Pivot zur Abfrage: Verwendung von Pivot-Facetten zum Aufbau eines Mehrfeld-Suggestors
Suggestoren, auch bekannt als Autovervollständigung, Typeahead oder „prädiktive Suche“, sind leistungsstarke Mittel, um die Konversation zwischen Benutzer und Suchanwendung zu beschleunigen. Die Abfrage einer Suchanwendung ist ein wenig wie ein Ratespiel – der Benutzer formuliert eine Abfrage, von der er hofft, dass sie das Gewünschte liefert – aber manchmal gibt es ein Element von „Ich weiß nicht, was ich nicht weiß“ – also kann die anfängliche Abfrage etwas vage oder zweideutig sein. Nachfolgende Interaktionen mit der Suchanwendung sind manchmal erforderlich, um die gewünschten Informationen zu finden. Facettierte Navigation und Suchvorschläge sind zwei Möglichkeiten, um diese Situation zu verbessern. Facetten wirken in der Regel im Nachhinein, d.h. nachdem ein erster Versuch unternommen wurde, wohingegen Suggestoren versuchen, bereits beim Verfassen der ersten Suchanfrage Feedback zu geben, um die Präzision der Anfrage von Anfang an zu verbessern. Facetten bieten auch eine kontextbezogene, mehrdimensionale Visualisierung der Ergebnismenge, die im „Entdeckungsmodus“ der Suche sehr nützlich sein kann.
Ein Grundprinzip der Suggestor-Implementierung ist es, niemals Suchanfragen vorzuschlagen, die keine Ergebnisse liefern werden. Alles andere ist sinnlos (und erweckt auch kein Vertrauen in Ihre Suchanwendung!). Vorschläge können aus einer Reihe von Quellen stammen – frühere Suchanfragen, die sich als beliebt erwiesen haben, Vorschläge, die auf bestimmte Geschäftsziele abzielen, und Vorschläge, die auf den Inhalten basieren, die in die Suchkollektion aufgenommen wurden. Es gibt auch eine Reihe von Implementierungen, die in Solr/Lucene standardmäßig verfügbar sind.
Ich konzentriere mich hier auf Vorschläge, die über die Abfrage eines einzelnen Begriffs hinausgehen – die mehr Details zu den gewünschten Ergebnissen liefern und die Vorteile von mehrdimensionalen Facetten mit Typeahead kombinieren. Vorschläge, die aus Abfrageprotokollen abgeleitet werden, können diesen Kontext haben, aber diese werden in Bezug auf ihre Struktur nicht kontrolliert. Vorschläge aus indizierten Begriffen oder Feldwerten können ebenfalls verwendet werden, aber diese funktionieren nur mit jeweils einem Feld. Ein weiterer Schwerpunkt dieses und meiner vorangegangenen Blogs ist es, etwas semantische Intelligenz in den Suchprozess einzubringen – je mehr, desto besser. Eine Möglichkeit, dies zu tun, besteht darin, grammatikalisch sinnvolle Vorschläge zu formulieren, die aus mehreren Metadatenfeldern zusammengesetzt sind und Abfragephrasen bilden, die eindeutig angeben, was zurückgegeben wird.
Was meine ich also mit „grammatikalisch sinnvollen Vorschlägen“? Nur, dass wir an die Metadaten denken können, die wir in unserem Suchindex haben (und wenn wir sie nicht haben, sollten wir versuchen, sie besorgen!) als Attribute oder Eigenschaften einiger Elemente oder Konzepte, die durch indizierte Dokumente repräsentiert werden. Es gibt potenziell eine große Anzahl von Permutationen dieser Attributwerte, von denen die meisten aus grammatikalischer Sicht keinen Sinn ergeben. Einige Attribute beschreiben die Art der Sache (Typattribute), andere beschreiben die Eigenschaften der Sache. Im linguistischen Sinne können wir uns diese als Substantiv- bzw. Adjektiveigenschaften vorstellen.
Um ein Beispiel zu geben, was ich meine: Nehmen wir an, ich habe einen Suchindex über Personen und Orte. Normalerweise hätten wir Felder wie Vorname, Nachname, Beruf, Stadt und Bundesland. Normalerweise würden wir uns diese Felder in dieser Reihenfolge vorstellen oder vielleicht nachname, vorname, stadt, staat – beruf wie in:
Jones, Bob Cincinnati, Ohio – Buchhalter
Oder
Bob Jones, Buchhalter, Cincinnati, Ohio
Aber wir würden im Allgemeinen nicht verwenden:
Cincinnati Accountant Jones Ohio Bob
Auch wenn dies eine gültige mathematische Permutation der Feldwertanordnung ist. Wenn wir also an alle möglichen Möglichkeiten denken, eine Reihe von Attributen anzuordnen, machen nur einige davon für uns als „menschlich lesbare“ Darstellung der Daten „Sinn“.
Pivot-Facetten „umdrehen“ – Verwendung von Facetten zur Erstellung von Abfragevorschlägen
Facettenwerte selbst sind zwar eine gute Quelle für Abfragevorschläge, weil sie die „Aboutness“ eines Datensatzes kapseln, aber sie können dies nur für jeweils ein Attribut tun. Diese Ebene von Vorschlägen ist bereits mit Solr/Lucene Suggester-Implementierungen verfügbar, die die gleichen Feldwertdaten wie Facetten in Form eines so genannten uninvertierten Indexes (auch bekannt als Lucene FieldCache oder indizierte Doc Values) verwenden. Aber was ist, wenn wir Facettenfelder wie oben kombiniert haben wollen? Solr Pivot-Facetten (siehe„Pivot-Facetten von innen und außen“ für Hintergrundinformationen zu Pivot-Facetten) bieten eine Möglichkeit, eine beliebige Menge von Feldern zu kombinieren, um eine kaskadierende oder verschachtelte Menge von Feldwerten zu erzeugen. Stellen Sie sich das als eine Möglichkeit vor, eine „Taxonomie“ der Facettenwerte zu erstellen – und zwar „on the fly“. Wie hilft uns das weiter? Nun, wir können Pivot-Facetten (zur Indexzeit) verwenden, um alle Permutationen für eine zusammengesetzte Phrase „Vorlage“ zu finden, die aus einer Folge von Feldnamen besteht – d.h. um das zu erstellen, was ich „Facettenphrasen“ nennen werde. Hm? Vielleicht hilft Ihnen ein Beispiel.
Nehmen wir an, ich habe einen Musikindex, der Einträge zu Liedern, Alben, Musikgenres und den Musikern, Bands oder Orchestern, die sie aufgeführt haben, sowie den Komponisten, Textern und Songschreibern, die sie geschrieben haben, enthält. Ich würde gerne nach Dingen wie „Jazz-Schlagzeuger“, „Klassische Geiger“, „Progressive Rockbands“, „Rolling Stones-Alben“ oder „Blues-Songs“ und so weiter suchen. Jede dieser Phrasen setzt sich aus Werten aus zwei verschiedenen Indexfeldern zusammen – zum Beispiel sind „Schlagzeuger“, „Geiger“ und „Band“ Typen von Musikern oder Darstellern. „Rolling Stones“ sind eine Band, die als Gruppe ein Künstler ist (wir haben es hier mit Entitäten zu tun, die einzelne Personen oder Gruppen wie die Stones sein können). „Jazz“, „Klassik“, „Progressive Rock“ und „Blues“ sind Genres und „Alben“ und „Songs“ sind Aufzeichnungstypen („Song“ ist auch ein Kompositionstyp). All diese Dinge können als Facetten behandelt werden. Wenn ich also einige Phrasenmuster für diese Arten von Abfragen erstelle, wie z.B. „Musikertyp, Aufnahmetyp“ oder „Genre, Musikertyp“ oder „Interpret, Aufnahmetyp“, und diese als Pivot-Facettenabfragen einreiche, kann ich aus den zurückgegebenen Facettenwerten viele Beispiele für die oben genannten Phrasen konstruieren. So würde beispielsweise das Pivot-Muster „genre, musician_type“ Dinge wie „Jazzpianist“, „Rockgitarrist“, „klassischer Geiger“, „Countrysänger“ und so weiter zurückgeben – sofern ich für jede dieser Kategoriekombinationen Datensätze in der Sammlung habe.
Sobald ich diese Phrasen habe, kann ich sie als Suchvorschläge verwenden, indem ich sie in einer Sammlung indiziere, die ich zu diesem Zweck verwende. Es wäre auch schön, wenn die Präzision, die ich in meine Suchvorschläge einbaue, bei der Suche beachtet würde. Dies kann auf verschiedene Weise geschehen. Wenn ich meine Suggestor-Sammlung mit diesen Pivot-Mustern aufbaue, kann ich die Quellfelder erfassen und sie mit den Vorschlägen zurücksenden. Dies würde es ermöglichen, präzise Filter- oder Boost-Abfragen zu verwenden, wenn sie vom Such-Frontend übermittelt werden. Ein potenzielles Problem besteht darin, dass der Benutzer genau dieselbe Abfrage eingibt, die ihm vorgeschlagen wurde – d.h. er wählt nicht aus der Dropdown-Liste typeahead. In diesem Fall würde er das Feedback des Suggestors nicht erhalten, aber wir möchten sicherstellen, dass die Ergebnisse genau die gleichen sind.
Die Technik zur automatischen Filterung von Abfragen, die ich entwickelt und über die ich gebloggt habe, ist eine weitere Lösung, um die Präzision der Antwort mit der zusätzlichen Präzision dieser Abfragen mit mehreren Feldern in Einklang zu bringen. Sie würde unabhängig davon funktionieren, ob der Benutzer auf einen Vorschlag klickt oder den Satz selbst eingibt und auf „Enter“ drückt. Einige kürzlich vorgenommene Erweiterungen dieses Codes, die es ermöglichen, auf Verben, Präpositionen oder Adjektive zu reagieren und den „Kontext“ des generierten Filters oder der Boost-Abfrage anzupassen, bieten eine weitere Ebene der Präzision, die wir in unseren Vorschlägen nutzen können. Das heißt, Vorschläge können aus Vorlagen oder Mustern erstellt werden, in die wir „Füllwörter“ wie Verben, Präpositionen und Adjektive einfügen können, die der Abfrage-Autofilter jetzt unterstützt.
Auch hier kann ein Beispiel helfen, die Verwirrung zu klären. In meiner Musik-Ontologie habe ich Attribute für „Interpret“ und „Komponist“ in Dokumenten über Songs oder Aufnahmen von Songs. Viele Künstler, die wir zum Beispiel als „Singer-Songwriter“ bezeichnen, treten sowohl als Komponisten als auch als Interpreten auf. Wenn ich also nach all ihren Songs suchen möchte, unabhängig davon, ob sie sie geschrieben oder aufgeführt haben, kann ich nach etwas wie „Komponist“ suchen:
Jimi Hendrix Songs
Wenn ich nur die Songs sehen möchte, die Jimi Hendrix geschrieben hat, würde ich gerne nach
„Songs, die Jimi Hendrix geschrieben hat“ oder „Songs, die von Jimi Hendrix geschrieben wurden
“
, was Titel wie „Purple Haze“, „Foxy Lady“ und „The Wind Cries Mary“ ergeben sollte.
Im Gegensatz dazu die Abfrage:
„Songs, die Jimi Hendrix gespielt hat“
sollte Coverversionen wie „All Along the Watchtower“ (für Ihr Hörvergnügen, hier ein Link), „Hey Joe“ und „Sgt Peppers Lonely Hearts Club Band“ enthalten.
und
„Songs, die Jimi Hendrix gecovert hat“
würde nicht seine Originalkompositionen umfassen.
In diesem Fall sind die Verbphrasen „wrote“ oder „written by“, „performed“ oder „covered“ keine Feldwerte im Index, aber sie sagen uns, dass der Benutzer die Ergebnisse entweder auf Kompositionen oder auf Aufführungen einschränken möchte. Die neuen Funktionen des Abfrage-Autofilters können jetzt mit diesen Dingen umgehen, aber was ist, wenn wir solche Vorschläge machen wollen?
Dazu schreiben wir das Pivot-Vorlagenmuster wie folgt
${composition_type} ${composer} schrieb
${composition_type} geschrieben von ${composer}
${composition_type} ${performer} durchgeführt
Code für das Pivot Facet Mining
Der Quellcode zum Erstellen von Vorschlägen mit mehreren Feldern unter Verwendung von Pivot-Facetten ist auf github verfügbar. Der Code funktioniert als Java-Main-Client, der eine Suggestion-Sammlung in Solr erstellt.
Das Design des Suggestor Builders umfasst einen oder mehrere „Abfragekollektoren“, die Abfragevorschläge an einen zentralen „Suggestor Builder“ weiterleiten, der a) die Vorschläge anhand der Ziel-Inhaltssammlung validiert und b) mithilfe von Facettenabfragen Kontextinformationen aus der Inhaltssammlung abrufen kann (siehe unten). Eine der Implementierungen des Abfragekollektors ist der PivotFacetQueryCollector. Andere Implementierungen können Vorschläge aus Abfrageprotokollen, Dateien, Fusion-Signalen und so weiter beziehen.
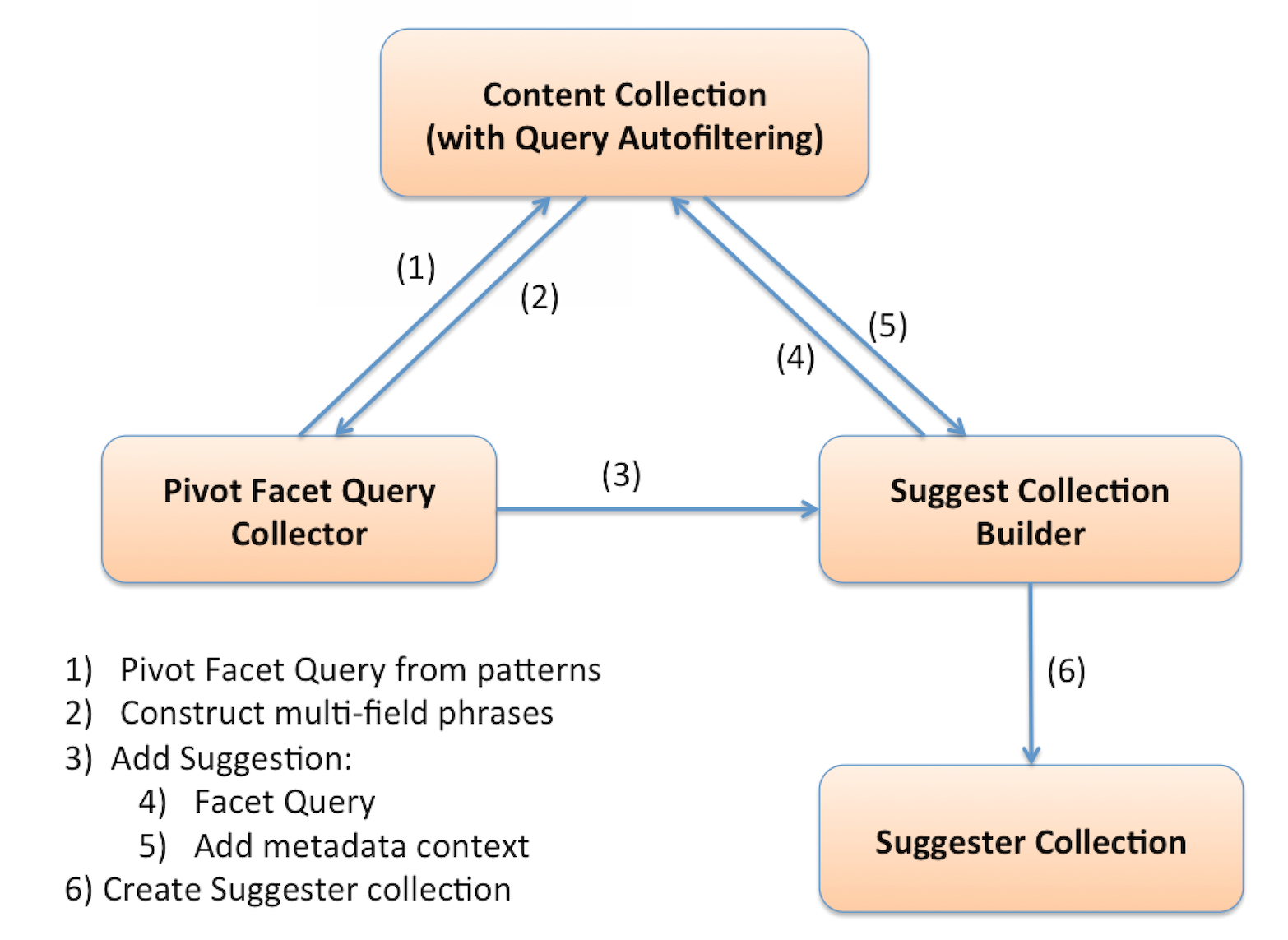
Die github-Distribution enthält den Musik-Ontologie-Datensatz, der für diesen Blog-Artikel verwendet wurde, sowie eine Beispielkonfigurationsdatei, um eine Reihe von Vorschlägen für die Musikdaten zu erstellen. Die Ontologie selbst steht ebenfalls auf github als eine Reihe von XML-Dateien zur Verfügung, die zur Erstellung einer Solr-Sammlung verwendet werden können. Beachten Sie jedoch, dass die Ontologie vor der Erstellung dieser Dateien bearbeitet wurde. Die Manipulationen, die ich an der Ontologie vorgenommen habe, um sie zu ‚denormalisieren‘ oder zu verflachen, werden Gegenstand eines zukünftigen Blog-Beitrags sein, da es sich um Techniken handelt, die verwendet werden können, um interessante Beziehungen ‚an die Oberfläche‘ zu bringen und sie durchsuchbar zu machen, ohne dass komplexe Graph-Abfragen erforderlich sind.
Verwendung von Facetten, um mehr Kontext über die Vorschläge zu erhalten
Der oben eingeführte Begriff „aboutness“ kann sehr mächtig sein. Sobald wir uns entschlossen haben, eine spezielle Solr-Sammlung (auch als „Sidecar“-Sammlung bezeichnet) nur für Typeahead zu erstellen, gibt es weitere leistungsstarke Suchfunktionen, mit denen wir nun arbeiten können. Eine davon sind kontextbezogene Metadaten. Diese erhalten wir, indem wir Facetten auf die Abfrage anwenden, die der Suggerator Builder verwendet, um den Vorschlag anhand der Inhaltssammlung zu validieren. Eine Anwendung davon ist die Generierung von sicherheitsrelevanten ACL-Werten für einen Vorschlag, indem wir die ACLs für alle Dokumente ermitteln, auf die ein Abfragevorschlag treffen würde – unter Verwendung von Facetten. Sobald wir diese Werte haben, können wir dieselbe Filterabfrage zur Sicherheitsbeschränkung für die Suggestor-Sammlung verwenden, die wir auch für die Inhaltssammlung verwenden. Auf diese Weise können wir einem Benutzer niemals eine Abfrage vorschlagen, die für ihn keine Ergebnisse liefern kann – in diesem Fall, weil er keinen Zugriff auf eines der Dokumente hat, die die Abfrage liefern würde. Eine weitere Möglichkeit, die wir bei der Erstellung der Suggestor-Sammlung nutzen können, ist die Verwendung von Facetten, um Kontext zu verschiedenen Vorschlägen zu erhalten. Wie im nächsten Abschnitt erläutert, können wir diesen Kontext nutzen, um Vorschläge zu verbessern, die kontextbezogene Metadaten mit kürzlich ausgeführten Abfragen teilen.
Dynamische oder fliegende prädiktive Analysen
Eine der sehr leistungsstarken und äußerst benutzerfreundlichen Möglichkeiten, die Sie mit Typeahead nutzen können, ist die Berücksichtigung kürzlich durchgeführter Abfragen. Typeahead ist einer der Anwendungsfälle, bei denen eine gute Relevanz entscheidend ist, da der Benutzer nur einige wenige Ergebnisse sehen kann und keine Facetten oder Seitenwechsel nutzen kann, um mehr zu sehen. Die Relevanz ist bei einer Suchanfrage oft dynamisch, d.h. was der Benutzer sucht, kann sich ändern – sogar im Laufe einer einzigen Sitzung. Da typeahead schon bei der Eingabe von wenigen Zeichen zu arbeiten beginnt, sind die Abfragen zunächst sehr unklar. Wenn wir die Relevanz von kürzlich gesuchten Dingen berücksichtigen können, können wir dem Benutzer eine Menge a) Arbeit und b) Ärger ersparen. Google scheint genau dies zu tun. Als ich die Beispiel-Musik-Ontologie erstellte, habe ich Google und Wikipedia (ja, ich habe dazu beigetragen!) verwendet, um nach Songs und Künstlern zu suchen und Dinge zu erfahren oder zu überprüfen, wie z.B. wer der/die Songschreiber war(en) usw. Ich stellte fest, dass Google, wenn ich mich auf einen einzelnen Künstler oder ein Genre konzentrierte, nach ein paar Suchvorgängen begann, lange Songtitel mit nur zwei oder drei eingegebenen Zeichen vorzuschlagen!!! Es war, als ob es „wüsste“, was ich suche! Ehrlich gesagt, es war etwas unheimlich, aber sehr befriedigend.
Wie können wir also ein wenig von Googles geheimer Soße in unsere eigenen Typeahead-Implementierungen einfließen lassen? Nun, der Schlüssel dazu ist Kontext. Wenn wir etwas darüber wissen, wonach der Nutzer sucht, können wir Dinge mit ähnlichen Eigenschaften besser hervorheben. Und diesen Kontext können wir mit Hilfe von Facetten erhalten, wenn wir die Vorschlagsammlung erstellen! Kurz gesagt, wir können die Werte der Facettenfelder verwenden, um Boost-Abfragen zu erstellen, die in zukünftigen Abfragen in einer Benutzersitzung verwendet werden. Der grundlegende Datenfluss ist unten dargestellt:
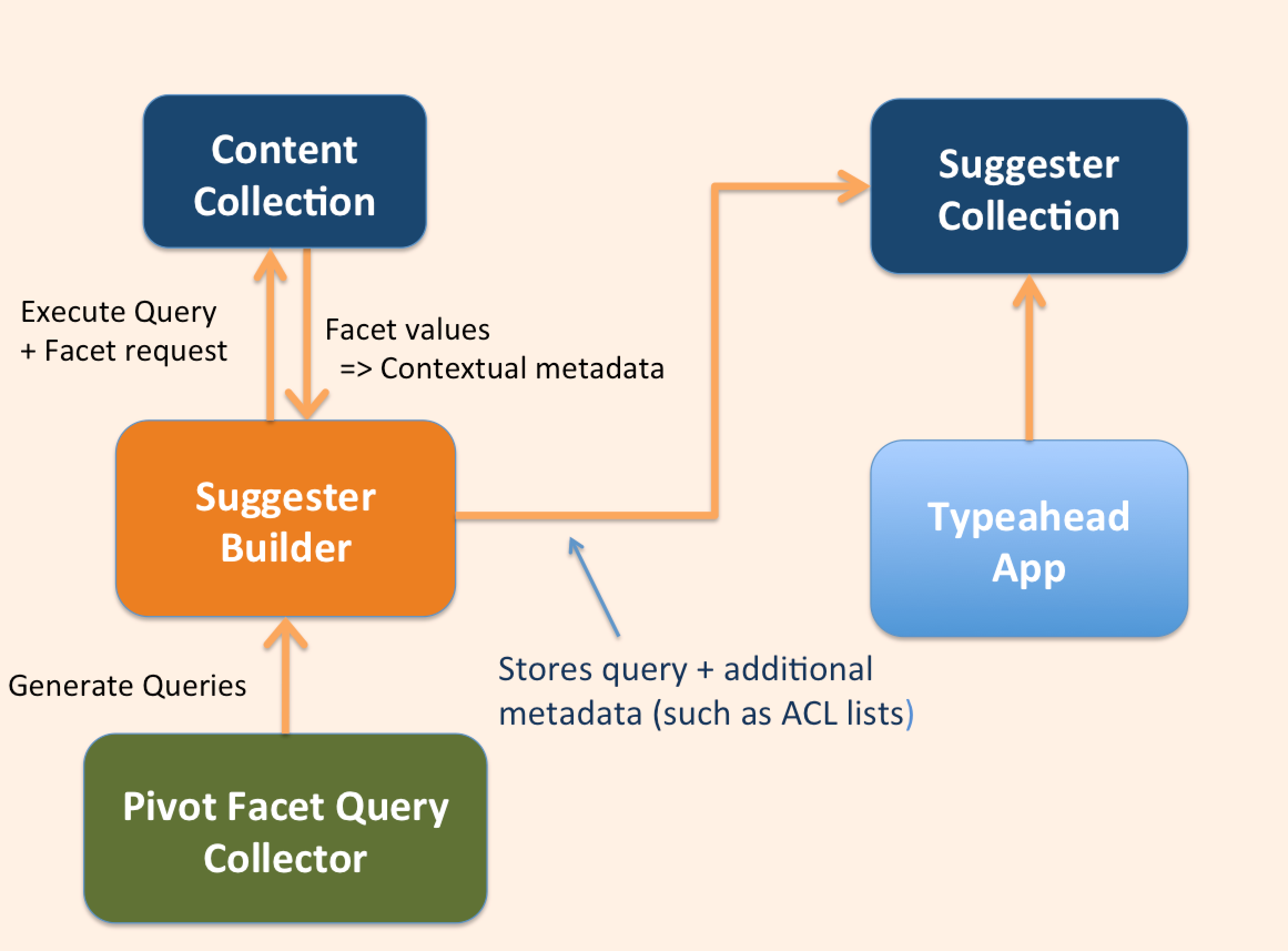
Dies erfordert eine gewisse Koordination zwischen dem Sugger-Builder und der Front-End-Suchanwendung (in der Regel auf der Basis von Javascript). Der Suggerator Builder extrahiert Kontext-Metadaten für jeden Abfragevorschlag mit Hilfe von Facetten, die er aus der Quellen- oder Inhaltssammlung erhält, und speichert diese Werte zusammen mit den Abfragevorschlägen in der Suggerter-Sammlung. Um zu demonstrieren, wie diese kontextbezogenen Metadaten in einer Typeahead-Anwendung verwendet werden können, habe ich eine einfache Angular JS-Anwendung geschrieben, die diese facettenbasierten Metadaten in der Suggester-Sammlung verwendet, um Vorschläge zu verstärken, die den kürzlich ausgeführten Abfragen ähneln. Wenn eine Abfrage aus einer Typeahead-Liste ausgewählt wird, werden die mit dieser Abfrage verknüpften Metadaten zwischengespeichert und für die Erstellung einer Boost-Abfrage bei nachfolgenden Typeahead-Aktionen verwendet.
Wenn ich also zum Beispiel den Buchstaben ‚J‘ in die Typeahead-App eingebe, erhalte ich
Jai Johnny Johanson Bands
Jai Johnny Johanson Gruppen
J.J. Johnson
Jai Johnny Johanson
Juke Joint Jezebel
Juke Joint Jimmy
Juke Joint Johnny
Aber wenn ich gerade nach ‚Paul McCartney‘ gesucht habe, bringt die Eingabe von ‚J‘ jetzt zurück:
John Lennon
John Lennon Songs
John Lennon Songs Covered
James P Johnson Songs
John Lennon Originals
Hey Jude
Die App hat etwas über meine Suchagenda gelernt! Damit dies funktioniert, speichert die Front-End-Anwendung die zurückgegebenen Metadaten für zuvor ausgeführte Suggestor-Ergebnisse in einem Cache und speichert diese in einer zirkulären Warteschlange auf der Client-Seite. Sie verwendet dann die zuletzt zwischengespeicherten Metadaten, um eine Boost-Abfrage für jede Typeahead-Übermittlung zu erstellen. Als ich also die Suche nach „Paul McCartney“ ausgeführt habe, waren die zurückgegebenen Metadaten:
genres_ss:Rock,Rock Roll,Soft Rock,Pop Rock
hasPerformer_ss:Beatles,Paul McCartney,José Feliciano,Jimi Hendrix,Joe Cocker,Aretha Franklin,Bon Jovi,Elvis Presley (… und viele mehr)
composer_ss:Paul McCartney,John Lennon,Ringo Starr,George Harrison,George Jackson,Michael Jackson,Sonny Bono
memberOfGroup_ss:Beatles,Wings
Von diesen zurückgegebenen Metadaten – unter Berücksichtigung der Top-Ergebnisse – war die gecachte Boost-Abfrage:
genres_ss: „Rock“^50 genres_ss: „Rock Roll“^50 genres_ss: „Soft Rock“^50 genres_ss: „Pop Rock“^50
hasPerformer_ss: „Beatles“^50 hasPerformer_ss:“Paul McCartney“^50 hasPerformer_ss: „José Feliciano“^50 hasPerformer_ss: „Jimi Hendrix“^50
composer_ss: „Paul McCartney“^50 composer_ss:“John Lennon“^50 composer_ss: „Ringo Starr“^50 composer_ss: „George Harrison“^50
memberOfGroup_ss: „Beatles“^50 memberOfGroup_ss: „Wings“^50
Und da John Lennon sowohl ein Komponist als auch ein Mitglied der Beatles ist, werden Platten mit John Lennon doppelt aufgewertet, weshalb diese Platten nun die Typeahead-Liste anführen. (Ich bin mir nicht sicher, warum sich James P. Johnson dort eingeschlichen hat, außer dass sein Name zwei ‚J‘ enthält).
Dies zeigt, wie leistungsfähig die Verwendung von Kontext sein kann. In diesem Fall basiert der Kontext auf den aktuellen Suchmustern des Benutzers. Eine weitere Erkenntnis ist, dass Facetten neben der traditionellen Verwendung als Navigationshilfe auf der Benutzeroberfläche eine leistungsstarke Möglichkeit sind, Kontext in eine Suchanwendung zu integrieren. In diesem Fall wurden sie auf mehrere Arten verwendet – um die Pivot-Muster für den Suggerter zu erstellen, um kontextbezogene Metadaten mit Suggerter-Datensätzen zu verknüpfen und schließlich, um diesen Kontext in einer Typeahead-Anwendung zu nutzen, um Datensätze zu fördern, die für die jüngsten Suchziele des Benutzers relevant sind. (Der Quellcode für die Angular JS-App ist ebenfalls im Github-Repository enthalten).
Wir vermissen Sie, Jimi – danke für all die großartigen Melodien! (Sie haben recht, ich habe beim Schreiben dieses Blogs Hendrix und auch die Beatles gehört – ist das so offensichtlich?)