Was sind Pivot-Facetten?
Hinweis: Die in diesem Blogbeitrag besprochenen Features und Funktionen sind in Solr zwar immer noch verfügbar und werden unterstützt, aber neuen Benutzern wird empfohlen, stattdessen die JSON Facet API zu verwenden, um ähnliche Ergebnisse zu erzielen. Obwohl ihre Genauigkeit in verteilten Sammlungen bei ihrer Einführung in Solr 5.0 etwas begrenzt war, unterstützt die JSON Facet API eine breitere Palette von Funktionen (einschließlich der Möglichkeit, nach verschachtelten Statistikfunktionen zu sortieren). Mit der Hinzufügung der (zweistufigen) Verfeinerungsunterstützung in Solr 7.0 und der konfigurierbaren overrefine in 7.5 gibt es für Benutzer praktisch keinen Grund mehr, facet.pivot oder stats.field.
Solr 4.10 wird jede Minute veröffentlicht und mit ihm kommt die lang ersehnte Unterstützung für verteilte Abfragen für Pivot Faceting (aka: SOLR-2894). Heute haben wir einen besonderen Gastbeitrag von 4 Leuten bei CareerBuilder, die dazu beigetragen haben, dass verteiltes Pivot Faceting Wirklichkeit geworden ist: Trey Grainger, Brett Lucey, Andrew Muldowney und Chris Russell.
Was sind Pivot-Facetten?
Wenn Sie in der Vergangenheit mit Lucene / Solr gearbeitet haben, sind Sie wahrscheinlich mit der Facettierung vertraut, die es Ihnen ermöglicht, die Gesamtzahl der Suchergebnisse nach einer bestimmten Kategorie aufzuschlüsseln (oft die Liste der Werte innerhalb eines bestimmten Feldes). Wenn Sie z.B. eine Suche nach Restaurants durchführen würden(Beispiel-Dokumente), könnten Sie mit der folgenden Anfrage eine Liste der 3 Städte mit den besten 4- oder 5-Sterne-Restaurants erhalten:
Abfrage:
/select?q=*:*
&fq=rating:[4 TO 5]
&facet=true
&facet.limit=3
&facet.mincount=1
&facet.field=city
Ergebnisse:
{ ...
"facet_counts":{
...
"facet_fields":{
"city":[
"Atlanta",4,
"Chicago",3,
"New York City",3]}
... }
Dies ist ein sehr schneller und flexibler Weg, um Echtzeit-Analysen bereitzustellen (mit Ad-hoc-Abfragemöglichkeiten durch die Verwendung von Schlüsselwörtern), aber in jedem einigermaßen ausgefeilten Analysesystem werden Sie Ihre Daten in mehreren Dimensionen analysieren wollen. Mit der Veröffentlichung von Solr 4.0 wurde eine neue Funktion eingeführt, die es ermöglicht, die Werte nicht nur nach einer einzigen Facettenkategorie aufzuschlüsseln, sondern auch nach allen zusätzlichen Unterkategorien. Nehmen wir unser Beispiel mit den Restaurants: Wir möchten herausfinden, wie viele 4- und 5-Sterne-Restaurants es in den Top-Städten in den 3 wichtigsten US-Bundesstaaten gibt. Dies können wir mit der folgenden Abfrage erreichen (Beispiel aus Solr in Action):
Abfrage:
/select?q=*:*
&fq=rating:[4 TO 5]
&facet=true
&facet.limit=3
&facet.pivot.mincount=1
&facet.pivot=state,city,rating
Ergebnisse:
{ ...
"facet_counts":{
...
"facet_pivot":{
"state,city,rating":[{
"field":"state",
"value":"GA",
"count":4,
"pivot":[{
"field":"city",
"value":"Atlanta",
"count":4,
"pivot":[{
"field":"rating",
"value":4,
"count":2},
{
"field":"rating",
"value":5,
"count":2}]}]},
{
"field":"state",
"value":"IL",
"count":3,
"pivot":[{
"field":"city",
"value":"Chicago",
"count":3,
"pivot":[{
"field":"rating",
"value":4,
"count":2},
{
"field":"rating",
"value":5,
"count":1}]}]},
{
"field":"state",
"value":"NY",
"count":3,
"pivot":[{
"field":"city",
"value":"New York City",
"count":3,
"pivot":[{
"field":"rating",
"value":5,
"count":2},
{
"field":"rating",
"value":4,
"count":1}]}]}
... ]}}}
Dieses Beispiel demonstriert eine dreistufige Pivot-Facette, wie sie durch den Parameter „facet.pivot=state,city,rating“ definiert ist. Dies ermöglicht interessante Analysemöglichkeiten in einer einzigen Anfrage, ohne dass Sie die Abfrage mehrfach ausführen müssen, um Facettenwerte für jede Ebene zu generieren. Wenn Sie einen Index von Profilen in sozialen Netzwerken anstelle von Restaurantkritiken durchsuchen würden, könnten Sie die Dokumente stattdessen nach Kategorien wie Geschlecht, Schule, Schulabschluss oder sogar nach Unternehmen oder Berufsbezeichnung aufschlüsseln. Wenn Sie in der Lage sind, auf jede dieser verschiedenen Arten von Informationen zuzugreifen, können Sie eine Fülle von Wissen aufdecken, indem Sie die aggregierten Beziehungen zwischen Ihren Dokumenten untersuchen.
Eine vollständige Dokumentation zur Verwendung von Pivot Faceting in Solr (einschließlich unterstützter Abfrageparameter und zusätzlicher Beispiele) finden Sie im Abschnitt Pivot Faceting im Solr Reference Guide.
Implementierung der Unterstützung für „verteilte“ Pivot-Facetten
Facettierung in einer verteilten Umgebung ist sehr komplex. Obwohl die Pivot-Facettierung in Solr bereits seit fast 2 Jahren (seit Solr 4.0) unterstützt wird, war ein erheblicher zusätzlicher Entwicklungsaufwand erforderlich, um sie in einer verteilten Umgebung (wie SolrCloud) zum Laufen zu bringen. Hier finden Sie einen kleinen Überblick über die Geschichte der Funktion sowie Details zur technischen Implementierung für diejenigen, die an einem tieferen Verständnis der Interna interessiert sind.
Geschichte
Pivot Faceting begann als SOLR-792. Erik Hatcher schrieb den ursprünglichen Code zur Darstellung hierarchischer Facetten in nicht verteilten Umgebungen, der in Solr 4.0 veröffentlicht wurde. Diese Arbeit wurde später zu SOLR-2894 erweitert, um speziell auf verteilte Umgebungen wie SolrCloud einzugehen.
Da Chris Russell diese Fähigkeit für einige der Datenanalyseprodukte von CareerBuilder benötigte, versuchte er, einen frühen, von der Community erstellten Patch anzuwenden und zu integrieren. Nachdem der Patch in der Solr-Version von CareerBuilder funktionierte, stellte das Team fest, dass bei der Unterstützung verteilter Umgebungen eine wichtige Funktion fehlte: Der verfügbare Patch verstand zwar die Notwendigkeit, Antworten von verteilten Shards zusammenzuführen, enthielt aber keinen Code, um mit „Verfeinerungs“-Anfragen umzugehen, um sicherzustellen, dass genaue aggregierte Ergebnisse zurückgegeben wurden. Trey Grainger und Chris Russell begannen mit der Entwicklung einer skalierbaren Lösung für die Unterstützung von verschachtelten Facettenverfeinerungsanfragen und übergaben diese Arbeit schließlich an Andrew Muldowney, um sie weiter zu implementieren. Andrew zog die Verfeinerungsarbeit durch und brachte den Patch zu einem Punkt, an dem er in einer verteilten Solr-Konfiguration genau funktionierte – wenn auch langsam.
Als die Anforderungen von CareerBuilder an diesen Patch stiegen, zogen wir Brett Lucey hinzu, der die Aufgabe übernahm, die Leistung zu verbessern. Brett optimierte die Verfeinerungslogik und die Datenstrukturen, um die Leistung schließlich um das 80-fache zu steigern. Zu diesem Zeitpunkt übernahm Chris Hostetter den SOLR-2894-Mantel und erstellte eine robuste Testsuite, die mehrere Fehler aufdeckte, die vom Team bei CareerBuilder behoben wurden.
Die Herausforderung
Bevor wir uns mit den Details der Implementierung befassen, sollten Sie sich mit einigen nützlichen Begriffen für die Diskussion vertraut machen:
- Begriff – Ein bestimmter Wert aus einem Feld
- Limit – Maximale Anzahl von Begriffen, die zurückgegeben werden sollen
- Offset – Die Anzahl der obersten Facettenwerte, die in der Antwort übersprungen werden sollen (wie beim Blättern durch die Suchergebnisse und der Wahl eines Offsets von 51, um auf Seite 2 zu beginnen, wenn 50 Ergebnisse pro Seite angezeigt werden)
- Shard – Eine durchsuchbare Partition von Dokumenten (dargestellt als Solr-„Kern“), die eine Teilmenge des Index einer Sammlung enthält.
- Verfeinerung – Der Vorgang, bei dem einzelne Shards nach der Anzahl bestimmter Begriffe gefragt werden, die sie ursprünglich nicht zurückgegeben haben, die aber von einem oder mehreren anderen Shards zurückgegeben wurden und die anschließend von allen Shards für eine genaue Verarbeitung abgerufen werden müssen. Im Zusammenhang mit Distributed Pivot Facetten, die verschachtelte Facettenebenen enthalten, enthält der „Begriff“ eine Liste der übergeordneten Einschränkungen für alle zuvor verarbeiteten Ebenen.
Wenn eine verteilte Anfrage eingeht, wird die Anfrage auf mehrere Shards verteilt, die jeweils eine Parition des Index der Sammlung enthalten. Da jeder Shard über eine andere Teilmenge des Indexes verfügt, antwortet jeder Shard mit der Antwort, die nur auf der Grundlage seiner eigenen Daten lokal korrekt ist. Anschließend müssen alle lokal korrekten Antworten zusammengeführt werden, um die global korrekte Antwort für die gesamte Sammlung von Shards zu ermitteln. Dieser Prozess (bekannt als Verfeinerung) erfordert, dass jeder Shard nach der Anzahl bestimmter Begriffe gefragt wird, die in anderen Shards gefunden wurden.
Bei der traditionellen einstufigen Facettierung gibt es nur eine Runde der Verfeinerung. Die kollationierte Antwort wird untersucht, um festzustellen, welche Begriffe verfeinert werden müssen, und die Anfragen werden gesendet. Sobald diese Anfragen beantwortet sind, verfügt die Zusammenstellung nun über perfekte Informationen für die Facettenwerte. Dies gilt jedoch nicht für Pivot-Facetten: Zwar wird jede Ebene einer Pivot-Facette nur einmal verfeinert, aber die aus diesen Verfeinerungen gewonnenen Informationen können – und tun es oft – die Begriffe ändern, die für die Verfeinerung auf den nachfolgenden Ebenen untersucht werden. Das bedeutet, dass wir den Status der Werte, die von jedem Shard zurückkommen, speichern und bei Bedarf intelligente Verfeinerungsanfragen stellen müssen, um genaue Zahlen für jede Ebene zu berechnen. Dies erfordert sehr viel mehr Arbeit. Pivot-Facetten sind teuer: Die Verfeinerung einer mehrstufigen Facette kann sehr viel Zeit in Anspruch nehmen. Wir haben ziemlich viel in die richtigen Datenstrukturen investiert, um diesen Prozess so schnell wie möglich zu gestalten.
Die Umsetzung
Wenn eine Distributed Pivot Faceting-Anfrage eingeht, wird die ursprüngliche Abfrage bearbeitet, bevor sie an jeden Shard in der Solr-Sammlung weitergegeben wird. Während dieser Bearbeitung wird das Limit um den Offset erhöht und dann der Offset aus der Abfrage entfernt. Das Limit wird dann erhöht bzw. überabgefragt, um die Verfeinerung zu minimieren (denn wenn wir alle Top-Werte in der ersten Abfrage zurückbekommen, ist eine weitere Verfeinerungsabfrage für diese Ebene nicht erforderlich).
Wir müssen nun eine vollständige Aufzeichnung der Antworten der einzelnen Shards erstellen: Die Antworten der einzelnen Shards werden in einem Array gespeichert und eine kombinierte Antwort aller Shards wird ebenfalls gespeichert. Die kombinierte Antwort wird dann geprüft und es werden Kandidaten für eine mögliche Verfeinerung ausgewählt. Die Kandidaten für die Verfeinerung lassen sich in zwei Kategorien einteilen: Begriffe, die innerhalb der angegebenen Grenze liegen, und Begriffe, die möglicherweise innerhalb der Grenze liegen könnten, wenn sie verfeinert werden. Um festzustellen, ob ein Begriff innerhalb des Limits liegen könnte, wenn er verfeinert wird, prüfen wir die Zählung der einzelnen Shards für den betreffenden Begriff. Wenn ein Shard keine Zählung für diesen Begriff enthält, nehmen wir die niedrigste Zählung, die von diesem Shard für das entsprechende Feld zurückgegeben wird. Der Grund dafür ist einfach: Diese Zählung ist die höchste, die der Shard für den jeweiligen Begriff liefern konnte. Wenn die kombinierte Zählung für den Wert groß genug ist, um innerhalb des Limits zu liegen, verfeinern wir diesen Wert. Da jede nachfolgende Ebene in hohem Maße von der Verfeinerung der vorangegangenen Ebene abhängt, gehen wir erst dann zu den nachfolgenden Ebenen über, wenn alle Verfeinerungsanfragen der vorangegangenen Ebene beantwortet worden sind. Nachdem jede Ebene verfeinert wurde, wird das kombinierte Ergebnis getrimmt, die korrekten Grenzwerte und Offsets werden auf jede Ebene angewendet und das kombinierte Ergebnis wird in das richtige Ausgabeformat konvertiert, das zurückgegeben werden soll.
Verwendung der verteilten Pivot-Facettierung
Wie nutzt CareerBuilder die verteilte Pivot-Facettierung?
Unser Hauptanwendungsfall ist die Nutzung der Analyseprodukte von CareerBuilder für Angebot & Nachfrage und Vergütung, die tiefe Einblicke in Arbeitsmarktdaten bieten. Wenn jemand zum Beispiel nach „Buchhalter“ (oder einem anderen Schlüsselwort) sucht, führen wir eine Suche über eine Sammlung von Lebensläufen (Angebot) und eine Sammlung von Stellen (Nachfrage) durch und analysieren die resultierenden Daten. Wir könnten zunächst nach einem Feld suchen, das die Sammlung repräsentiert („Angebot“ oder „Nachfrage“), und dann nach interessanten Informationen in diesen Daten suchen (z.B. Jahre Erfahrung, Standorte, Bildungsniveau usw.). Unten sehen Sie einen Screenshot unseres Produkts Angebot & Nachfrage, der die Arbeitsmarkttrends für Buchhalter in Massachusetts zeigt:
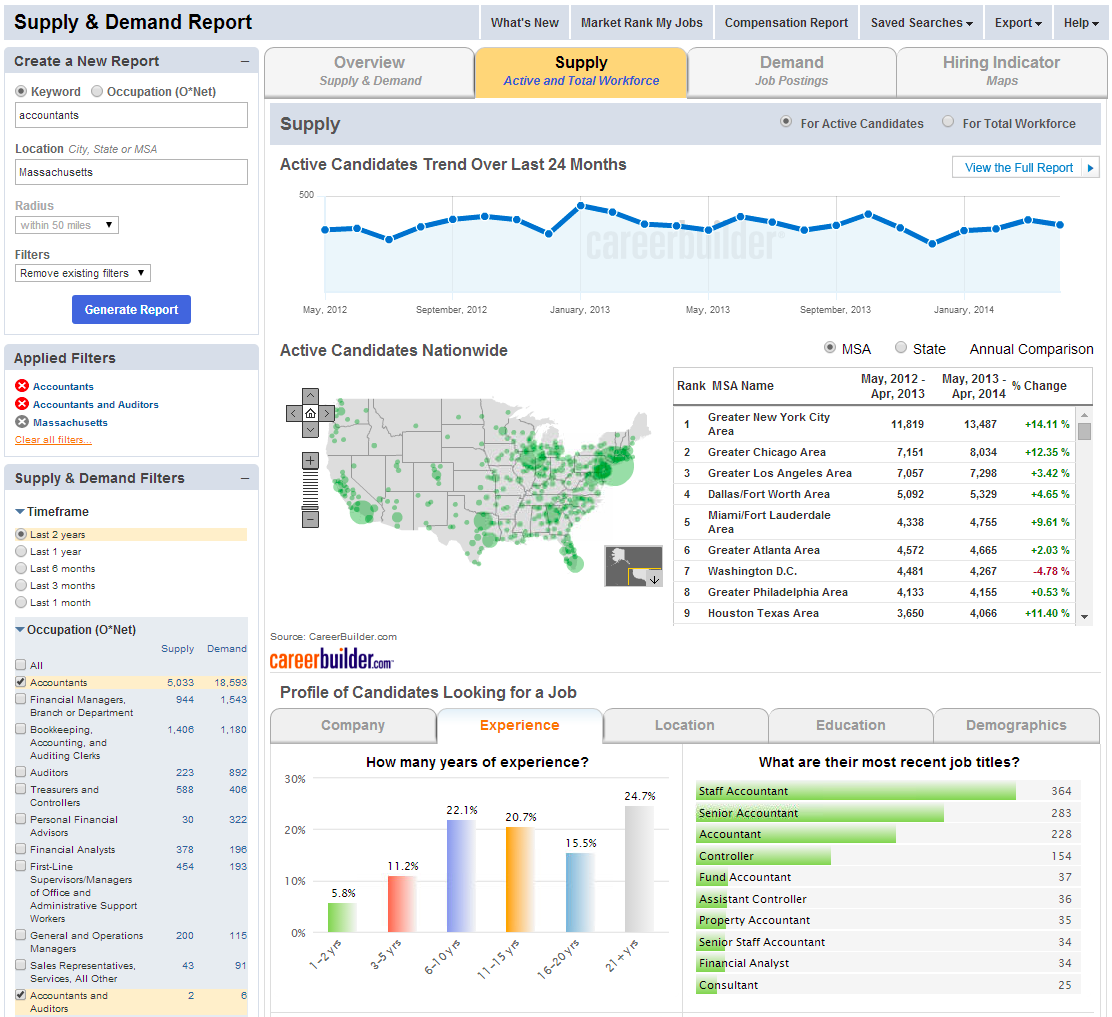
Bei CareerBuilder gehen wir noch einen Schritt weiter und kombinieren Distributed Pivot Faceting mit SOLR-3583, um Perzentile und andere Statistiken auf jeder Pivoting-Ebene zu erhalten. So können wir z.B. die Daten zum „Angebot“ facettieren, auf das „Bildungsniveau“ pivotieren und dann die Perzentil-Statistiken (25., 50., 75. usw.) zum Gehaltsbereich für Stellensuchende, die in diese Kategorie fallen, erhalten. Hier ist ein Beispiel dafür, wie wir diese Daten in unserem Vergütungsportal für die Berichterstattung über Vergütungstrends auf dem Arbeitsmarkt nutzen:
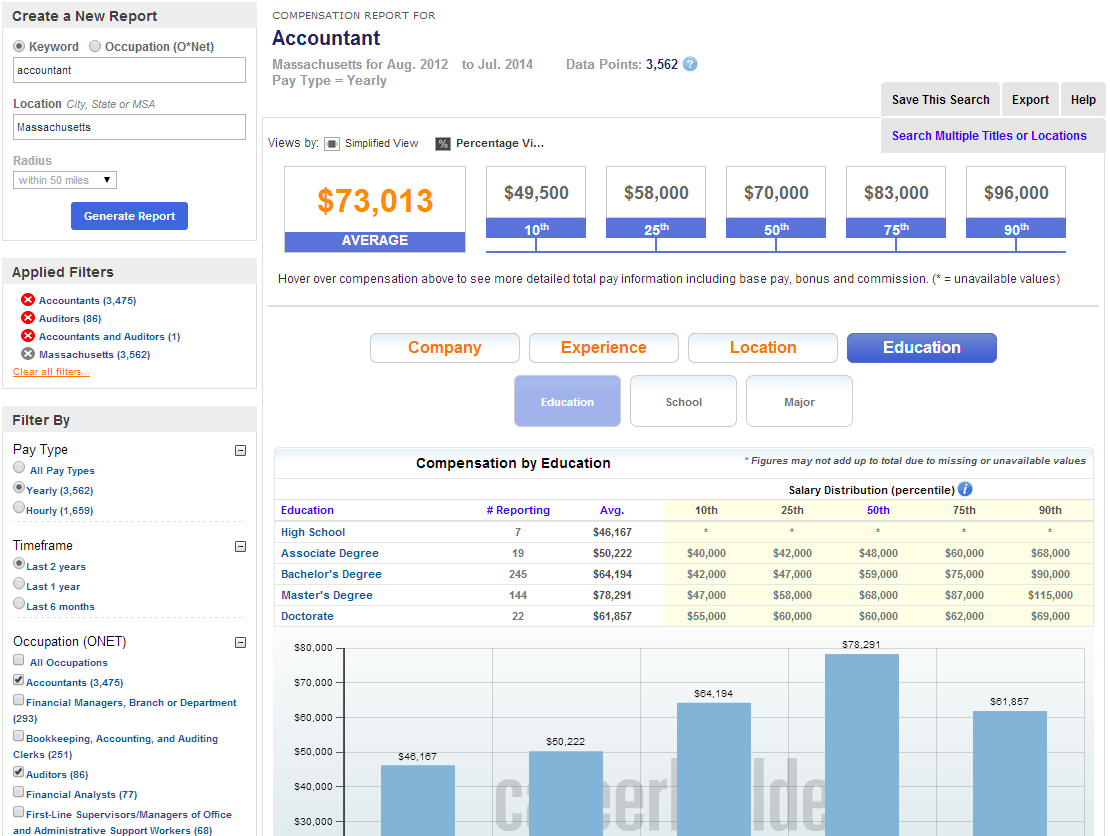
Unten sehen Sie eine Folie aus einem Vortrag über unsere Verwendung von Solr für Analysen auf der Lucene Revolution 2013, in dem Trey Grainger beschreibt, wie wir diese Art von Statistiken zusammen mit Distributed Pivot Faceting nutzen (siehe Minuten 21:30 bis 26:00 im Video oder Folien 41-42):

Der Patch SOLR-3583 für verteilte Pivot-Statistiken wurde nicht an Solr übergeben, aber Leser können ihn untersuchen, wenn sie einen ähnlichen Anwendungsfall haben. Eine verbesserte Version von SOLR-3583 befindet sich derzeit in der Entwicklung(SOLR-6350 + SOLR-6351), die SOLR-3583 in Zukunft wahrscheinlich ersetzen wird. (EDIT 2015-05-20: Pivot-Statistiken wurden in Solr 5.1 hinzugefügt, und Perzentil-Unterstützung wurde in Solr 5.2 hinzugefügt – siehe das Solr-Referenzhandbuch für weitere Details)
Was sind die derzeitigen Einschränkungen von Distributed Pivot Faceting?
facet.pivot.mincount=0funktioniert nicht gut in Distributed Pivot Faceting. (SOLR-6329)- Pivot-Facettierung (ob verteilt oder nicht) unterstützt nur Facettierung auf Feldwerten(SOLR-6353)
- Distributed Pivot Faceting funktioniert möglicherweise nicht gut mit einigen benutzerdefinierten FieldTypes. (SOLR-6330)
- Die Verwendung von
facet.*Parametern als lokale Parameter innerhalb von facet.field verursacht Probleme bei der verteilten Suche. (SOLR-6193)
Wie skalierbar ist Distributed Pivot Faceting?
Im Allgemeinen kann die Pivot-Facettierung teuer sein. Selbst bei einer einzelnen, nicht verteilten Solr-Suche kann die Anzahl der Dimensionen, die Sie abfragen, exponentiell ansteigen und die Systemressourcen schnell erschöpfen (was zu Problemen mit dem Speicher und der Garbage Collection führt), wenn Sie nicht darauf achten, auf jeder Ebene Ihres Pivot-Facets die richtigen facet.limit Parameter zu setzen. Dies gilt insbesondere, wenn Sie Ihre facet.limit=-1 auf ein Feld mit vielen eindeutigen Werten setzen. Wenn Sie die Funktion jedoch verantwortungsbewusst nutzen, können Sie mit der verteilten Unterstützung wirklich leistungsstarke, skalierbare Analyseprodukte auf der Grundlage von Solr erstellen. Bei CareerBuilder haben wir die Funktion Distributed Pivot Facet erfolgreich in einem Cluster eingesetzt, der Hunderte von Millionen von Volltextdokumenten (Jobs und Lebensläufe) enthält, die auf fast 150 Shards verteilt sind, und zwar mit Antwortzeiten von unter einer Sekunde, was angesichts der Datenmenge und der damit verbundenen Verarbeitung sehr effizient ist.
Mit der nun vorhandenen Unterstützung für Distributed Pivot Faceting gibt es mehrere aufregende neue Funktionen, von denen wir glauben, dass sie endlich das Licht der Welt in Solr erblicken werden. Insbesondere sollte es bald möglich sein, verschiedene Facettentypen auf jeder Ebene zu kombinieren (derzeit unterstützen Pivot Facets nur die Facettierung von Feldwerten, nicht aber von Funktionen oder Bereichen) und zusätzliche Metainformationen wie Statistiken (Summen, Durchschnittswerte, Perzentile usw.) auf jeder Facettenebene bereitzustellen. Es ist eine wirklich aufregende Zeit für Solr, da es sich auf dem Weg befindet, eine sehr robuste Suite von Echtzeit-Analysefunktionen bereitzustellen, die bereits für innovative Produkte auf dem Markt genutzt werden.
Nochmals vielen Dank an Trey, Brett, Andrew, Chris und ihre Mitarbeiter bei CareerBuilder – sowohl für die Arbeit, die sie an diesem Patch geleistet haben, als auch für das Schreiben und die Herausgabe dieses großartigen Artikels darüber, wie Pivot Faceting funktioniert und wie es verwendet werden kann.
-Hoss