Indexing Performance in Solr 5.2 (now twice as fast)
About this time last year (June 2014), I introduced the Solr Scale Toolkit and published some indexing performance metrics for Solr 4.8.1. Solr 5.2.0 was just released and includes some exciting indexing performance improvements, especially when using replication. Before we get into the details about what we fixed, let’s see how things have improved empirically.
Using Solr 4.8.1 running in EC2, I was able to index 130M documents into a collection with 10 shards and replication factor of 2 in 3,727 seconds (~62 minutes) using ten r3.2xlarge instances; please refer to my previous blog post for specifics about the dataset. This equates to an average throughput of 34,881 docs/sec. Today, using the same dataset and configuration, with Solr 5.2.0, the job finished in 1,704 seconds (~28 minutes), which is an average 76,291 docs/sec. To rule out any anomalies, I reproduced these results several times while testing release candidates for 5.2. To be clear, the only notable difference between the two tests is a year of improvements to Lucene and Solr!
So now let’s dig into the details of what we fixed. First, I cannot stress enough how much hard work and sharp thinking has gone into improving Lucene and Solr over the past year. Also, special thanks goes out to Solr committers Mark Miller and Yonik Seeley for helping identify the issues discussed in this post, recommending possible solutions, and providing oversight as I worked through the implementation details. One of the great things about working on an open source project is being able to leverage other developers’ expertise when working on a hard problem.
Too Many Requests to Replicas
One of the key observations from my indexing tests last year was that replication had higher overhead than one would expect. For instance, when indexing into 10 shards without replication, the test averaged 73,780 docs/sec, but with replication, performance dropped to 34,881. You’ll also notice that once I turned on replication, I had to decrease the number of Reducer tasks (from 48 to 34) I was using to send documents to Solr from Hadoop to avoid replicas going into recovery during high-volume indexing. Put simply, with replication enabled, I couldn’t push Solr as hard.
When I started digging into the reasons behind replication being expensive, one of the first things I discovered is that replicas receive up to 40x the number of update requests from their leader when processing batch updates, which can be seen in the performance metrics for all request handlers on the stats panel in the Solr admin UI.
Batching documents into a single request is a common strategy used by client applications that need high-volume indexing throughput. However, batches sent to a shard leader are parsed into individual documents on the leader, indexed locally, and then streamed to replicas using ConcurrentUpdateSolrClient. You can learn about the details of the problem and the solution in SOLR-7333. Put simply, Solr’s replication strategy caused CPU load on the replicas to be much higher than on the leaders, as you can see in the screenshots below.
CPU Profile on Leader
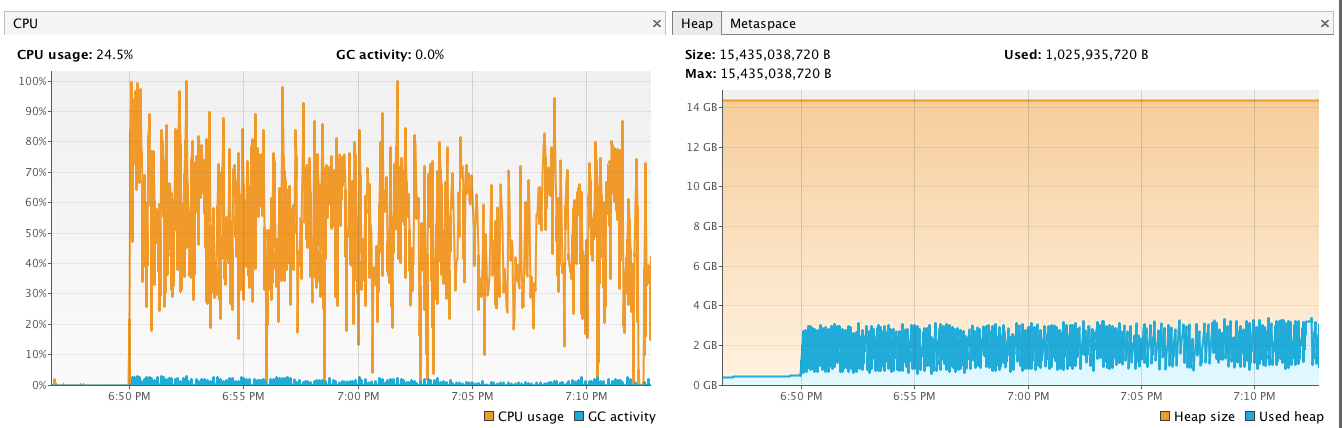
CPU Profile on Replica (much higher than leader)
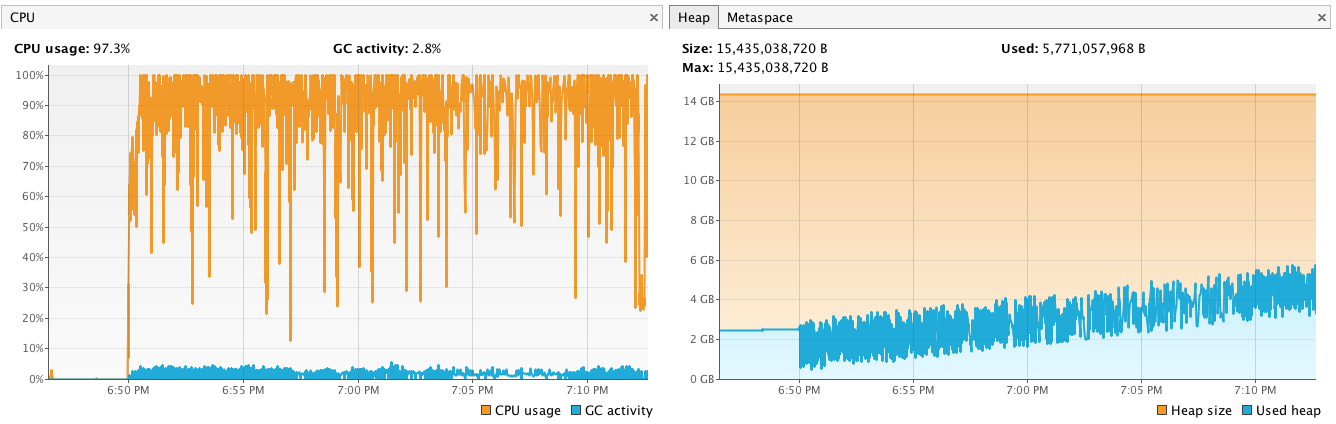
Ideally, you want all servers in your cluster to have about the same amount of CPU load. The fix provided in SOLR-7333, helps reduce the number of requests and CPU load on replicas by sending more documents from the leader per request when processing a batch of updates. However, be aware that the batch optimization is only available when using the JavaBin request format (the default used by CloudSolrClient in SolrJ); if your indexing application sends documents to Solr using another format (JSON or XML), then shard leaders won’t utilize this optimization when streaming documents out to replicas. We’ll likely add a similar solution for processing other formats in the near future.
Version Management Lock Contention
Solr adds a _version_ field to every document to support optimistic concurrency control. Behind the scenes, Solr’s transaction log uses an array of version “buckets” to keep track of the highest known version for a range of hashed document IDs. This helps Solr detect if an update request is out-of-date and should be dropped.
Mark Miller ran his own indexing performance tests and found that expensive index housekeeping operations in Lucene can stall a Solr indexing thread. If that thread happens to be holding the lock on a version bucket, it can stall other threads competing for the lock. To address this, we increased the default number of version buckets used by Solr’s transaction logs from 256 to 65536, which helps reduce the number of concurrent requests that are blocked waiting to acquire the lock on a version bucket. You can read more about this problem and solution in SOLR-6820. We’re still looking into how to deal with Lucene using the indexing thread to performance expensive background operations but for now, it’s less of an issue.
Expensive Lookup for a Document’s Version
When adding a new document, the leader sets the _version_ field to a long value based on the CPU clock time; incidentally, you should use a clock synchronization service for all servers in your Solr cluster. Using the YourKit profiler, I noticed that replicas spent a lot of time trying to lookup the _version_ for new documents to ensure update requests were not re-ordered. Specifically, the expensive code was where Solr attempts to find the internal Lucene ID for a given document ID. Of course for new documents, there is no existing version, so Solr was doing a fair amount of wasted work looking for documents that didn’t exist.
Yonik pointed out that if we initialize the version buckets used by the transaction log to the maximum value of the _version_ field before accepting new updates, then we can avoid this costly lookup for every new document coming into the replica. In other words, if a version bucket is seeded with the max value from the index, then when new documents arrive with a version value that is larger than the current max, we know this update request has not been reordered. Of course the max version for each bucket gets updated as new documents flow into Solr.
Thus, as of Solr 5.2.0, when a Solr core initializes, it seeds version buckets with the highest known version from the index, see SOLR-7332 for more details. With this fix, when a replica receives a document from its leader, it can quickly determine if the update was reordered by consulting the highest value of the version bucket for that document (based on a hash of the document ID). In most cases, the version on an incoming document to a replica will have a higher value than the version bucket, which saves an expensive lookup to the Lucene index and increases overall throughput on replicas. If by chance, the replica sees a version that is lower than the bucket max, it will still need to consult the index to ensure the update was not reordered.
These three tickets taken together achieve a significant increase in indexing performance and allows us to push Solr harder now. Specifically, I could only use 34 reducers with Solr 4.8.1 but was able to use 44 reducers with 5.2.0 and still remain stable.
Lastly, if you’re wondering what you need to do to take advantage of these fixes, you only need to upgrade to Solr 5.2.0, no additional configuration changes are needed. I hope you’re able to take advantage of these improvements in your own environment and please file JIRA requests if you have other ideas on how to improve Solr indexing performance. The Solr Scale Toolkit has been upgraded to support Solr 5.2.0 and the dataset I used is publicly shared on S3 if you want to reproduce these results.