Data.gov on Solr
At ApacheCon this week I presented “Rapid Prototyping with Solr”. This is the third time I’ve given a presentation with the same title. In the spirit of the rapid prototyping theme, each time I’ve created a new prototype just a day or so prior to presenting it. At Lucene EuroCon the prototype used attendee data, a treemap visualization, and a cute little Solr-powered “app” for picking attendees at random for the conference giveaways. For a recent Lucid webinar the prototype was more general purpose, bringing in and making searchable rich documents and faceting on file types with a pie chart visualization.
This time around, the data set I chose was Data.gov’s catalog of datasets, which fit with the ApacheCon open source aura, and Lucid Imagination’s support of Open Source for America, which helps to advocate for open source in the US Federal Government. The prototype built includes faceting browsing, query term suggest, hit highlighting, result clustering, spell checking, document detail, and a bonus Venn diagram visualization.
The prototype was built with these steps:
- Install Lucidworks for Solr
- Grab the Data.gov catalog CSV file
- Iterate a bit with Solr’s CSV update handler (the funnest way to get data into Solr) and a little Solr schema tinkering
- Adjusted the Solr configuration and UI templates to get a nice look and feel, adding in a document detail page and a Venn diagram visualization comparing query overlaps
Voilà (click the images for large view):
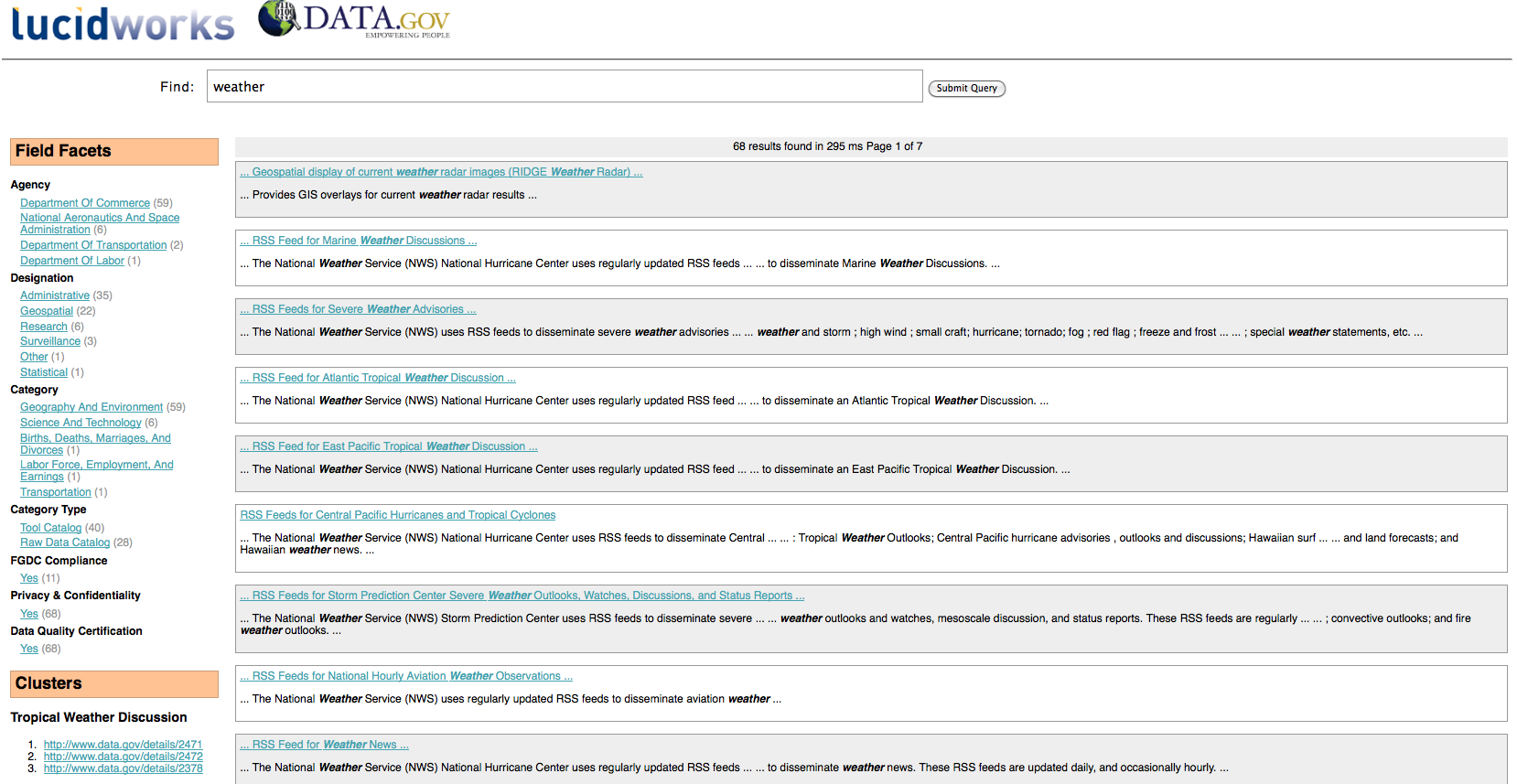
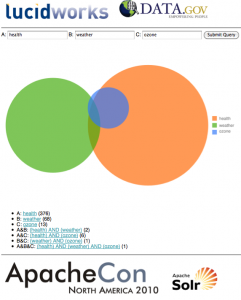
This isn’t the first time we’ve toyed with Data.gov data… earlier this year, Hoss demonstrated Solr’s stats component on another of Data.gov’s data sets.
My ApacheCon slides are published at Slideshare and embedded here:
https://www.slideshare.net/erikhatcher/rapid-prototyping-with-solr-5675936
All the code and instructions for running the entire prototype yourself can be found here: https://github.com/erikhatcher/solr-rapid-prototyping/tree/master/ApacheCon2010