

Integrating Storm and Solr
In this post I introduce a new open source project provided by Lucidworks for integrating Solr and Storm. Specifically, I cover features such as micro-buffering, data mapping, and how to send custom JSON documents to Solr from Storm. I assume you have a basic understanding of how Storm works, but if you need a quick refresher, please review the Storm concepts documentation.
As you read through this post, it will help to have the project source code on your local machine. After cloning https://github.com/Lucidworks/storm-solr, simply do: mvn clean package. This will create the unified storm-solr-1.0.jar in the target/ directory for the project.
The project discussed here started out as a simple bolt for indexing documents in Solr. My first pass at creating Solr bolt was quite simple, but then a number of questions came up that made my simple bolt not quite so simple. For instance, how do I …
- Separate my application business logic from Storm boilerplate code?
- Unit test application logic in my bolts and spouts?
- Run a topology locally while developing?
- Configure my Solr bolt to specify environment-specific settings like the ZooKeeper connection string needed by SolrCloud?
- Package my topology into something that can be deployed to a Storm cluster?
- Measure the performance of my components at runtime?
- Integrate with other services and databases when building a real-world topology?
- Map Tuples in my topology to a format that Solr can process?
This is just a small sample of the types of questions that arise when building a high-performance streaming application with Storm. I quickly realized that I needed more than just a Solr bolt. Hence, the project evolved into a toolset that makes it easy to integrate Storm and Solr, as well as addressing all of the questions raised above.
I’ll spare you the nitty-gritty details of the framework supporting Solr integration with Storm. If you’re interested, the README for the project contains more details about how the framework was designed.
Packaging and Running a Storm Topology
To begin, let’s understand how to run a topology in Storm. Effectively, there are two basic modes of running a Storm topology: local and cluster mode. Local mode is great for testing your topology locally before pushing it out to a remote Storm cluster, such as staging or production. For starters, you need to compile and package your code and all of its dependencies into a unified JAR with a main class that runs your topology.
For this project, I use the Maven Shade plugin to create the unified JAR with dependencies. The benefit of the Shade plugin is that it can relocate classes into different packages at the byte-code level to avoid dependency conflicts. This comes in quite handy if your application depends on 3rd party libraries that conflict with classes on the Storm classpath. You can look at the project pom.xml file for specific details about I use the Shade plugin. For now, let it suffice to say that the project makes it very easy to build a Storm JAR for your application. Once you have a unified JAR (storm-solr-1.0.jar), you’re ready to run your topology in Storm.
The project includes a main class named com.lucidworks.storm.StreamingApp that allows you to run a topology locally or in a remote Storm cluster. Specifically, StreamingApp provides the following:
- Separates the process of defining a Storm topology from the process of running a Storm topology in different environments. This lets you focus on defining a topology for your specific requirements.
- Provides a clean mechanism for separating environment-specific configuration settings.
- Minimizes duplicated boilerplate code when developing multiple topologies and gives you a common place to insert reusable logic needed for all of your topologies.
To use StreamingApp, you simply need to implement the StormTopologyFactory interface, which defines the spouts and bolts in your topology:
public interface StormTopologyFactory {
String getName();
StormTopology build(StreamingApp app) throws Exception;
}
Let’s look at a simple example of a StormTopologyFactory implementation that defines a topology for indexing tweets into Solr:
class TwitterToSolrTopology implements StormTopologyFactory {
static final Fields spoutFields = new Fields("id", "tweet")
String getName() { return "twitter-to-solr" }
StormTopology build(StreamingApp app) throws Exception {
// setup spout and bolts for accessing Spring-managed POJOs at runtime
SpringSpout twitterSpout =
new SpringSpout("twitterDataProvider", spoutFields);
SpringBolt solrBolt =
new SpringBolt("solrBoltAction", app.tickRate("solrBolt"));
// wire up the topology to read tweets and send to Solr
TopologyBuilder builder = new TopologyBuilder()
builder.setSpout("twitterSpout", twitterSpout,
app.parallelism("twitterSpout"))
builder.setBolt("solrBolt", solrBolt, app.parallelism("solrBolt"))
.shuffleGrouping("twitterSpout")
return builder.createTopology()
}
}
A couple of things should stand out to you in this listing. First, there’s no command-line parsing, environment-specific configuration handling, or any code related to running this topology. All that you see here is code defining a StormTopology; StreamingApp handles all the boring stuff for you. Second, the code is quite easy to understand because it only does one thing. Lastly, this class is written in Groovy instead of Java, which helps keep things nice and tidy and I find Groovy to be more enjoyable to write. Of course if you don’t want to use Groovy, you can use Java, as the framework supports both seamlessly.
The following diagram depicts the TwitterToSolrTopology. A key aspect of the solution is the use of the Spring framework to manage beans that implement application specific logic in your topology and leave the Storm boilerplate work to reusable components: SpringSpout and SpringBolt.
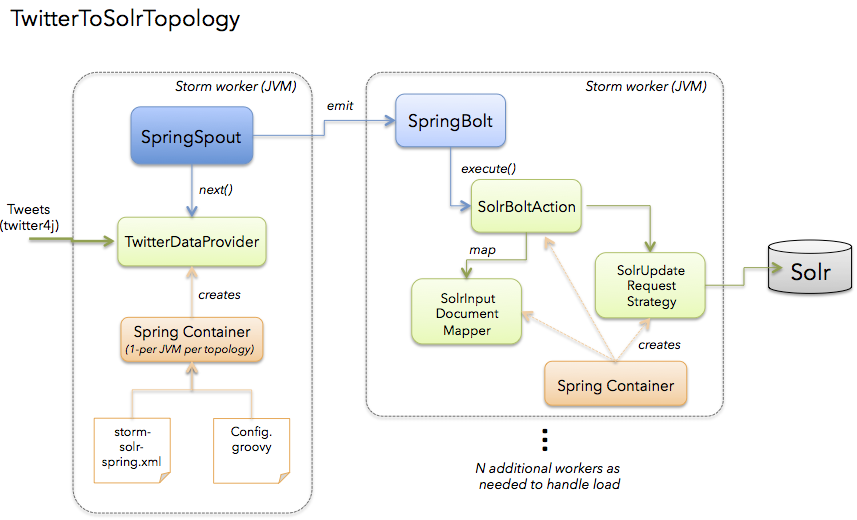
We’ll get into the specific details of the implementation shortly, but first, let’s see how to run the TwitterToSolrTopology using the StreamingApp framework. For local mode, you would do:
java -classpath $STORM_HOME/lib/*:target/storm-solr-1.0.jar com.lucidworks.storm.StreamingApp example.twitter.TwitterToSolrTopology -localRunSecs 90
The command above will run the TwitterToSolrTopology for 90 seconds on your local workstation and then shutdown. All the setup work is provided by the StreamingApp class. To submit to a remote cluster, you would do:
$STORM_HOME/bin/storm jar target/storm-solr-1.0.jar com.lucidworks.storm.StreamingApp example.twitter.TwitterToSolrTopology -env staging
Notice that I’m using the -env flag to indicate I’m running in my staging environment. It’s common to need to run a Storm topology in different environments, such as test, staging, and production, so that’s built into the StreamingApp framework.
So far, I’ve shown you how to define a topology and how to run it. Now let’s get into the details of how to implement components in a topology. Specifically, let’s see how to build a bolt that indexes data into Solr, as this illustrates many of the key features of the framework.
SpringBolt
In Storm, a bolt performs some operation on a Tuple and optionally emits Tuples into the stream. In the example Twitter topology definition above, we see this code:
SpringBolt solrBolt = new SpringBolt("solrBoltAction", app.tickRate("solrBolt"));
This creates an instance of SpringBolt that delegates message processing to a Spring-managed bean with ID “solrBoltAction”.
The main benefit of the SpringBolt is it allows us to separate Storm-specific logic and boilerplate code from application logic. The com.lucidworks.storm.spring.SpringBolt class allows you to implement your bolt logic as a simple Spring-managed POJO (Plain Old Java Object). To leverage SpringBolt, you simply need to implement the StreamingDataAction interface:
public interface StreamingDataAction {
SpringBolt.ExecuteResult execute(Tuple input, OutputCollector collector);
}
At runtime, Storm will create one or more instances of SpringBolt per JVM. The number of instances created depends on the parallelism hint configured for the bolt. In the Twitter example, we simply pulled the number of tasks for the Solr bolt from our configuration:
// wire up the topology to read tweets and send to Solr
...
builder.setBolt("solrBolt", solrBolt, app.parallelism("solrBolt"))
...
The SpringBolt needs a reference to the solrBoltAction bean from the Spring ApplicationContext. The solrBoltAction bean is defined in resources/storm-solr-spring.xml as:
<bean id="solrBoltAction"
class="com.lucidworks.storm.solr.SolrBoltAction"
scope="prototype">
<property name="solrInputDocumentMapper" ref="solrInputDocumentMapper"/>
<property name="maxBufferSize" value="${maxBufferSize}"/>
<property name="bufferTimeoutMs" value="${bufferTimeoutMs}"/>
</bean>
There are a couple of interesting aspects of about this bean definition. First, the bean is defined with prototype scope, which means that Spring will create a new instance for each SpringBolt instance that Storm creates at runtime. This is important because it means your bean instance will only be accessed by one thread at a time so you don’t need to worry about thread-safety issues. Also notice that the maxBufferSize and bufferTimeoutMs properties are set using Spring’s dynamic variable resolution syntax, e.g. ${maxBufferSize}. These properties will be resolved during bean construction from a configuration file called resources/Config.groovy.
When the SpringBolt needs a reference to solrBoltAction bean, it first needs to get the Spring ApplicationContext. The StreamingApp class is responsible for bootstrapping the Spring ApplicationContext using storm-solr-spring.xml. StreamingApp ensures there is only one Spring context initialized per JVM instance per topology as multiple topologies may be running in the same JVM.
If you’re concerned about the Spring container being too heavyweight, rest assured there is only one container initialized per JVM per topology and bolts and spouts are long-lived objects that only need to be initialized once by Storm per task. Put simply, the overhead of Spring is quite minimal especially for long-running streaming applications.
The framework also provides a SpringSpout that allows you to implement a data provider as a simple Spring-managed POJO. I’ll refer you to the source code for more details about SpringSpout but it basically follows the same design patterns as SpringBolt.
Environment-specific Configuration
I’ve implemented several production Storm topologies in the past couple years and one pattern that keeps emerging is the need to manage configuration settings for different environments. For instance, we’ll need to index into a different SolrCloud cluster for staging and production. To address this need, the Spring-driven framework allows you to keep all environment-specific configuration properties in the same configuration file, see resources/Config.groovy.
Don’t worry if you don’t know Groovy, the syntax of the Config.groovy file is very easy to understand and allows you to cleanly separate properties for the following environments: test, dev, staging, and production. Put simply, this approach allows you to run the topology in multiple environments using a simple command-line switch to specify the environment settings that should be applied -env.
Metrics
Storm provides high-level metrics for bolts and spouts, but if you need more visibility into the inner workings of your application-specific logic, then it’s common to use the Java metrics library, see: https://dropwizard.github.io/metrics/3.1.0/. Fortunately, there are open source options for integrating metrics with Spring, see: https://github.com/ryantenney/metrics-spring.
The Spring context configuration file resources/storm-solr-spring.xml comes pre-configured with all the infrastructure needed to inject metrics into your bean implementations.
When implementing your StreamingDataAction (bolt) or StreamingDataProvider (spout), you can have Spring auto-wire metrics objects using the @Metric annotation when declaring metrics-related member variables. For instance, the SolrBoltAction class uses a Timer to track how long it takes to send batches to Solr.
@Metric public Timer sendBatchToSolr;
The SolrBoltAction class provides several examples of how to use metrics in your bean implementations.
At this point you should have a basic understanding of the main features of the framework. Now let’s turn our attention to some Solr-specific features.
Micro-buffering and Ack’ing Input Tuples
It’s possible that thousands of documents per second will be flowing into each Solr bolt. To avoid sending too many requests into Solr and to avoid blocking too much in the topology, the bolt uses an internal buffer to send documents to Solr in small batches. This helps reduce the number of network round-trips between your bolt and Solr. The bolt supports a maximum buffer size setting to control when the buffer should be flushed, which defaults to 100.
Buffering poses two basic issues in a streaming topology. First, you’re likely using Storm to power a near real-time data processing application, so we don’t want to delay documents from getting into Solr for too long. To support this, the bolt supports a buffer timeout setting that indicates when a buffer should be flushed to ensure documents flow into Solr in a timely manner. Consequently, the buffer will be flushed when either the size threshold or the time limit is reached.
There is a subtle side-effect that would normally require a background thread to flush the buffer if there was some delay in messages being sent into the bolt by upstream components. Fortunately, Storm provides a simple mechanism that allows your bolt to receive a special type of Tuple on a periodic schedule, known as a TickTuple. Whenever the SolrBoltAction bean receives a TickTuple, it checks to see if the buffer needs to be flushed, which avoids holding documents for too long and alleviates the need for a background thread to monitor the buffer.
Field Mapping
The SolrBoltAction bean takes care of sending documents to SolrCloud in an efficient manner, but it only works with SolrInputDocument objects from SolrJ. It’s unlikely that your Storm topology will be working with SolrInputDocument objects natively, so the SolrBoltAction bean delegates mapping of input Tuples to SolrInputDocument objects to a Spring-managed bean that implements the com.lucidworks.storm.solr.SolrInputDocumentMapper interface. This fits nicely with our design approach of separating concerns in our topology.
The default implementation provided in the project (DefaultSolrInputDocumentMapper) uses Java reflection to read data from a Java object to populate the fields of the SolrInputDocument. In the Twitter example, the default implementation uses Java reflection to read data from a Twitter4J Status object to populate dynamic fields on a SolrInputDocument instance.
It should be clear, however, that you can inject your own SolrInputDocumentMapper implementation into the bolt bean using Spring if the default implementation does not meet your needs.
JSON
As of Solr 5, you can send arbitrary JSON documents to Solr and have it parse out documents for indexing. For more information about this cool feature in Solr, please see: https://lucidworks.com/post/indexing-custom-json-data/
If you want to send arbitrary JSON objects to Solr and have it index documents during JSON parsing, you need to use the solrJsonBoltAction bean instead of solrBoltAction. For our Twitter example, you could define the solrJsonBoltAction bean as:
<bean id="solrJsonBoltAction"
class="com.lucidworks.storm.solr.SolrJsonBoltAction"
scope="prototype">
<property name="split" value="/"/>
<property name="fieldMappings">
<list>
<value>$FQN:/**</value>
</list>
</property>
</bean>
Lucidworks Fusion
Lastly, if you’re using Lucidworks Fusion (and you should be), then instead of sending documents directly to Solr, you can send them to a Fusion indexing pipeline using the FusionBoltAction class. FusionBoltAction posts JSON documents to the Fusion proxy which gives you security and the full power of Fusion pipelines for generating Solr documents.