Search Basics for Data Engineers
Lucidworks Fusion is a platform for data engineering, built on Solr/Lucene, the Apache open source search engine, which is fast, scalable, proven, and reliable. Fusion uses the Solr/Lucene engine to evaluate search requests and return results in the form of a ranked list of document ids. It gives you the ability to slice and dice your data and search results, which means that you can have Google-like search over your data, while maintaining control of both your data and the search results.
The difference between data science and data engineering is the difference between theory and practice. Data engineers build applications given a goal and constraints. For natural language search applications, the goal is to return relevant search results given an unstructured query. The constraints include: limited, noisy, and/or downright bad data and search queries, limited computing resources, and penalties for returning irrelevant or partial results.
As a data engineer, you need to understand your data and how Fusion uses it in search applications. The hard part is understanding your data. In this post, I cover the key building blocks of Fusion search.
Fusion Key Concepts
Fusion extends Solr/Lucene functionality via a REST-API and a UI built on top of that REST-API. The Fusion UI is organized around the following key concepts:
- Collections store your data.
- Documents are the things that are returned as search results.
- Fields are the things that are actually stored in a collection.
- Datasource are the conduit between your data repository and Fusion.
- Pipelines encapsulate a sequence of processing steps, called stages.
- Indexing Pipelines process the raw data received from a datasource into fielded documents for indexing into a Fusion collection.
- Query Pipelines process search requests and return an ordered list of matching documents.
- Relevancy is the metric used to order search results. It is a non-negative real number which indicates the similarity between a search request and a document.
Lucene and Solr
Lucene started out as a search engine designed for following information retrieval task: given a set of query terms and a set of documents, find the subset of documents which are relevant for that query. Lucene provides a rich query language which allows for writing complicated logical conditions. Lucene now encompasses much of the functionality of a traditional DBMS, both in the kinds of data it can handle and the transactional security it provides.
Lucene maps discrete pieces of information, e.g., words, dates, numbers, to the documents in which they occur. This map is called an inverted index because the keys are document elements and the values are document ids, in contrast to other kinds of datastores where document ids are used as a key and the values are the document contents. This indexing strategy means that search requires just one lookup on an inverted index, as opposed to a document oriented search which would require a large number of lookups, one per document. Lucene treats a document as a list of named, typed fields. For each document field, Lucene builds an inverted index that maps field values to documents.
Lucene itself is a search API. Solr wraps Lucene in an web platform. Search and indexing are carried out via HTTP requests and responses. Solr generalizes the notion of a Lucene index to a Solr collection, a uniquely named, managed, and configured index which can be distributed (“sharded”) and replicated across servers, allowing for scalability and high availability.
Fusion UI and Workflow
The following sections show how the above set of key concepts are realized in the Fusion UI.
Collections
Fusion collections are Solr collections which are managed by Fusion. Fusion can manage as many collections as you need, want, or both. On initial login, the Fusion UI prompts you to choose or create a collection. On subsequent logins, the Fusion UI displays an overview of your collections and system collections:
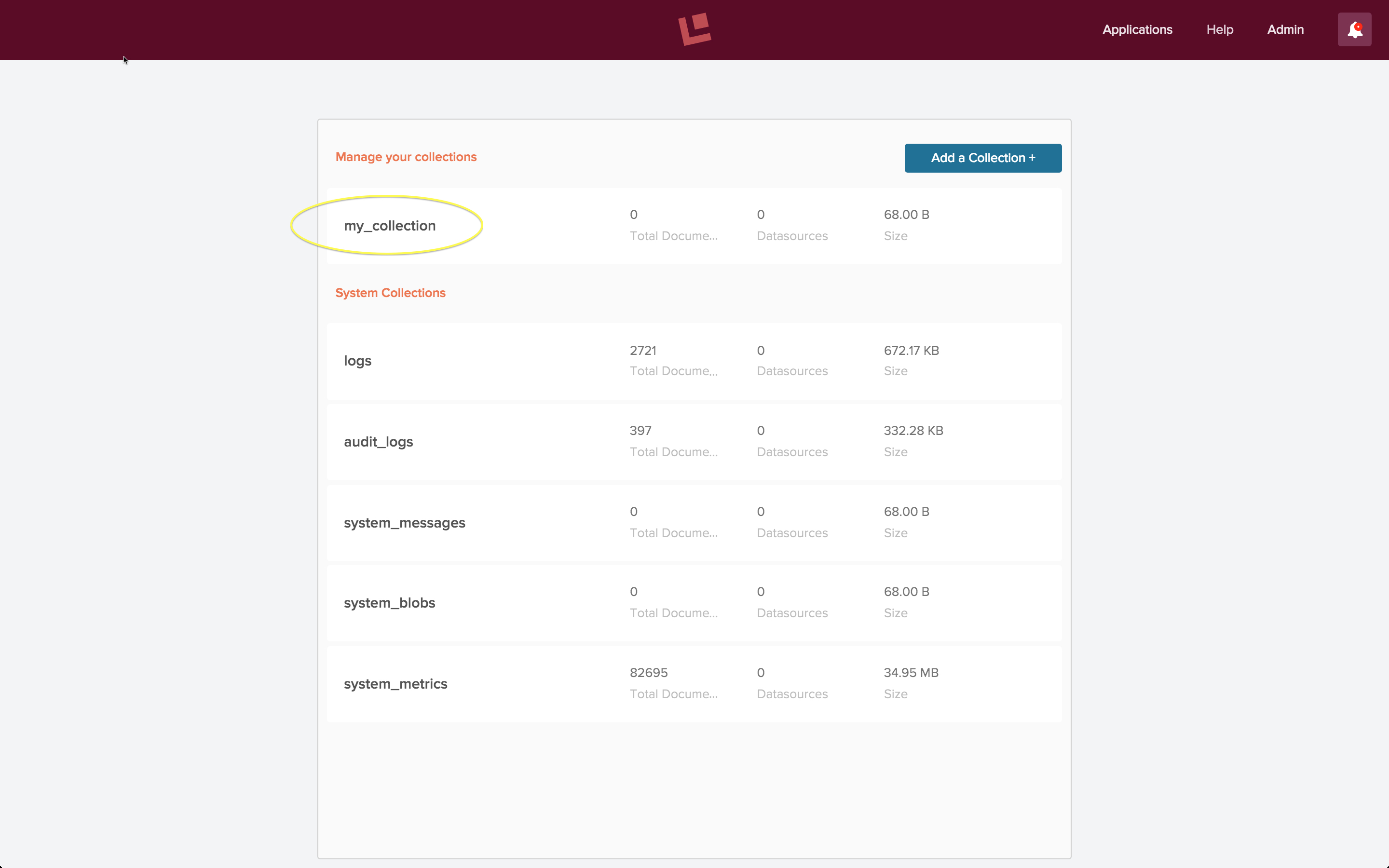
The above screenshot shows the Fusion collections page for an initial developer installation, just after initial login and creation of a new collection called “my_collection”, which is circled in yellow. Clicking on this circled name leads to the “my_collection” collection home page:
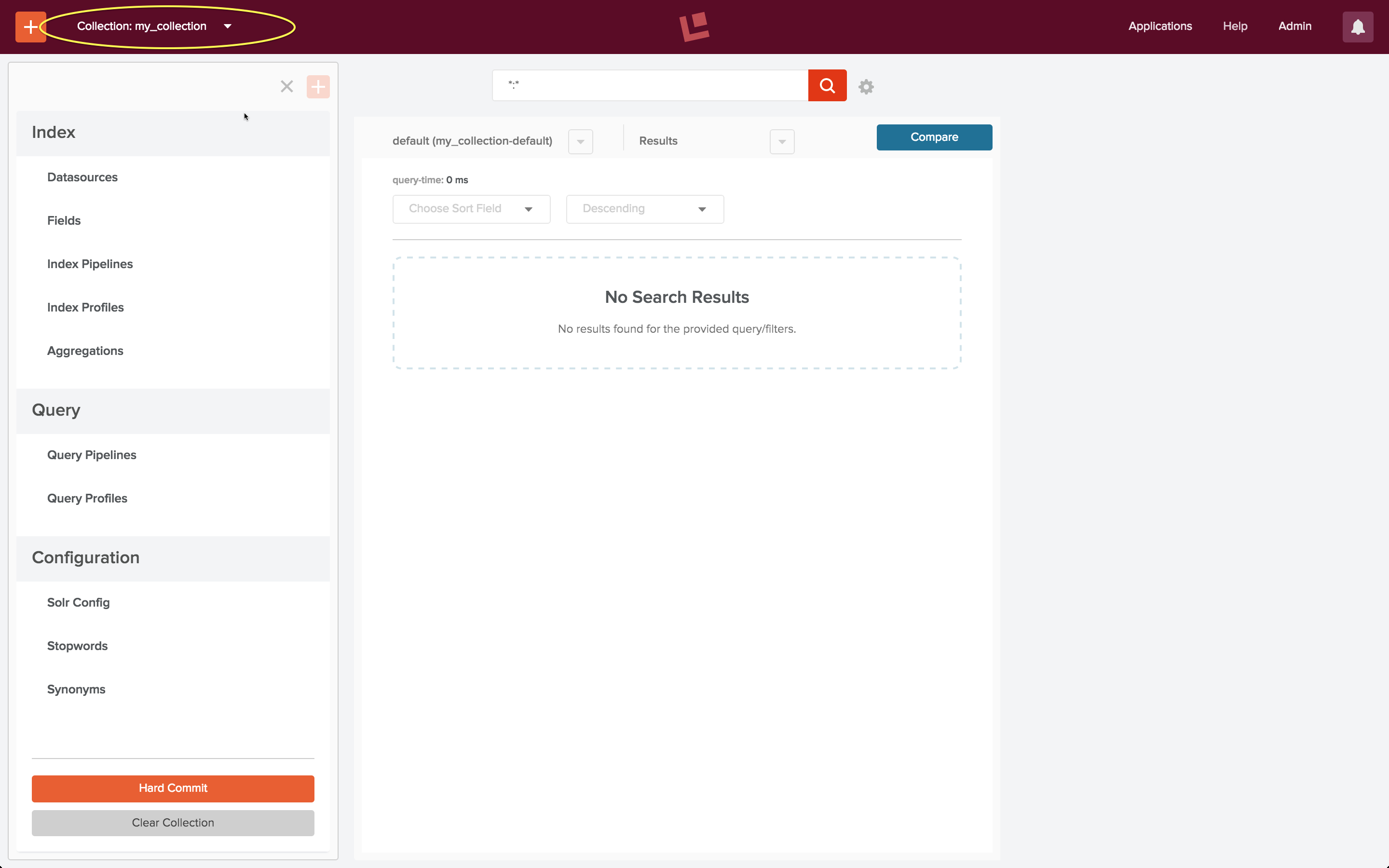
The collection home page contains controls for both search and indexing. As this collection doesn’t yet contain any documents, the search results panel is empty.
Indexing: Datasources and Pipelines
Bootstrapping a search app requires an initial indexing run over your data, followed by successive cycles of search and indexing until you have a search app that does what you want it to do and what search users expect it to do. The collections home page indexing toolset contains controls for defining and using datasources and pipelines.
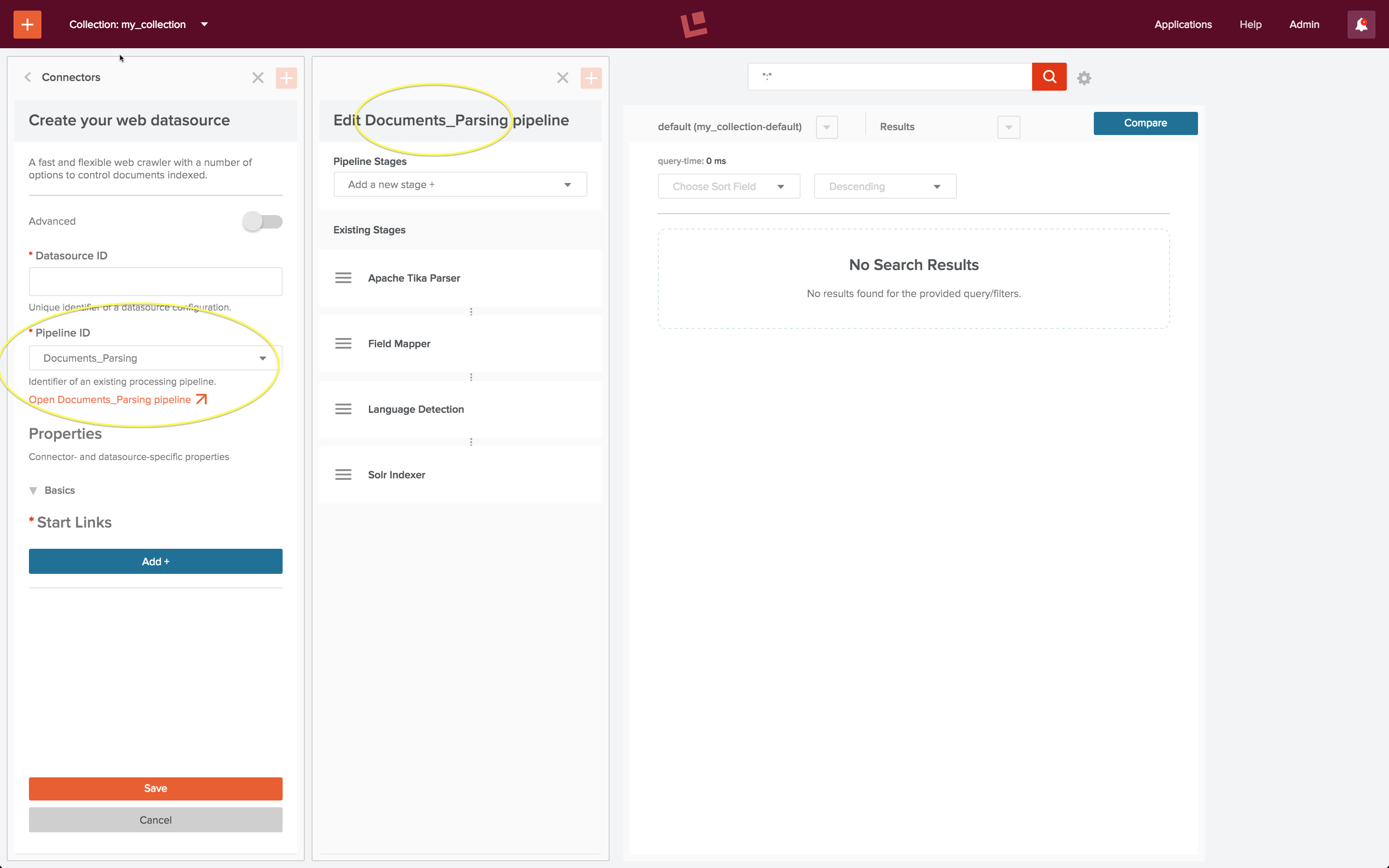
Once you have created a collection, clicking on the “Datasource” control changes the left hand side control panel over to the datasource configuration panel. The first step in configuring a datasource is specifying the kind of data repository to connect to. Fusion connectors are a set of programs which do the work of connecting to and retrieving data from specific repository types. For example, to index a set of web pages, a datasource uses a web connector.
To configure the datasource, choose the “edit” control. The datasource configuration panel controls the choice of indexing pipeline. All datasources are pre-configured with a default indexing pipeline. The “Documents_Parsing” indexing pipeline is the default pipeline for use with a web connector. Beneath the pipeline configuration control is a control “Open <pipeline name> pipeline”. Clicking on this opens a pipeline editing panel next to the datasource configuration panel:
Once the datasource is configured, the indexing job is run by controls on the datasource panel:
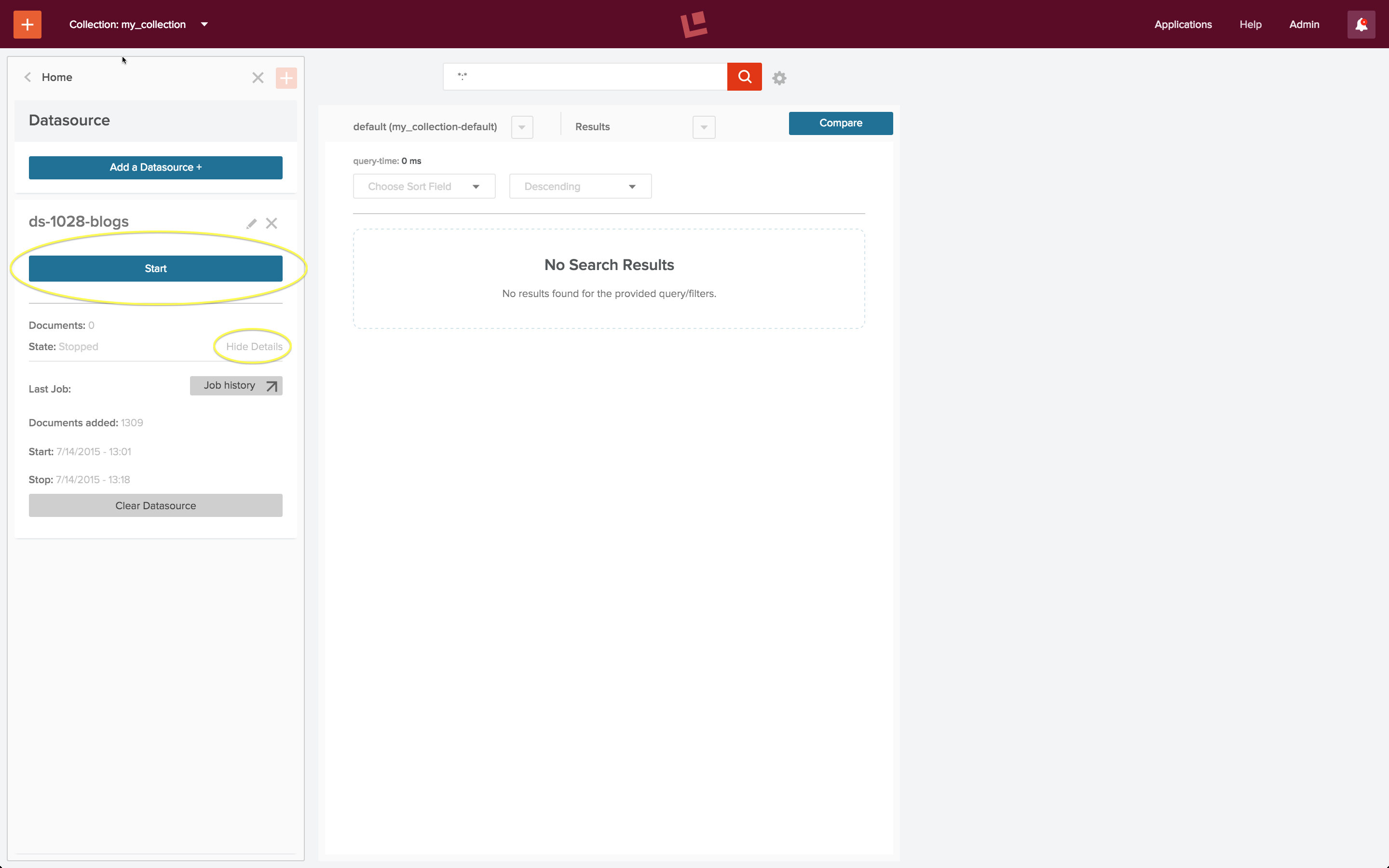
The “Start” button, circled in yellow, when clicked, changes to “Stop” and “Abort” controls. Beneath this button is a “Show details”/”Hide details” control, shown in its open state.
Creating and maintaining a complete, up-to-date index over your data is necessary for good search. Much of this process consists of data munging. Connectors and pipelines make this chore manageable, repeatable, and testable. It can be automated using Fusion’s job scheduling and alerting mechanisms.
Search and Relevancy
Once a datasource has been configured and the indexing job is complete, the collection can be searched using the search results tool. A wildcard query of “:” will match all documents in the collection. The following screenshot shows the result of running this query via the search box at the top of the search results panel:
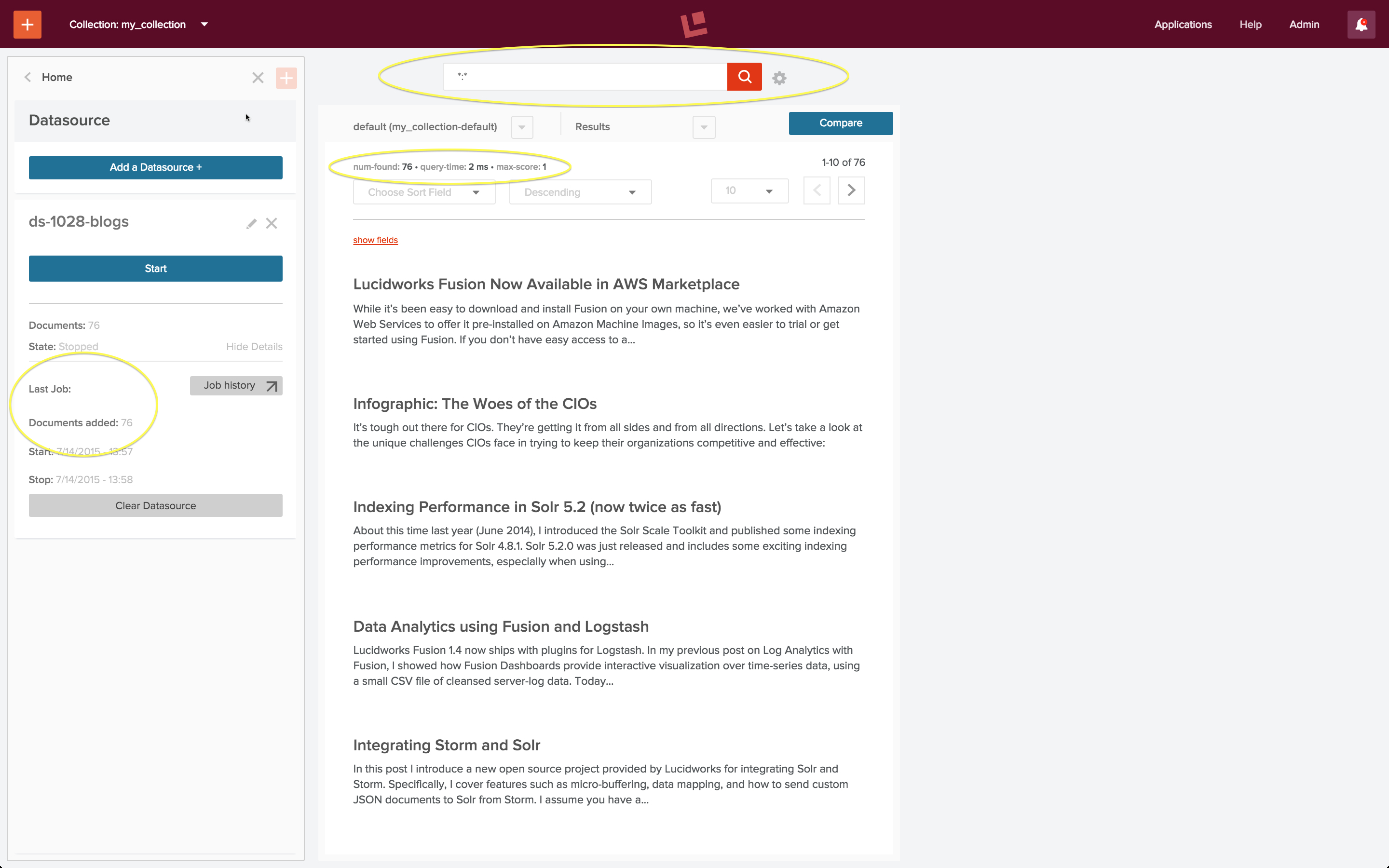
After running the datasource exactly once, the collection consists of 76 posts from the Lucidworks blog, as indicated by the “Last Job” report on the datasource panel, circled in yellow. This agrees with the “num found”, also circled in yellow, at the top of the search results page.
The search query “Fusion” returns the most relevant blog posts about Fusion:
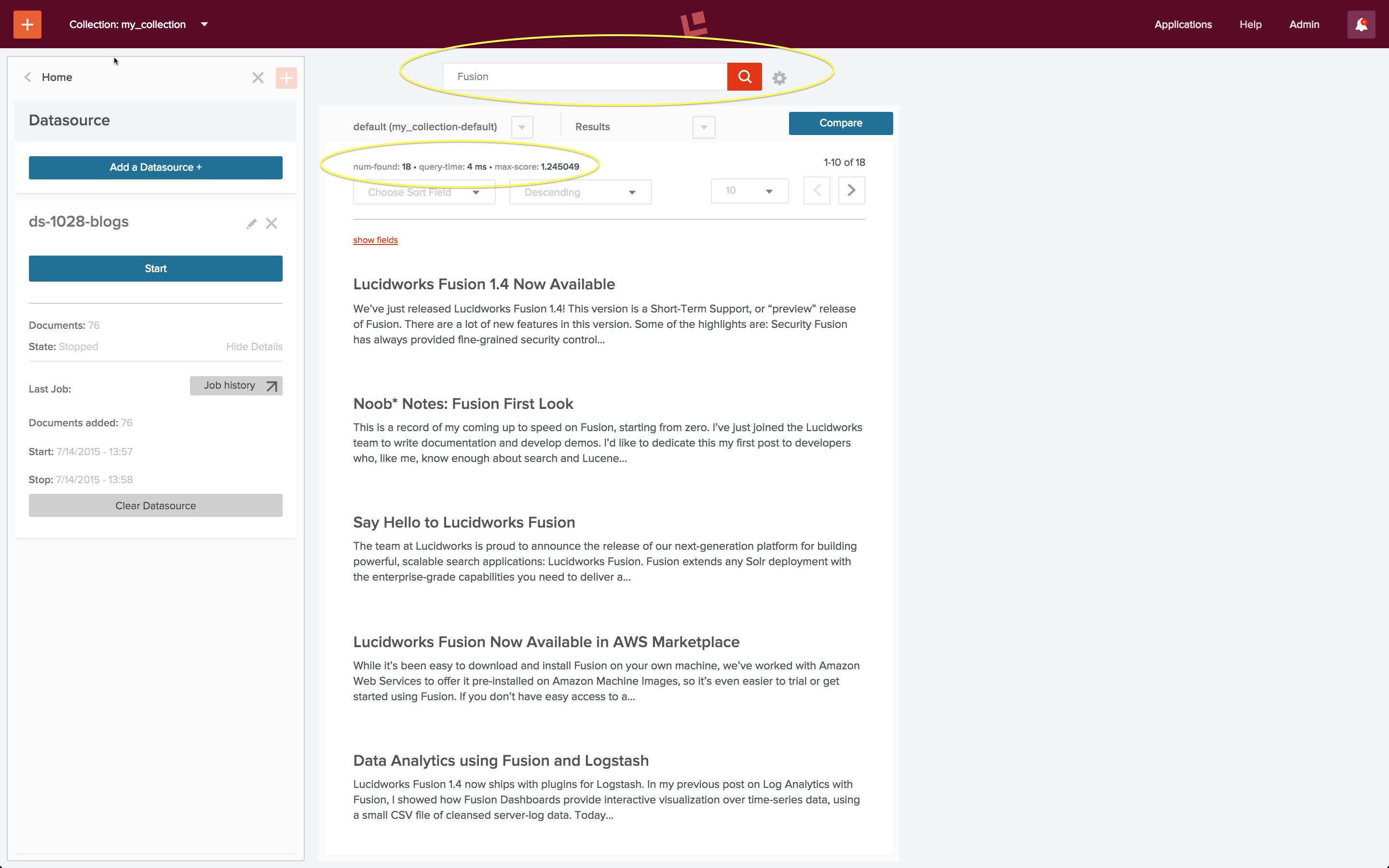
There are 18 blog posts altogether which have the word “Fusion” either in the title or body of the post. In this screenshot we see the 10 most relevant posts, ranked in descending order.
A search application takes a user search query and returns search results which the user deems relevant. A well-tuned search application is one where the both the user and the system agree on both the set of relevant documents returned for a query and the order in which they are ranked. Fusion’s query pipelines allow you to tune your search and the search results tool lets you test your changes.
Conclusion
Because this post is a brief and gentle introduction to Fusion, I omitted a few details and skipped over a few steps. Nonetheless, I hope that this introduction to the basics of Fusion has made you curious enough to try it for yourself.