What Is Data Science?
Don’t get me wrong, Data Science is really cool – trust me. I say this (tongue in cheek of course) because most of the information that you see online about Data Science is (go figure) written by Data “Scientists”. And you can usually tell – they give you verbiage and mathematical formulas that only they understand so you have to trust them when they say things like – “it can easily be proven that …” – that a) it has been proven and b) that it is easy – for them, not for you. That’s not an explanation, it’s a cop out. But to quote Bill Murray’s line from Ghostbusters: “Back off man, I’m a Scientist”. Science is complex and is difficult to write about in a way that is easy for non-scientists to understand. I have a lot of experience here. As a former scientist, I would have difficulty at parties with my wife’s friends because when they asked me what I do, I couldn’t really tell them the gory details without boring them to death (or so I thought) so I would give them a very high level version. My wife used to get angry with me for condescending to her friends when they wanted more details and I would demur – so OK its hard and I punted – I told her that I was just trying to be nice – not curmudgeonly. But if we are smart enough to conceive of these techniques, we should be smart enough to explain them to dummies. Because if you can explain stuff to dummies, then you really understand it too.
Lucy – you’ve got lots of ‘splainin’ to do
Don’t you love it when an article starts out with seemingly english-like explanations (the promise) and quickly degenerates into data science mumbo jumbo. Your first clue that you are in for a rough ride is when you hit something like this – with lots of Greek letters and other funny looking symbols:
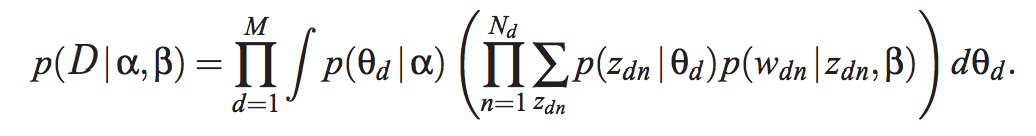
and paragraphs like this:
“In ordinary language, the principle of maximum entropy can be said to express a claim of epistemic modesty, or of maximum ignorance. The selected distribution is the one that makes the least claim to being informed beyond the stated prior data, that is to say the one that admits the most ignorance beyond the stated prior data.” (from Wikipedia article on the “Principle of Maximum Entropy“)
Huh? Phrases like “epistemic modesty” and “stated prior data” are not what I would call “ordinary language”. I’ll take a shot at putting this in plain english later when I discuss Information Theory. “Maximum Ignorance” is a good theme for this blog though – just kidding. But to be fair to the Wikipedia author(s) of the above, this article is really pretty good and if you can get through it – with maybe just a Tylenol or two or a beverage – you will have a good grasp of this important concept. Information Theory is really cool and is important for lots of things besides text analysis. NASA uses it to clean up satellite images for example. Compression algorithms use it too. It is also important in Neuroscience – our sensory systems adhere to it big time by just encoding things that change – our brains fill in the rest – i.e. what can be predicted or inferred from the incoming data. More on this later.
After hitting stuff like above – since the authors assume that you are still with them – the rest of the article usually leaves you thinking more about pain killers than the subject matter that you are trying to understand. There is a gap between what they know and what you do and the article has not helped much because it is a big Catch-22 – you have to understand the math and their jargon before you can understand the article – and if you already had that understanding, you wouldn’t need to read the article. Jargon and complex formulas are appropriate when they are talking to their peers because communication is more efficient if you can assume prior subject mastery and you want to move the needle forward. When you try that with dummies you crash and burn. (OK, not dummies per se, just ignorant if that helps you feel better. As my friend and colleague Erick Erickson would say, we are all ignorant about something – and you guessed it, he’s a curmudgeon too.) The best way to read these articles is to ignore the math that you would need a refresher course in advanced college math to understand (assuming that you ever took one) and just trust that they know what they’re talking about. The problem is that this is really hard for programmers to do because they don’t like to feel like dummies (even though they’re not).
It reminds me of a joke that my dad used to tell about Professor Norbert Weiner of MIT. My dad went to MIT during WWII (he was 4-F because of a chemistry experiment gone wrong when he was 12 that took his left hand) – and during that time, many of the junior faculty had been drafted into the armed forces to work on things like radar, nuclear bombs and proximity fuses for anti-aircraft munitions. Weiner was a famous mathematician noted for his work in Cybernetics and non-linear mathematics. He was also the quintessential absent minded professor. The story goes that he was recruited (most likely ordered by his department chairman) to teach a freshman math course. One day, a student raised his hand and said “Professor Weiner, I was having trouble with problem 4 on last nights assignment. Could you go over problem 4 for us?” Weiner says, “Sure, can somebody give me the text book?” So he reads the problem, thinks about it for a minute or two, turns around and writes a number on the board and says, “Is that the right answer?” The student replies, “Yes, Professor that is what is in the answer section in the book, but how did you get it? How did you solve the problem?” Weiner replies, “Oh sorry, right.” He erases the number, looks at the book again, thinks for another minute or so, turns back to the board and writes the same number on the board again. “See”, he says triumphantly, “I did it a different way.”
The frustration that the students must have felt at that point is the same frustration that non-data scientists feel when encountering one of these “explanations”.
So lets do some ‘splainin’. I promise not to use jargon or complex formulas – just english.
OK dummies, so what is Data Science?
Generally speaking, data science is deriving some kind of meaning or insight from large amounts data. Data can be textual, numerical, spatial, temporal or some combination of these. Two branches of mathematics that are used to do this magic are Probability Theory and Linear Algebra. Probability is about the chance or likelihood that some observation (like a word in a document) is related to some prediction such as a document topic or a product recommendation based on prior observations of the huge numbers of user choices. Linear algebra is the field of mathematics that deals with systems of linear equations (remember in algebra class the problem of solving multiple equations with multiple unknowns? Yeah – much more of that). Linear algebra deals with things called Vectors and Matrices. A vector is a list of numbers. A vector in 2 dimensions is a point on a plane – a pair of numbers – it has an X and a Y coordinate and can be characterized by a length and angle from the origin – if that is too much math so far, then you really are an ignorant dummy. A matrix is a set of vectors – for example a simultaneous equation problem can be expressed in matrix form by lining up the coefficients – math-eze for constant numbers so if one of the equations is 3x – 2y + z = 5, the coefficients are 3, -2, and 1 – which becomes a row in the coefficient matrix, or 3, -2, 1 and 5 for a row in the augmented or solution matrix. Each column in the matrix of equations is a vector consisting of the sets of x, y and z coefficients.
Linear algebra typically deals with many dimensions that are difficult or impossible to visualize, but the cool thing is that the techniques that have been worked out can be used on any size vector or matrix. It gets much worse than this of course, but the bottom line is that it can deal with very large matrices and has techniques that can reduce these sets to equivalent forms that work no matter how many dimensions that you throw at it – allowing you to solve systems of equations with thousands or millions of variables (or more). The types of data sets that we are dealing with are in this class. Pencil and paper won’t cut it here or even a single computer so this is where distributed or parallel analytic frameworks like Hadoop and Spark come in.
Mathematics only deals with numbers so if a problem can be expressed numerically, you can apply these powerful techniques. This means that the same methods can be used to solve seemingly disparate problems like semantic topic mapping and sentiment analysis of documents to recommendations of music recordings or movies based on similarity to tunes or flicks that the user likes – as exemplified by sites like Pandora and Netflix.
So for the text analytics problem, the first head scratcher is how to translate text into numbers. This one is pretty simple – just count words in documents and determine how often a given word occurs in each document. This is known as term frequency or TF. The number of documents in a group that contain the word is its document frequency or DF. The ratio of these two TF/DF or term frequency multiplied by inverse document frequency (1/DF) is a standard number known affectionately to search wonks as TF-IDF (yeah, jargon has a way of just weaseling its way in don’t it?) I mention this because even dummies coming to this particular blog have probably heard this one before – Solr used to use it as its default way of calculating relevance. So now you know what TF-IDF means, but why is it used for relevance? (Note that as of Solr 6.0 TF-IDF is no longer the default relevance algorithm, it has been replaced by a more sophisticated method called BM25 which stands for “Best Match 25” a name that gives absolutely no information at all – it still uses TF-IDF but adds some additional smarts.) The key is to understand why TF-IDF was used, so I’ll try to ‘splain that.
Some terms have more meaning or give you more information about what a document is about than others – in other words, they are better predictors of what the topic is. If a term is important to a topic, it stands to reason that it will be used more than once in documents about that topic, maybe dozens of times (high TF) but it won’t be often used in documents that are not about the subject or topic to which it is important – in other words, it’s a keyword for that subject. Because it is relatively rare in the overall set of documents it will have low DF so the inverse 1/DF or IDF will be high. Multiplying these two (and maybe taking the logarithm just for kicks ‘cause that’s what mathematicians like to do) – will yield a high value for TF-IDF. There are other words that will have high TF too, but these tend to be common words that will also have high DF (hence low IDF). Very common words are manually pushed out of the way by making them stop words. So the relevance formula tends to favor more important subject words over common or noise words. A classic wheat vs chaff problem.
So getting back to our data science problem, the reasoning above is the core concept that these methods use to associate topics or subjects to documents. What these methods try to do is to use probability theory and pattern detection using linear algebraic methods to ferret out the salient words in documents that can be used to best predict their subject areas. Once we know what these keywords are, we can use them to detect or predict the subject areas of new documents (our test set). In order to keep up with changing lingo or jargon, this process needs to be repeated from time to time.
There are two main ways that this is done. The first way called “supervised learning” uses statistical correlation – a subject matter expert (SME) selects some documents called “training documents” and labels them with a subject. The software then learns to associate or correlate the terms in the training set with the topic that the human expert has assigned to them. Other topic training sets are also in the mix here so we can differentiate their keywords. The second way is called “unsupervised learning” because there are no training sets. The software must do all the work. These methods are also called “clustering” methods because they attempt to find similarities between documents and then label them based on the shared verbiage that caused them to cluster together.
In both cases, the documents are first turned into a set of vectors or a matrix in which each word in the entire document set is replaced by its term frequency in each document, or zero if the document does not have the word. Each document is a row in the matrix and each column has the TF’s for all of the documents for a given word, or to be more precise, token (because some terms like BM25 are not words). Now we have numbers that we can apply linear algebraic techniques to. In supervised learning, the math is designed to find the terms that have a higher probability of being found in the training set docs for that topic than in other training sets. Two probability theorems that come into play are Bayes’ Theorem which deals with conditional probabilities and Information Theory. A conditional probability is like the probability that you are a moron if you text while driving (pretty high it turns out – and would be a good source of Darwin awards except for the innocent people that also suffer from this lunacy.) In our case, the game is to compute the conditional probabilities of finding a given word or token in a document and the probability that the document is about the topic we are interested in – so we are looking for terms with a high conditional probability for a given topic – aka the key terms.
Bayes’ Theorem states that the probability of event A given that event B has occurred – p(A|B) – is equal to the probability that B has occurred given A – p(B|A) – times the overall probability that A can happen – p(A) – divided by the overall probability that B can happen – p(B). So if A is the probability that a document is about some topic and B is the probability that a term occurs in the document, terms that are common in documents about topic A but rare otherwise will be good predictors. So if we have a random sampling of documents that SMEs have classified (our training set), the probability of topic A is the fraction of documents classified as A. p(B|A) is the frequency of a term in these documents and p(B) is the term’s frequency in the entire training set. Keywords tend to occur together so even if any one keyword does not occur in all documents classified the same way (maybe because of synonyms), it may be that documents about topic A are the only ones (or nearly) that contain two or three of these keywords. So, the more keywords that we can identify, the better our coverage of that topic will be and the better chance we have of correctly classifying all of them (what we call recall). If this explanation is not enough, check out this really good article on Bayes’ Theorem – its also written for dummies.
Information Theory looks at it a little differently. It says that the more rare an event is, the more information it conveys – keywords have higher information than stop words in our case. But other words are rare too – esoteric words that authors like to use to impress you with their command of the vocabulary but are not subject keywords. So there are noise words that are rare and thus harder to filter out. But noise words of any kind tend to have what Information Theorists call high Entropy – they go one way and then the other whereas keywords have low entropy – they consistently point in the same direction – i.e., give the same information. You may remember Entropy from chemistry or physics class – or maybe not if you were an Arts major who was in college to “find” yourself. In Physics, entropy is the measure of disorder or randomness – the Second Law of Thermodynamics states that all systems tend to a maximum state of disorder – like my daughter’s room. So noise is randomness, both in messy rooms and in text analytics. Noise words can occur in any document regardless of context, and in both cases, they make stuff harder to find (like a matching pair of socks in my daughter’s case). Another source of noise are what linguists call polysemous words – words with multiple meanings in different contexts – like ‘apple’ – is it a fruit or a computer? (That’s an example of the author showing off that I was talking about earlier – ‘polysemous’ has way high IDF, so you probably don’t need to add it to your every day vocabulary. Just use it when you want people to think that you are smart.) Polysemous words also have higher entropy because they simultaneously belong to multiple topics and therefore convey less information about each one – i.e., they are ambiguous.
The more documents that you have to work with, the better chance you have to detect the words with the most information and the least entropy. Mathematicians like Claude Shannon who invented Information Theory have worked out precise mathematical methods to calculate these values. But there is always uncertainty left after doing this, so the Principle of Maximum Entropy says that you should choose a classification model that constrains the predictions by what you know, but hedges its bets so to speak to account for the remaining uncertainties. The more you know – i.e. the more evidence that you have, the maximum entropy that you need to allow to be fair to your “prior stated data” will go down and the model will become more accurate. In other words, the “maximum ignorance” that you should admit to decreases (of course, you don’t have to admit it – especially if you are a politician – you just should). Ok, these are topics for advanced dummies – this is a beginners class. The key here is that complex math has awesome power – you don’t need to fully understand it to appreciate what it can do – just hire Data Scientists to do the heavy lifting – hopefully ones that also minored in English Lit so you can talk to them – (yes, a not so subtle plug for a well rounded Liberal Arts Education!). And on your end of the communication channel as Shannon would say – knowing a little math and science can’t hurt.
In unsupervised learning, since both the topics and keywords are not known up front, they have to be guessed at, so we need some kind of random or ‘stochastic’ process to choose them (like Dirichlet Allocation for example or a Markov Chain). After each random choice or “delta”, we see if it gives us a better result – a subset of words that produce good clustering – i.e., small sets of documents that are similar to each other but noticeably different from other sets. Similarity between the documents is determined by some distance measure. Distance in this case is like the distance between points in the 2-D example I gave above but this time in a high-dimensional space of the matrix – but it’s the same math and is known as Euclidian distance. Another similarity measure just focuses on the angles between the vectors and is known as Cosine Similarity. Using linear algebra, when we have a vector of any dimension we can compute distances or angles in what we call a “hyper-dimensional vector space” (cool huh? – just take away ‘dimensional’ and ‘vector’ and you get ‘hyperspace’. Now all we need is Warp Drive). So what we need to do is to separate out the words that maximize the distance or angle between clusters (the keywords) from the words that tend to pull the clusters closer together or obfuscate the angles (the noise words).
The next problem is that since we are guessing, we will get some answers that are better than others because as we take words in and out of our guessed keywords list, the results get better and then get worse again so we go back to the better alternative. (This is what the Newton method does to find things like square roots). The rub here is that if we had kept going, the answer might have gotten better again so what we stumbled on is what is known as a local maximum. So we have to shake it up and keep going till we can find the maximum maximum out there – the global maximum. So we do this process a number of times until we can’t get any better results (the answers “converge”), then we stop. As you can imagine all of this takes a lot of number crunching which is why we need powerful distributed processing frameworks such as Spark or Hadoop to get it down to HTT – human tolerable time.
The end results are pretty good – often exceeding 95% accuracy as judged by human experts (but can we assume that the experts are 100% accurate – what about human error? Sorry about that, I’m a curmudgeon you know – computers as of yet have no sense of humor so you can’t tease them very effectively.) But because of this pesky noise problem, machine learning algorithms sometimes make silly mistakes – so we can bet that the Data Scientists will keep their jobs for awhile. And seriously, I hope that this attempt at ‘splainin’ what they do entices you dummies to hire more of them. Its really good stuff – trust me.