A/B Testing Your Search Engine with Fusion 4.0
From head tail rewriting to recommendations and collaborative filtering based boosting, Lucidworks Fusion offers a whole host of strategies to help you improve the relevance of your search results. But discovering which set of strategies works best for your users can be a daunting task. Fusion’s new experiment management framework helps you A/B test different approaches and discover what works best for your system.
What is A/B Testing?
A/B testing is, essentially, a way to compare two or more variants of something to determine which performs better, according to certain metrics. In search, the variants in an A/B test are typically different search pipelines you want to compare; the metrics are typically aspects of user behavior you want to analyze. For example, let’s say you want to see how enabling Fusion’s item to item recommendation boosting stage impacts query click through rate.
You would begin by creating two pipelines, one with a baseline relevance measurement and one with that default plus item to item recommendations enabled.
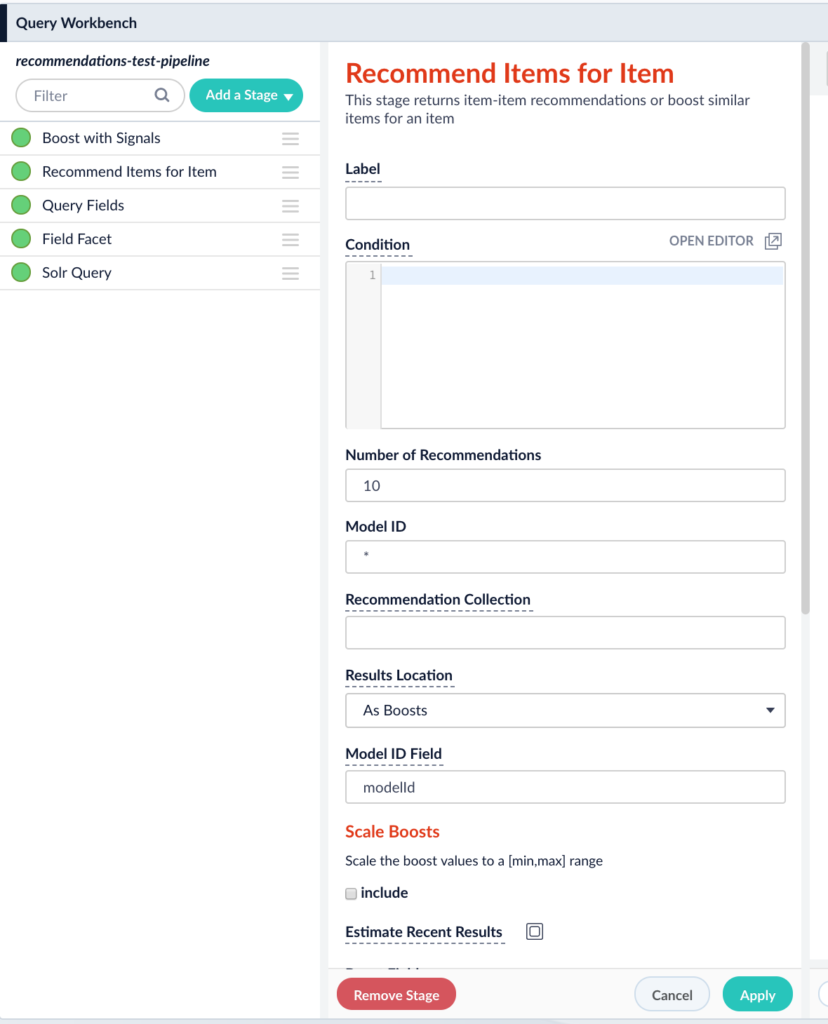
Fusion has a compare tool that enables you to query and see results for two pipelines side by side.
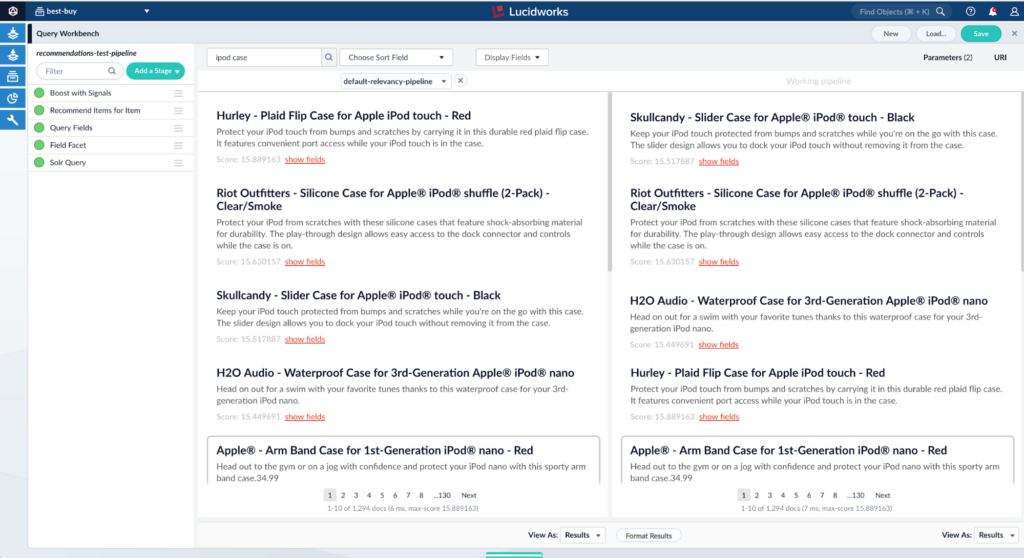
As you can see, for the particular query ipod case, both pipelines are giving different results, but both seems reasonable. How do we determine which is better? Let’s let our system’s users tell us. Let’s launch an experiment to see which pipeline gives a higher click through rate. This will tell us which pipeline gives more relevant results for our particular users.
To set up an experiment, navigate to the experiment manager in Fusion. Select the two pipelines as your variants and CTR as your metric. When you are setting up your variants you will see the option to select what varies in each variant. This is essentially the parameter you plan on changing between your variants.
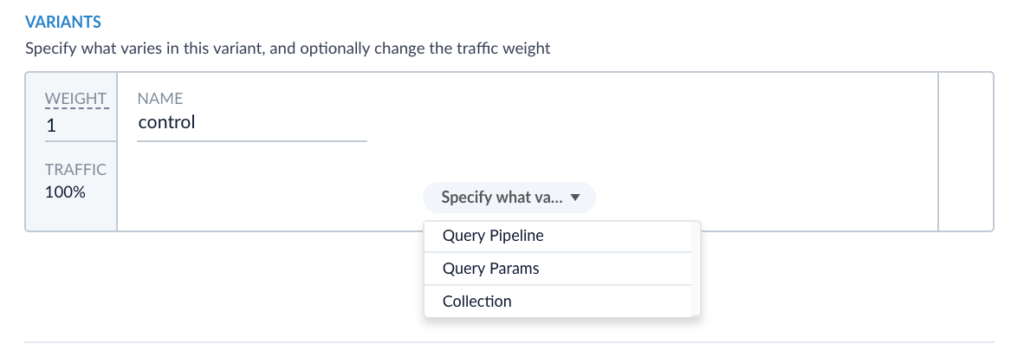
Fusion allows you to vary the pipeline, parameters, or collection. In this case we are comparing two query pipelines so I will select Query Pipeline for both variants. Also note, on the left, that we can specify how much traffic gets routed to each variant. In this case, since we have a default pipeline and we just want to see if enabling the recommendation stage improves the pipeline, lets route less traffic to the recommendations pipeline and keep most of our users looking at the default “good” search results we already have. An 80/20 split seems reasonable, so I am going to adjust the weight on the primary variant to be 8 and on the secondary variant to be 2.
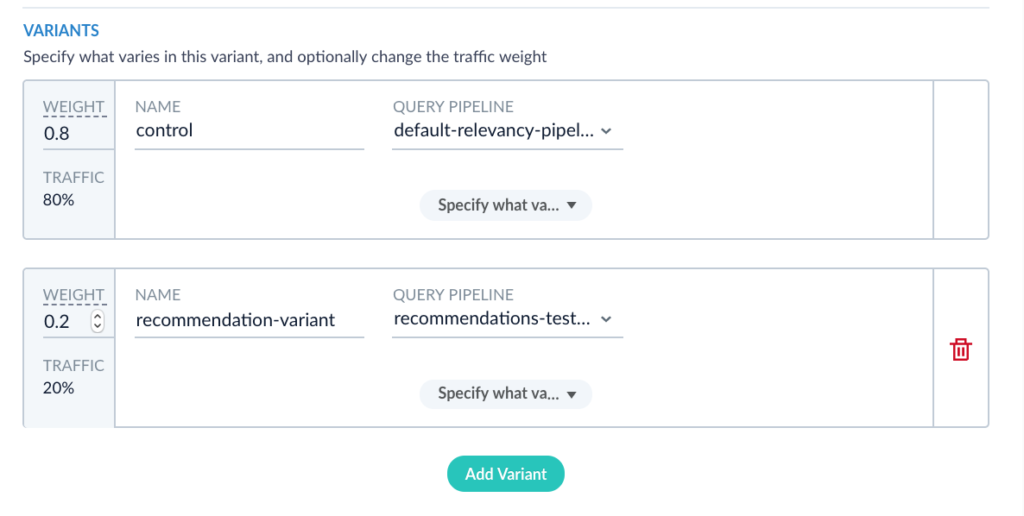
This means 80% of the traffic is going to the default pipeline and 20% is going to our experimental variant.
Fusion also offers a number of metrics that you can compute for each variant.
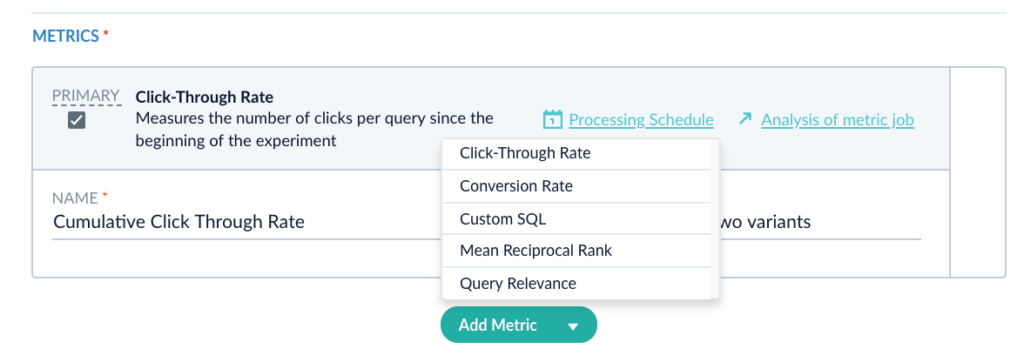
You can select as many or as few of these metrics as you would like. For the purposes of this experiment, let’s focus on click through rate. For more info on the other metrics refer to our documentation here.
Once you have your experiment configured and saved, your page should look something like this. Click Save.
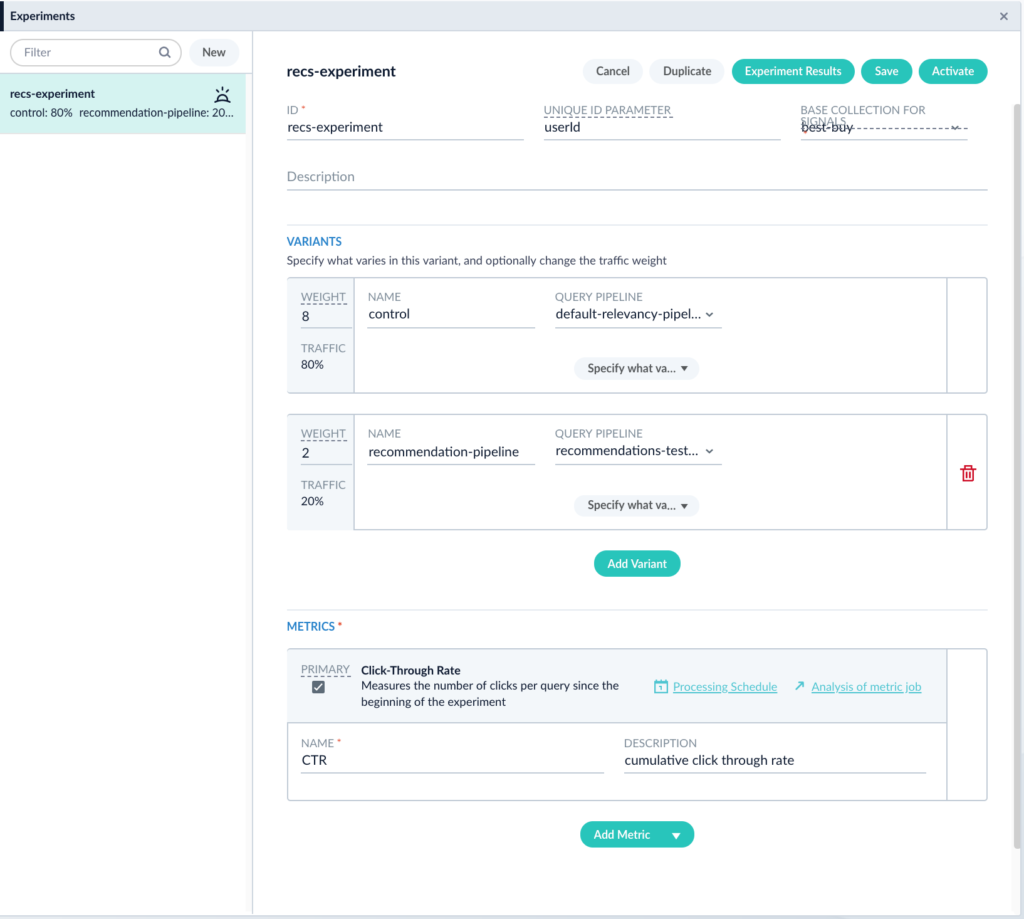
In order to start gathering data for an experiment, the experiment must be linked with either a query profile or a query pipeline. This way, whenever a user hits the API endpoint associated with the query profile or the query pipeline, they will be automatically placed in the experiment and routed to a particular variant. Let’s link this experiment with the default query profile associated with my app. For more on query profiles see our documentation here.
You should see the enable experimentation check box. Select the experiment we just set up and click Save. Then hit Run Experiment. The screen should now look like this:
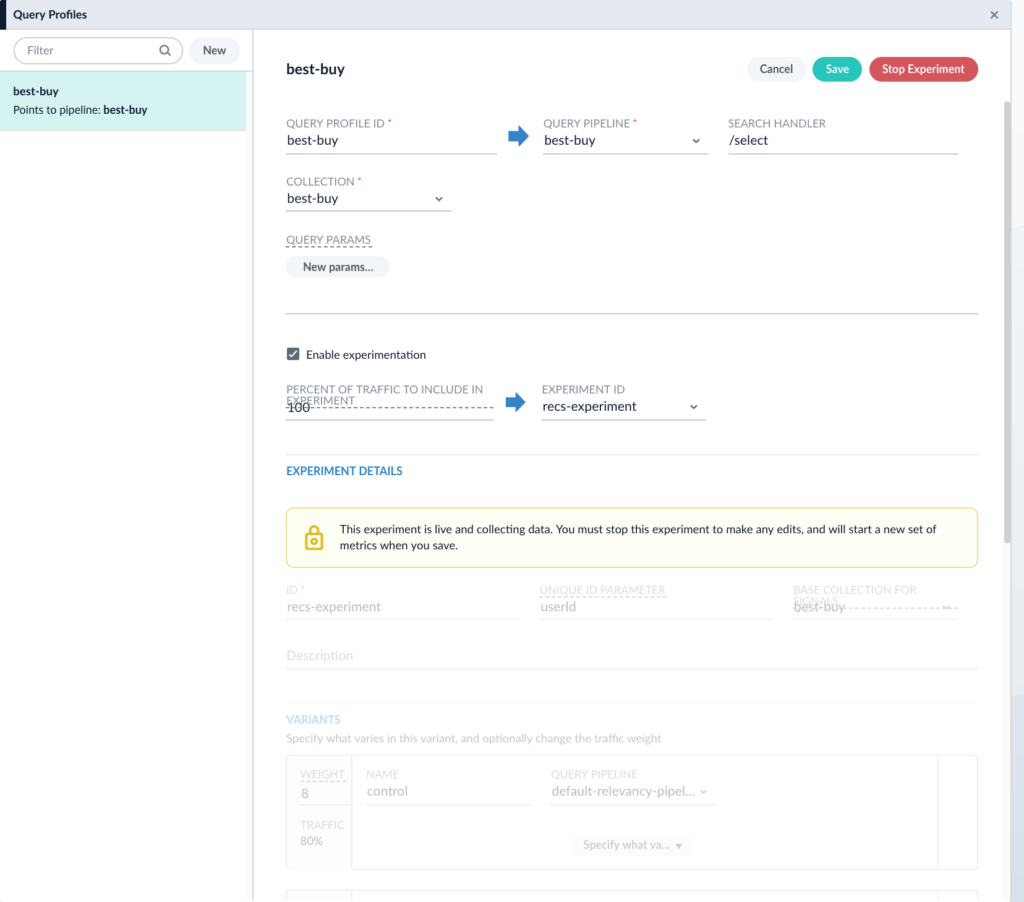
Once an experiment is running, it is locked. This means you cannot change the variants or the collected metrics without stopping and restarting the experiment. This is to safeguard against collecting inaccurate metrics. Now we have a running experiment! Every time a user hits the endpoint at the end of the query profile, they will be routed into this experiment.

80% of users that hit that endpoint will see the results coming from the default-relevancy-pipeline and 20% will see the results coming from the recommendations-test-pipeline. Now let’s examine the results of the experiment. Going back to the experiment manager and selecting the experiment we just created brings up an “Experiment Results” button. Clicking it will take you to a page that looks like this:
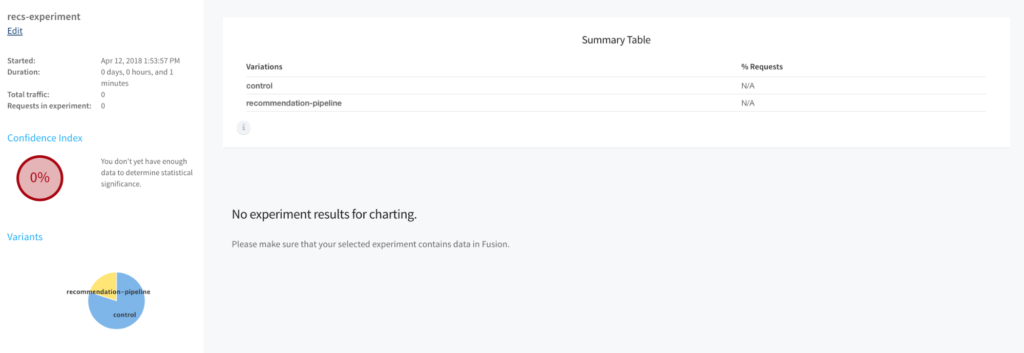
You’ll see that the confidence index is zero. This means there is not enough traffic running through your experiment to display statistically significant data yet. Let’s wait for a while, let the users interact with the system, and come back to the results. After some time, the results should look more like this:
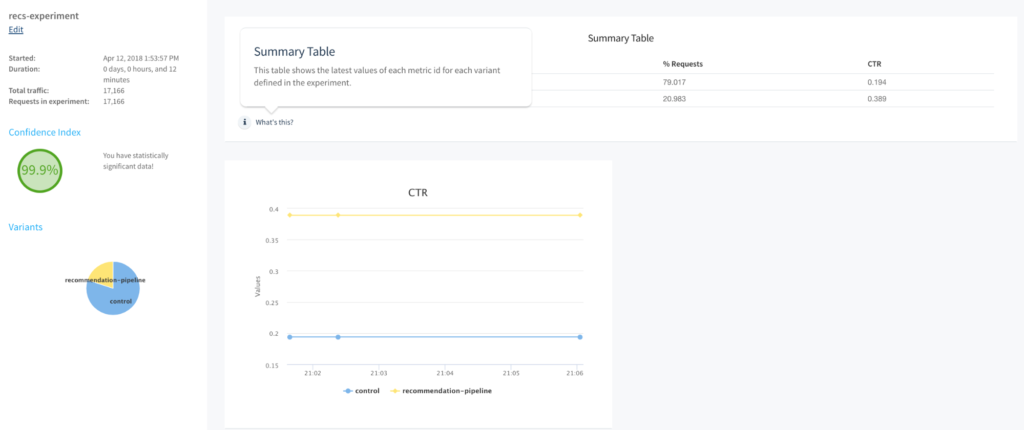
Looks like the recommendation pipeline is consistently doing better. Now that we know this, we can end the experiment and deploy the recommendation pipeline into production. Fusion Experiment Management has helped us collect relevant data and make an informed decision about the search system!
A/B testing is a critical part of a functioning search architecture. Experimentation allows you to collect actionable data about how your users are interacting with the search system.
Next Steps
- Learn more about Fusion 4 from our previously recorded Fusion 4 Overview webinar.
- Contact us, we’d love to hear from you.