Solr 2014: A Year In Review
The last few years have seen Apache Solr move at a reasonably aggressive pace. 2013 marked the debut of SolrCloud: a newly architected, truly distributed mode of Solr. 2014 saw Solr, specifically SolrCloud, mature in terms of greater ease of use, more predictable scalability and more reliability in production environments with each new release.
Beyond all the direct work on Solr, which is built on and released in tandem with Lucene, Solr bakes in Lucene’s steady improvements and new features.
Usability – Ease of use and management
With Solr, usability isn’t restricted to the getting started but includes the entire experience from start to finish. That means, 2014 was the year of running and managing Solr in a whole new way. Let me start by talking about the bin scripts. While the scripts make Solr really easy to start with, they have also been extended to manage a basic Solr setup. From creating a collection to indexing data, everything can now be done via a script in the bin directory. This streamlines setting up Solr to an extent where the following lines are all it takes to start, index and search Solr from scratch:
bin/solr start -e cloud -noprompt
bin/post gettingstarted https://lucidworks.com
open http://localhost:8983/solr/gettingstarted/browse
While the scripts cover the getting started experience, there was a lot more that was added to simplify going to production and even managing an existing cluster. From the introduction of schema-less mode (or, data-driven mode, as some like to call it) to managed schema APIs, which no longer require users to have the knowledge of implementation details (xml), evolving the schema for your data has now become a breeze.
Adding to the ease of use, solrconfig now supports editing common values via APIs, modeled around the bulk schema API, abstracting the implementation details.
It hasn’t just been about moving implementation details behind the scenes and hiding them behind bash scripts and API calls. Support for auto-generation of unique keys, when they are missing from a document has been another feature that makes data injection easier for users.
Also, the ability to transform and index custom JSON documents as per user configuration gives a lot of convenience to users with JSON data. The configuration is passed along with the update request.
SolrCloud and Collection APIs
Through the releases in 2014, we also saw newer Collection APIs introduced. Like the ones to migrate documents (MIGRATE), and manage SolrCloud cluster by adding or deleting of replicas (ADD/DELETE REPLICA). APIs to monitor and get statistics of the cluster and overseer have also come in handy for managing SolrCloud clusters.
Scalability and optimizations
2014 saw Solr being used at really large scale, both – in terms of data and traffic while solving complicated use cases. There were more than a few architectural changes and new features to help Solr scale to data sizes that belong in the the current generation of computing.
Among other things, thanks to Noble Paul, his effort to split the clusterstate in SolrCloud has helped Solr move towards being a highly scalable system. That, in addition to changes to support asynchronous calls and multi-threaded processing has enabled Solr to process large-scale mutually exclusive Collection API calls really fast.
Tri-level document routing in SolrCloud also helps users target documents to be co-located and enables Solr to query selective shards depending upon the request, thereby helping large setups scale up.
HDFS is an important part of the ‘big data’ ecosystem and Solr saw support for HDFS out of the box, introduced and improved over the year. This includes creating and hosting indexes on HDFS, supporting features like auto-addition of replicas on shared file systems and enhanced HDFS support for Solr.
Features
CursorMark: Distributed deep paging
This year started with Solr providing a cursor-based implementation for deep paging that works with arbitrary sorting. This enables users to export results or page really deep, which until that time had been traditionally been inefficient.
TTL: Auto-expiration for documents
Another one of numerous contributions to Solr was the ability to periodically delete documents based on an expiration field or a time-to-live (TTL) specified while indexing. This allows users to automatically delete docs from the collection after their expiration date.
Distributed Pivot Faceting
This year saw distributed pivot faceting – an issue that was opened over 3 years ago, had over 75 watchers and required 20+ contributors – get committed by Hossman. Those numbers speak for both, the complexity of the feature as well as the community around Solr.
75 watchers and 56 votes, @_hossman just closed the massive Solr feature, Distributed Pivot Faceting https://t.co/gE6s41wMAl #Solr
— Mark Miller (@heismark) August 20, 2014
Query Parsers
Solr supports numerous query parsers and newer ones make things easier for specific use cases. This year saw Lucene’s SimpleQueryParser exposed in Solr via “Simple” query parser. Another addition was TermsQueryParser, which was aimed at the security filtering use case, which involved filtering terms, which until that point involved constructing Boolean query, often hitting the max clause limit and also leading to scoring of hits. Yet to be released, the MLTQParser helps users find documents similar to an already existing document, given a document’s unique id.
Distributed IDF
Another one of the long running issues that took multiple contributors and a total of almost 5 years was “Distributed IDF”. It will be out with the next release of Solr, Solr 5.0 and will help users with non-uniform distribution of terms across their data.
Apache Solr Santa came early this year and gave us Distributed IDF b/c we were good! https://t.co/IMiA981or7 #solr #solrcloud — Otis Gospodnetić (@otisg) December 22, 2014
Solr Scale Toolkit
SolrCloud hasn’t been trivial to deploy, especially when it comes to large scale deployments. Early in 2014, Lucidworks invested time, money and resources to build and open-source Solr Scale Toolkit for conveniently deploying and managing SolrCloud in cloud-based platforms such as AWS. This toolkit, has been further improved to support non-cloud based setups.
Testing
A lot of maturing of SolrCloud has come by way of testing it. Not restricted to end-users taking Solr to production, but way beyond that. We at Lucidworks have invested extensively in testing SolrCloud, be it using the Solr Scale Toolkit to setup 1000 collections and indexing billions of documents, while trying rolling restarts to make sure that the system stays stable, or through the impressive Jepsen tests by Shalin Shekhar Mangar to confirm that Solr doesn’t lose data. This, in addition to the improved Junit test coverage for Solr, is a part of the project.
https://twitter.com/aphyr/status/543547826756530176
No more war
Solr 5 will see Solr being officially supported only as it’s own application. A ‘war’ will no longer be shipped with the distribution and with the servlet container becoming an implementation detail, it changes the way people have looked at Solr as far as setting it up is concerned.
Solr 5
The last few months of 2014 have been about Solr 5.0. Right after 4.10 came out, a decision was made to call the next release “Version 5.0”. It’s reasonably different from the kind of release 4.0 was, as it’s less of an architecture change and more of a maturity release. From where it stands, it already is packed with a lot of goodness. From enhanced bin scripts that let you do a lot more, to more SolrCloud management Collection API calls. From the splitting of clusterstate to specifying query timeouts, some of the stuff I’ve written about above is yet to be released with Solr 5.0 but was done all in 2014.
Community
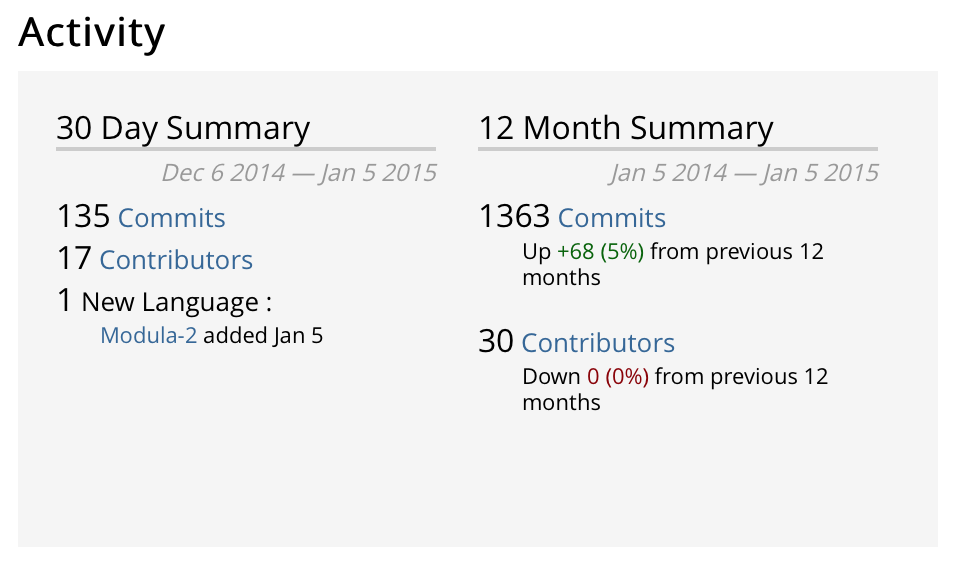
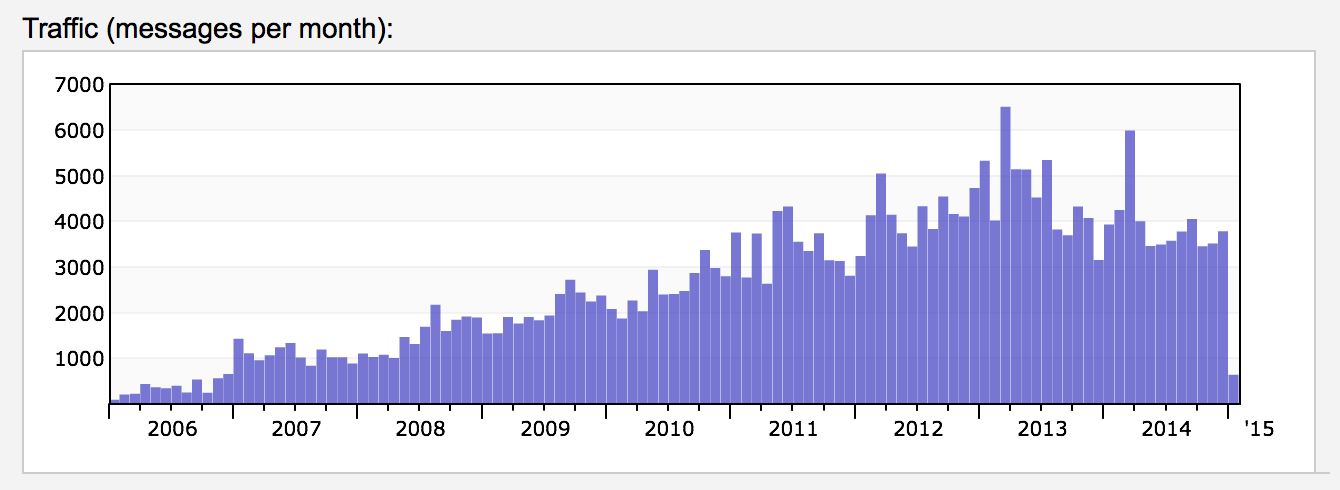
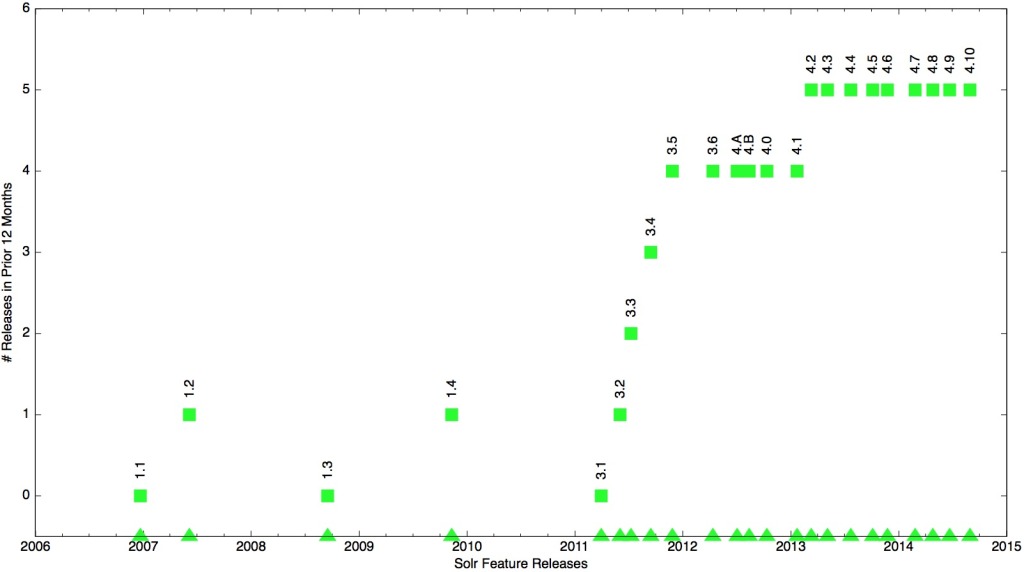
Though we saw tons of features, testing, usability fixes go into Solr, we can not miss the awesomeness of the all new Solr website and logo. Thanks to Francis Lukesh for creating it and everyone else involved to tighten the bolts and get it in. Finally, the numbers below speak more about how Solr as a project has shaped up over the last one year.