Lucidworks Fusion 3.1 is Ready for Download!
Lucidworks is pleased to announce the release of Fusion 3.1!
Fusion AI
The Fusion Artificial Intelligence suite now includes sophisticated machine learning tools for Classification, Clustering, and Collaborative Filtering to advance our cognitive search and recommendation capabilities.
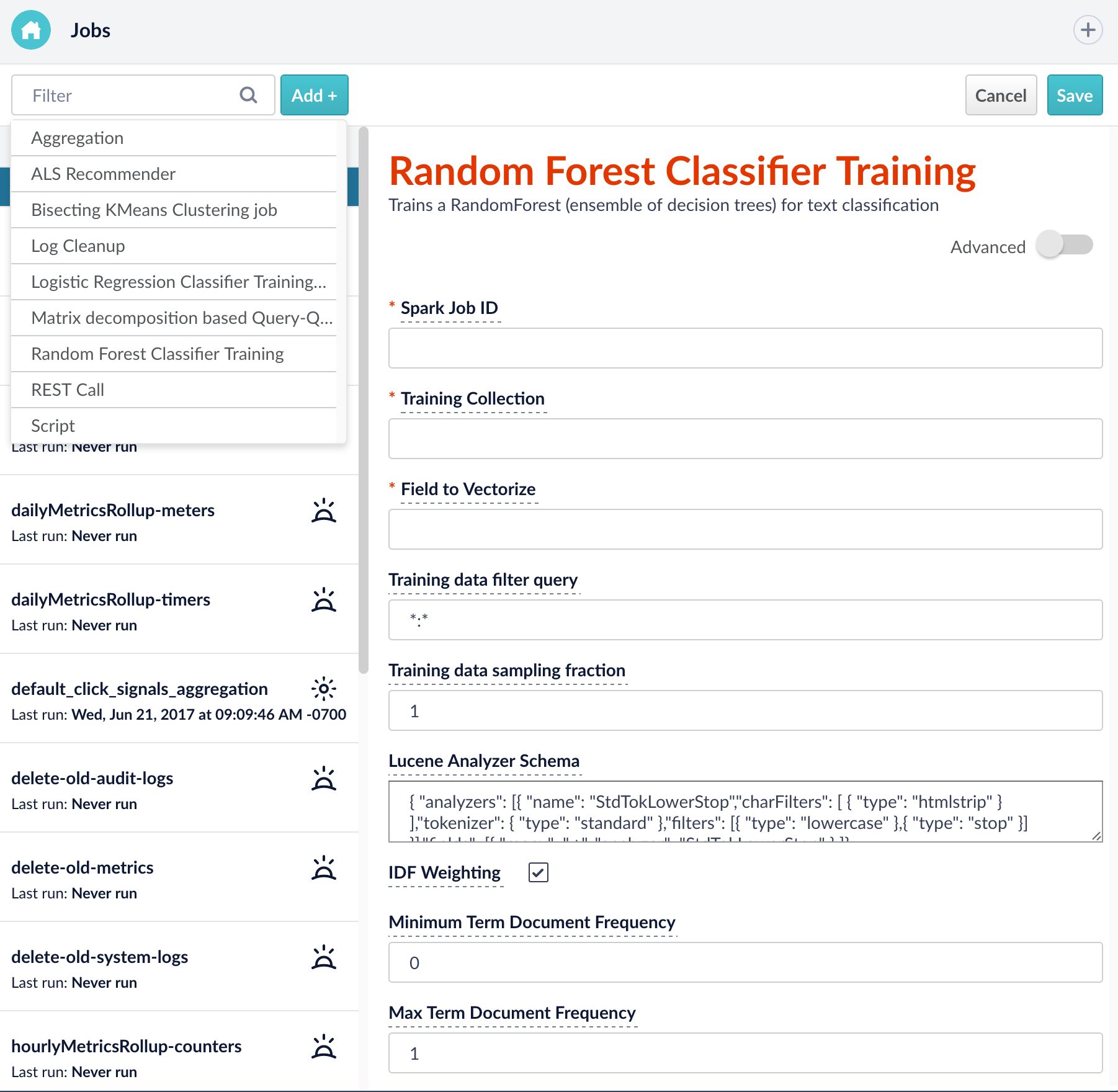
Fusion 3.1 ships with the several popular classification models for training your own query intent classifier for use in a Fusion query pipeline.
- Random Forest
- Logistic Regression
- Word2Vec
- Bisecting k-Means
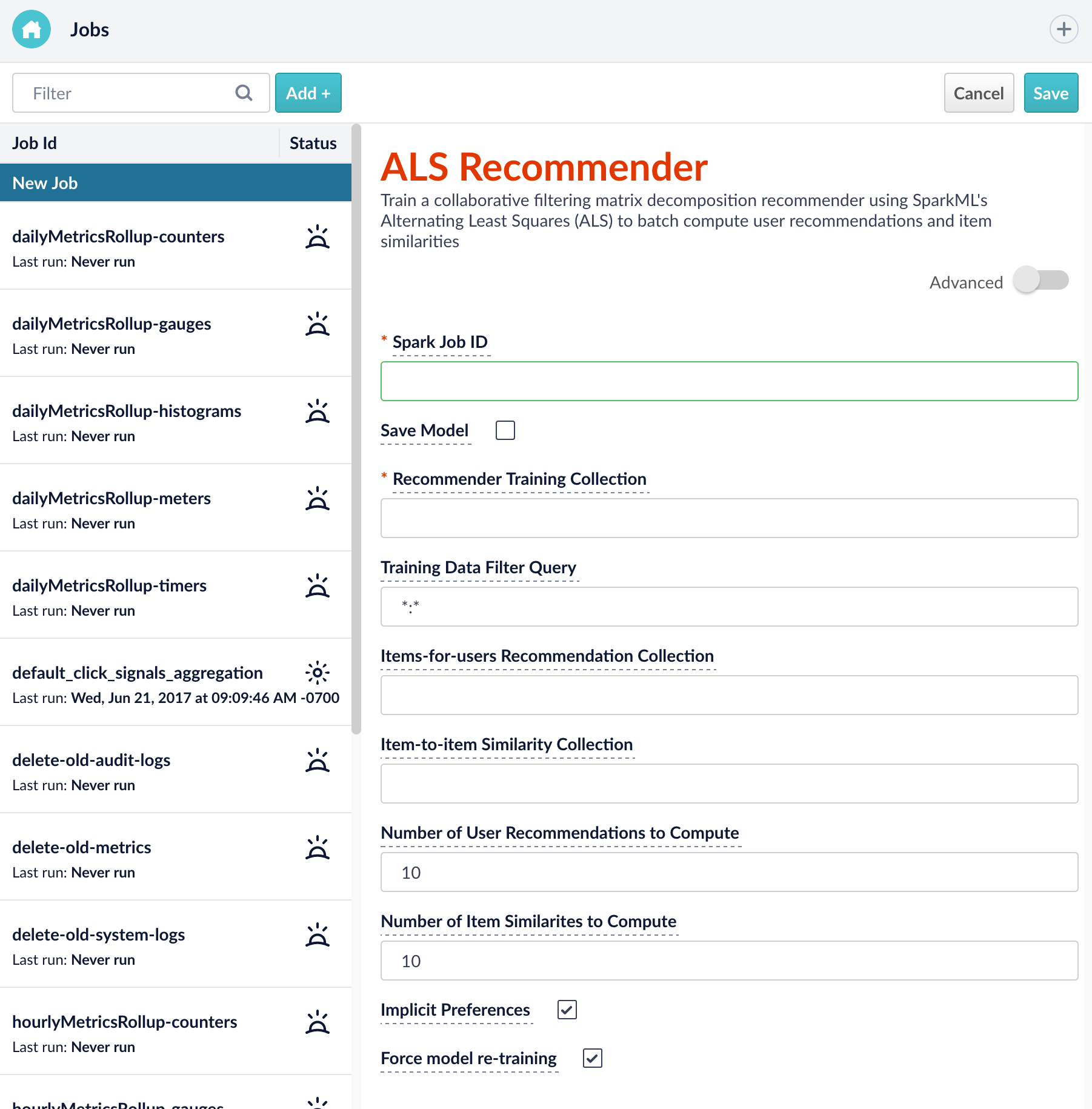
This release also includes significant improvements to our Recommendations framework.
The new ALS (Alternating Least Squares) Recommender job can be used to precompute Items-for-User & Items-for-Items recommendations.
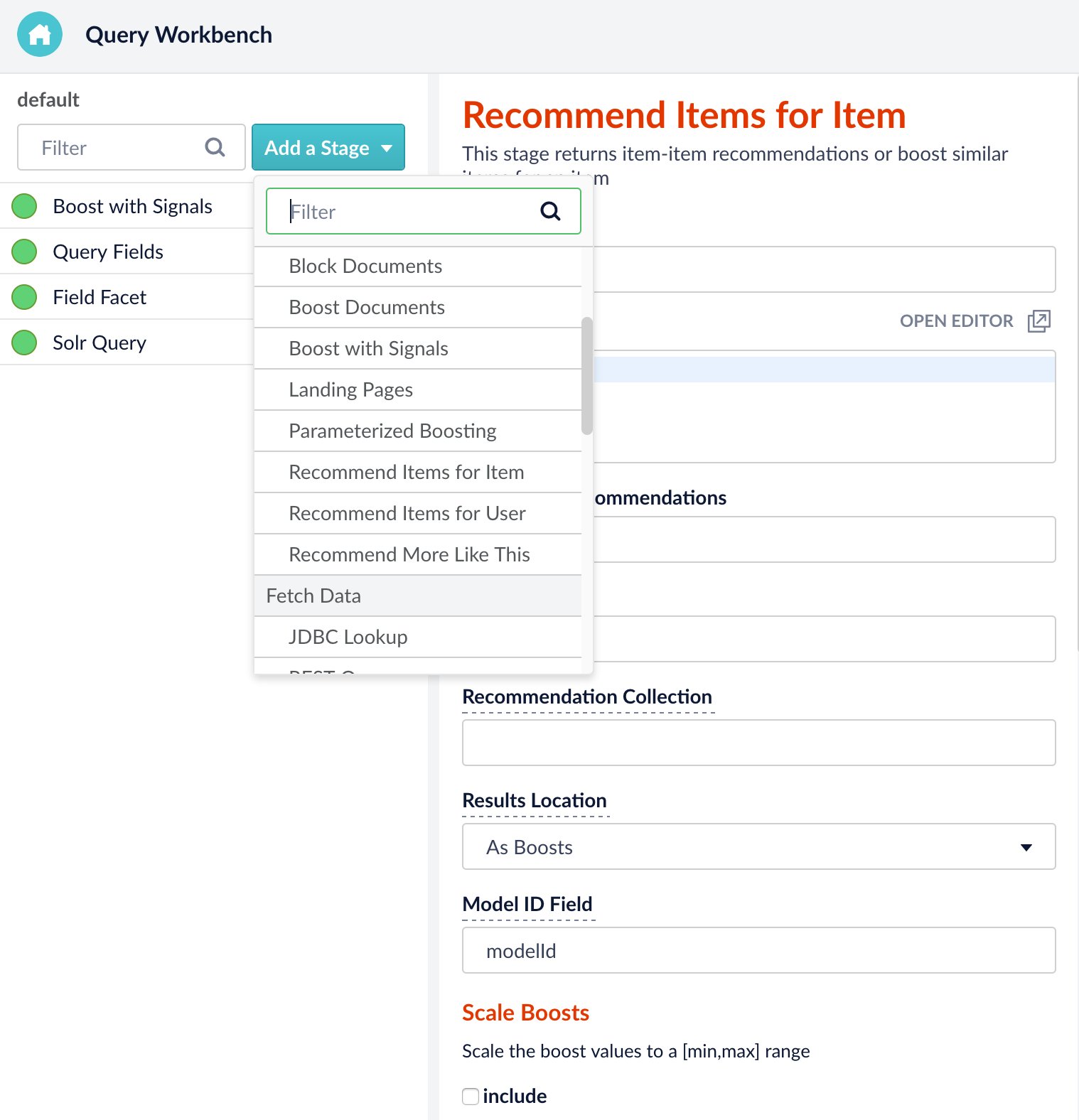
These recommendations can now be served at query time using our new Collaborative Filtering Stages.
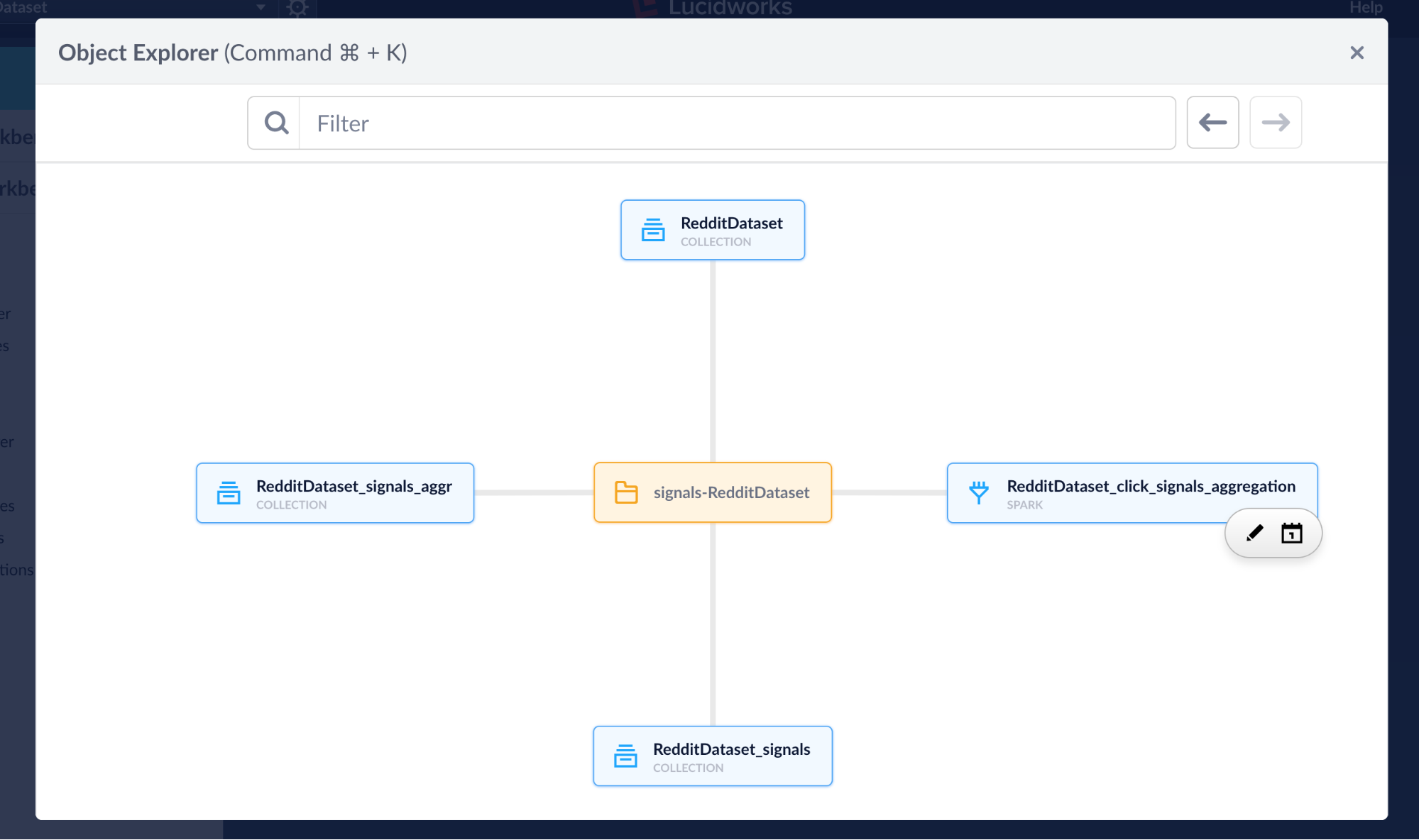
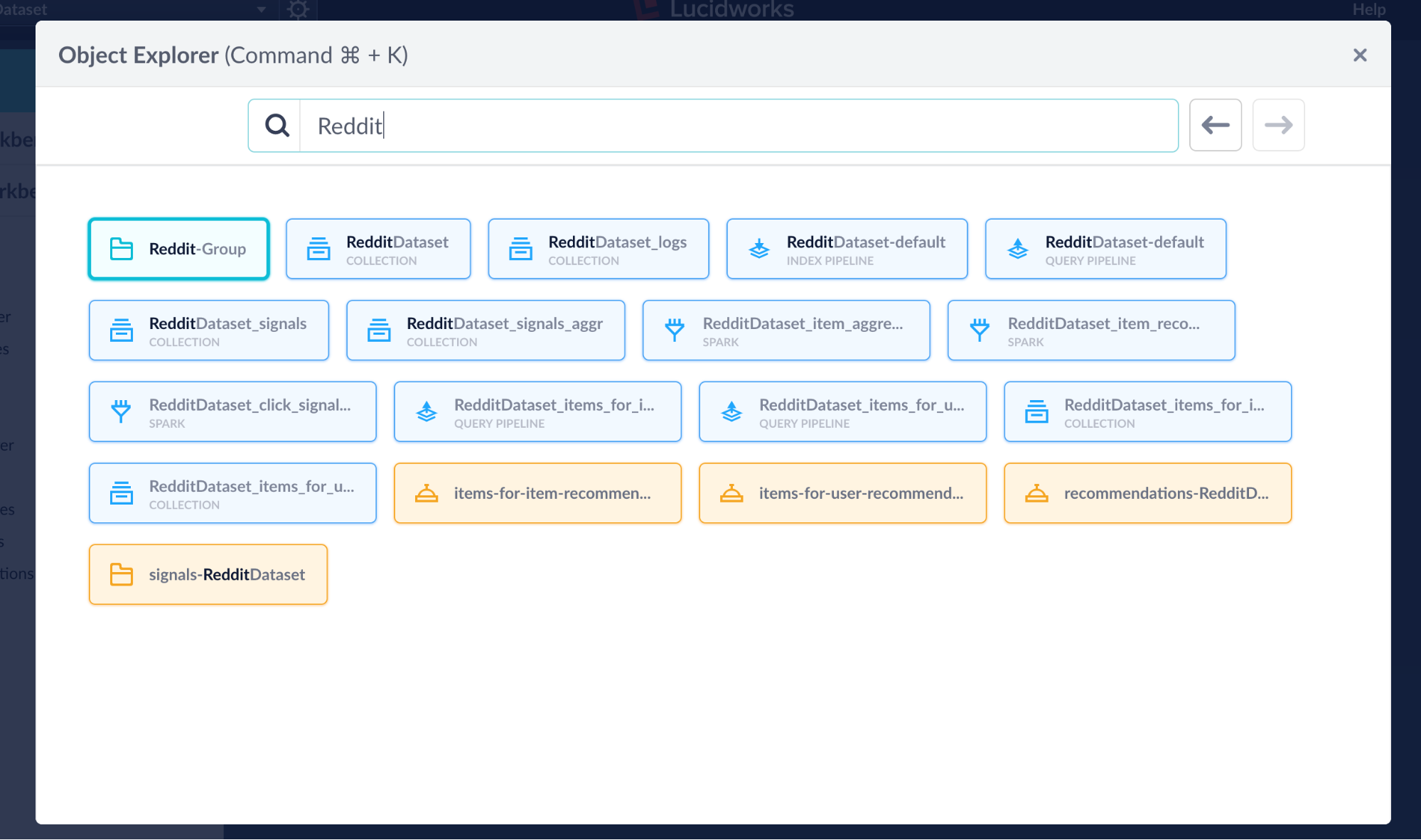
Object Explorer
The Object Explorer is a new interface for visualizing the relationship between Fusion Objects. Using our new Links and Groups API’s, it allows for users to navigate amongst associated objects to explore these relationships. It allows one to create User Groups, schedule Jobs and navigate to the object specific editors.
Job Management and Scheduling
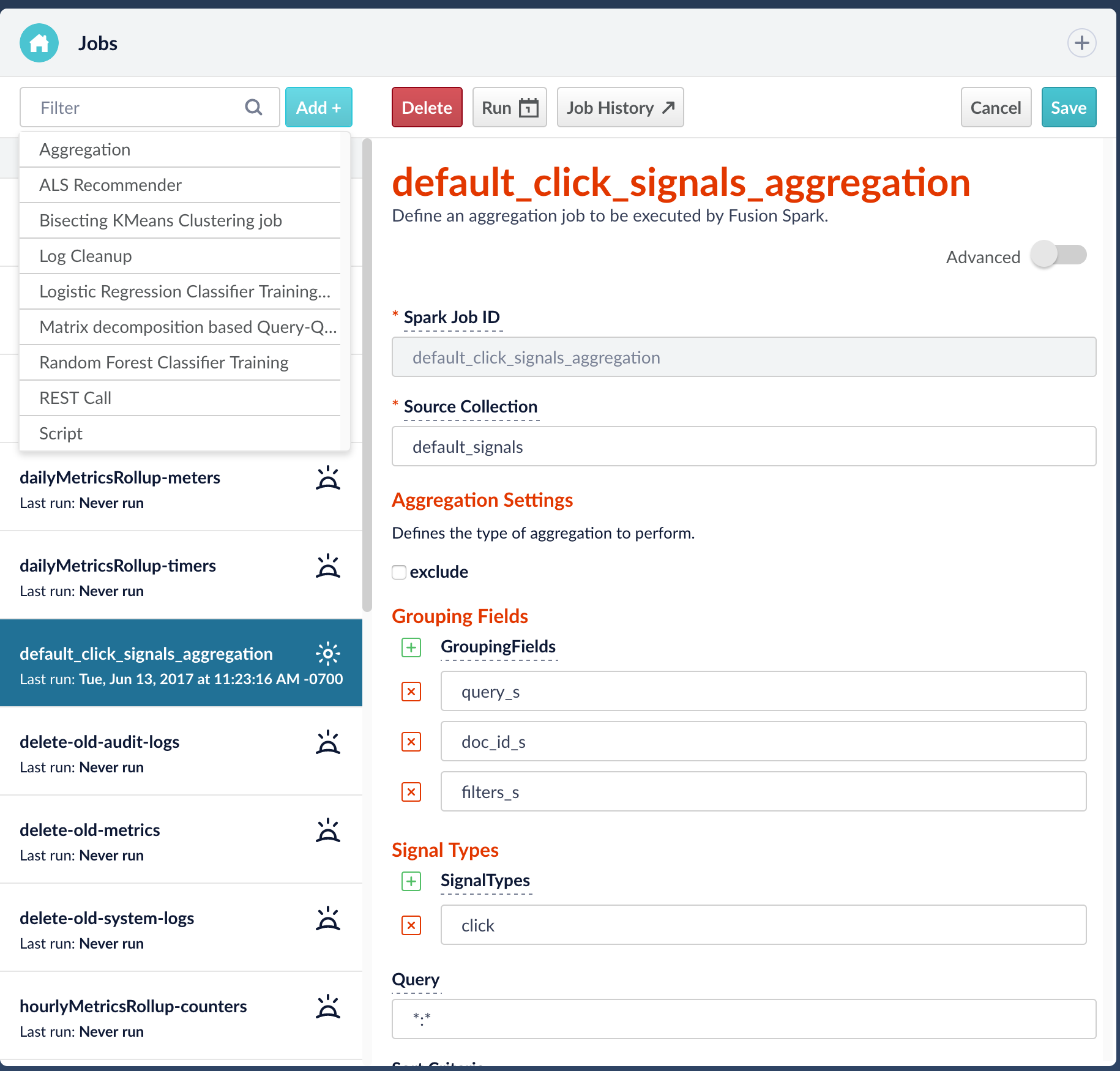
The Jobs Manager is a new interface for managing and scheduling Fusion Spark Jobs and Tasks. We have 2 new API’s to use for Jobs and Task
Jobs API: This API allows you to define schedules for objects that perform work. You can schedule datasources, tasks, and Spark jobs.. .
Tasks API:Tasks are a flexible job type that can be used to clean up old logs or run any REST call. The Tasks API allows you to view and define Fusion tasks.
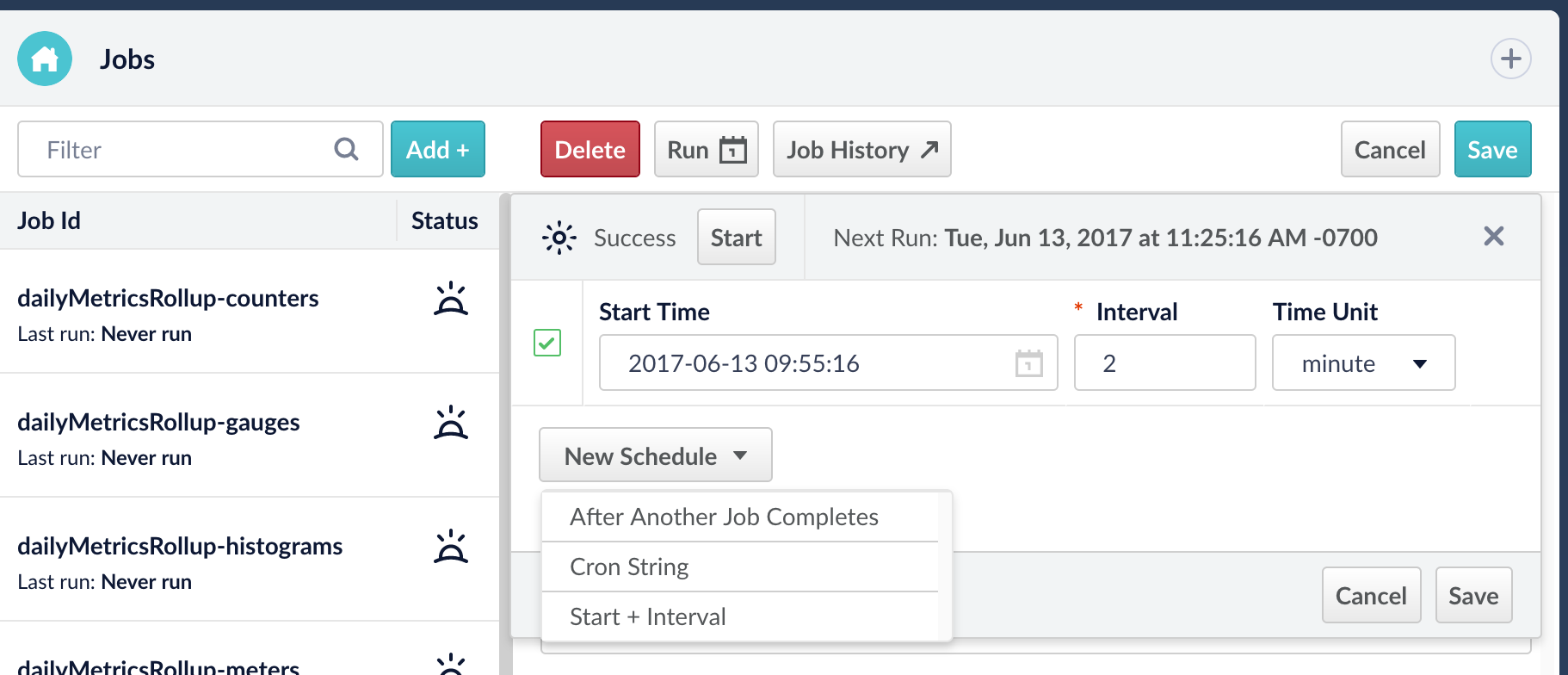
The scheduler dropdown within the Job Manager allows for jobs and tasks to be configured with different triggers, allowing for the easy build out and maintenance of a comprehensive job workflow.
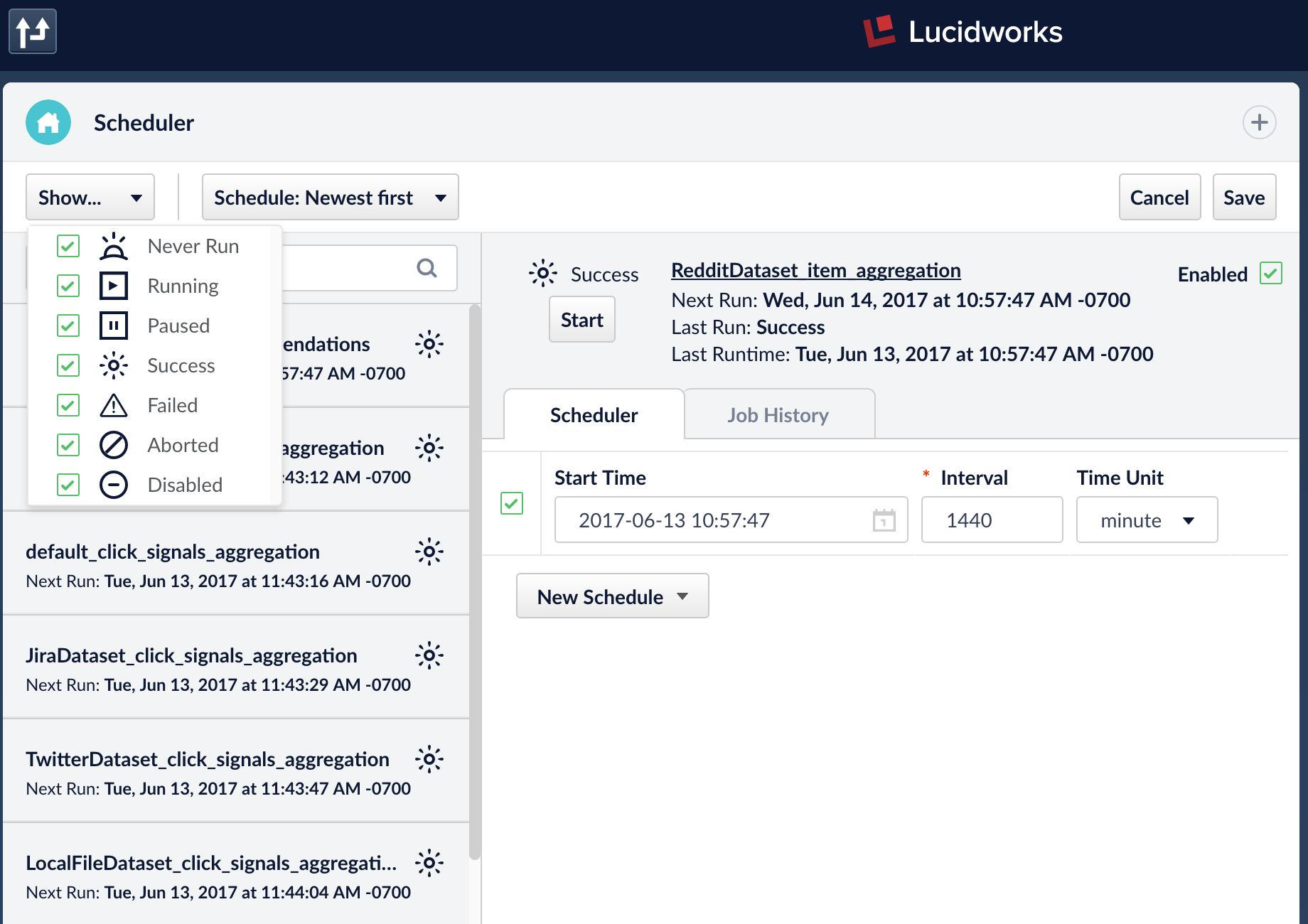
The Scheduler interface provides a management console for all scheduled jobs and tasks.
Blob Management
This Blob Manager allows for managing Fusion resource types, which include ML/NLP models, JDBC drivers, Connector plugins and Banana Dashboards.
New Parsers for HTML & XML
Extending on the parser framework introduced in Fusion 3, we have introduced two new parsers for HTML and XML.
- The HTML parser supports the usage of JSoup selectors to extract CSS and HTML elements into new documents or fields.
- The XML parser supports splitting of XML documents and using XPATH-like expressions. XML nodes can be parsed into new documents.
Security Between Fusion and Solr
Fusion can now communicate with a secure Solr cluster over SSL, with basic authentication or Kerberos.
Connector Updates

Fusion 3.1 now ships with 4 built-in connectors (Web, File Upload, JDBC, and Local FileSystem).
- SharePoint Online support to index data from the Microsoft collaboration suite.
- Box and Google Drive connectors now support incremental crawls.
- Web connector can now crawl web sites built with JavaScript.
Or dive right into some of new features with these blog posts:
Machine Learning in Lucidworks Fusion: Classification, clustering, and collaborative filtering (the “3 C’s of machine learning”) are now available in the Lucidworks Fusion application suite – from training your models offline in Fusion’s horizontally scalable Apache Spark cluster to serving these models as part of runtime query and indexing pipelines. Go to blog post.
Query Explorer Jobs in Fusion: Query analysis is the most powerful analytical tool in any search engineer’s arsenal. Fusion 3.1 ships with out-of-the-box Spark analytics jobs to help you make sense of your queries and data more easily. Go to blog post.
Automatic Document Clustering and Anomaly Detection: Fusion 3.1 also has several important machine learning modules for exploratory data analysis. Here’s how to get started using them. Go to blog post.