Solr Powered ISFDB – Part #7: Simple UI
This is part #7 in a (never ending?) series of articles on Indexing and Searching the ISFDB.org data using Solr.
When we left last time, I had added pseudonym information for authors so that there was pretty good coverage of all the key pieces of information people might want to search on when looking for authors or titles. This week, I’m going to switch tacks and talk a little about one of my least favorite things to work on: User Interfaces.
(If you are interested in following along at home, you can checkout the code from github. I’m starting at the blog_6 tag, and as the article progresses I’ll link to specific commits where I changed things, leading up to the blog_7 tag containing the end result of this article.)
Disclaimer #1: I Am Not A UI Guy
To start things off, I should make it clear that I don’t really like working on UI stuff. I’m most happy when I’m just hacking away on back-end code that crunches and returns data in a structured manner — so that other people can write UI code to display it in pretty ways. That said, UIs are obviously important, and when working with search code/data it tends to be crucial to have some easy mechanism to really take a good look at the data you’ve got to work with while you iterate. I’m happy to read raw XML when I work with Solr, but when tuning relevancy, and tweaking configs, you can frequently work a lot faster when you have a simple UI (even if it’s just a quick prototype) that helps you easily view results and facet counts.
Solr has a plugin called Solritas which can be used to generate UIs directly in Solr using Velocity templates. Since I need a simple UI, and since I don’t know anything about Velocity, it seems like a good choice for building a basic UI today. (and learning some things in the process)
Disclaimer #2: Separation of Logic and UI
I’m a big believer that a good application should have a clear separation between the application logic and the presentation of the results. While Solritas has been used by a lot of people to build some very nice UIs for Solr, I personally don’t think it’s a good idea to have Solr generating webpages that are consumed directly by users. I think of Solr as a DataStore — a repository of data/logic. I treat it the same way I treat a database, or a NoSql repository, or a local file-system. I like it to be walled off from my users, and have them utilize it by accessing an application layer that talks to Solr on their behalf.
With that said: There are certainly advantages to letting Solr create an HTML based UI for you directly. When building prototypes, proof of concepts, internal tools, etc… it can definitely be handy to have one less moving part in your system. And for the purposes of this blog, where the primary purpose is to learn about and demonstrate Solr features, there is very little downside.
It should also be noted that within Solr there is already a decent separation between logic and presentation. Solritas is implemented as a QueryResponseWriter that has access to the Solr response after the SolrRequestHandler has processed it. It’s probably possible for a Velocity template to contain logic and data processing, but you’d have to go out of your way to do so. So as long as you implement your Velocity templates with a separation of concerns in mind, re-implementing them in another application (using the output from another QueryResponseWriter) at a later date should be completely straight forward.
Ok, enough disclaimers. Time to get started.
Step #1: Reuse Some Templates
I really knew next to nothing about the VelocityResponseWriter (or Velocity!) when I got up this morning. What I did know is that you declare it in your solrconfig.xml, and then you point it at some Velocity templates. So to start with, I copied the existing templates from the VelocityResponseWriter sample configs along with the basic solrconfig.xml changes to use it. Note that I also modified my build.xml slightly to copy the jars I’d need into my lib directory.
The result wasn’t the prettiest UI in the planet, but it wasn’t bad considering I didn’t have to write / modify any code…
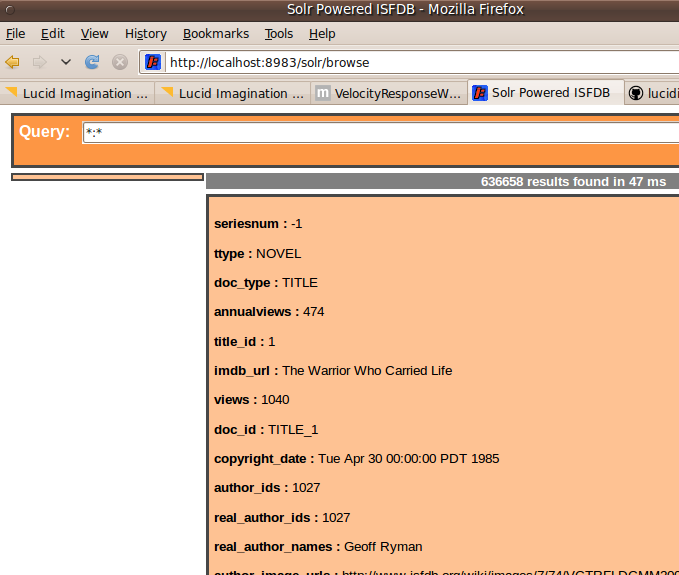
Without even looking at those sample templates, or learning anything about Velocity syntax, I was able to make some improvements just by modifying my solrconfig.xml and schema.xml. I started be adding some default faceting. This gave me a quick and dirty left nav with some facet links so I can see at a glance how the various documents are organized, but it also exposed a few limitations in the templates I copied:
- They don’t seem to display “facet.query” counts by default
- The template seems to have “/itas” hard coded in them (the path it was registered to in the sample solrconfig.xml) which means the facet links and search box won’t work since I picked a different name for the request handler
Now I could have dove in and start trying to fix these things, but I happen to know that a lot of work has been done on improving these templates for the next release of Solr. Even with out upgrading Solr, I (was pretty certain I) would be able to upgrade just the templates and get all of their improved goodness. So I tried it, and things definitely got more visually pleasing…
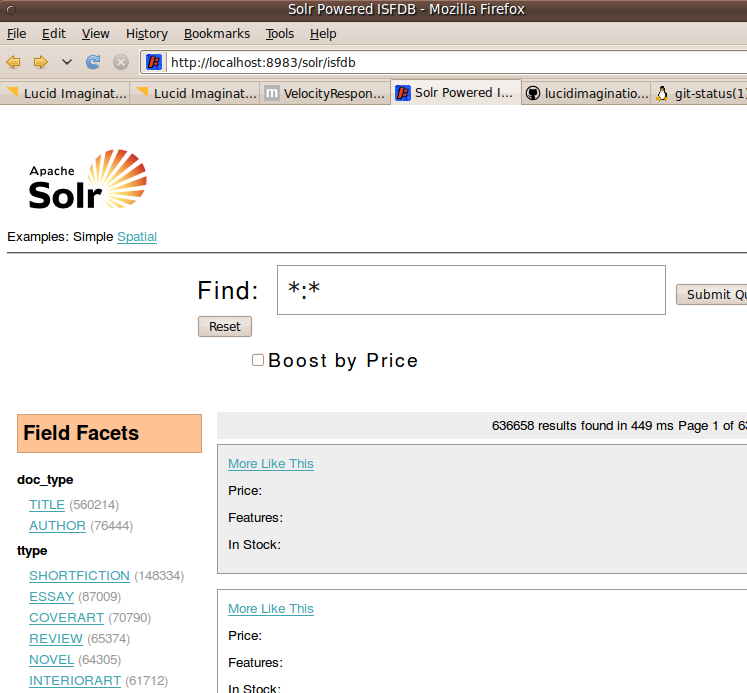
…but there were still some problems…
- The newer templates have hard coded field names for display
- My query facets for filtering out pseudo authors showed up, but they appeared twice (once in the range faceting section?)
- The new templates still had the request handler path hard coded, but now it’s hard coded to “/browse”
…so it was time to have to get my hands dirty and learn some velocity!
Step #2: Customizing Templates
I started by changing how the individual results were displayed, so I could get the fields I want returned. Poking around in the velocity directory, I found that the template responsible for generating the individual documents was called “doc.mv” (I found it by greping for “Price:” since that seemed to be hard coded). The first thing I notice is that velocity directives seem to use a “#” prefix, and everything else looks like regular HTML … except for echoing variables and function output, that seems to use “$” … oh well. I figured I’d just start hacking on stuff and eventually I’d get the hang of it. (turns out “#” is how you refer to macros, and “$” is how you refer to objects, which can have methods)
I started with something simple: ripping out the “More Like This” links. I plan to show off More Like This at some point, but not today. (It’s particularly interesting that these MLT links seem like they were suppose to be hidden unless a special param was specified, but they were always showing up for me … all the more reason to rip it out). I also update the “result-title” div so that instead of displaying the “name” field, it displayed the fields “title” and “canonical_name” followed by doc_type. This way I would always have a good “header” for each item regardless of the doc_type. (ultimately I wanted to make the display conditional on the “doc_type”, but I started with baby steps).
Right off the bat, I discovered some problems. Apparently I had some title docs with out a “title” field. Not sure how that happened, I used a quick query to find all TITLE docs, faceting on whether they have any terms in title field and I discovered that apparently none of the title docs have a title. Clearly I introduced a bug a while back and never realized it.
Looking at my DIH config, I saw that I was most definitely indexing the “title” as an “imdb_url” field … obviously a stupid cut/paste mistake I made a while back and never noticed until now. Go figure. Once I fixed that I could move on to making other improvements to the fields that were displayed for each of my doc_types (and driving the presentation based on the type of doc).

All of these changes were made just by muddling my way through the Velocity syntax using the existing templates as examples and knowing that these are all Java objects under the covers. I’m sure a Velocity expert would say my changes where very clunky and overly-complicated — but so far so good.
Step #3: Cleaning Up Some Messes
So now I had a very rudimentary display, but there was still a lot of “cruft” in the UI left over from the example templates I copied. I wanted to rip all that out. This was mostly straight forward by greping for the text I saw being generated that I didn’t want…
- “Boost by Price” checkbox
- Range Facets (not available in Solr 1.4.1, and the Velocity template has price hard coded)
- Spatial (not available in Solr 1.4.1, and the ISFDB data doesn’t have any lat/lon fields
I also noticed that there was a lot of debug related links that didn’t seem to do anything. Looking at the HTML source for the generated pages, I realized this was trying to use jQuery but according to the javascript console in my browser, jQuery wasn’t working at all. Poking around the generated HTML “script” links made it clear the velocity templates were assuming a particular version of jQuery would be directly available in the “/solr/admin/” directory, and the version in Solr 1.4.1 is slightly older. So I fixed the jQuery reference, along with the debug call (which assumed the uniqueKey field was ‘id’).
Step #4: Hyper-linking
At this point, the UI was still by no means pretty — but it was functional and far easier to read then the raw XML (or JSON) output from Solr. (even if most fields still weren’t being displayed). The one remaining thing I really wanted to do before wrapping up the day was to add some hyper-linking:
- Link titles to their Authors
- Link Authors to their Titles
- Link pseudonyms and authors to each other
I’m sure the “right” way to do a lot of this in Velocity would be with some reusable macros, but I started simple (It can always be refactored later).
Linking to individual authors (from pseudonyms, or titles that only have one author) was fairly straight forward; as was linking to the list of titles by an author. In both cases it was just a simple link using a single value from the current result. Linking to all authors of a title, or all pseudonyms of an author was a bit trickier, because i needed to correlate values from multiple fields (the “ids” and the “names”) and up until this point I’d only dealt with simple “foreach” loops in Velocity. So I had to go lookup the documentation, and figure out how to use indexed for loops to build the links. It wasn’t too painful to accomplish. But I did struggle initially because I was looking at the User Guide for the wrong version of Velocity and the variable for accessing the look counter has changed.
Conclusion (For Now)
And that wraps up this latest installment with the blog_7 tag.
The end result is something that can display simple search results, with titles and authors linking back and forth between each other. It’s still pretty ugly, but I definitely think it’s useful…
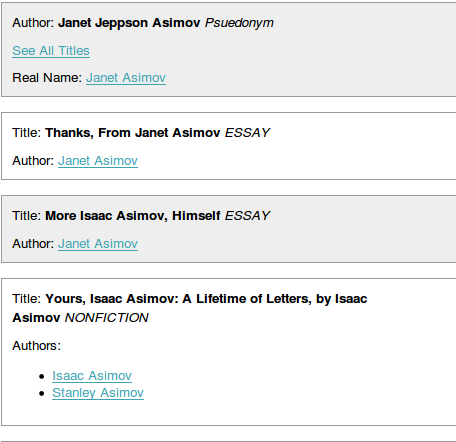
Next time I hope to make further improvements to the basic UI (hopefully with out getting sucked too deep into learning about Velocity).