LUCIDWORKS PLATFORMThe enterprise-grade AI-powered search platform.Seamless, multimodal search that transforms your data into actionable insights and delivers ROI faster.
Get a DemoSay hello to your unified AI platform.
Our AI-driven search platform uses machine learning and natural language processing to deliver hyper-relevant results tailored to your unique business needs, turning scattered data silos into seamless connectivity with intelligent data management.
Whether you’re boosting employee productivity, delighting customers, or making more thoughtful decisions, Lucidworks scales effortlessly with your enterprise.
Your new superpower
Lucidworks isn’t just search—it’s your competitive edge. We help you uncover opportunities hidden in your data to make search a superpower.
See Success StoriesSpeed to value
Non-technical decision-makers? No problem. We’ll get you up and running fast so you can see ROI sooner.
AI-powered search and insights
The world moves at lightning speed. Lucidworks’ AI-driven insights engine keeps you ahead with insights at scale.
Hyper relevance
The most modern approaches, like hybrid search and AI, understand intent better and deliver improved search experiences at scale.
Discover Neural Hybrid SearchDeployment flexibility
Lucidworks is available in SaaS, self-hosted, or hybrid SaaS deployments. This level of choice is unique in the industry and makes Lucidworks an innovative partner.
Compare Deployment OptionsCommerce control
Merchandisers for B2C or B2B can manage complex catalogs, use AI to help scale, see rules in action, and boost, bury, and pin easily.
The Lucidworks Platform: Built to make automating relevance easy at scale.
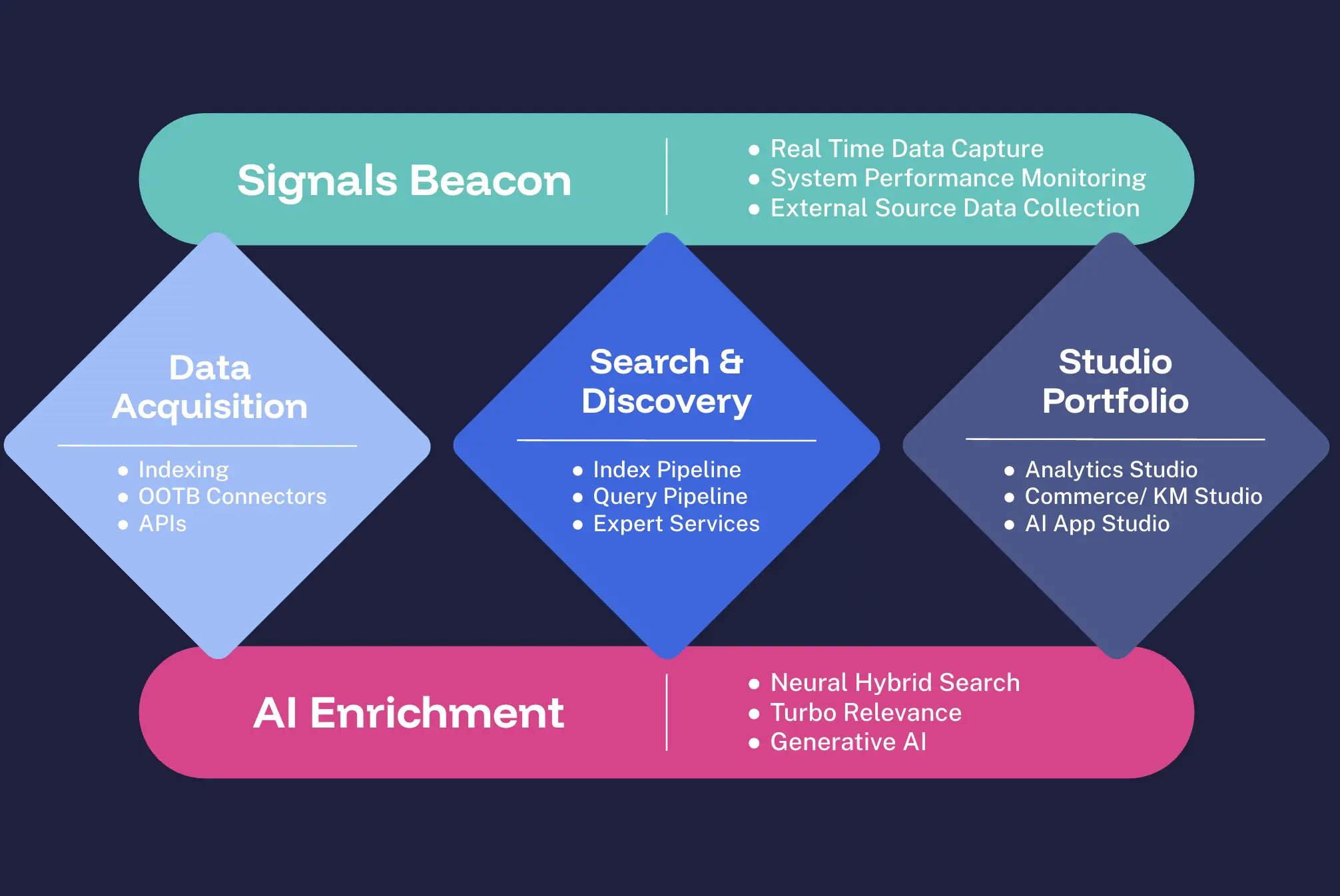
Lucidworks Signals Beacon™
Your data's new bestie.
A lightweight, single-line JavaScript tool for capturing real-time data on user interactions from your website. Beacon collects behavioral signals like clicks, searches, and purchase paths to help businesses optimize their digital experiences.
Start Capturing User Signals TodayLucidworks Data Acquisition™
Connect everything to drive the best insights and relevance.
Seamlessly integrate with existing systems to unify structured and unstructured data.
Connect Your Data SourcesLucidworks Search™
Proven enterprise search and discovery.
A robust solution for managing and optimizing search experiences. Lucidworks handles data preparation and query execution to ensure users get relevant results quickly.
Uplevel Your Search ExperienceLucidworks AI™
AI that plays well with others.
The orchestration layer that brings AI capabilities together into a cohesive and impactful solution. Lucidworks AI ensures that advanced technologies work seamlessly across your business.
Orchestrate Your AI StrategyLucidworks Studios™
A business users' new playground.
A user-facing suite of tools that gives business teams direct control over search, analytics, and personalization strategies for AI apps, commerce, and knowledge management.
Explore Drag-and-Drop StudiosCommerce Studio empowers merchandisers to create personalized, AI-driven shopping experiences that optimize product discovery and drive revenue growth through intuitive, no-code tools.

We’re ready: CMS, PIM, CRM, LLM, and more.
We make it easy to get your data flow’n.
E-commerce Platforms, CRM Systems
Magento
Salesforce Commerce Cloud
BigCommerce
Shopify
SAP CommerceCloud
Salesforce
Microsoft Dynamics 365
Data Storage & Management, Content Management Systems (CMS)
Amazon S3
Google Cloud Storage
Azure Blob Storage
Databricks
Snowflake
Adobe Experience Manager
Drupal
Sharepoint
Collaboration, Productivity, Gen AI & LLMs
Slack
Confluence
Google Vertex AI
ChatGPT
Mistral
Hugging Face
Your deployment, your way.
Only Lucidworks gives you this many ways to set up your solution. You choose what works for your business now and what will grow with you in the future—no forcing you into a one-size-fits-all approach.
SaaS
A modern no-code platform with everything business, search, and digital teams need to create, manage, and optimize search and product discovery for agencies or B2B and B2C companies in any industry. Fast deployment, continually updated, secure, and scalable with automatic feature updates.
Self-Hosted
A self-hosted platform with everything business, search, and digital teams need to create, manage, and optimize search and product discovery for agencies or B2B and B2C companies in any industry. Ultimate control, secure, scalable, and customizable to your environment.
Hybrid-SaaS
A combined solution offering our self-hosted platform with secure access to additional SaaS features. Everything teams need to create, manage, and optimize search and product discovery for agencies or B2B and B2C companies in any industry. Flexible, secure, and scalable deployment options.
Expert Services
We're with you every step of the way.
We support you through every part of your journey, a distinctive advantage of working with Lucidworks.
Our global expert teams advise in search and digital program design, relevance improvement and optimization, B2B and B2C ROI, and full lifecycle implementation and support.
Technology is essential, but so are the people who partner with you for your success.

“Unlike other solutions on the market, Lucidworks AI-powered platform is not a closed black box. This allows us to have the control to monitor and tune results.”
Alexander Czajor, Director of Digital Marketing, STMicroelectronics
Forrester's Total Economic Impact study found that companies using Lucidworks achieve a 391% ROI within three years, with payback beginning in less than six months.
Download ROI StudyLenovo increased annual revenue contribution by 95% and improved search relevance by 55% using Lucidworks' AI-powered search solutions.
Watch Lenovo's StoryRed Hat unified their knowledge management using the Lucidworks platform, increasing the self-solve rate by 311%.
Explore Red Hat's Success