Exploring Lucene’s Indexing Code: Part 2
Previous: Exploring Lucene’s Indexing Code: Part 1
A trace of addDocument is pretty intense, so we are going to have to start at an even higher level I think.
Using some basic IR knowledge, we know that addDocument is going to use our Analyzer to break up each field in the given document, and use the resulting terms to build an inverted index. At its simplest, an inverted index might just be a list of postings, mapping each term to a list of document ids.
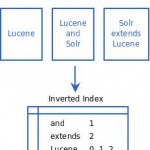
A real implementation will need more info than just which documents you can find a term in – Lucene also optionally stores document frequency for each term, as well as positions for each document. You can imagine squeezing this type of data into the simple posting list above. Rather than Lucene – > <docnum> + you might have Lucene -> <docFreq> (<docnum> <occurences> <position>^(occurences) ) +. Lucene can also store other info – termvectors, stored (uninverted) fields, a score normalization factor, payloads, etc.
So, back to that friendly high level: addDocument is going to take our Document of fields (mapping field names to values and given attributes) and break the text from each field into terms. This is the start of the inversion process – we are going to take document centric data and invert it to be term centric. A given number of documents will be built into a sub index, called a segment in Lucene. The given segment will allow us to traverse quickly from any given term in the documents in that segment to the overall document frequency for that term (only for that segment), which documents the term occurs in, and at what positions in those documents. The IndexWriter can collect multiple documents in RAM and then flush those documents as a new segment at given points, either by configuration or user interaction. At that time, the n document segment will remain unmodified until Lucene merges it into larger segments (there is a small exception with deletes and norm changes – these are masked on the fly until merged/written into the index structure). A MergePolicy controls how Lucene merges segments over time.
So we know the IndexWriter will collect document posting lists in RAM and then eventually write a segment for a given number of documents. We can look at Lucene’s file formats page to learn what the written segment will look like.
For now, we will ignore the simple compression techniques that Lucene uses (if you are interested, check out the info on the Lucene Index File Formats page), as well as the optional compound file format. Even if you choose to use the compound file format, the underlying data structures will remain the same.
To help get our head around things, lets take a closer look at the files that make up a Lucene index. Some of the information is simplified for illustration purposes.
Per Index Files
Segments File (segments_N, segments.gen)
The Segments File references the active segments in the index. Lucene uses a write once scheme for index files (in general, files are not modified) and when segments are merged or added, a new generation is created. A generation is simply a collection of segments – some may have belonged to a previous generation, and some may be newly created segments. The _N in the segments file name refers to the generation that particular segment_N file tracks. It will point you to the segments to use if you want to read that particular generation. The segments file with the highest _N is the latest generation. By default, Lucene removes older generations when it can, but you can use a pluggable IndexDeletionPolicy to keep older generations around.
segments.gen stores the latest generation, _N, and is used as a fall back in case the current generation cannot be accurately determined by simply listing the directory and choosing the segments_N file with the largest _N.
Lock File
Depending on the LockFactory used, there may be an index Lock file. By default, this will be located in the Lucene index directory, but the location is configurable.
Per Segment Files
The Field Info File (*.fnm)
This file records the index time attributes for every field.

Term Dictionary (*.tis, *.tii)
The Term Dictionary stores how to navigate the various other files for each term. At a simple, high level, the Term Dictionary will tell you where to look in the frq and prx files for further information related to that term. Terms are stored in alphabetical order for fast lookup. Further, another data structure, the Term Info Index, is designed to be read entirely into memory and used to provide random access to the “tis” file. Other book keeping (skip lists, index intervals) is also tracked with the Term Dictionary.
Term Frequencies (*.frq)
The .frq file contains the ids of documents which contain each term, along with the frequency of the term in that document (unless you use omitTf on that field). Skip list data is also stored in this file. See Skip Lists.
Term Positions (*.prx)
The .prx file contains the lists of positions that each term occurs at within documents. If all fields use omitTf, there will not be a Term Positions data structure.
Stored Fields (*.fdx *.fdt)
Stored fields are the original raw text values that were given to Lucene. This is not really part of the inverted index structure – its simply a mapping from document id’s to stored field data. The Field Index file (*.fdx) is used to map from document id to the position in the Field Data file (*.fdt) where the stored field data resides.
Term Vectors (*.tvx, *.tvd, *.tvf)
TermVectors are optional data structures that store additional info and data about the current segment. Support comes in three files – the first (Document Index *.tvx) indexes into the other two by document id.
The Document file (*.tvf) lists which fields have term vectors and indexes into the TermVector field file (*.tvf).
The TermVector field file (*.tvf) contains, for each field that has a TermVector stored, a list of the terms, their frequencies and, optionally, position and offset information.
Norms (*.nrm)
Norms are an index time normalization factor that can be factored into scoring. Document and field boosts as well as length normalization are applied with norms. When in memory, norms occupy one byte per document for each field with norms on, even if only one document has norms on for that field. The Norms file does some book keeping and stores the byte for each document. If you modify norms, modifications will be tracked in a new norms file, seg_prefix_X.sN ,were N is the field number, and X is the norms generation.
Deleted Documents (*.del)
Tracks which documents have been deleted from the index, but have not yet been merged out. This file only exists if the index contains un-merged deletes.
Continued…
With this knowledge we can see how Lucene sets up the inverted index. The Term Dictionary quickly points us to various information given a query term – we can follow its pointer to document ids, term positions, stored fields, and term vector information. Now we can see where we are going with IndexWriter.addDocument(). It must take our Document, break up the text into terms, and then build the above referenced structures.
Next, we start by exploring the Lucene indexing chain that is kicked off with addDocument…