Smarter Image Search in Fusion with Google’s Vision API
After five days in Mexico with your friends, surfing sunny, secluded point breaks along the Pacific side of Baja, you’re on your way back home, squinting at an overly dense photo gallery on your phone (or worse, sifting through a collection of files in your DCIM folder with names like DSC10000.JPG), trying to find that one photo of the classic 1948 Woodie Station Wagon with the single-fin surfboard on the roof rack…

Granted, even if you are not a surfer or a car enthusiast, better cases have been made for smart image search, including the ubiquitous search for “blue suede shoes” on your favorite commerce site, social media networks, and facial recognition applications, to name a few. Companies like Google, Facebook, and Pinterest have invested heavily in image recognition and classification using artificial intelligence and deep learning technologies, and users, who have grown accustomed to this level of functionality, now expect the same behavior in their enterprise search applications.
Lucidworks Fusion can index images and other unstructured document formats, such as HTML, PDF, Microsoft Office documents, OpenOffice, RTF, audio, and video. To that end, Fusion uses the Apache Tika parser to process these files. Tika is a very versatile parser that provides comprehensive metadata about image files such as dimensions, resolution, color palette, orientation, compression ratio, and even the make and model of the camera and lens from which the photo originated, if that information is added by the imaging software. That said, such low-level metadata is not useful enough when searching for a “red car with white wall tires”…
Enter the Google Cloud Vision API
The Google Cloud Vision API is a REST service that enables developers to easily understand the content of an image while completely abstracting the underlying machine learning models. It quickly classifies images into categories (e.g. “surfboard”, “car”, “beach”, “vacation”), detects individual objects and faces within images, extracts printed words contained within images, and can even moderate offensive content via image sentiment analysis. When the GCV API is used to augment the image parsing capabilities of Fusion Server, the combined metadata can be used by Fusion AppStudio to create a sophisticated image search experience.
Using GCV From Fusion
To incorporate the GCV API functionality into your search app, follow these three simple steps:
- Add a Tika Parser stage to the Index Pipeline. Ensure that the Include Images and Add original document content (raw bytes) options are checked, and that the Flatten Compound Documents option is unchecked.
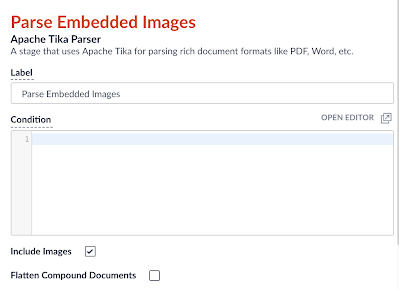
Figure 2: Tika Parser - Add a JavaScript stage to your Fusion Index Pipeline. The following code snippet will convert the binary format Tika stores the image in into a base64-encoded string:
function (doc) { if (null != doc.getId()) { var ByteArrayInputStream = java.io.ByteArrayInputStream; var ByteArrayOutputStream = java.io.ByteArrayOutputStream; var DatatypeConverter = javax.xml.bind.DatatypeConverter; var raw = doc.getFirstFieldValue("_raw_content_"); if (null != raw) { var bais = new ByteArrayInputStream(raw); if (null != bais) { var bytes; var imports = new JavaImporter( org.apache.commons.io.IOUtils, org.apache.http.client); with(imports) { var baos = new ByteArrayOutputStream(); IOUtils.copy(bais, baos); bytes = baos.toByteArray(); var base64Input = DatatypeConverter.printBase64Binary(bytes); doc.setField("base64image_t", base64Input); } } } } return doc; }Note: the script uses the javax.xml.bind.DatatypeConverter class. In order to load this class at runtime, you’ll need to add the JAXB library to the connector’s classpath and restart the connectors-classic process, as follows:
cp $FUSION_HOME/apps/spark/lib/jaxb-api-2.2.2.jar $FUSION_HOME/apps/libs/ ./bin/connectors-classic stop ./bin/connectors-classic start
- Add a REST Query stage to your Fusion Index Pipeline. Configure the REST query as shown in the following figures:
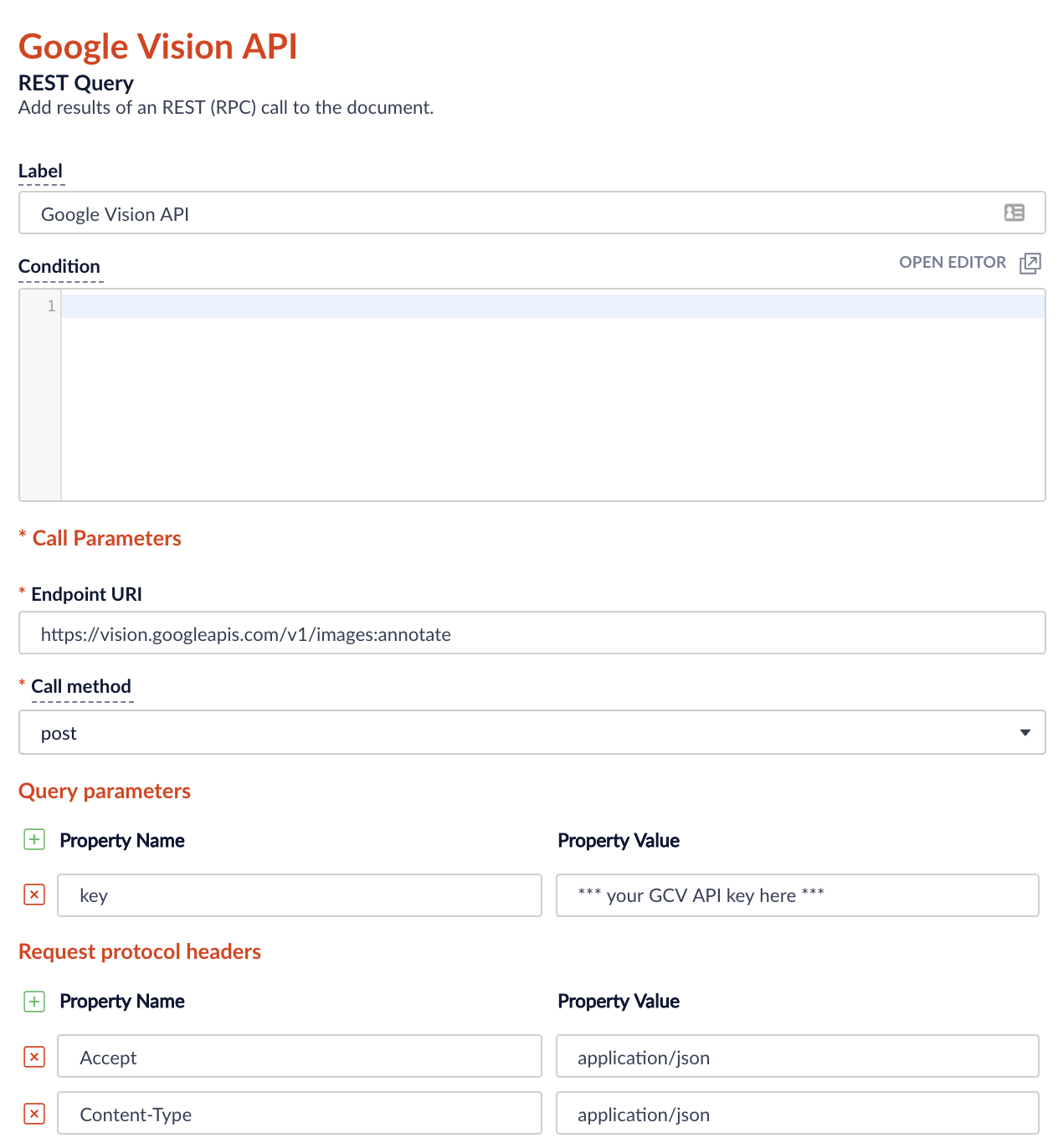
Figure 3: HTTP parameters Note: you can generate your own API key on the Google Cloud Console.
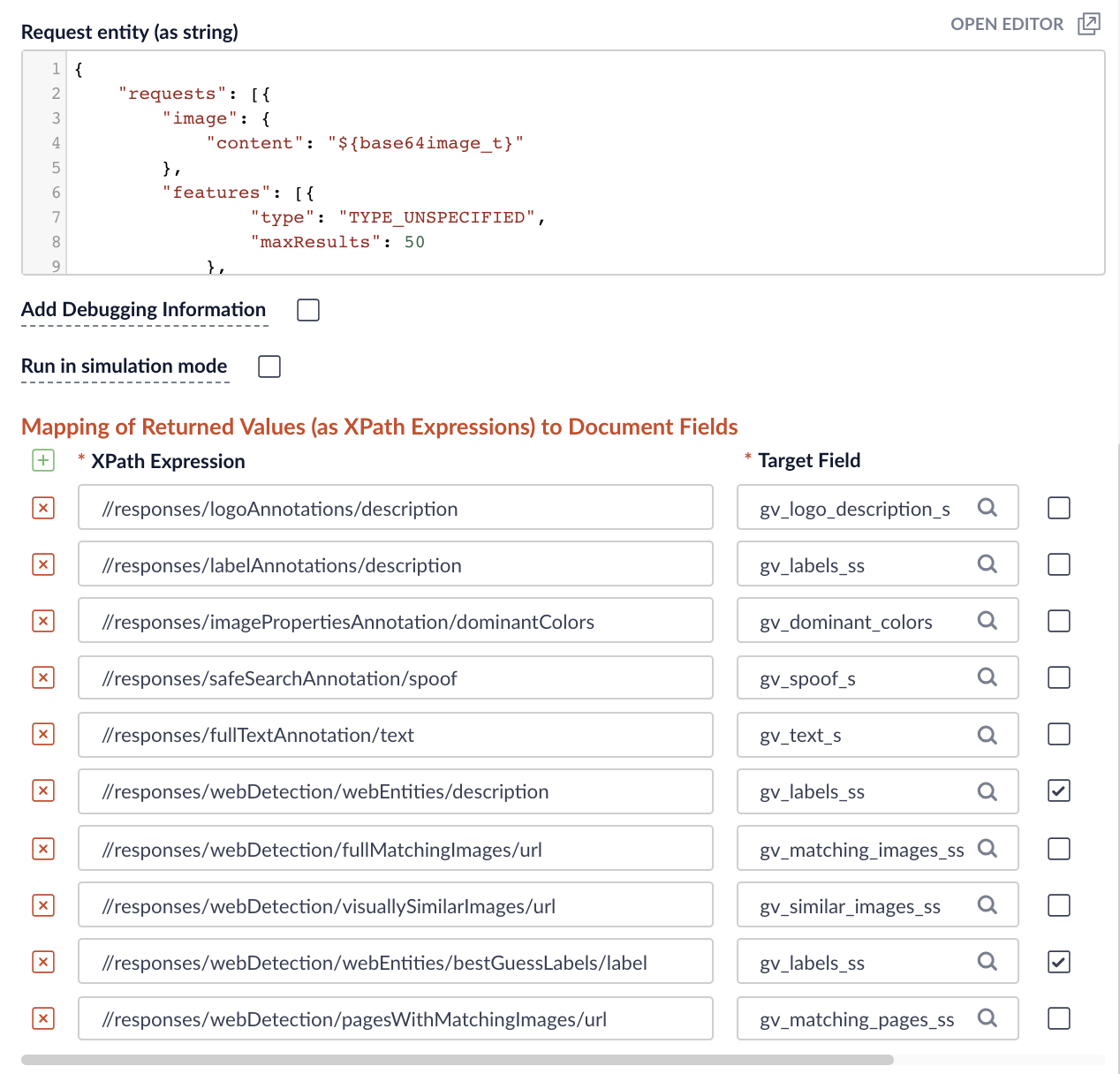
Figure 4: Field mappings Use the following JSON as the request entity. Note the use of the ${base64input} field that was defined in the preceding JavaScript stage as the value for the image.content request property.
{ "requests": [{ "image": { "content": "${base64image_t}" }, "features": [ { "type": "TYPE_UNSPECIFIED", "maxResults": 50 }, { "type": "LANDMARK_DETECTION", "maxResults": 50 }, { "type": "FACE_DETECTION", "maxResults": 50 }, { "type": "LOGO_DETECTION", "maxResults": 50 }, { "type": "LABEL_DETECTION", "maxResults": 50 }, { "type": "TEXT_DETECTION", "maxResults": 50 }, { "type": "SAFE_SEARCH_DETECTION", "maxResults": 50 }, { "type": "IMAGE_PROPERTIES", "maxResults": 50 }, { "type": "CROP_HINTS", "maxResults": 50 }, { "type": "WEB_DETECTION", "maxResults": 50 } ] }] } - Bonus — use Name That Color to find the name of the closest matching color to the image’s dominant RGB code. Add another JavaScript stage to the Index Pipeline with the following code:
function (doc) { /* +---------------------------------------------------------+ | paste the content of http://chir.ag/projects/ntc/ntc.js | | right below this comment +---------------------------------------------------------+ */ if (null != doc.getId()) { var reds = doc.getFieldValues( "gv_dominant_colors.colors.color.red"); var greens = doc.getFieldValues( "gv_dominant_colors.colors.color.green"); var blues = doc.getFieldValues( "gv_dominant_colors.colors.color.blue"); var scores = doc.getFieldValues( "gv_dominant_colors.colors.score"); if (null != reds && null != greens && null != blues && null != scores) { var dominant = -1; var highScore = -1; var score = -1; for (var i = 0; i < scores.size(); i++) { score = scores.get(i); if (null != score && parseFloat(score) > highScore) { highScore = score; dominant = i; } } if (dominant >= 0) { var red = parseInt(reds.get(dominant)).toString(16); if (red.length == 1) red = "0" + red; var green = parseInt(greens.get(dominant)).toString(16); if (green.length == 1) green = "0" + green; var blue = parseInt(blues.get(dominant)).toString(16); if (blue.length == 1) blue = "0" + blue; var rgb = "#" + red + green + blue; score = parseFloat(scores.get(dominant)); if (null != rgb && null != score) { var match = ntc.name(rgb); if (null != match && undefined != match && match.length > 0) { if (rgb != match[0]) { doc.setField( "gv_dominant_color_s", match[0]); doc.setField( "gv_dominant_color_score_d", score); } if (match.length > 1) { doc.setField( "gv_dominant_color_name_s", match[1]); } } } } } } }
Next, initiate a crawl of your web or file system datasource. For this demo, I am indexing a directory of photos that I previously downloaded from the Internet, served by a local web server.
Note: ensure that the Parser selection drop-down remains empty, as we are using a Tika Parser stage instead.
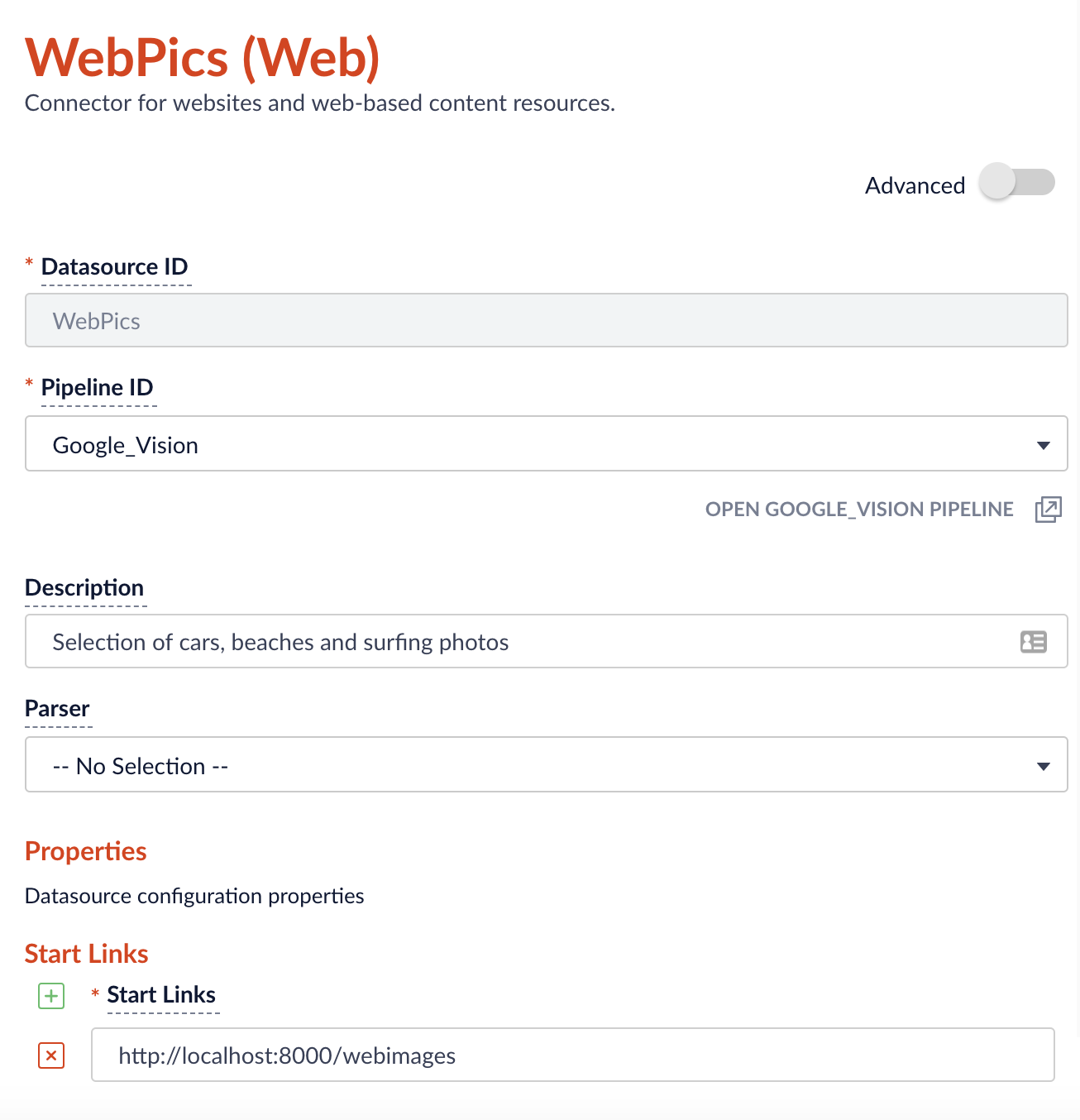
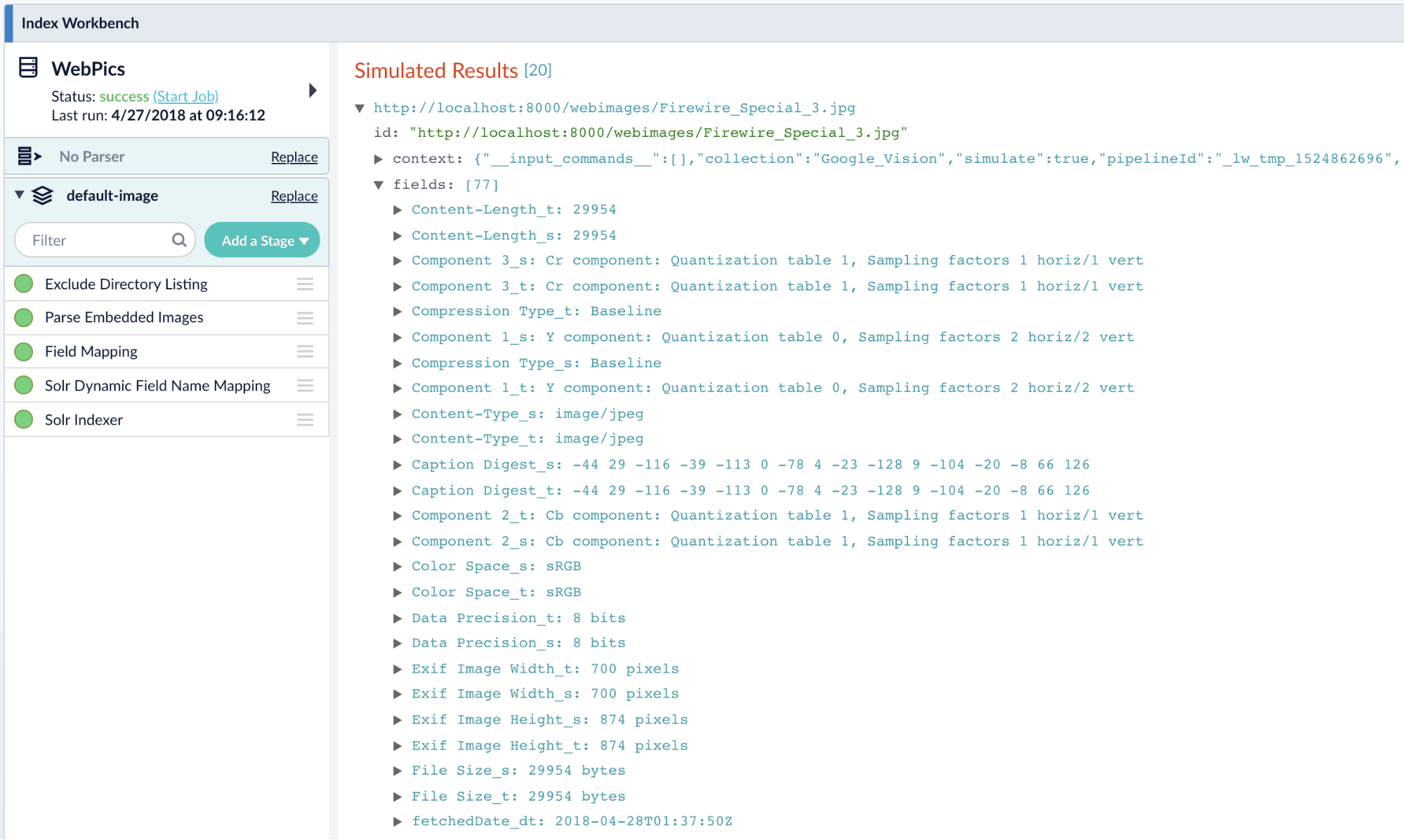
Once we have some indexed content, we can set up a few facets using the Query Workbench.
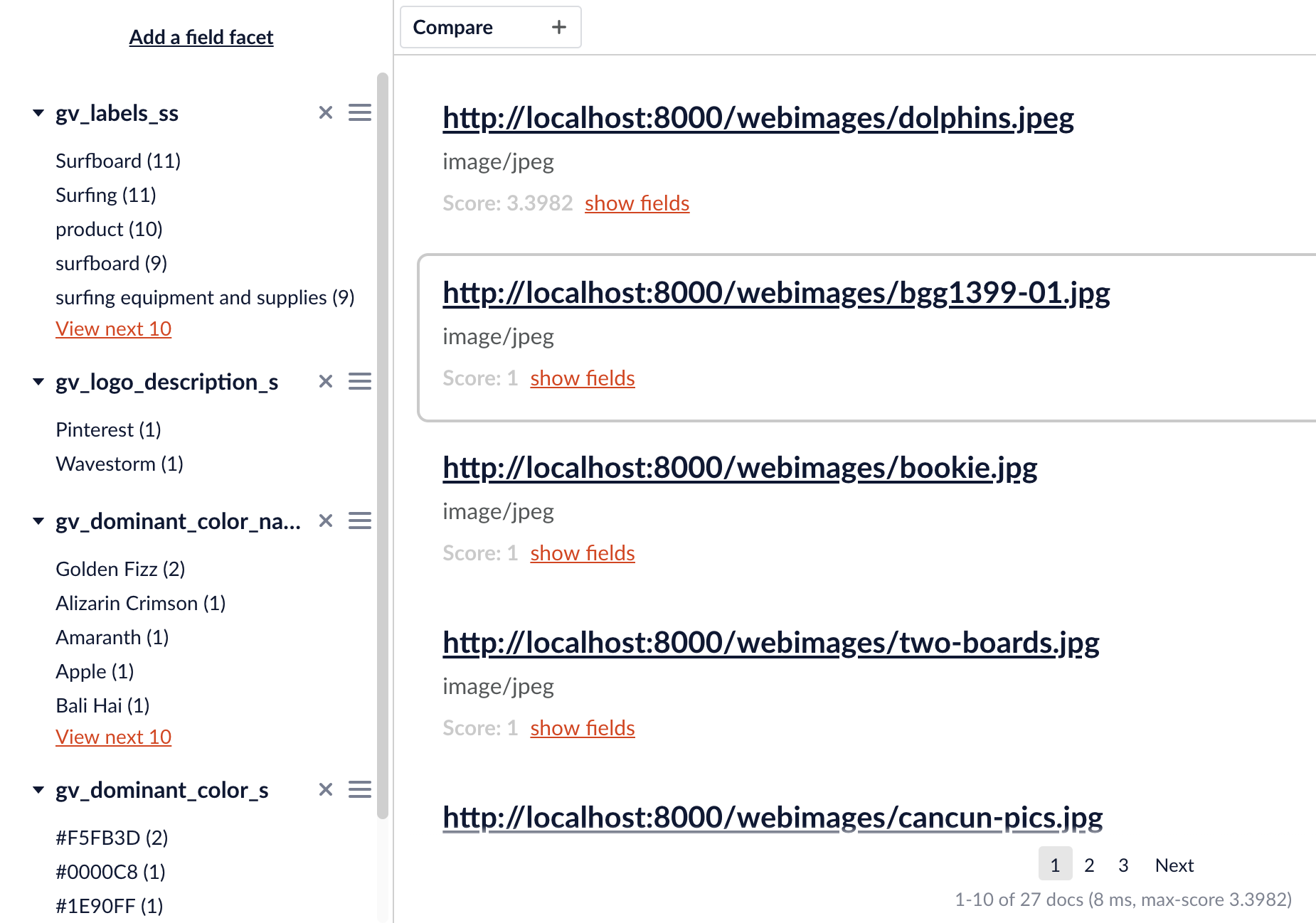
Putting it All Together
Using the newly enriched metadata, my new search app can now produce meaningful results for queries like “wooden surfboard” and a “car with white wall tires and a surfboard”. As an added bonus, the GCV AOPI also performed a reverse image lookup on the images in my local server and found the original images or hosting pages on the Internet, and those links are rendered alongside the search results.
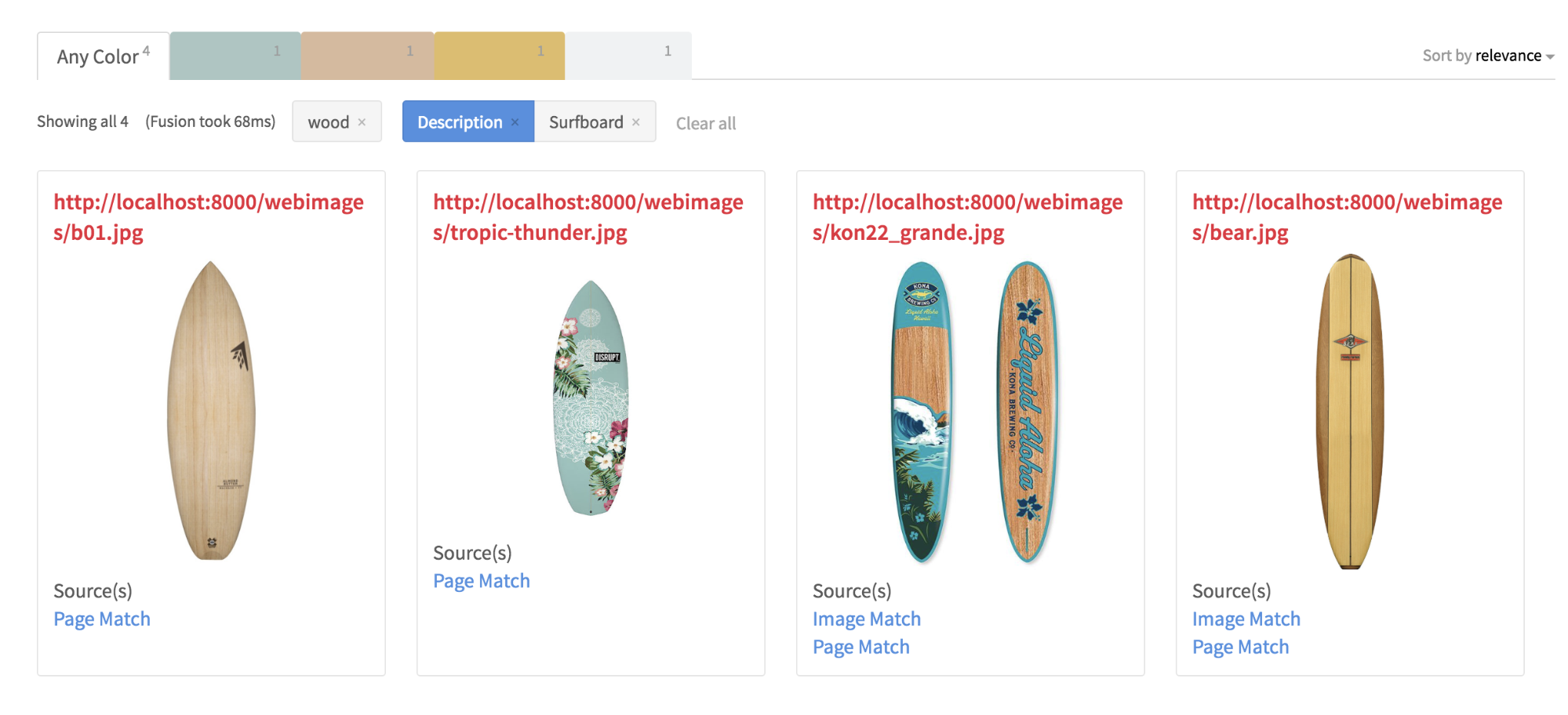
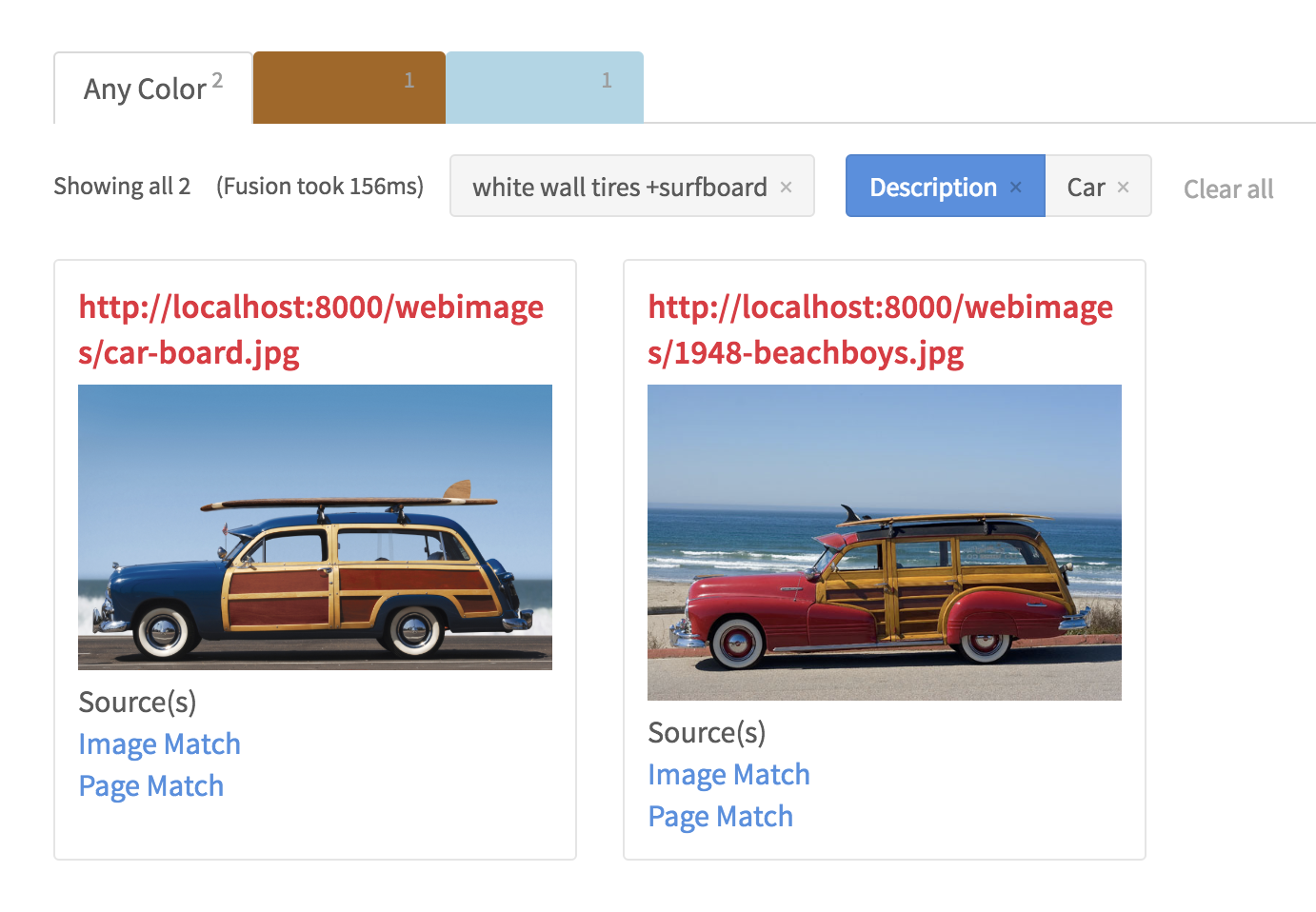
Conclusion
Lucidworks Fusion is a powerful and scalable search platform built on the open foundation of Apache Solr and Spark. Fusion’s index pipelines transform incoming data through a series of configurable stages into document objects for indexing by Fusion’s Solr core. The REST Query and JavaScript stages offer quick and easy extensibility of the data ingestion process to include external APIs such as Google’s Cloud Vision API that further enrich the metadata used by search applications.
Next Steps
- Watch my webcast Using Google Vision Image Search in Fusion and attend Lasya Marla’s A/B Testing in Fusion 4 Webinar
- Check out our previously recorded Fusion 4 Overview
- Contact us, we’d love to help.