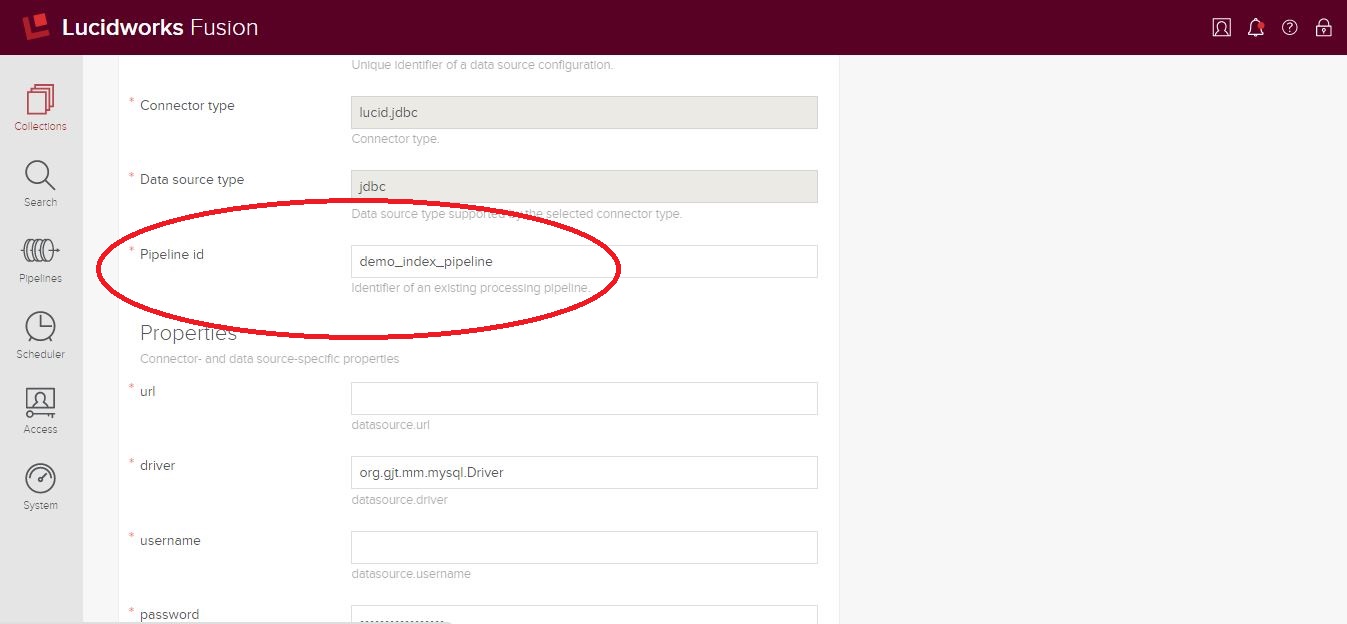
Speichern Sie Ihre Änderungen und wenn Sie das nächste Mal die Indizierung dieser Datenquelle starten, wird Ihre Index-Pipeline ausgeführt.
Sie können Ihre JavaScript-Stage debuggen, indem Sie den Bereich „Pipeline-Ergebnisvorschau“ nutzen, mit dem Sie Ihren Code direkt im Browser anhand statischer Daten testen können. Außerdem können Sie dem JavaScript Protokollanweisungen hinzufügen, indem Sie eine Methode des Logger-Objekts aufrufen, für das Ihre Stage bereits ein Handle besitzt. Zum Beispiel:
logger.debug("This is a debug message");
schreibt eine Protokollnachricht auf Debug-Ebene an <fusion home>/logs/connector/connector.log. Durch die Kombination dieser beiden Ansätze sollten Sie in der Lage sein, die Ursache aller aufgetretenen Probleme schnell zu ermitteln.
Eine letzte Anmerkung
Wahrscheinlich haben Sie bereits erkannt, welches Potenzial die JavaScript-Stage bietet; Lucidworks nennt sie ein „Schweizer Taschenmesser“. Sie können nicht nur jedes ECMA-konforme JavaScript ausführen, sondern auch Java-Bibliotheken importieren. So können Sie benutzerdefinierten Java-Code innerhalb der Stufe verwenden und eine Vielzahl von Lösungen anbieten. Die JavaScript-Stage ist ein leistungsstarkes Werkzeug für jede Pipeline!
Über den Autor
Sean Mare ist ein Technologe mit über 18 Jahren Erfahrung in der Konzeption und Entwicklung von Unternehmensanwendungen. Als Solution Architect bei der Knowledgent Group Inc., einem führenden Beratungsunternehmen für Big Data und Analytik und Partner von Lucidworks, nutzt er die Möglichkeiten der Unternehmenssuche, um Menschen und Organisationen zu ermöglichen, ihre Daten auf spannende und interessante Weise zu erforschen. Er wohnt im Großraum New York City.