Verwenden Sie Fusion + thematische Abfragen für die Überwachung von Sammlungen und für Warnmeldungen
Übersicht
Lucidworks Fusion bietet eine Reihe von APIs, die zur Abfrage, Aktualisierung und sonstigen Interaktion mit Apache Solr verwendet werden können. Für viele neue Funktionen von Solr gibt es jedoch noch keine direkte Unterstützung innerhalb der Fusion-Pipeline-Stufen. Die neue Streaming Expressions API in Solr 6.2+ verfügt beispielsweise über Quellen für JDBC/SQL-Abfragen, verteiltes Graphentraversal, maschinelles Lernen und paralleles iteratives Modelltraining, Themenabfragen und mehr. In den Blogs von Joel Bernstein unter solrj.io finden Sie einige der Möglichkeiten, die sich mit den Streaming Expressions von Solr realisieren lassen .
Die Streaming-Ausdrücke von Solr
Seit der Version 6.0 bietet Apache Solr zunehmend Unterstützung für Streaming Expressions. Eine der Fähigkeiten von Streaming Expressions ist die so genannte Topic Query. Einfach ausgedrückt ist eine Themenabfrage ein Mechanismus, der jede Abfrage eines bestimmten Themas verfolgt und nur Ergebnisse zurückgibt, die neuer sind als die, die zuvor für dieses Thema abgefragt wurden. Auf diese Weise können Sie auf einfache Weise eine Abfrage wiederholt durchführen, erhalten aber nur Ergebnisse, die Sie zuvor noch nicht gesehen haben.
Mögliche Anwendungsfälle
Was soll ein Website-Administrator tun, wenn er betriebliche Informationen sammeln muss, aber keine praktische API hat, die die benötigten Informationen liefert? In den Protokollen können von Zeit zu Zeit Hinweise gefunden werden, aber die ständige Überprüfung der Protokolle kann mühsam sein. Eine geplante Themenabfrage kann helfen! Betrachten Sie folgende Beispiele:
Sie haben eine Solr-Abfrage, die Sie nach erfolgreicher Ausführung einer Fusion-Datenquelle ausführen möchten, um wichtige Statistiken über diese Datenquelle zu sammeln und zu melden. Wenn ein Crawl der Datenaufnahme abgeschlossen ist, wird eine einfache Meldung „FINISHED“ zusammen mit den Namen der Sammlung und der Datenquelle wie folgt protokolliert.
2017-03-07T10:00:03,554 - INFO [com.lucidworks.connectors.ConnectorJob, id=important-datasource:JobStatus@294] - {collectionId=enterprise-search, datasourceId=important -datasource} - end job id: important-datasource took 00:00:03.429 counters: deleted=0, failed=0, input=1, new=0, output=1, skipped=0 state: FINISHED
Ein Schwesterunternehmen, das regelmäßig Daten zur Aufnahme in Fusion liefert, hat in der Vergangenheit fehlerhafte Daten gesendet. Das Ergebnis ist, dass einige Datensätze nicht übernommen werden. Das Problem rührt von einem Fehler bei der Datensammlung auf ihrer Seite her, der zu einem sehr langen Datenfeld führt. Die Organisation, die das Problem verursacht hat, meldet, dass sie das Problem behoben hat, bittet Sie aber, sie zu benachrichtigen, wenn das Problem erneut auftritt. Im Folgenden sehen Sie ein Beispiel dafür, wie dieser Fehler im Protokoll aussieht.
ERROR (qtp606548741-61861) o.a.s.h.RequestHandlerBase org.apache.solr.common.SolrException: Exception writing document id Research-112885-334 to the index; possible analysis error: Document contains at least one immense term in field="entity_desc_s" (whose UTF8 encoding is longer than the max length 32766), all of which were skipped.
Die Operations-Abteilung möchte benachrichtigt werden, wenn Sie eine Website crawlen, die keine robots.txt-Datei zur Kontrolle der Crawl-Rate verwendet. Sie crawlen jeden Monat Tausende von Websites und diese ändern häufig ihre Einstellungen. Wenn Sie jedoch eine Website ohne robots.txt-Einrichtung crawlen, erhalten Sie die folgende Meldung in der Protokolldatei.
WARN [test-fetcher-fetcher-4:RobotsTxt@81] - {} - http://www.SampleServer.com:80 has no robots.txt, status=404, defaulting to ALLOW-ALL
Die Möglichkeiten, die sich mit den in diesem Tutorial vorgestellten Techniken ergeben, sind vielfältig. Um den Umfang auf ein vernünftiges Maß zu beschränken, wird sich dieses Tutorial jedoch auf das oben erwähnte Beispiel der fehlenden robots.txt konzentrieren. Natürlich können Sie mit ähnlichen Schritten jedes der oben genannten Probleme und auch viele andere lösen.
Die Schritte sind wie folgt:
- Entwickeln Sie eine thematische Abfrage, die die zu überwachende Bedingung oder den zu überwachenden Zustand identifizieren kann. Z.B. das Crawlen einer Website, die keine robots.txt-Datei hat.
- Konfigurieren Sie den SMTP-Nachrichtendienst für den Versand von E-Mails aus einer Pipeline-Stufe. Dies muss nur einmal für eine bestimmte Fusion-Instanz durchgeführt werden
- Lösen Sie die Themenabfrage aus einer Pipeline-Phase heraus aus. Es kann entweder eine Index- oder eine Abfrage-Pipeline verwendet werden, je nachdem, was für Ihren Anwendungsfall am besten geeignet ist.
- Formatieren Sie die Ergebnisse der Themenabfrage (falls vorhanden) in eine Nachricht und speichern Sie die Nachricht im Pipeline-Kontext
- Senden Sie die Nachricht (falls vorhanden) aus dem Pipeline-Kontext über eine Messaging Stage.
Schritt 1. Entwickeln Sie eine thematische Abfrage
Der folgende Screenshot zeigt, wie eine Topic-Abfrage für eine Protokollnachricht in Solr eingerichtet werden könnte. Es kann schwierig sein, die Abfrage- und Themenparameter richtig einzustellen. Daher kann es hilfreich sein, dies mit dem Solr Streaming Expression Tool zu modellieren. Sobald bekannt ist, dass die Abfrage wie erwartet funktioniert, kann sie entweder in eine Fusion Index- oder Abfrage-Pipelinestufe eingebettet werden. Darüber hinaus kann der Fusion Scheduler dazu verwendet werden, die Pipeline so oft wie nötig auszuführen, um eine bestimmte Warnbedingung kontinuierlich zu überwachen.
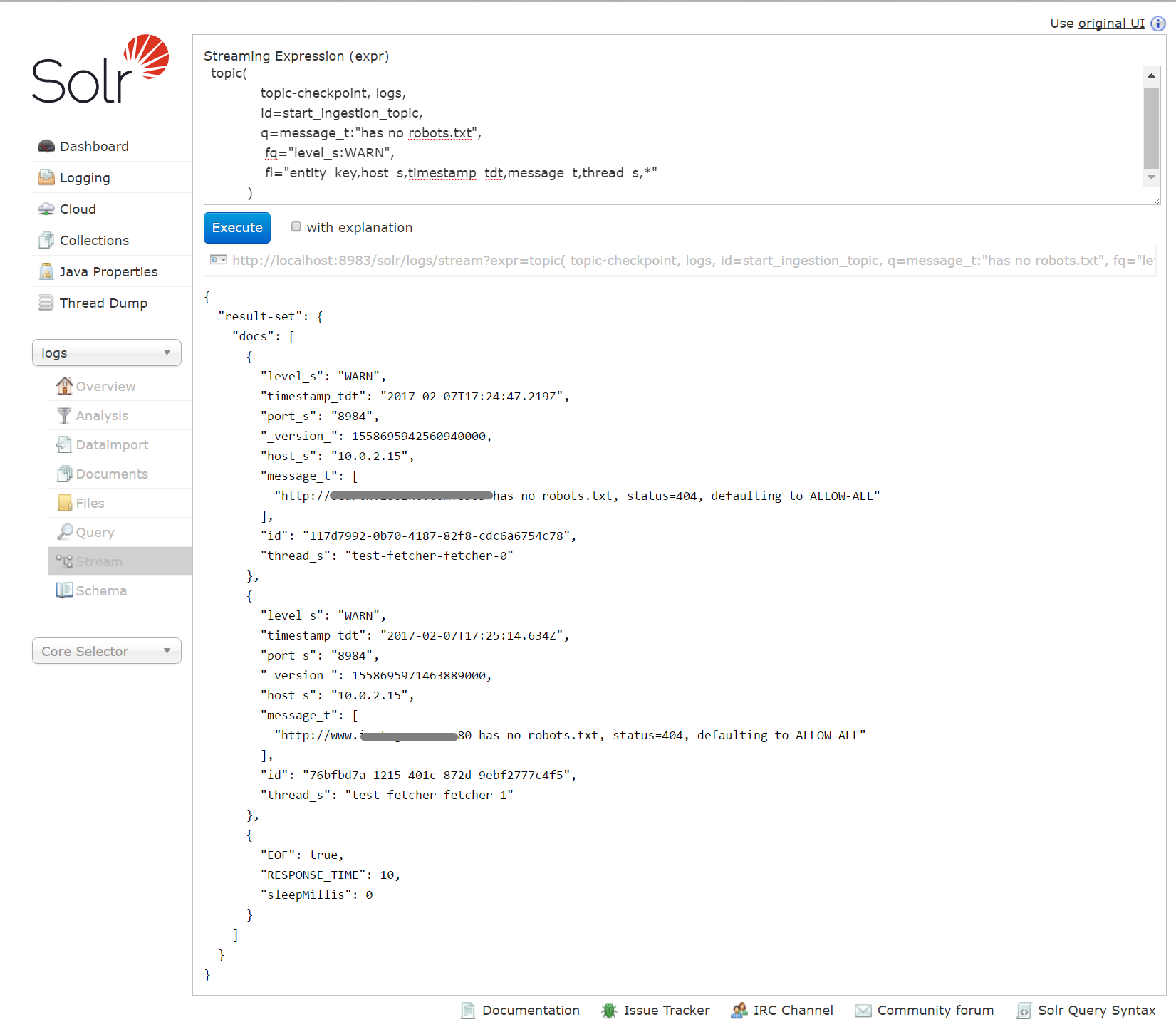
Ein paar Dinge sind zu beachten:
- Die Bedeutung der ersten drei Parameter der Themenabfrage ist vielleicht nicht offensichtlich. Sie lauten:
- Die Sammlung, in der der Status der Themenabfrage protokolliert wird, d.h. topic-checkpoint. Diese Sammlung kann einfach mit Fusion erstellt werden, muss aber vorhanden sein, wenn die Themenabfrage eingereicht wird. Sie wird vom Solr Streaming Expression Mechanismus verwendet, um zu verfolgen, wann ein bestimmtes Thema abgefragt wird.
- Die Sammlung, die abgefragt werden soll, d.h. die Protokolle
- Ein eindeutiger Themenname. Verwenden Sie jeden beliebigen Namen, aber verwenden Sie ihn konsequent.
- Die Felder in der Sammlung Logs unterscheiden sich zwischen Fusion 2.4.x und 3.0, so dass die Feldliste (fl-Parameter) in der Abfrage möglicherweise entsprechend angepasst werden muss.
- Die Ergebnismenge der Themenabfrage folgt nicht dem bekannten response.docs Format, das vom select handler von Solr verwendet wird. Dies hat unter anderem zur Folge, dass die Ergebnisse der Themenabfrage in Fusion zwar bearbeitet und an die Messaging-API gesendet werden können, das Hinzufügen dieser Ergebnisse zum Standard-Antwortobjekt in einer Query Pipeline jedoch nicht automatisch erfolgt. In diesem Tutorial veröffentlicht die Abfrage-Pipeline nicht direkt im Antwortobjekt, so dass sie keine Ergebnisse erzeugt, die auf der Fusion-Suchseite angezeigt werden können. Wenn ein Benutzer die Ergebnisse der Themenabfrage sowohl in einer E-Mail als auch auf der Seite Fusion Search veröffentlichen möchte, müssen sie in das Antwortobjekt der Pipeline übertragen werden.
- Der letzte Datensatz der Ergebnismenge markiert das Ende der Antwort. Ein ähnlicher „EOF“-Datensatz wird immer zurückgegeben, auch wenn die Themenabfrage keine neuen Datensätze gefunden hat.
- Denken Sie daran, dass eine Themenabfrage festhält, was für ein bestimmtes Thema bereits veröffentlicht wurde und nur einmal ein bestimmtes Ergebnis zurückgibt. Wenn Sie Ihre Abfrage verfeinern oder anderweitig eine Themenabfrage testen möchten, müssen Sie Datensätze aus der Checkpoint-Sammlung löschen, um den Status des Themas zurückzusetzen.
Schritt 2, Konfigurieren Sie den SMTP-Nachrichtendienst
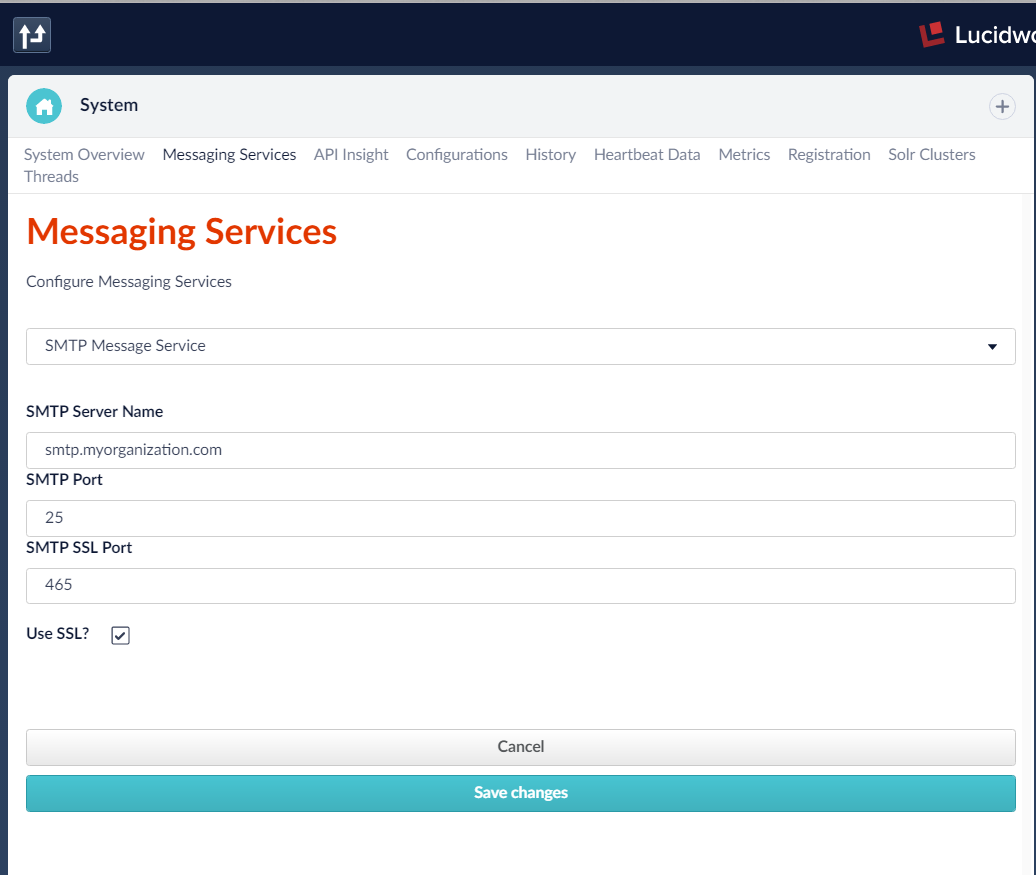
Der Fusion Messaging-Dienst wird über die Seite System im Anwendungsmenü in Fusion 2.4.x oder im DevOps Home Menü in 3.0 konfiguriert. Beachten Sie, dass auch Messaging-Dienste für Slack (Textnachrichten) und Paging-Dienste konfiguriert werden können. Der Dienst Logging Message kann ohne Konfiguration verwendet werden. Weitere Informationen und Beispiele für die Verwendung von Messaging-Stufen für Alerts finden Sie in diesem technischen Artikel.
Klicken Sie auf der Seite System auf die Registerkarte Messaging Services und geben Sie die erforderliche Konfiguration ein. Je nach verwendetem SMTP-Server müssen möglicherweise die Port- und SSL-Optionen angepasst werden. Erkundigen Sie sich bei Ihrem E-Mail-Anbieter nach den Einzelheiten. Wenn Sie den SMTP-Nachrichtendienst nicht einrichten können, können Sie dieses Lernprogramm auch mit dem Protokollierungsdienst durchführen. Der Unterschied besteht darin, dass Ihre Warnmeldung in die Protokolldatei geschrieben und nicht in einer E-Mail veröffentlicht wird.
Schritte 3 und 4, Auslösen einer Themenabfrage über eine Stufe der Fusion-Pipeline und Formatieren der Ergebnisse in eine Nachricht
Seit der Version 3.0 unterstützt Fusion keine direkten Abfragen an den Solr Stream Handler. Aus diesem Grund müssen Streaming-Ausdrücke wie Themenabfragen über eine JavaScript-Phase ausgeführt werden. Im folgenden Beispiel werden Informationen aus einer Themenabfrage über einen HTTP-GET-Aufruf abgerufen und dann über eine SMTP-Nachrichten-Pipelinestufe veröffentlicht.
Die Phase der JavaScript-Pipeline
Der Großteil der Arbeit, sowohl beim Starten der Themenabfrage als auch beim Formatieren einer geeigneten Nachricht aus den Abfrageergebnissen, wird in einer JavaScript-Pipeline-Stufe erledigt. Das vollständige Skript finden Sie am Ende dieses Tutorials. Im Folgenden finden Sie vereinfachte Versionen der wichtigsten Funktionen.
function buildTopicQueryUrl(serverName, topicQuery){
var uriTemplate = '/{collection}/{requestHandler}';
var uri = 'http://' + serverName + ':8983/solr' + UriBuilder.fromPath(uriTemplate).build(collection,'stream').toString();
uri += ('?wt=json' + '&expr=' + encodeURI(topicQuery));
return uri;
}
Die Funktion buildTopicQueryUrl nimmt einfach einen topicQuery String und formatiert ihn in eine URL, die für die Abfrage von Solr geeignet ist.
function queryHttp2Json(url){
var client = HttpClientBuilder.create().build();
var request = new HttpGet(url);
var rsp = client.execute(request);
var responseString = IOUtils.toString(rsp.getEntity().getContent(), 'UTF-8');
return JSON.parse(responseString);
}
Die Funktion queryHttp2Json führt eine einfache HTTP-GET-Anfrage für eine bestimmte URL durch. Die Ergebnisse werden in ein JSON-Objekt geparst. Der Einfachheit halber wird eine Antwort mit einem JSON-formatierten UTF-8-String angenommen.
function main(request, response ){
'use strict';
var alertMessage = '';
var topicQuery_3_0 = 'topic(' +
'topic-checkpoint,logs,id=start_ingestion_topic,' +
'q=message_t:"has no robots.txt",' +
'fq=level_s:WARN’, +
'fl="level_s,host_s,timestamp_tdt,message_t,thread_s")';
try {
var url = this.buildTopicQueryUrl('localhost',topicQuery_3_0); //Line 12
var json = this.queryHttp2Json(url); //Line 13
}catch(err){
logger.error("Error querying solr " + err);
}
//only process result-set elements containing a message_t field
if(json && json['result-set'] && json['result-set'].docs && //Line 19
Array.isArray(json['result-set'].docs) &&
json['result-set'].docs[0].message_t
){
var docs = json['result-set'].docs;
alertMessage += 'Top ' + (docs.length -1)+ ' are:n';
//process all records except the last last one (EOF)
for(var i = 0; i < docs.length; i++){ //Line 28
// loop thru records and format the alertMessage
…
}
//set this in the pipeline for publication by an alert stage
ctx.put('scriptMessage',alertMessage); //Line 103
}
};
Die Hauptfunktion ruft buildTopicQueryUrl() und queryHttp2Json() in den Zeilen 12 und 13 auf. In den Zeilen 19-22 wird geprüft, ob die Ergebnisse die erwartete Struktur enthalten, und in Zeile 28 beginnt der Prozess der Schleifenbildung durch die JSON-Ergebnisse. Der Kürze halber wird die Schleife für die einzelnen Nachrichten zur Formatierung der alertMessage weggelassen. In Zeile 103 wird die alertMessage schließlich in das Pipeline-Kontextobjekt eingefügt, so dass sie von einer Stufe abgeholt werden kann, die die Nachricht veröffentlicht.
Schritt 5, Veröffentlichen Sie die Nachricht
Wenn die JavaScript-Stufe neue Protokolleinträge findet, die der Themenabfrage entsprechen, wird eine scriptMessage in den Pipeline-Kontext gestellt. Die Prüfung auf diese Nachricht im Bedingungsblock der Nachrichtenstufe stellt sicher, dass nur neu entdeckte Nachrichten veröffentlicht werden. Der folgende Screenshot zeigt diese Prüfung im Skriptblock Bedingung sowie Beispielwerte, die zum Ausfüllen des Textkörpers einer Pipelinestufe E-Mail senden verwendet werden.
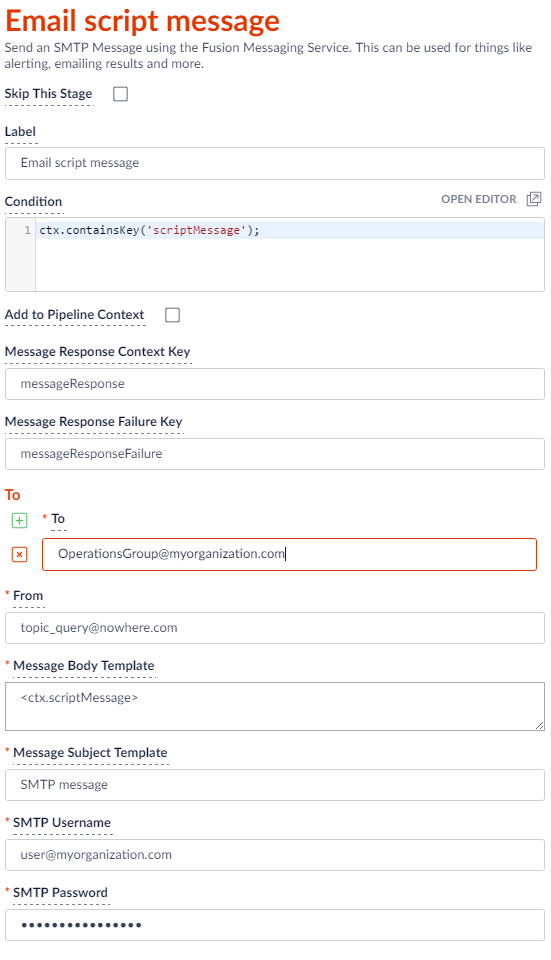
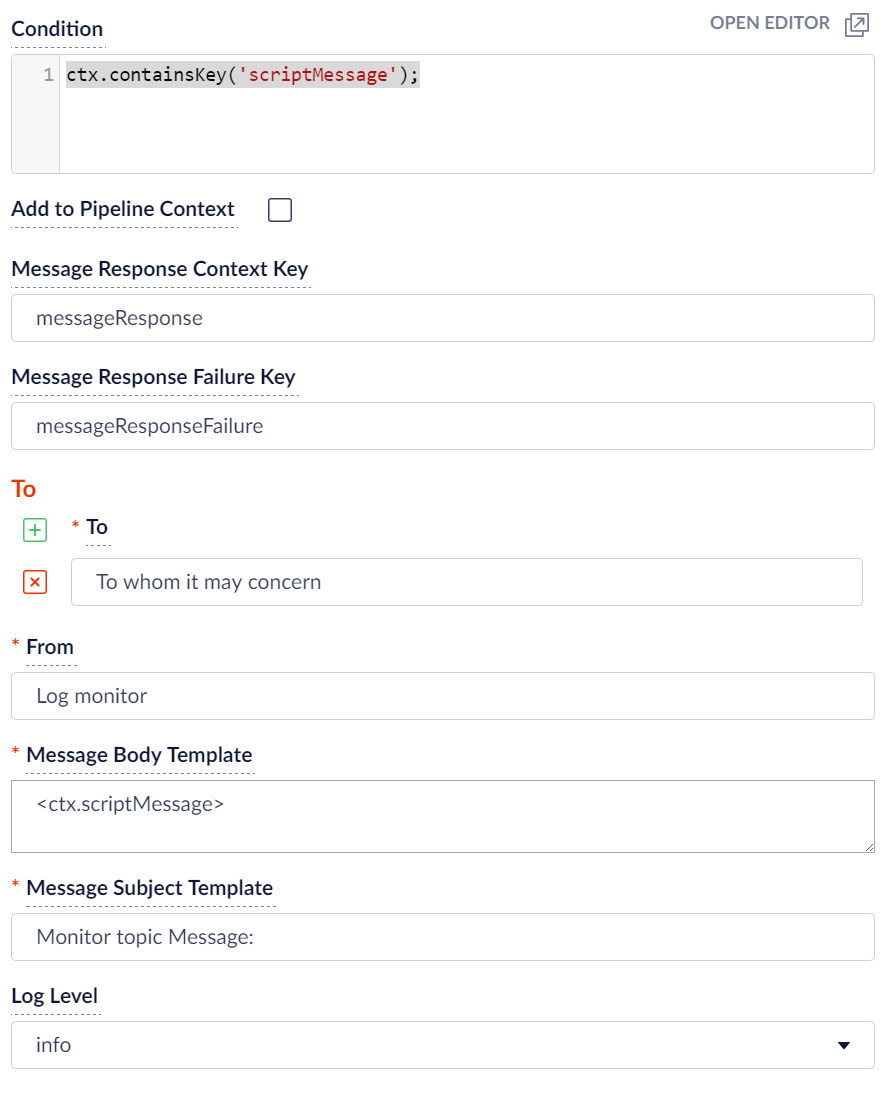
Wenn Sie anstelle der Pipeline-Stufe E-Mail senden die Stufe Nachricht protokollieren verwenden, sieht Ihre Stufe wie folgt aus.
Fazit
Im Abschnitt Übersicht wurden mehrere mögliche Verwendungszwecke für thematische Abfragen vorgestellt. Eine davon – die Notwendigkeit, die Betriebsabteilung zu benachrichtigen, wenn Websites gecrawlt werden, die keine robots.txt-Datei haben – wurde für dieses Tutorial herausgegriffen. Dies wurde durch eine Kombination aus einer JavaScript-Phase und einer Alerting-Phase bewerkstelligt. Die JavaScript-Stufe verwendete eine thematische Abfrage, um neue Protokolleinträge zu finden, die auf eine fehlende robots.txt-Datei hinweisen, und formatierte diese Protokolleinträge in eine Nachricht, die von der Alerting-Stufe veröffentlicht wurde. Ganz allgemein zeigt dieses Beispiel, wie Sie automatisch eine formatierte Benachrichtigung veröffentlichen können, sobald eine wichtige Protokollmeldung von Fusion geschrieben wird. Da eine thematische Abfrage keine zuvor abgefragten Ergebnisse meldet, können thematische Abfragen immer wieder ausgeführt werden und liefern erst dann nicht gemeldete Ergebnisse, wenn neue Daten in die Zielsammlung geschrieben wurden. Damit sind Themenabfragen ideale Kandidaten für die Ausführung durch den Fusion-Scheduler, um den Zustand einer Fusion-Installation kontinuierlich zu überwachen.
/*jshint strict: true */
/**
* JavaScript query pipeline stage called by com.lucidworks.apollo.pipeline.query.stages.JavascriptQueryStage
*
*
*/
// list known globals so that jshint will not complain.
/* globals Java, id, logger, context, ctx, params, request,response,collection,solrServer,solrClientFactory, arguments */
var _this = {};// jshint ignore:line
var invocationArgs = Array.prototype.slice.call(arguments);
//log level set in /apps/jetty/connectors/resources/log4j2.xml e.g.
logger.debug('*************************** JSCrawler QUERYPIPELINE *************');
var LinkedHashSet = Java.type('java.util.LinkedHashSet');
var LinkedHashMap = Java.type('java.util.LinkedHashMap');
var JavaString = Java.type('java.lang.String');
var ArrayList = Java.type('java.util.ArrayList');
var UriBuilder = Java.type('javax.ws.rs.core.UriBuilder');
var HttpClientBuilder = Java.type('org.apache.http.impl.client.HttpClientBuilder');
var HttpGet = Java.type('org.apache.http.client.methods.HttpGet');
var IOUtils = Java.type('org.apache.commons.io.IOUtils');
/**
* add functions as needed then return results of crawl()
*/
_this.getTypeOf = function getTypeOf(obj){
'use strict';
var typ = 'unknown';
//test for java objects
if(obj && typeof obj.getClass === 'function' && typeof obj.notify === 'function' && typeof obj.hashCode === 'function'){
typ = obj.getClass().getName();
}else{
typ = obj ? typeof obj :typ;
}
return typ;
};
_this.buildTopicQueryUrl = function(serverName, topicQuery){
var uriTemplate = '/{collection}/{requestHandler}';
//logger.info('Querying Solr for topicQuery : ' + topicQuery);
var url = 'http://' + serverName + ':8983/solr' + UriBuilder.fromPath(uriTemplate).build(collection,'stream').toString();
url += ('?wt=json' + '&expr=' + encodeURI(topicQuery));
return url;
}
/**
* Perform an HTTP GET request for a URL and parse the results to JSON.
* Note: for example simplicity we assume the response holds a JSON formatted UTF-8 string.
*/
_this.queryHttp2Json = function(url){
//logger.info('BUILDING HTTP REQUEST : ' );
var client = HttpClientBuilder.create().build();
var request = new HttpGet(url);
//logger.info('SUBMITTING HTTP REQUEST : ' + url);
var rsp = client.execute(request);
//logger.info('MESSAGE gpt resp: ' + rsp );
var responseString = IOUtils.toString(rsp.getEntity().getContent(), 'UTF-8');
//logger.info('PARSING JSON from ' + responseString);
var json = JSON.parse(responseString);
return json;
}
/**
*
*/
_this.process = function process(request, response ){
'use strict';
var alertMessage = '';
var topicQuery_2_4 = 'topic(' +
'topic-checkpoint,logs,id=start_ingestion_topic,' +
'q=message_t:"has no robots.txt",' +
'fq="ctx_collectionId_s:' + collection +
' AND ctx_datasourceId_s:*",' +
'fl="host_s,timestamp_tdt,message_t,ctx_collectionId_s" )';
var topicQuery_3_0 = 'topic(' +
'topic-checkpoint,logs,id=start_ingestion_topic,' +
'q=message_t:"has No robots.txt",' +
'fq=level_s:WARN,'+
'fl="level_s,host_s,timestamp_tdt,message_t,thread_s",' +
'initialCheckpoint=0 )';
try {
var url = this.buildTopicQueryUrl('localhost',topicQuery_3_0);
var json = this.queryHttp2Json(url);
}catch(err){
logger.error("Error querying solr " + err);
}
if(json && json['result-set'] && json['result-set'].docs &&
Array.isArray(json['result-set'].docs) && //this much should always be there
json['result-set'].docs[0].message_t // if "empty" we shouldn't have a dataSource
){
/*
An "empty" response looks like this EOF record and experimentation shows it to be in every response
{"result-set":{"docs":[
{"EOF":true,"RESPONSE_TIME":29,"sleepMillis":1000}]}}
*/
var docs = json['result-set'].docs;
alertMessage += 'Top ' + (docs.length -1)+ ' are:n';
/* Unlike Fusion 2.4.x the 3.0 result does not have datasource or collection fields.
{
"level_s": "WARN",
"timestamp_tdt": "2017-02-07T17:24:47.219Z",
"port_s": "8984",
"_version_": 1558695942560940000,
"host_s": "10.0.2.15",
"message_t": [
"http://foobar.com:8983 has no robots.txt, status=404, defaulting to ALLOW-ALL"
],
"id": "117d7992-0b70-4187-82f8-cdc6a6754c78",
"thread_s": "test-fetcher-fetcher-0"
}
*/
//process all records except the last one which should be the EOF record
for(var i = 0; i < docs.length; i++){
var doc = docs[i];
//filter out the EOF record by only acccepting docs containing a message_t
if(doc && doc.message_t ) {
alertMessage += 'ttimestamp_tdt: ' + doc.timestamp_tdt + 'n';
if(doc.ctx_datasourceId_s) {
alertMessage += 'tctx_datasourceId_s: ' + doc.ctx_datasourceId_s + 'n';
}
if(doc.thread_s) {
alertMessage += 'tthread_s: ' + doc.thread_s + 'n';
}
var messages = doc.message_t; //message_t is an Array type
if (messages && messages.length) {
alertMessage += 'tmessage lines: n';
for (var n = 0; n < messages.length; n++) {
var msg = messages[n];
alertMessage += 'tMsg:' + (n + 1) + 't :' + msg + 'n';
}
}
}
}
//set this in the pipeline so that the alert stage can publish it
ctx.put('scriptMessage',alertMessage);
logger.info('publishing scriptMessage as ' + alertMessage);
}
};
//invoke the 'main' function when wrapper is called
var returnValue = _this.process.apply(_this,invocationArgs);
//the crawler.fetch.impl.script.JavascriptFetcher expect the last line to be a return value.
returnValue;// jshint ignore:line
Andrew Shumway ist Senior Software Engineer bei Polaris Alpha und Berater für Lucidworks, wo er Suchanwendungen für Unternehmen entwickelt.