Wie Big Data die Pharmaindustrie im Stich lässt
Die pharmazeutische Industrie erzeugt immer größere Datenmengen. Es ist daher nicht überraschend, dass Pharmaunternehmen viel Geld für Big Data-Lösungen ausgegeben haben. Doch die meisten dieser Systeme haben nicht den Wert erbracht, der ursprünglich versprochen wurde. Kurz gesagt, das„Eroom’sche Gesetz“ – die Verlangsamung der Markteinführung von Medikamenten trotz technologischer Verbesserungen – muss erst noch durchbrochen werden, und diese Big Data-„Lösungen“ müssen erst noch Früchte tragen.
Ein Teil des Problems liegt in den Extremen. Frühere Systeme für die Pharmaindustrie basierten auf antiquierten, stark strukturierten Paradigmen. Diese Data-Warehousing-Systeme gingen davon aus, dass Sie Daten mit bestimmten Fragestellungen im Hinterkopf erfassen und zusammenstellen.
In den letzten Jahren hat die Pharmaindustrie stark in Technologien im Stil eines „Data Lake“ investiert. Im Wesentlichen geht es darum, zuerst die Daten zu erfassen und später eine Verwendung dafür zu finden. Während die Menge der erfassten Daten gestiegen ist, warten wir immer noch auf die Ergebnisse.
Wie Philip Bourne von der Skagg School of Pharmacy es ausdrückte, „Wir haben diese Explosion von Daten, die es uns im Prinzip ermöglicht, eine Menge zu tun. […] wir fangen an, komplexe Systeme auf eine Weise zu verstehen, wie wir es noch nie zuvor getan haben. Das sollte sich auf den Prozess der Arzneimittelentdeckung auswirken. Zum jetzigen Zeitpunkt glaube ich nicht, dass das der Fall ist, aber ich denke, wir stehen an der Schwelle zu einer Wende. Und natürlich verbessert sich die Informationstechnologie, die für all das benötigt wird […], ganz offensichtlich. Lassen Sie also Optimismus walten.“ 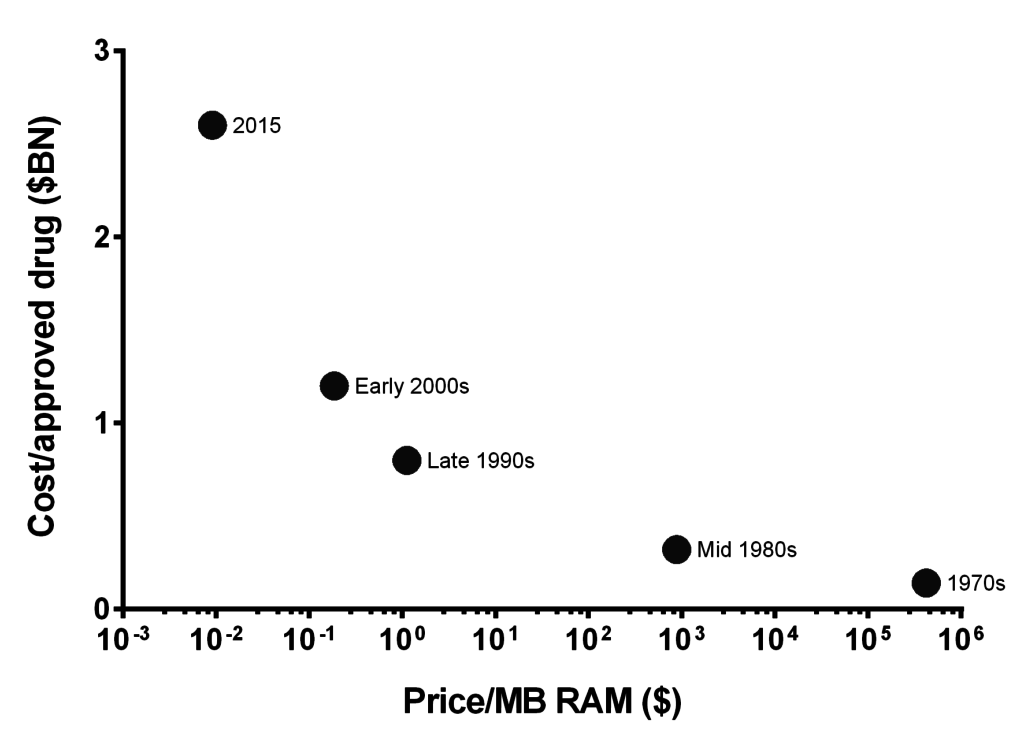
Aber der Datensee ist nicht ganz richtig
Data Warehouses sind nicht genug. Die Organisation von Daten in übersichtlichen Tabellenstrukturen oder Würfeln zur Beantwortung einer Forschungsfrage ist etwas „zu weit hergeholt“, um in einem HOLNet oder einem modernen pharmazeutischen Forschungsansatz zu funktionieren. An einem bestimmten Punkt im Lebenszyklus der Arzneimittelentwicklung ist dies immer noch nützlich, aber für eine allgemeinere Verwendung ist es zu starr.
Gleichzeitig hat es aber auch nicht wirklich gut funktioniert, alles in einen Datensee – einen großen unstrukturierten Speicher – zu werfen und mit Analysetools auszugraben. Eigentlich hat das nirgendwo funktioniert. Es ist ein bisschen so, als hätten wir beschlossen, dass der Bau von Lagerhäusern nicht mit der Produktion mithalten konnte, also haben wir einen großen, fetten Graben gebaut und die Daten dort hineingeschaufelt. Wenigstens war das Lagerhaus gut organisiert. Denkt jemand so über seinen Data Lake?
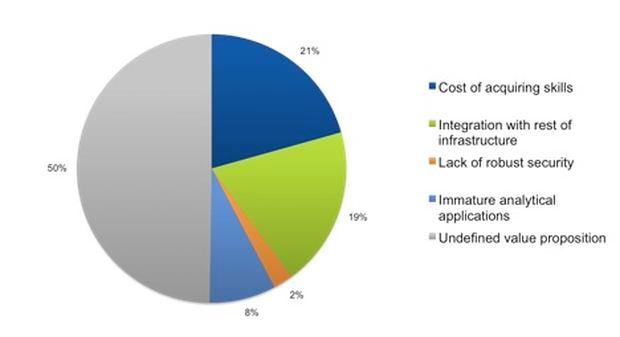
Quelle: 451 Forschung
Ein großes Problem mit dem Data Lake-Ansatz ist, dass er das Kind mit dem Bade ausschüttet. Ein Data Lake ist wie das Internet, in dem Sie alles, was Sie jemals wissen wollten, auf Knopfdruck finden, nur ohne Google. Einige Unternehmen haben es mit methodischen Ansätzen versucht, ähnlich wie bei einem Zettelkatalog und einem Bibliothekar, um die Daten zu verwalten (d.h. Datenmanagement- und Kuratierungslösungen). Angesichts der Tatsache, dass sich die Pharmadaten alle fünf Monate verdoppeln, ist klar, dass diese Ansätze weder jetzt noch auf lange Sicht funktionieren werden.
Analyse-Tools von der Stange sind unzureichend
Der Analysemarkt ist riesig, es gibt Hunderte von Anbietern mit Tausenden von Angeboten. Es erstaunt mich immer wieder, was Menschen mit einfachen Tools wie Microsoft Excel und einem VLOOKUP alles machen können. Die Verwendung eines generischen, bereichsunabhängigen Analysetools wie Tableau für die Analyse komplexer Daten aus der pharmazeutischen Forschung und klinischen Studien ist jedoch so, als würde man einen See mit einem Teelöffel trockenlegen.
Generische Tools verstehen die Domäne nicht, und die Metadaten sind zu abstrakt, als dass ein Forscher oder Analytiker einen Datensatz leicht durchschauen könnte. Wenn außerdem nur einige wenige Experten in einem Unternehmen die Daten verstehen können, sind sie für den modernen vernetzten Ansatz der Entwicklung von Medikamenten und Biologika ungeeignet.
Eine andere Herangehensweise an die Datenspeicherung
Was wir brauchen, ist ein Speichermechanismus, der sowohl flexibel als auch organisiert ist. Das Wichtigste ist jedoch auch das Einfachste: Die Daten sollten auf der Speicherebene indiziert werden, wie es in den Jahrzehnten vor Data Lakes der Fall war. Andernfalls dauert das Laden der Daten (selbst in einer speicherbasierten Lösung) eine Ewigkeit. Indizes sind das, was man braucht, um etwas effizient zu finden. Sie sind das „Google“ für Ihren internen Speicher.
Die Daten müssen gespeichert werden:
- Ermöglichen Sie die Organisation von Daten in flexiblen Dokumentstrukturen mit einem Schema, das leicht ergänzt werden kann.
- Skalierung bei wachsendem Datenvolumen (Verdoppelung alle 5 Monate)
- Führen Sie Volltext-, Ranglisten- und andere Suchvorgänge schnell und mit einer Reaktionszeit von weniger als einer Sekunde durch.
- Seien Sie vor allem flexibel. Es gibt zukünftige Verwendungsmöglichkeiten für die Daten, die wir noch nicht kennen. Veränderung ist eine Konstante. Starre Strukturen und Werkzeuge brechen unter dem Druck der modernen pharmazeutischen Forschung, Entwicklung und Vermarktung zusammen.
Bessere Analysen und Informationsaustausch
Analysetools sollten nicht so stark angepasst werden, dass sie die Geld- oder Zeitkosten eines umfangreichen IT-Projekts verursachen. Sie sollten jedoch bereichs- und zweckorientiert genug sein, um die gemeinsame Nutzung durch Forschung, Entwicklung, Marketing und darüber hinaus zu ermöglichen, ohne dass Datenspezialisten jede Frage beantworten müssen.
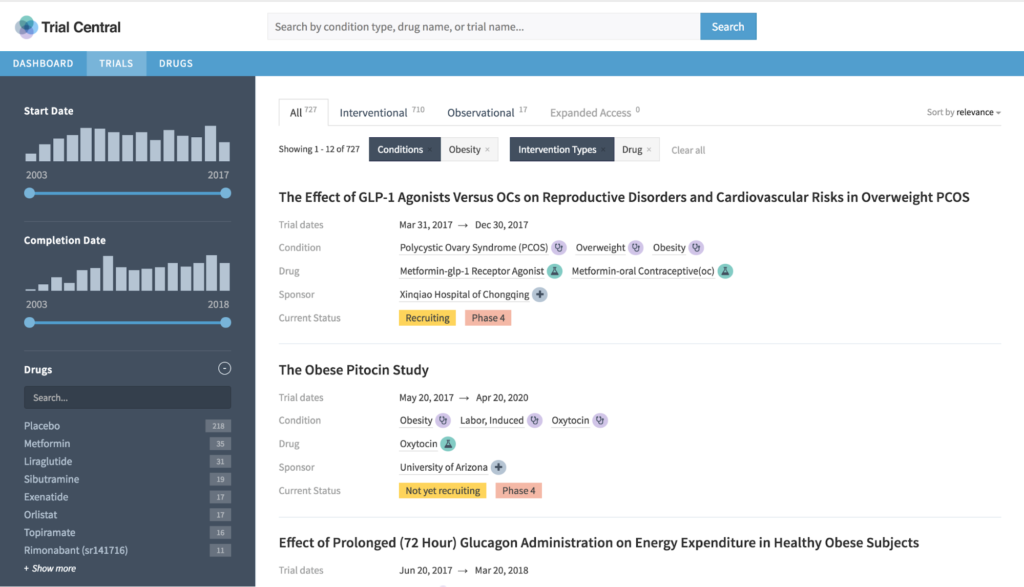
Standardwerkzeuge sind großartig, aber nicht ausreichend für diese Aufgabe. So wie pharmazeutische Anlagen aus einer Kombination von vorgefertigten, handelsüblichen und maßgeschneiderten Teilen und Materialien gebaut werden, so müssen auch pharmazeutische Analyse- und Informationssysteme gebaut werden. Sie können weder völlig individuell noch völlig generisch sein. Sie sollten im Wesentlichen „fit for purpose“ sein.
Bessere Datenverwaltung
Es gibt zu viele Daten, die zu schnell eingehen, um sie manuell zu kuratieren. Es werden Systeme zur schrittweisen Datenanreicherung und -verbesserung benötigt. Die Daten müssen in zunehmendem Umfang und manchmal in Echtzeit identifiziert, gekennzeichnet, angereichert, bereinigt und kombiniert werden.
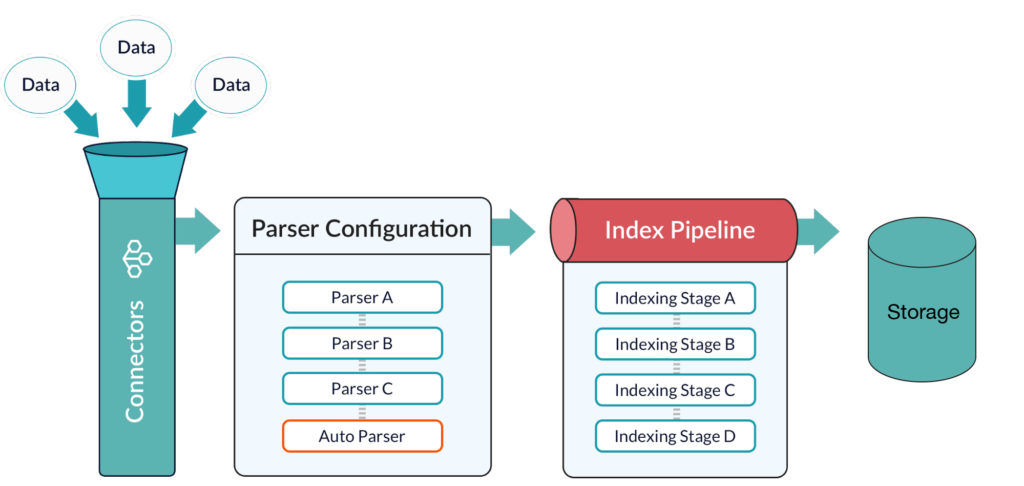
Darüber hinaus sind neue Techniken, die Technologien der künstlichen Intelligenz nutzen, wie maschinelles Lernen und Deep Learning, für ein modernes Datenmanagement erforderlich. KI findet Muster und ermöglicht es dem System, Daten im Handumdrehen zu clustern und zu klassifizieren. KI ersetzt nicht die Notwendigkeit von Branchenkenntnissen und Fachwissen, sondern ergänzt sie, damit Forscher und Vermarkter gleichermaßen mit immer größeren Datenmengen umgehen können.
…Mit anderen Worten: Diese Tools helfen dabei, Daten in tatsächliche Informationen zu verwandeln.
Angesichts der ständig wachsenden Datenmengen, darunter Daten aus klinischen Studien, molekulare Daten, elektronische Gesundheitsakten (EHR/EMR) und bald auch Daten von intelligenten Pillen, benötigt die Pharmaindustrie Lösungen, die Daten flexibel speichern, erweitern, umwandeln, abgleichen, gemeinsam nutzen und analysieren. Die Systeme müssen mit den Daten mitwachsen und sie im gesamten Unternehmen verfügbar machen. Generische Analysetools und Data Lakes haben nicht dazu beigetragen, die Produktivität und Rentabilität zu steigern. Es werden neue und bessere Ansätze benötigt.
Erfahren Sie mehr:
- Download „Connecting the Dots: Datenanwendungen für die lebensrettende Forschung“
- Melden Sie sich für unser Webinar „Daten aus klinischen Studien verstehen“ an .
- Kontaktieren Sie uns, wir helfen Ihnen gerne!