Verwendung von Solr Tagger zur Verbesserung der Relevanz
Volltextdokumente und Benutzeranfragen enthalten in der Regel Verweise auf Dinge, die wir bereits kennen, wie Namen von Personen, Orten, Farben, Marken und andere bereichsspezifische Konzepte. Viele Systeme übersehen diese wichtigen, expliziten und spezifischen Informationen und behandeln den Korpus am Ende nur als eine Ansammlung von Wörtern. Das Erkennen und Extrahieren dieser wichtigen Entitäten auf eine semantisch reichhaltigere Art und Weise verbessert die Klassifizierung, Facettierung und Relevanz von Dokumenten.
Solr enthält eine leistungsstarke Funktion, den Solr Tagger. Wenn das System mit einer Liste bekannter Entitäten gefüttert wird, liefert der Tagger Details zu diesen Dingen in Textform. In diesem Artikel erfahren Sie, wie Sie den Solr Tagger verwenden, um Städte, Farben und Marken zu taggen, und wie Sie ihn an Ihre eigenen Suchprojekte anpassen können.
Was ist der Solr Tagger?
Entity-Erkennung ist nicht neu, aber vor Solr 7.4 gab es eine Menge Python und händisches Zeug, dasdie Arbeit zwar erledigte, aber nicht einfach war. Mit der Veröffentlichung von Solr 7.4 wurde dann Solr Tagger eingeführt, eine unglaubliche Arbeit von David Smiley, einem außergewöhnlichen Solr-Committer.
Der Solr Tagger nimmt eine Sammlung, einen Feldnamen und eine Zeichenkette auf und gibt Vorkommen von Tags zurück, die in einem Textstück vorkommen. Wenn ich den Tagger z.B. bitte, „Ich habe mein Herz in San Francisco gelassen, bin aber in New York zu Hause“ zu verarbeiten und ich habe „San Francisco“ und „New York“ als Städte definiert, wird Solr das sagen:
"response":{"numFound":2,"start":0,"docs":[
{
"id":"5128542",
"name":["San Francisco"],
"type": "city",
"countrycode":"US"}]
},
{
"id":"5128512",
"name":["New York"],
"type":"city",
"countrycode":"US"}]
}
Auszug aus einer Beispielausgabe
Der Tagger von Solr ist ein naiver Tagger und verarbeitet keine natürliche Sprache (NLP). Er kann dennoch als Teil eines vollständigen NER- oder ERD-Systems (Entity Recognition and Disambiguation) oder sogar zum Aufbau einer Implementierung für die Beantwortung von Fragen oder für virtuelle Assistenten verwendet werden .
So funktioniert der Solr Tagger
Der Solr Tagger ist ein Solr-Endpunkt, der eine spezielle Sammlung verwendet, die „Tags“ enthält, bei denen es sich um definierte Textstrings handelt. In diesem Fall sind die „Tags“ Zeiger auf Textbereiche (Teilzeichenketten; Start- und End-Offsets) innerhalb des angegebenen Textes. Diese Textbereiche stimmen mit _Dokumenten_ überein, und zwar über das angegebene Tagging-Feld. Dokumente im allgemeinen Sinne von Solr sind einfach eine Sammlung von Feldern. Zusätzlich zu den Tags können Benutzer Metadaten definieren, die mit dem Tag verbunden sind. Metadaten für getaggte „Städte“ könnten zum Beispiel den Ländercode, die Einwohnerzahl und den Breitengrad/Längengrad enthalten.
Der Abschnitt Solr Referenzhandbuch für den Solr Tagger enthält ein ausgezeichnetes Tutorial, das sich leicht mit einer neuen Solr-Instanz ausführen lässt. Wir empfehlen Ihnen, zunächst dieses ausführliche Tutorial durchzuarbeiten, da wir im Folgenden auf den Daten und der Konfiguration dieses Tutorials aufbauen werden.
Wenn Sie einen tieferen Einblick in das Innenleben des Solr Tagger erhalten möchten, sehen Sie sich die Präsentation von David Smiley von vor ein paar Jahren an:
Entitäten markieren
In Erweiterung des Solr Tagger-Tutorials mit Städten werden wir nun weitere Arten von Entitäten hinzufügen.
Wenn wir den Dokumenten in der Tagger-Sammlung ein einzelnes Feld für den Typ hinzufügen, können wir auch andere Arten von Dingen taggen, z.B. Farben, Marken, Personennamen usw. Diese und andere typenspezifische Informationen zu Tagger-Dokumenten ermöglichen auch das Filtern der zum Taggen verfügbaren Dokumente. Zum Beispiel können die typ- und typspezifischen Felder es erleichtern, nur Städte zu taggen, die in geringer Entfernung zu einem bestimmten Ort liegen.
Mit Fusion legen wir zunächst die grundlegenden Daten des Solr Tagger-Tutorials für Geonames in den Blob-Speicher von Fusion und erstellen eine Datenquelle, um sie zu indizieren (in einer weiteren Datenquelle befinden sich einige andere Beispiel-Entitäten, die wir im nächsten Schritt untersuchen werden):
Bevor wir diese Datenquelle starten, ändern wir das Schema und die Konfiguration mit dem Solr Config-Editor von Fusion gemäß der Solr Tagger-Dokumentation. Die Geonames-Städte-Daten enthalten zwar Breiten- und Längengrade, aber die einfache Indizierungsstrategie des Tutorials belässt sie als separate Felder. Die Geofunktionen von Solr arbeiten mit einem speziellen kombinierten „lat/lon“-Feld, das als eine einzige kombinierte kommagetrennte Zeichenkette angegeben werden muss. Das Standardschema von Solr bietet ein dynamisches *_p (für „Punkt“) Feld. In Fusion bietet die praktische Feldzuordnungsphase eine Möglichkeit, ein Feld mit einem Template (StringTemplate) Trick zu setzen, wie hier für location_p gezeigt:

Außerdem ist das Feld type für jedes Dokument in dieser Datenquelle buchstäblich auf „city“ gesetzt und enthält nur Städte. Wir werden in Kürze weitere „Typen“ von Entitäten hinzufügen, aber lassen Sie uns zunächst sehen, was die Felder type und location_p uns jetzt geben:
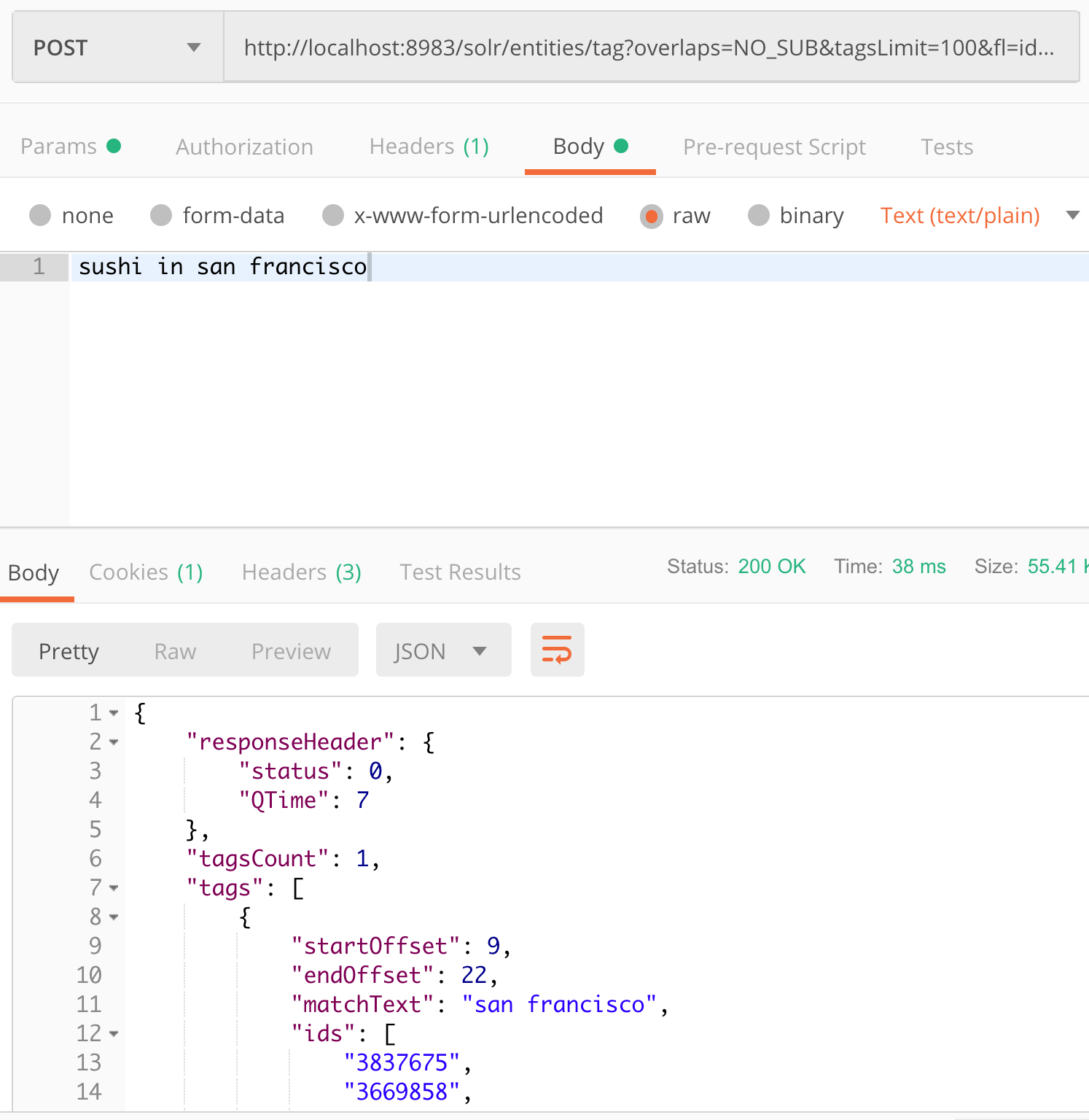
http://localhost:8983/solr/entities/tag?overlaps=NO_SUB&tagsLimit=100&fl=id,name,*_s&wt=json&indent=on&matchText=true&json.nl=map
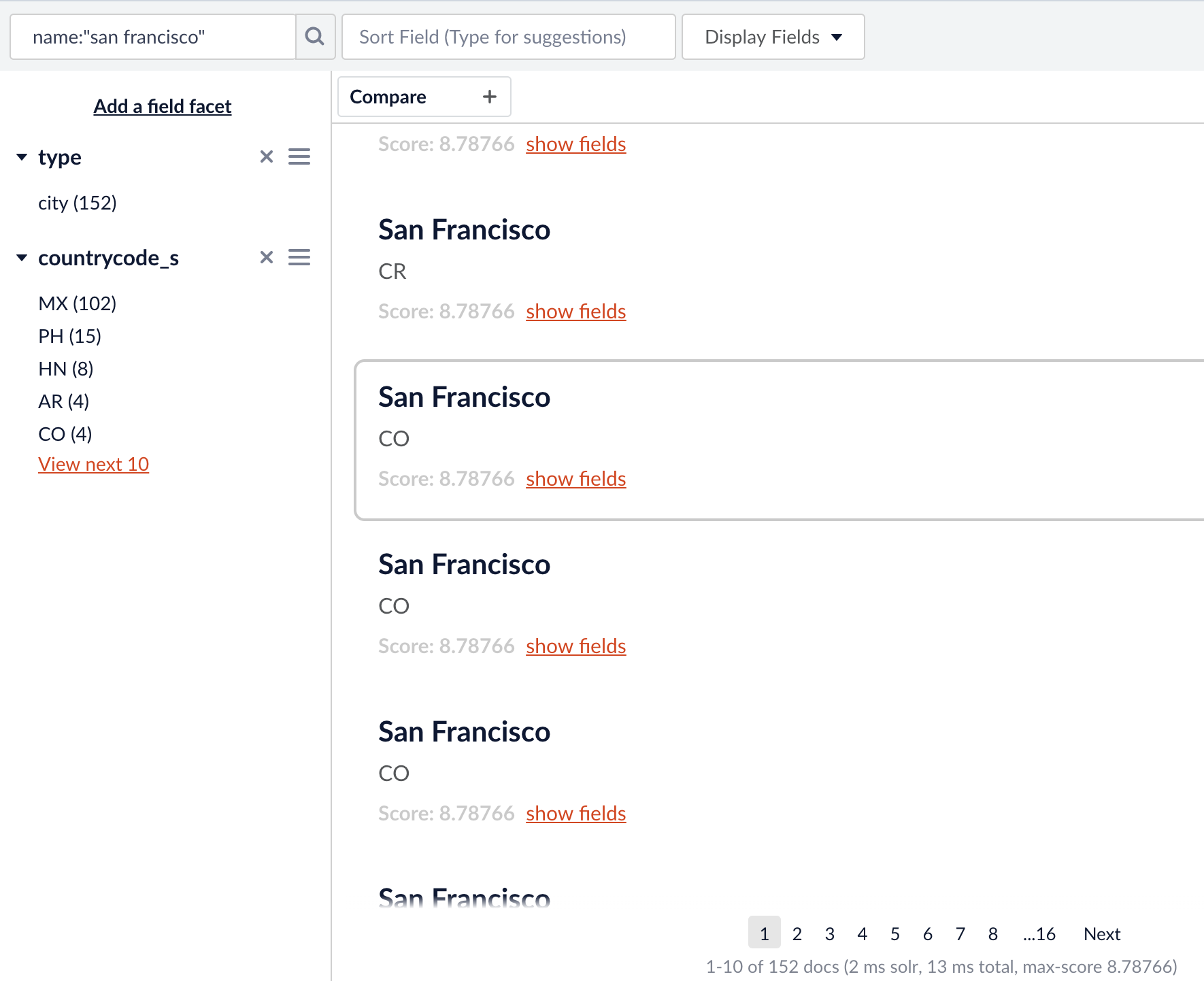
„san francisco“ ist die einzige bekannte Zeichenkette in der Sammlung `entities` in diesem Text. Es gibt 42 Städte, die genau als „San Francisco“ in dieser Sammlung bekannt sind. (es gibt noch viel mehr, die „San Francisco“ als Teil ihres Namens haben, wie in der Fusion Query Workbench unten gezeigt)
Viele „San Francisco „s, aber nur 42 mit exakter Übereinstimmung, und somit mit der aktuellen Konfiguration taggbar.
Visualisieren von Tags beim Tippen
Der letzte Schliff besteht darin, das Taggen von Text während der Eingabe zu ermöglichen. Es wurde eine einfache(VelocityResponseWriter) Proof-of-Concept-Schnittstelle erstellt, um schnell ein Textfeld, einen Aufruf des Solr Tagger-Endpunkts und die Anzeige der Ergebnisse zu verbinden. Wenn Sie denselben Satz eingeben, wird die Antwort von Solr Tagger diagnostisch angezeigt, zusammen mit einer farbkodierten Ansicht der getaggten Zeichenfolge. Getaggte Städte sind gelb kodiert:

Angenommen, wir befinden uns in San Francisco, Kalifornien, am Hauptsitz von Lucidworks, und möchten Sushi-Restaurants in der Nähe finden, dann geben wir einen nützlichen Kontext an: unseren Standort. Indem wir die Markierung von Orten auf eine geografische Entfernung von einem bestimmten Punkt eingrenzen, können wir die verfügbaren Städte für die Markierung des Strings eingrenzen. Wenn der ortsbezogene Kontext angegeben wird, indem das Kästchen „In SF?“ markiert wird, erhält der Tagger einen Filter (fq) von:
(type:city AND {!geofilt sfield=location_p}) OR (type:* -type:city)
Diese Funktion filtert nach Städten innerhalb eines Umkreises von 10 km (d=10) um den angegebenen Standort (der Parameter pt gibt einen Breiten- und Längengrad an).
Mehr als nur Standorte markieren
Bis jetzt haben wir nur Städte getaggt. Aber wir haben die Tagger-Sammlung so konfiguriert, dass sie jeden „Typ“ von Dingen unterstützt. Um zu zeigen, wie zusätzliche Typen funktionieren, werden ein paar zusätzliche Typen auf ähnliche Weise eingebracht (eine CSV-Datei im Fusion Blobstore und eine grundlegende Datenquelle, um sie zu indizieren):
id,type,name color-1,color,White color-2,color,Blue brand-1,brand,White Linen
Nehmen wir an, wir taggen jetzt die Phrase „Blue White Linen sheets“ (fügen Sie „in san francisco“ für noch mehr Farbe hinzu):

Die Teilzeichenkette „weiß“ ist hier mehrdeutig, da sie eine Farbe ist und auch Teil von „weißes Leinen“ (eine Marke). Es gibt einen Parameter für den Tagger (overlaps), der steuert, wie überlappender getaggter Text behandelt werden soll. Die Standardeinstellung ist NO_SUB, so dass keine überlappenden Tags zurückgegeben werden, sondern nur die äußersten. Dies führt dazu, dass „weißes Leinen“ als Marke getaggt wird und nicht als Marke mit einem Farbnamen darin.
End Offset – Was kommt als nächstes?
Nun, das ist cool – wir sind in der Lage, Teilstrings im Text zu markieren und sie mit Dokumenten zu verknüpfen. Die eigentliche Magie entsteht, wenn die getaggten Informationen und Dokumente verwendet werden. Mit Hilfe der getaggten Informationen können wir beispielsweise die Entitäten aus einer Abfragezeichenfolge extrahieren und sie in Filter verwandeln.
Wenn zum Beispiel jemand nach „blauen Schuhen“ gesucht hat und Blau als Farbe getaggt ist, können wir es mit dem Tagger finden und aus dem Abfrage-String extrahieren und als Filterabfrage hinzufügen. Effektiv können wir „blaue Schuhe“ in q=Schuhe&fq=Farbe_s:blau umwandeln, und das mit nur ein paar Zeilen Code zur Stringmanipulation. Dies ändert die Struktur der Abfrage und macht sie relevanter. Zum einen suchen wir nach „blau“ in einem Farbfeld und nicht mehr allgemein im Dokument oder in der Produktbeschreibung. Zum anderen kann es bei längeren Abfragen effizienter sein, da sich diese in der Regel dazu hinreißen lassen, Begriffe über alle Felder zu verteilen, unabhängig davon, ob die Abfragebegriffe für diese Felder tatsächlich sinnvoll sind.
Trey Grainger, Chief Algorithms Officer bei Lucidworks, hat auf der Haystack-Konferenz die natürliche Sprachsuche mit Wissensgraphen vorgestellt und damit das Tagging auf eine neue Ebene gehoben. In dieser Präsentation nutzte Trey den Solr Tagger, um nicht nur Dinge zu taggen („Heuhaufen“ in seinem Beispiel), sondern auch Befehls-/Bedienungswörter („nahe“). Der Solr Tagger ist ein wichtiger Bestandteil der natürlichsprachlichen Suche.
Probieren Sie es jetzt bei Lucidworks Labs

Das oben beschriebene Solr Tagger-Beispiel wurde in ein Lucidworks Lab gepackt, so dass es von https://lucidworks.com/labs/apps/tagger/ aus gestartet werden kann.
Erik erforscht die suchbasierten Möglichkeiten von Lucene, Solr und Fusion. Er ist Mitbegründer von Lucidworks und Mitautor von ‚Lucene in Action‘.