What’s a Shingle in Lucene Parlance?
Every now and then we get asked what the heck is a shingle in Lucene, as in the ShingleFilter or the ShingleMatrixFilter, so it seems worthwhile to provide some info on shingles in Lucene, Solr and Lucidworks. First off, a shingle is just a word-based n-gram, as opposed to a character-based n-gram (NGramTokenizer, NGramTokenFilter, EdgeNGramTokenizer and EdgeNGramTokenFilter provide the latter functionality). We named it shingles just to differentiate the two when it comes to naming the filters and, well, because like shingles on your roof, they overlap each other.
What are shingles good for? Many people use them to create “pseudo-phrases” during the indexing process since the shingle ends up being a single token, which is then subject to the normal TF-IDF scoring that is used in Lucene. In many cases, searching for phrases yields relevance improvements, but finding phrases at query-time can be more expensive than normal term queries, so people sometimes try to get ahead of the game and use shingles.
If you want to see shingles in action and compare them to n-grams, add the following field types to a sample Solr schema:
<fieldtype name="shingle"> <analyzer> <tokenizer class="solr.WhitespaceTokenizerFactory"/> <filter class="solr.ShingleFilterFactory" minShingleSize="2" maxShingleSize="5"/> </analyzer> </fieldtype> <fieldtype name="ngram"> <analyzer> <tokenizer class="solr.NGramTokenizerFactory" maxGramSize="5" minGramSize="2"/> </analyzer> </fieldtype>
Next start up your Solr instance and browse to http://localhost:8983/solr/admin/analysis.jsp and do the following steps:
- In the Field row, choose “Type” from the dropdown and enter shingle in the text area
- In the Field Value section, choose Verbose output and enter “The quick red fox jumped over the lazy brown dogs”.
- Hit Submit. You should see something like:
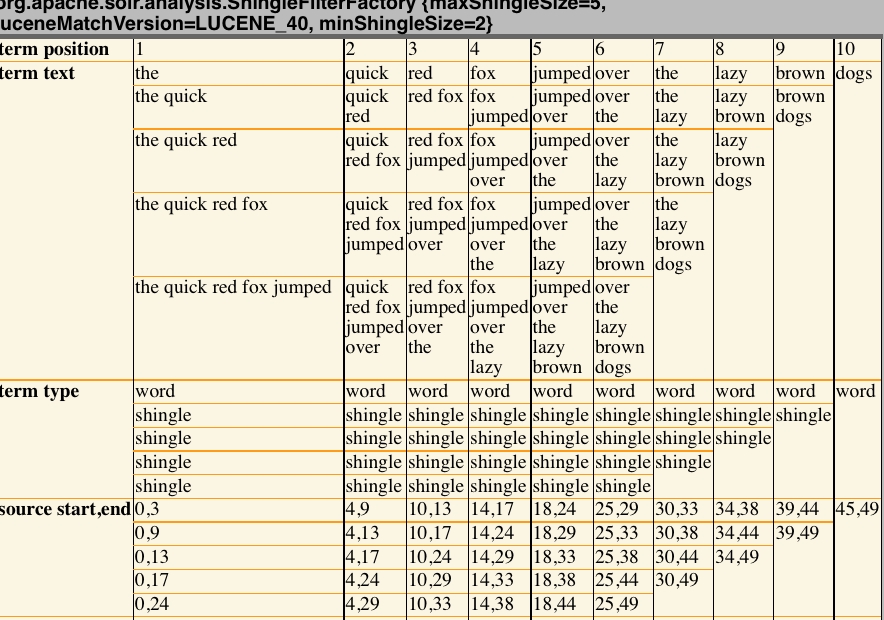
As you can see, there are multiple tokens put out for each position, many of which contain multiple words as a single token.
Next, try the same sentence, but switch from “shingle” to “ngram” for the field type. This time you should see the words split up into character groups.
For more info, see http://en.wikipedia.org/wiki/N-gram. Note, you might also find Google Book’s ngram viewer interesting too: http://ngrams.googlelabs.com/