Solr Streaming Expressions Enables Advanced Search and Filtering in Fitch Connect
Fitch Solutions helps clients manage credit risk by providing intelligence on the macroeconomic environment and debt investment market. Fitch Connect, their flagship product, makes information like credit ratings, macroeconomic data, bank ratings, and industry research, available in one platform. With Fitch Connect, customers have access to data that supports informed decision making.

At virtual Activate, Prem Prakash, technical lead at Fitch Solutions, and Weiling Su, senior developer and in-house Solr and Fusion expert, shared the path they took to enable text search, numeric range filters, and alpha numeric range filters for data stored in different collections. They described how, ultimately, Solr streaming expressions and Fusion query pipelines enabled them to pull data stored in three separate Solr collections with a single query.

Searching Fitch Connect
Fitch Connect’s search page looks like this:
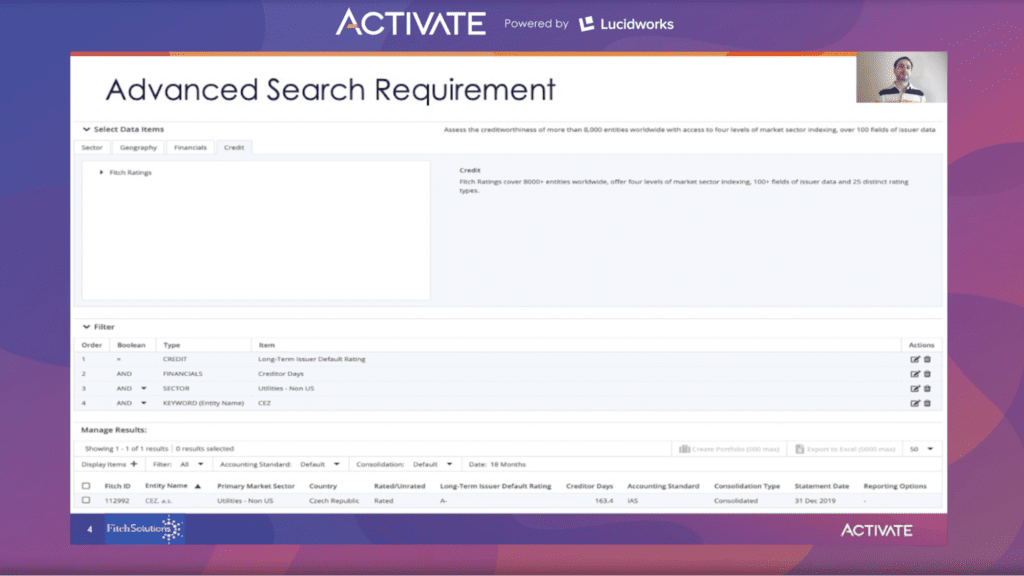
At the top of the page is the “Select Data Items” option. Below this, data filtering categories: sector, geography, financials, and credit, of which geography and credit offer selectable filters, and financials offers numeric range filters in addition to selectable filters. Once filters are applied, results are displayed in the “manage results” section at the bottom of the page.
Drilling down into available filters, specific entities can be searched by using a keyword, and if that entity is found, the filter can be applied. Filters are available for region, market sector, and rating. On top of the ratings filter, rating actions, rating watchers, and rating outlook can also be applied.
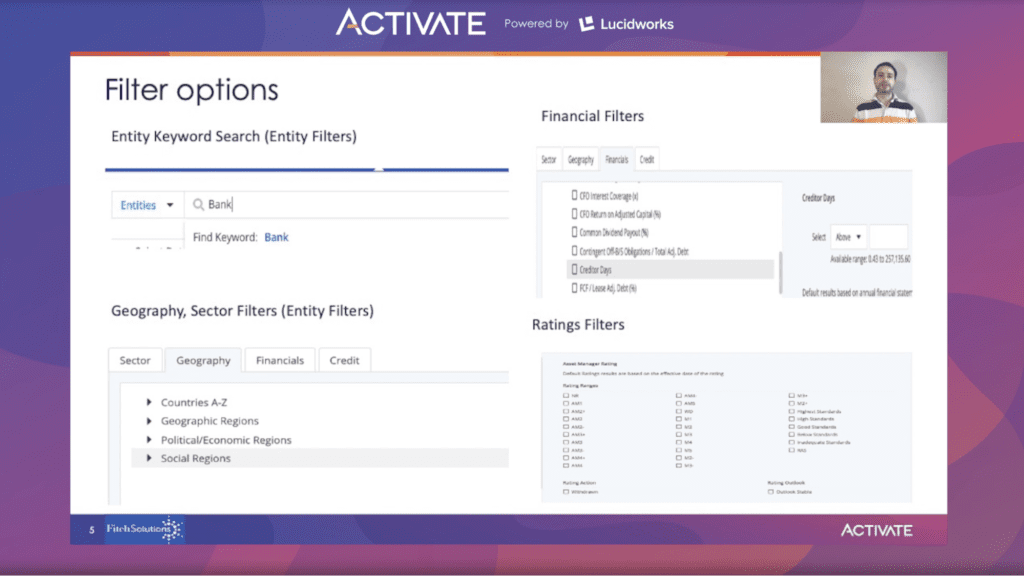
In the financial filters, once the financial field is chosen, there’s an option to select a range above, below, or between the values entered in the text box.
Data Structure
Due to the varied nature and complexity of the data that Fitch Connect accesses, it is stored in three separate Solr collections: entity, ratings, and financials. Entity and ratings data is joined by the entity ID and all the three collections are joined by the agent ID.

On top of this joined data, keyword search has to be performed and text filters applied. For the financial data, numeric range filters are also available. Finally, historical data needs to be retrieved. All of this needs to be accessible with a single query.
Fitch considered storing all of the data in one collection to make this feasible, but given the complexity of the data structure and the nature of the historical data, it just wasn’t possible. By storing the data in three separate collections, the data structure is simple and easy to work with. Many requirements need just a particular data set, displayed on different screens, which is made easier with this isolated data structure. Data refresh is also easier to handle.
Paths to a Solution
Solr join query and sub query, Solr parallel SQL, Fusion SQL, and streaming expressions were explored to support a Solr data join:

The important features of the join mechanism were identified as:
- limit on the number of collections that could be joined
- filters able to be performed on both sides of the join
- keyword search
- sorting
- grouping
- pagination
- customization
Based on analysis performed by Fitch Solutions, streaming expressions emerged as the best solution.
Benefits of Streaming Expressions
Streaming expressions is a powerful stream processing language with a suite of functions that, combined, enable many, parallel computing tasks to be performed. Its substantial open-source community also provides a growing library and support.
Streaming expressions enable three different functions:
- Stream sources, originate the streams.
- Stream decorators, wrap other stream functions or perform operations on the streams.
- Stream evaluators, evaluate experiments and return results.

Stream sources and stream decorators return streams of tuples (a row of data retrieved from Solr). Stream evaluators act more like a traditional function, evaluating experiments and returning results.
Using Fitch Connect
A customer on Fitch Connect might search for a bank with total assets greater or equal to 2M, and a long-term issuer default rating value of A-, A, A+, AA, AA+, or AAA. They want results sorted by bank name in alphabetical order with 25 results showing per page.

The search function is used to filter out the matched tuples from the core Solr collection. A tuple consists of the raw data of the data values and the timestamp.
How It’s Done
In the core collection, the following is performed:

Any sorting option can be applied to any returned field, but since the next step is to perform joins, the join operation requires both joined streams be the same sorting field type and in the same sorting order. A sort function can be saved by specifying the same sort field and order to prepare for the join.
A select function is used to project the fields and/or rename the fields. In the example above, the entity ID is renamed to be the issuer or transaction ID, and the ID is grouped by ID. Qt parameters are used by default in the search handler, but a paginated output will be returned rather than the total record. If you want to apply the join to the whole collection, Qt parameters must be set to equal “export”. Fitch performed an innerJoin to find all the matches once.
In the second collection, data is filtered from the financial Solr collection using the search function by applying the range filter on total_asset_bnk greater or equal to 2. More criteria are applied with periodType, latestStatement, stmntDate, accountingStandards, and cross consolidationType.
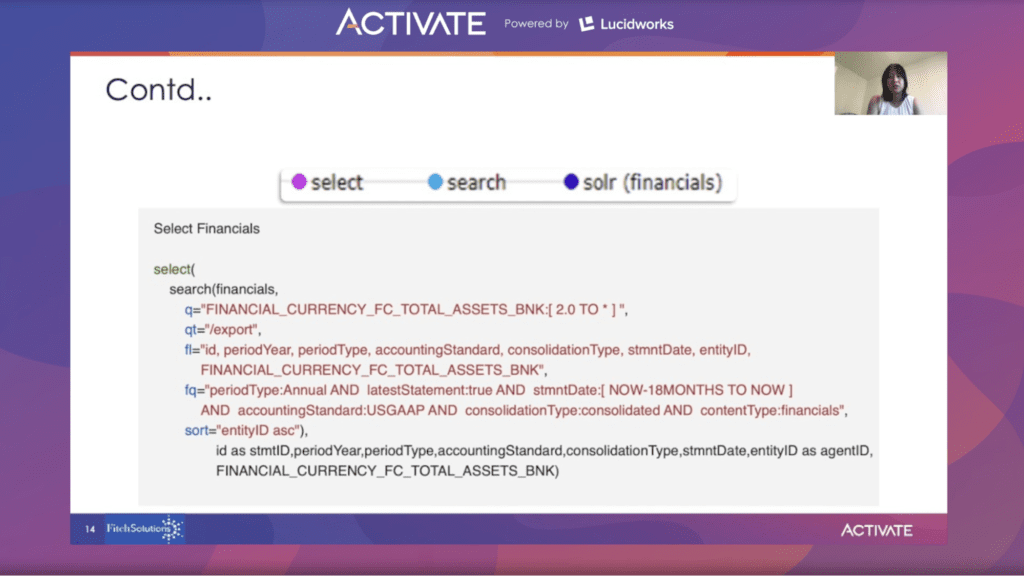
The select function renames the field to a more meaningful name, then the sorting function is applied to entity ID in ascending order.
In the rating collections, the search function is used to filter rating values.
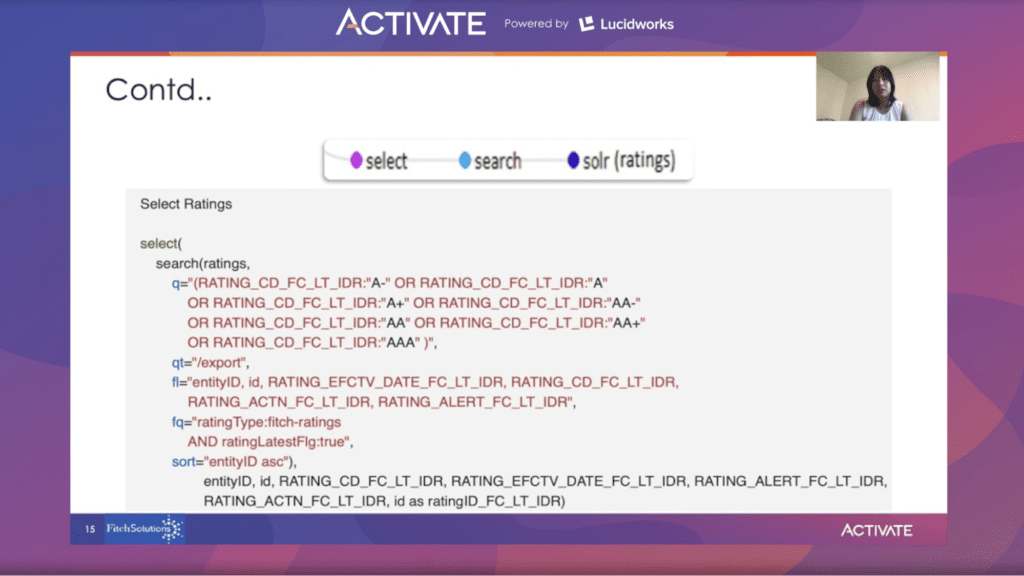
Sorting on entity ID in ascending order, the same way previous collections were sorted, allows a clean join.
Once the data has been filtered, the join operation can be performed.

A join between the core collection and financials collection is done on agent ID. Several join types are available to use. A hash join function will give a performance edge over an inner join, but with the big data used by Fitch Connect, an inner join is the best option. When calling the inner join function, the join condition is specified with parameters set to equal a certain condition. If the join fields from both sides have the same name, only one field name is necessary. If they vary, it needs to be specified that the left field name equals the right field name. If the join fields or the orders differ, another sort needs to be performed before the next join.
The data returned from the previous join of entity and financials is now joined with the rating data. A sort function is applied on top of the inner join between entity and financials to enable the data to join correctly with the rating data because the inner join with the rating data is on entity ID rather than the agent ID used in the previous join.

Here is the final query:
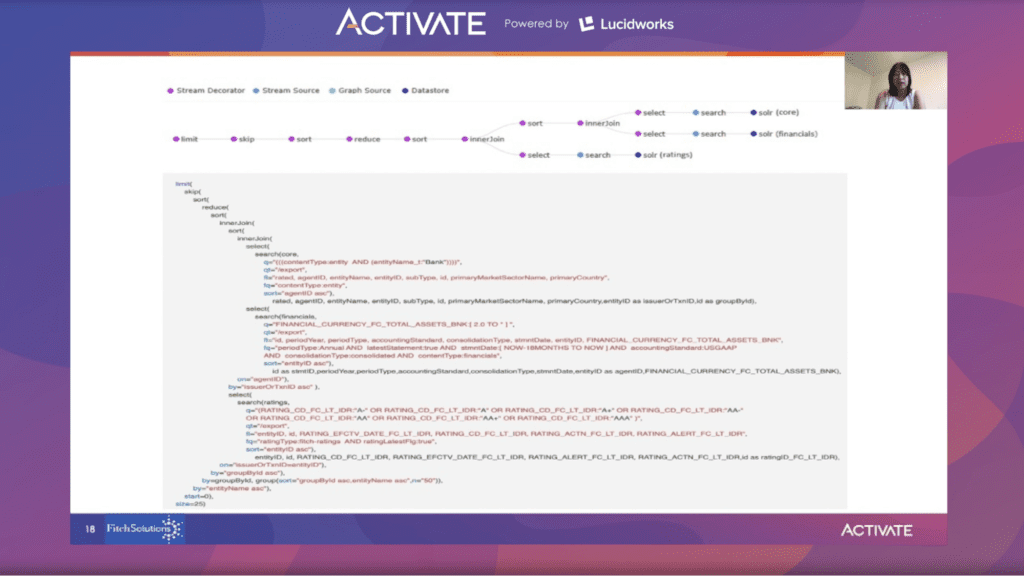
A reduce operation is performed to group by the groupByID field since the final results will be aligned by groupByID. One entity will have many matched ratings and many financial records. When using groupByID, we know how many unique entities are a match. Finally, the limit and skip functions allow results to be displayed with pagination.
The JSON data returned from the streaming expressions functions looks like this:

The left panel contains unique entity information and the right panel displays grouped data in an array. Different possible joins with the rating and financial details are found, which is what the Fitch team hoped for.
Paginated Results
The final requirement that needed to be fulfilled was a paginated results display format. Unfortunately this did not exist in any available Solr library for the Solr 7 version Fitch was running. Taking advantage of Solr’s open-source ethos, the Fitch team implemented a new Solr streaming expression to support pagination.
To add the new streaming expression, the TupleStream abstract class needed to be extended and an expressible interface needed to be implemented. Two stream functions were added.
1. SkipStream was used to skip the first tuples:

2. LimitStream was created to limit the total number of records returned:

Finally, the StreamHandler class had to be updated to load the new expressions into streamFactory so the streamFactory object would load them along with the other streaming expressions functions at start up:

To test compatibility with the version of Solr Fitch uses on it’s server, it downloaded the same version, made changes and updates to it, and recompiled to deploy to the Solr server.

Since Fitch uses Solr embedded inside of Lucidworks Fusion software, Fusion’s Solr libraries needed to be updated to see the new streaming expression functions.

Fusion has repackaged Solr so there are several places to update. After testing one Solr instance was successful, the team at Fitch loaded and updated the rest of their Solr instances in their cluster.
With streaming expressions built and in place, performance optimization was the next waypoint on the map.
Improving Performance
Although streaming expressions fulfilled all of Fitch’s requirements, queries that required complex joins and involved multiple filters were sluggish.
To solve this, the following changes were implemented:
- Appropriate filters were applied to reduce the total amount of data before applying the join.
- The fields to select from both join collections were limited.
- The Parallel function was used to do parallel computing wherever applicable.
- A hybrid solution between the standard Solr query and streaming expressions was used when performing complex joins.
The Architecture
Fitch’s search architecture looks like this:

The index data lives in Solr. Fusion pipelines are used to retrieve the data from Solr. Fusion Query Service, a layer between Fusion and the web client, helps construct streaming expressions. A request coming from the client is converted into a streaming expressions query in the Fusion Query Service layer. The response, received from Solr or Fusion, is transformed into a JSON output and returned to the client. This architecture allows any unnecessary implementation details to be hidden from the client and exposes a simple request payload for the clients to query the data. The client doesn’t need to worry about the joins and technology used underneath.
To better serve standard user behavior on the default page, only the entity with default rating information is displayed. In these standard cases, queries perform better via the pipeline than via the streaming expressions and the data is processed in the service layer.

Once a user applies advanced filters on entity, rating, and financial data, queries are routed through the streaming expressions pipeline. This hybrid approach balances querying the simple data and advanced data using complex joins.
Lessons Learned
Over the course of the quest to provide text search, numeric range filters, and alpha numeric range filters on complex data stored over multiple collections, there were a few takeaways.
- If you need to add a customized implementation, the streaming expressions plugin approach is better suited to add internal only functions. Solr streaming expressions plugin architecture will be a better option as it’s more plugable.
- Create an empty worker collection to run the streaming expressions handler. This way you can optimize for streaming expressions performance by creating multiple shards and replicas, and it will trigger multiple workers to run the streaming expressions on an empty data set.
- Use parallel() and parallelList() to do parallel computing whenever possible. For queries with no dependences or order restrictions, parallel streaming processing will maximize the computing power.
- Apply the filter before applying the join operator. Performance testing Fitch conducted found the streaming expressions computation time is a linear correlation to the size of the data.
- Finally, build and validate streaming expressions step by step, inside out. This is the most effective way to debug.
Check out Fitch Solutions full presentation here to learn more.