Apache Solr Segment Merging, Deleted Documents, and Why Optimize May Be Bad For You
This article applies to Apache Solr 7.4 and earlier. The behavior described in this post is not the default behavior in later versions of Solr. For Solr 7.5 and later, go to Solr and Optimizing Your Index: Take II. This article is still relevant background material for understanding why the newer default behavior is preferable.
Solr Merge Policy and Deleted docs
During indexing, whenever a document is deleted or updated, it’s not really removed from the index immediately. The document is just “marked as deleted” in its original segment. It doesn’t show in search results (or the new version is found in the case of update). This leads to some percentage of “waste.” Your index may consist of, say, 15%-20% deleted documents.
In some situations, the amount of wasted space is closer to 50%. And there are certain situations where the percentage deleted documents can be even higher, as determined by the ratio of numDocs to maxDocs in Solr’s admin UI.
Having half or more of your index “wasted” isn’t ideal. This article explains how these conditions arise and what to do about it. Spoiler: not a lot.
NOTE: We talk about “deleted” documents. For the purposes of this article, “deleted” includes both explicit deletes and updates to existing documents. This latter is implemented as a delete of the original document followed by an add.
Good News, Bad News

The good news is it’s easy to avoid having more than 50% of your index consist of deleted documents; do not optimize. We’ll talk about how optimize (aka forceMerge) can allow more than 50% of the index to consist of deleted documents later.
The bad news is there’s no configuration setting as of Solr 7.0.1 that will guarantee that no more than 50% of your index consists of deleted documents. You can read about this discussion and the fix Apache JIRA list at LUCENE-7976.
Apache Lucene Segments Are “Write Once”
Since about forever, Lucene indexes have been composed of “segments”. A single segment consists of multiple files sharing the same root name, but different extensions. A single segment consists of files like _0.fdt, _0.fdx, _0.tim and the like.
Lucene has a “write once” policy with respect to segments. Whenever a “hard commit” happens, the current segment is closed and a new one opened. That segment is never written to again [1]. So say a segment contains 10,000 documents. Once that segment is closed, that segment will always contain 10,000 documents, even if some are marked as deleted.
This can’t go on forever. You’d run out of file handles if nothing else.
Merging to the Rescue
The solution is “merging”. We mentioned above that when a commit happens, the segment is closed. At that point Lucene examines the index for segments that can be merged. There are several “merge policies”, all of them decide that some segments can be combined into a new segment and the old segments that have been merged can be removed. The critical point is that when segments are merged, the result does not contain the deleted documents.
Say two segments, each consisting of 10,000 docs 2,500 of which are deleted. These two segments are combined into a single new segment consisting of 15,000 documents, the 2,500 deleted documents from each original segment are purged during merge.
Anyway so far so good. And the default TieredMergePolicy (TMP) usually keeps the number of deleted documents in an index at around 10-15%.
It turns out, though, that there are situations where the various merge policies result in some behaviors that can result in up to 50% deleted documents in an index.
Why is Merging Done Like This?
It’s always a balancing act when creating merge policies. Some options are:
- Merge any segments with deleted documents. I/O would go through the roof and indexing (and querying while merging) performance would plummet. In the worst case scenario you would rewrite your entire index after deleting 0.01% of your documents.
- Reclaim the data from the segments when documents were deleted. Unfortunately that would be equivalent to rewriting the entire index. These are very complex structures and just reaching in and deleting the information associated with one doc is prohibitively expensive.
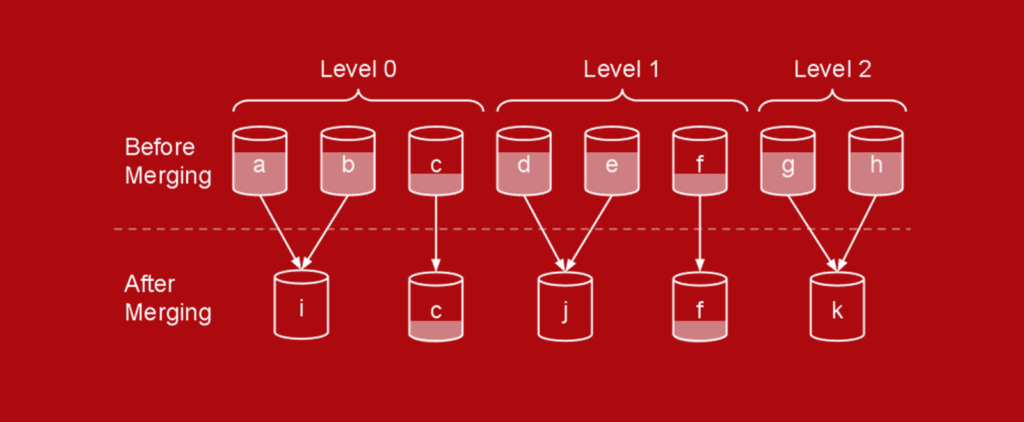
In this diagram, shaded portions indicate deleted docs. a, b, d, e, g and h have roughly 60% deleted docs, c and f 20%.
What? I Can’t Afford 50% “Wasted” Space!
Indeed. So how does that happen in the first place? Well, it gets a little tricky. Note that there is a “max segment size” that defaults to 5G that I’m using here, which can be configured higher or lower.
The root problem is that only segments with < 50% “max segment size” live documents are eligible for merging.
Let’s take an idealized 200G index consisting of exactly 40 segments each 5G in size. Further, let’s assume that docs in the corpus are updated randomly. None of these segments are eligible for merging until they contain < 2.5G “live” documents. Eventually all of the original 40 segments will have 2.51G “live” documents (or close enough to 50% for me).
You can see Michael McCandless’ writeup here, with graphs! He’s been deeply involved in the merging code.
What Can I Do About This?

Unfortunately, not much. Here are some ideas people have had:
- forceMerge (aka optimize) or expungeDeletes. These operations will, indeed, remove all deleted documents if you forceMerge and merge all segments over a certain percent in expungeDeletes. However, the downside here is that once you optimize, you have to keep optimizing it or live with lots of deleted documents [2]. The reason for this is that forceMerge (and expungeDeletes for that matter) create a large segment as a result [3]. In a 100G index example that single segment will be 100G despite the (default) 5G max segment size. Now to become eligible for merging, that single large segment must have < 2.5G “live” documents, it’ll have up to 97.5% wasted space.
- Make the max segment size bigger. We mentioned that this defaults to 5G, which can be done through a setting in solrconfig.xml. Changing the max segment size makes no difference since the problem isn’t how big each segment can be, it’s the fact that the segment is not considered for merging until is has < 50% of max segment size undeleted documents.
- Dig into the arcana of the merge policy and tweak some of the lower-level parameters. There are properties like “reclaimDeletesWeight” that can be configured by tweaking TieredMergePolicy in solrconfig.xml. None of those parameters matter since they don’t come into play until the segment has < 50%(max segment size) live documents, and there’s no option to configure this.
So Where Exactly Does That Leave Us?
Lucene indexing has served us well for years, so this is an edge case. Unless you are running into resource problems, it’s best to leave merging alone. If you do need to address this there are limited options at present:
- Optimize/forceMerge/expungeDeletes. These options will remove some or all of the deleted documents from your index. However, as outlined above, these operations will create segments much larger than the maximum considered for future merges and you’ll have to perform these operations routinely. OPTIMIZING IS NOT RECOMMENDED FOR NRT INDEXES! These are very heavy-weight operations, generally suitable only for very slowly changing indexes. The implication here if you index only periodically (say once a day) and can afford the time to optimize every time you rebuild your index, then optimizing is perfectly reasonable.
- Cleverly execute optimize/forceMerge. You can optionally tell the optimize/forceMerge operation to merge into N segments instead of just a single one, where N is something like (fudge factor) + (total index size)/(max segment size). Theoretically, that would not run into the pathological situation where > 50% of your index consisted of deleted documents. This is not explicitly supported behavior so I’d be very reluctant to predict the behavior.
- Change the code. Either create a patch for LUCENE-7976 or propose a new merge policy.
Conclusion
This article looks scary, but do remember that TieredMergePolicy has been around for a long time and has served admirably. We created this document to provide a reference for those situations where users notice that their index consists of a greater percentage of deleted documents than expected. As Solr and Lucene move into ever-larger document sets, it may be time to tweak TieredMergePolicy and/or create a new merge policy and that discussion is already under way.
[1] We’re simplifying a little here, the documents in that segment are marked as deleted in a separate file associated with that segment, so in that sense the segment is written to after it’s closed. But that’s unimportant for this discussion.
[2] We’re simplifying again here. If your index is unchanging, or if you always add new documents so no documents are ever updated or deleted, optimizing doesn’t have this downside since there won’t be deleted documents in your index and will show some improved response time.
[3] You can specify that the result of forceMerge will be more than one segment, but that doesn’t change the overall situation.
This post originally published on October 13, 2017.