SearchComponents, RequestHandler, Rechtschreibprüfung
Ich verbringe die meiste Zeit mit der Konfiguration von Solr in der Datei schema.xml, aber die Datei solrconfig.xml ist auch ein sehr leistungsfähiges Werkzeug. Ich wollte meine jüngsten Erfahrungen mit der Konfiguration der Rechtschreibprüfung nutzen, um einige Aspekte dieser wichtigen Datei zu überprüfen. Sicher, in der solrconfig.xml können Sie eine Reihe von banalen Dingen wie Caching-Richtlinien und Bibliotheksladepfade konfigurieren, aber sie enthält auch einige High-Tech-Konfigurations- „LEGO-Bausteine“, die Sie mischen und zu allen möglichen interessanten Solr-Setups zusammensetzen können. Die drei wichtigsten Bausteine, die ich besprechen werde:
- SearchHandlers (ein Typ von RequestHandler)
- SucheKomponenten
- Benannte Parametersätze, auch bekannt als Benannte Konfigurationen
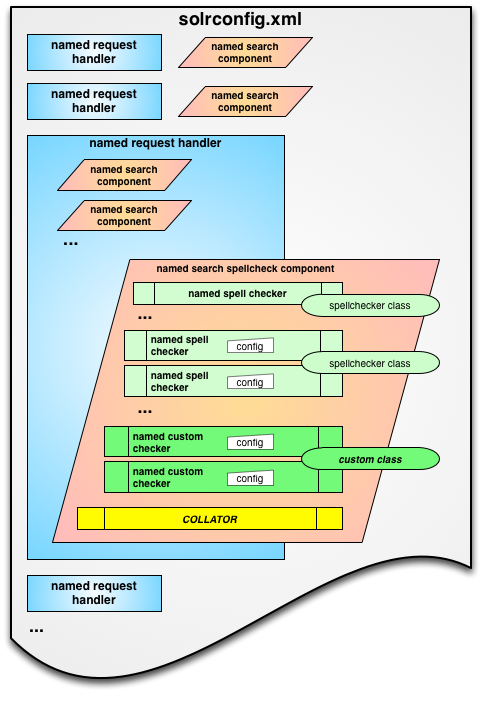
solrconfig.xml verschachtelt die Suchkomponenten (einschließlich der Rechtschreibprüfung)
unterhalb der Request Handler. Ich werde jede dieser Komponenten nach der Pause detailliert beschreiben…
RequestHandler
Im obigen konzeptionellen Diagramm sehen Sie, dass eine Reihe von RequestHandlern auf hoher Ebene definiert sind, die als blaue Rechtecke dargestellt sind. Diese definieren die wichtigsten Einstiegspunkte in Solr und enthalten einige Texte, die Sie vielleicht in den URLs wie /select, /update, /browse und /spell bemerkt haben. Request Handlers werden vom Request Dispatcher aufgerufen und sind die Container für SearchComponents. SearchHandler ist ein spezieller Typ von RequestHandler, der von besonderem Interesse sein wird.
SucheKomponenten
SearchComponents erledigen die eigentliche Arbeit, wie z.B. die eigentliche Suche (über QueryComponent), die Berechnung von Facetten, das Hervorheben übereinstimmender Begriffe oder das Hinzufügen von Vorschlägen zur Rechtschreibprüfung. Im obigen Diagramm sind dies die orangefarbenen Parallelogramme (gekippte Rechtecke).
Mehrere Suchkomponenten können innerhalb eines Suchhandlers aneinandergereiht werden. Daher kommt die Analogie mit den LEGO-Steinen. SearchHandler bestehen aus einer oder mehreren SearchComponents.
Eine Ausnahme
Erinnern Sie sich, dass ich sagte, dass das Diagramm oben konzeptionell ist? Wenn ich darauf hinweise, dass der standardmäßige /select Request Handler sechs Suchkomponenten hat (Query, Facet, mlt/MoreLikeThis, Highlight, Stats & Debug), würden Sie wahrscheinlich annehmen, dass Sie die Datei solrconfig.xml öffnen, den Search Handler finden, der sich um /select kümmert, und diese sechs Suchkomponenten genau dort definiert sehen – nun… das sind sie nicht.
Aus verschiedenen technischen und Legacy-Code-Gründen gibt es eine spezielle vordefinierte Java-Klasse namens „SearchHandler“, die standardmäßig die 6 Suchkomponenten enthält. Es handelt sich immer noch um einen Search Handler, der 6 Suchkomponenten enthält, aber er ist nicht in solrconfog.xml definiert.
Wenn Sie möchten, können Sie Ihren eigenen Suchhandler definieren und ihn so konfigurieren, dass er dieselben 6 Suchkomponenten enthält. In der Regel fügen die Benutzer zusätzliche Suchkomponenten zu den 6 bereits ausgeführten hinzu oder definieren einen Search Handler mit viel weniger Komponenten.
Rechtschreibprüfung SucheKomponenten
Die Rechtschreibprüfungs-Komponente ist ein besonders interessantes Beispiel für eine Suchkomponente, denn sie setzt sich aus weiteren Unterkomponenten zusammen, bei denen es sich um die Basisklassen für die Rechtschreibprüfung handelt. Eine Suchkomponente für die Rechtschreibprüfung kann also aus mehreren Rechtschreibprüfungsklassen bestehen (plus einem Collator, den ich später erläutern werde).
„Benannte Konfigurationen“
Der dritte Baustein der Konfiguration ist der Solr-Mechanismus für benannte Sätze von Konfigurationsdaten, die ich „Named Configs“ nennen werde. Im obigen Diagramm sind sie als kleine weiße Blöcke mit der Bezeichnung „config“ dargestellt. Wenn Sie sich die Datei solrconfig.xml schon einmal angesehen haben, werden Sie eine Menge <lst name="xyz"> XML-Strukturen gesehen haben, wobei „xyz“ ein beliebiger Name sein kann, aber oft als „default“ bezeichnet wird. Unter jeder dieser Strukturen befinden sich Sätze von Name/Wert-Paaren der Form <str name=“paramName“>param_value</str >.
Diese Named Configs sind ein allgemeines Konzept in Solr und sind nicht nur für Request Handler und Suchkomponenten spezifisch – Sie werden sie überall sehen! Und was genau bewirken diese Named Configs? Wie Sie wahrscheinlich wissen, ist Solr in Java implementiert, einer objektbasierten Sprache. Sie können mehr als eine Instanz einer Java-Objektklasse haben, und jede Instanz kann ihre eigene, individuelle Konfiguration haben. Die benannten Sätze von Konfigurationen in solrconfig.xml geben verschiedene Java-Klassen in Solr an, übergeben ihnen aber auch spezifische Sätze von Konfigurationseinstellungen. Zum Beispiel wird die FileBasedSpellChecker eine Textdatei mit Begriffen, aus der er Rechtschreibvorschläge macht. Über die Konfiguration könnten Sie eine Instanz mit dem Namen „english_dictionary“ und eine andere mit dem Namen „french_dictionary“ haben, die jeweils Begriffe aus ihrer eigenen sprachlich passenden Datei lesen. (im Wiki werden Gründe genannt, warum Sie FileBasedSpellCheckers nicht verwenden sollten, aber es ist ein sehr gutes Beispiel, um benannte Konfigurationen zu verstehen)
Im obigen Diagramm sehen Sie grüne Rechtecke, die definierte Low-Level-Rechtschreibkorrekturen darstellen, und grüne, abgerundete Rechtecke, die die eigentlichen Java-Klassen repräsentieren, auf die sie verweisen. Beachten Sie jedoch, dass es zwei Paare von grünen Rechtecken gibt, die sich gemeinsame Java-Klassen teilen. Obwohl sie auf dieselbe Klasse verweisen, enthält jede Definition ihr eigenes „config“-Modul, das die Parameter für diese spezielle Instanz festlegt.
Mögliche Named Config Verwirrung
Benannte Konfigurationen haben ein paar Dinge, die sie manchmal verwirrend machen.
Eine weitere Diskrepanz zwischen dem obigen konzeptionellen Diagramm und dem, was Sie tatsächlich in solrconfig.xml sehen, ist die Position der Named Config-Einstellungen innerhalb der Datei – normalerweise werden sie einmal definiert und dann an anderer Stelle referenziert.
Da Benannte Konfigurationen für viele verschiedene Kontexte verwendet werden, können auch mehrere Konfigurationen denselben Namen haben; dies gilt insbesondere für den Namen „default“! Sie können Standardeinstellungen für verschiedene Request Handler haben, die alle den Namen „default“ tragen.
Und noch eine Ausnahme: Wenn ein Konfigurations-Set „default“ heißt, ist das ein magischer Name, der nirgendwo anders explizit referenziert werden muss.
Ein weiterer potenziell verwirrender Aspekt dieser Namen in der Standard-Solrconfig ist, dass sie oft sehr allgemein aussehen und es für neue Benutzer nicht immer offensichtlich ist, dass es sich dabei um willkürliche Bezeichnungen handelt, die von anderen Teilen der Konfigurationsdatei referenziert werden, und nicht um ein wichtiges festes Schlüsselwort.
Die Standardkonfiguration von Solr für die oben erwähnte dateibasierte Rechtschreibprüfung heißt zum Beispiel „file“, wie in <str name="name">file</str>, und in einem anderen Teil der Beispielkonfiguration wird sie über <str name="spellcheck.dictionary">file</str> referenziert. Wenn Sie Ihre eigene Konfiguration erstellen würden, wäre es vielleicht klarer, sie „flat_file_config“ zu nennen, so dass Sie sie mit <str name="name">flat_file_config</str> definieren und über <str name="spellcheck.dictionary">flat_file_config</str> referenzieren könnten.
Um auf das frühere Beispiel mit dem englischen und französischen Wörterbuch zurückzukommen, würden Sie zwei benannte Konfigurationen „english_dictionary_file_config“ und „french_dictionary_file_config“ definieren und jede separat über den Parameter spellcheck.dictionary referenzieren. Die Eingabe dauert zwar viel länger, ist aber auf jeden Fall selbstdokumentierender, und außerdem ist Copy & Paste ja dafür da!
Und noch ein weiterer, potentiell verwirrender Hinweis, der sich auf die Rechtschreibprüfung bezieht, ist der etwas schlecht benannte Parameter spellcheck.dictionary, der verwendet wird, um auf jede Art von Unterkomponente der Rechtschreibprüfung zu verweisen, auch wenn sie nicht auf einem Wörterbuch basiert! Dies ist nur eine weitere Altlast, die Sie im Auge behalten müssen.
Um zum Beispiel auf die Konfiguration für die sehr nützliche WordBreakSolrSpellChecker zu referenzieren, würden Sie <str name="spellcheck.dictionary">wordbreak</str> sagen.
Und noch eine kleine Verwirrung zu Named Configs in Bezug auf die Rechtschreibprüfung: Normalerweise sollten Named Configs, die im gleichen Kontext verwendet werden, unterschiedliche Namen haben. Aber im Fall der Rechtschreibprüfung gibt es mehrere Konfigurationen mit dem Namen „spellchecker“, und das ist Absicht und eine gute Sache! Dies ist das name-Attribut; aber jede hat auch ein <str> Unterelement, das ebenfalls name heißt und die Konfigurationsgruppe benennt.
Zum Beispiel:
[code language=“xml“ highlight=“2,5,8″] <lst name=“spellchecker“> <str name=“name“>default</str> … <lst name=“spellchecker“> <str name=“name“>wordbreak</str> … <lst name=“spellchecker“> <str name=“name“>jarowinkler</str> … [/code]
Dies zu entschlüsseln:
- Die oberste Ebene
<lst>ist der Container für die benannte Konfiguration und hat das XML-Attribut „name“. Dieses wird für die interne Abfrage des XML-Baums verwendet und sollte nicht geändert werden. - Die verschachtelten
<str>Elemente sind die Name/Wert-Paare. In Pseudocode würden wirfoo=barsagen, aber in der Solr XML-Syntax wäre es<str name="foo">bar</str>. Konzeptionell könnten wir späterprint myConfig.foosagen und es würde „bar“ ausgedruckt werden. - Ich habe bereits erwähnt, dass benannte Konfigurationen beliebige Namen haben können. In diesem Beispiel definieren wir drei Namen: „default“, „wordbreak“ und „jarowinkler“. Diese werden durch ein
<str>Unterelement namens „name“ registriert, dessen Wert der Name ist, den wir tatsächlich registrieren wollen. Denken Sie noch einmal in Pseudocode: Anstattfoo=barzu sagen, wollen wir jetztname=wordbreaksagen. Anstelle von<str name="foo">bar</str>haben wir also<str name="name">wordbreak</str>. Es ist nur ein seltsam anmutender Syntax-Zufall, dass wirname="name"innerhalb des<str>Tags sehen. - Solr sammelt alle
<lst>Elemente mit dem Attribut name spellchecker und legt sie nach dem Namen ab, der durch den Wert des<str>Unterelements namens „name“ definiert ist. Auf dieses Element wird später über spellcheck.dictionary mit dem Namen referenziert.
Wenn Sie verwirrt sind, sehen Sie sich einige Beispiele für solrconfig.xml an, dann wird es vielleicht klarer. Es gibt hier eine Logik und der XML-Mechanismus bietet eine wirklich leistungsstarke Möglichkeit, das Verhalten von Solr zu ändern, ohne dass Sie immer einen Java-Compiler hervorholen müssen.
Die Bedeutung des Collators
Der Collator kombiniert alle rohen Rechtschreibvorschläge aus allen Klassen der Rechtschreibprüfung auf niedriger Ebene, führt einige Filterungen durch und erstellt dann vollständig umgeschriebene Abfragen, die als anklickbare Links in der Ergebnisliste angezeigt werden können oder als dynamische Autovervollständigungsvorschläge, während der Benutzer in das Suchfeld eingibt.
Die Low-Level-Klassen für die Rechtschreibprüfung arbeiten in der Regel wortweise, auch wenn die Abfrage des Benutzers mehrere Wörter enthält; sie liefern lediglich Low-Level-Vorschläge für jedes einzelne Wort. Da einige der Klassen für die Rechtschreibprüfung auf niedriger Ebene nicht einmal Ihren Solr-Index durchsuchen, können sie sehr wohl alternative Wörter vorschlagen, die in Ihren Dokumenten gar nicht existieren! Aber das ist in Ordnung, denn diese Low-Level-Klassen sind von vornherein einfach gehalten, sie machen nur Vorschläge für Kandidaten. Konfigurierte Rechtschreibprüfungen dürfen mehrere Low-Level-Klassen zur Rechtschreibprüfung aufrufen, um möglicherweise eine große Anzahl von Vorschlägen zu erhalten.
Es ist die Aufgabe des Collators, all diese Vorschläge zu kombinieren und dann zu sichten, indem er den Hauptindex von Solr überprüft. Beachten Sie, dass es auch in Ordnung ist, wenn mehr als eine Rechtschreibprüfung dieselbe alternative Schreibweise vorschlägt; der Collator kümmert sich auch darum! Er weiß, wie er alle Kandidaten kombinieren und entduplizieren kann.
Die Überprüfung des Indexes nimmt zwar etwas zusätzliche Zeit in Anspruch, da zusätzliche Suchvorgänge für diese Überprüfungen generiert werden, aber in einem gut funktionierenden System dauert dies nur ein paar zusätzliche Millisekunden. Der Collator entscheidet dann unter allen möglichen Wort-für-Wort-Korrekturen, welche neu zusammengesetzten Abfragen den besten Vorschlag ergeben würden.
Wenn man die Low-Level-Rechtschreibprüfung mit dem Collator vergleicht, nimmt man an, dass ein Benutzer Folgendes eingibt „helllo worlld“ (beide falsch geschrieben). Rechtschreibprüfungen auf niedriger Ebene betrachten oft jedes Wort einzeln. So könnte „helllo“ die Kandidaten „hello“, „halo“ und „hellion“ erzeugen; und „worlld“ könnte die Kandidaten „world“, „would“, „wold“ und „worldly“ erzeugen. Aber wenn man den Standardinhalt von Solr annimmt, ergeben nur „hello“ und „world“ wirklich einen Sinn.
Und denken Sie daran, dass die Abfrage eigentlich aus zwei Wörtern bestand, nicht aus einem, so dass wir nicht einfach „Hallo“ oder „Welt“ vorschlagen wollen. Aber der Collator findet das alles heraus und liefert den korrekten Zwei-Wort-Vorschlag „Hallo Welt“. Sehr cool!
Diese Art der Aufgabenteilung (Vorschläge auf niedriger Ebene gegenüber einer endgültigen Zusammenstellung der am besten umgeschriebenen Suchanfragen) ist wirklich gut, denn Sie können andere benutzerdefinierte Rechtschreibprüfungen hinzufügen und trotzdem dafür sorgen, dass der Collator von Solr Ihre „kreativeren“ Rechtschreibvorschläge nicht an die Benutzer weitergibt. Wenn Sie viele Inhalte hätten, wäre vielleicht auch „halo wold“ (beides gültige englische Wörter) ein vernünftiger Vorschlag gewesen. Und mit dem Collator können Sie entscheiden, wie viele Kandidaten Sie ausprobieren möchten, wie viele Vorschläge Sie präsentieren möchten, wie häufig ein Wort vorkommen muss, damit es als richtig oder falsch angesehen wird, usw. Sehr cooles Zeug.
Zusammenfassung
Erinnern Sie sich an die primären Bausteine in solrconfig.xml: SearchHandlers enthalten SearchComponents, die mit Named Config Blocks definiert sind, die auf Java-Klassen verweisen. Sie können die SearchComponents dann bei Bedarf in mehreren SearchHandlers referenzieren.
Für Rechtschreibvorschläge gibt es Rechtschreibprüfungen auf niedriger Ebene, die für jedes einzelne Wort alternative Schreibweisen vorschlagen. Es ist die Aufgabe des Collators, diese Kandidaten zu tabellarisieren, zu deduplizieren und mit dem eigentlichen Suchindex abzugleichen, um dann eine oder mehrere gültige und vollständige Abfragen zu erstellen.
Einige JIRA-Probleme, auf die Sie achten sollten: Wenn Sie Solr 4.3 oder höher verwenden, sollte alles in Ordnung sein. Wenn Sie jedoch frühere Versionen verwenden, sollten Sie wissen, dass die Solr-Beispielanwendung einige Konfigurations- und Vorlagenprobleme hatte, die verhinderten, dass Spellcheck sofort funktioniert. Siehe JIRA Bugs SOLR-4680,SOLR-4681 undSOLR-4702.